




LLaVA: 시각적 지침 조정을 통한 시각-언어 모델 발전
ChatGPT, LLAMA, 클로드 소네트 등 최신 대규모 언어 모델(LLM)은 인간 언어 기반 지시가 응답 품질을 개선하는 강력한 도구가 될 수 있음을 입증했습니다. 프롬프트 엔지니어링](https://zilliz.com/glossary/prompt-as-code-(프롬프트-엔지니어링))과 같은 기술을 사용하여 특정 사용 사례에 더욱 밀접하게 부합하는 응답을 생성하도록 LLM을 안내할 수 있습니다.
처음에 LLM은 텍스트 기반 입력 전용으로 설계되었습니다. 텍스트 지시가 주어지면 그에 맞는 응답을 생성하는 방식이었습니다. 이 접근 방식은 매우 성공적이었지만, 이러한 기능을 시각적 입력으로 확장하는 것은 자연스러운 발전입니다. 시각 기반 모델은 텍스트 명령어와 이미지를 모두 입력으로 받아 이미지의 내용을 요약하거나 정보를 추출하거나 이미지 내의 텍스트를 번역하는 등의 작업을 수행할 수 있습니다.
이 글에서는 시각 기반 모델에 텍스트 기반 인스트럭션을 구현하기 위한 선구적인 노력 중 하나인 LLaVA (대규모 언어 및 시각 지원)에 대해 살펴보겠습니다. 구현에 대해 자세히 알아보기 전에 한 걸음 뒤로 물러나 시각 기반 모델의 진화와 이 모델이 이 분야를 어떻게 변화시키고 있는지 이해해 보겠습니다.
시각적 기반 모델의 개발
초기 개발 단계에서 대부분의 시각 기반 모델은 일반적인 시각 작업을 수행하기 위해 컨볼루션 신경망(CNN) 기반 아키텍처에 의존했습니다. 가장 간단한 형태의 시각 기반 모델은 한 쌍의 CNN 레이어로 구축되어 주어진 이미지가 개인지 고양이인지 판별하는 것과 같은 간단한 이미지 분류 작업을 수행할 수 있습니다.
그러나 더 많은 클래스로 더 복잡한 이미지를 분류하려면 수백 개의 CNN 레이어로 구성된 더 심층적인 모델을 구축해야 합니다. 모델의 레이어가 깊을수록 소실 그라데이션 문제가 발생할 위험이 높아집니다. 소실 그라데이션은 모델 학습 중에 그라데이션이 너무 작아져 모델이 아무것도 학습하지 못하고 가중치를 업데이트할 수 없게 되는 현상을 말합니다.
이 문제를 해결하기 위해 모델 아키텍처 내에 잔여 연결과 같은 정교한 알고리즘을 구현하여 딥러닝 모델에서 흔히 발생하는 소실 경사 문제를 방지했습니다. 이 방법은 효과적인 것으로 입증되어 ResNet이 탄생하게 되었고, 이후 많은 이미지 분류 벤치마크 데이터 세트에서 최첨단 성능을 달성했습니다.
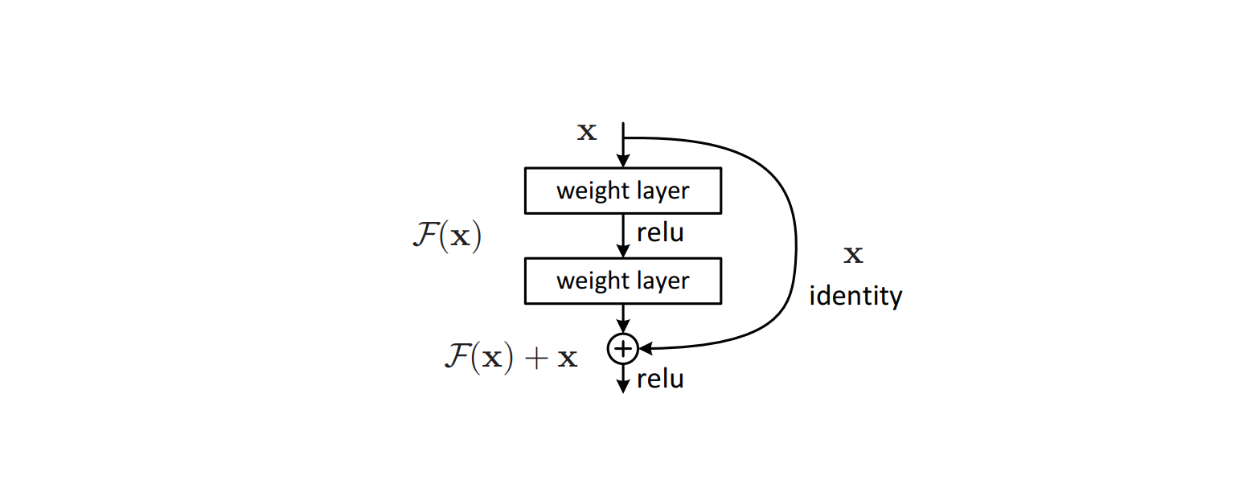
그림: 모델 아키텍처 내 잔여 연결의 빌딩 블록. Source.
ResNet의 성공은 더 복잡한 이미지 작업을 수행할 수 있는 다른 모델 아키텍처에 영감을 주었습니다. YOLO와 같은 시각적 모델은 아키텍처에 잔여 연결을 구현하여 객체 감지 작업을 수행했습니다. 동시에 U-Net은 U자형 아키텍처와 잔여 연결의 조합을 사용하여 이미지 분할 작업을 수행했습니다.
이러한 시각 모델은 시각 기반 작업을 수행할 수 있지만 각각 하나의 특정 작업만 수행할 수 있습니다. 이미지 분류를 위해 학습된 모델은 해당 용도로만 사용할 수 있습니다. 또한 모델에 학습 데이터의 이미지와 상당히 다른 이미지를 분류하도록 요청하면 모델의 예측에서 무작위성이 관찰될 수 있습니다.
2017년에 유명한 트랜스포머 모델이 도입되면서 딥러닝 모델 전반에서 급속한 발전이 이루어졌습니다. 아키텍처에 트랜스포머를 채택한 모델은 기존 모델보다 훨씬 뛰어난 성능을 보였습니다. 원래 텍스트 기반 모델에만 사용되던 트랜스포머 아키텍처는 비전 기반 모델에도 사용할 수 있을 만큼 다재다능한 것으로 입증되었습니다.
비전 트랜스포머(ViT)](https://zilliz.com/learn/understanding-vision-transformers-vit)와 같은 트랜스포머 기반 비전 모델은 이미지 분류 작업 수행에서 높은 성능을 보여주었습니다. 그 결과, 현재 CLIP과 같은 많은 인기 있는 텍스트 비전 모델에서 ViT를 백본 아키텍처로 사용하고 있습니다.
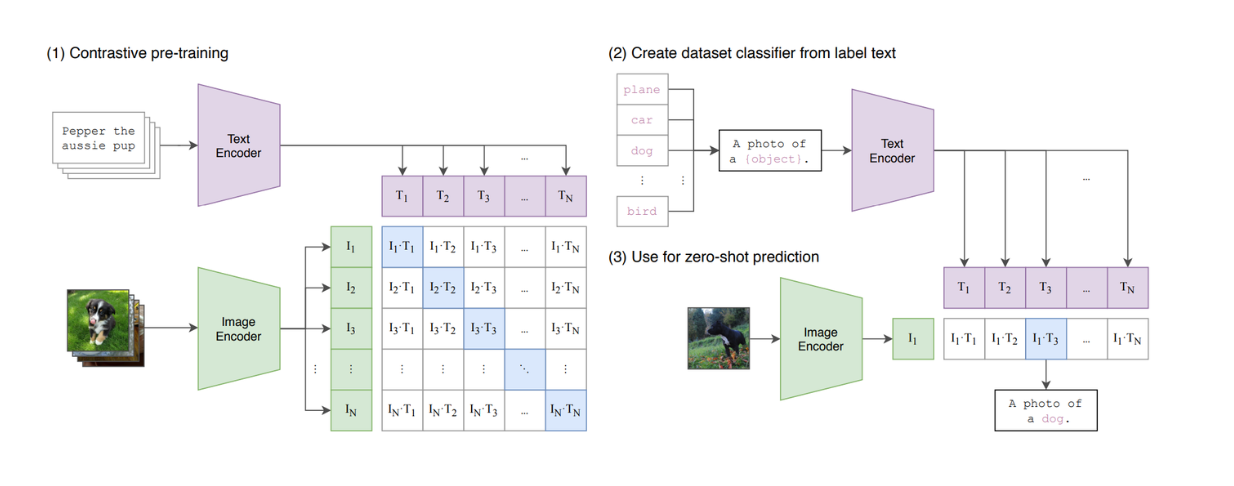
그림: CLIP 모델 요약. Source.
CLIP은 ViT와 BERT와 유사한 모델을 아키텍처에 결합한 모델입니다. ViT는 이미지 입력을 처리하고, BERT 유사 모델은 텍스트 입력을 처리합니다. CLIP은 텍스트와 이미지가 입력 쌍으로 주어지면 텍스트와 이미지의 유사도를 계산하는 대조 학습을 사용하여 학습되었습니다. 그러나 CLIP은 생성 모델이 아니기 때문에 텍스트 기반 LLM을 모방하는 능력에는 여전히 한계가 있음을 알 수 있습니다.
LLaVA는 텍스트 기반 명령어와 이미지를 입력으로 받아 적절한 응답을 생성할 수 있는 가장 초기의 시각 기반 LLM 중 하나입니다. 다음 섹션에서 LLaVA에 대해 자세히 설명하겠습니다.
LLaVa란 무엇인가요?
LLaVA(대규모 언어 및 시각 지원)는 텍스트 기반 대규모 언어 모델(LLM)과 시각 처리 기능을 결합하여 텍스트와 이미지 입력을 처리할 수 있는 멀티모달 모델입니다. 시각적 콘텐츠 요약, 이미지에서 정보 추출, 시각적 데이터에 대한 질문에 대한 답변 등의 작업을 수행하도록 설계되었습니다.
LLaVA는 시각적 이해를 통합하고 텍스트 기반 지침을 이미지 분석과 연계함으로써 LLM의 성공을 기반으로 합니다. 이러한 통합을 통해 모델은 텍스트 프롬프트와 이미지라는 쌍으로 된 입력을 처리하여 일관성 있고 맥락에 맞는 응답을 제공할 수 있습니다.
LLaVA 아키텍처
LLaVA의 아키텍처는 비교적 간단합니다. 사전 학습된 LLM을 사용하여 텍스트 명령을 처리하고, 사전 학습된 CLIP의 시각 인코더, 즉 ViT 모델을 사용하여 이미지 정보를 처리합니다.
공개적으로 사용 가능한 여러 사전 학습된 LLM 중에서 LLaVA의 저자는 한 쌍의 텍스트-이미지 입력이 주어졌을 때 텍스트 정보를 처리하고 최종 응답을 생성하는 백본으로 Vicuna를 선택했습니다.
대부분의 텍스트 기반 LLM은 트랜스포머 아키텍처를 기반으로 하기 때문에 응답 생성까지 텍스트를 변환하는 과정은 매우 간단합니다. 입력 텍스트의 각 토큰은 임베딩으로 변환된 다음 여러 개의 주의 스택과 고밀도 레이어를 거쳐 고정된 크기의 최종 특징 출력을 생성합니다.
이미지 입력을 처리하기 위해 LLaVA는 CLIP 내에서 사전 학습된 ViT 모델을 사용하여 입력 이미지를 고정된 크기의 피처 표현으로 변환합니다. 그러나 CLIP의 이미지 특징의 차원은 Vicuna의 텍스트 특징과 다릅니다. 따라서 LLaVA는 이후 간단한 고밀도 레이어를 구현하여 이미지 피처가 Vicuna의 텍스트 피처와 동일한 크기를 갖도록 투영합니다.
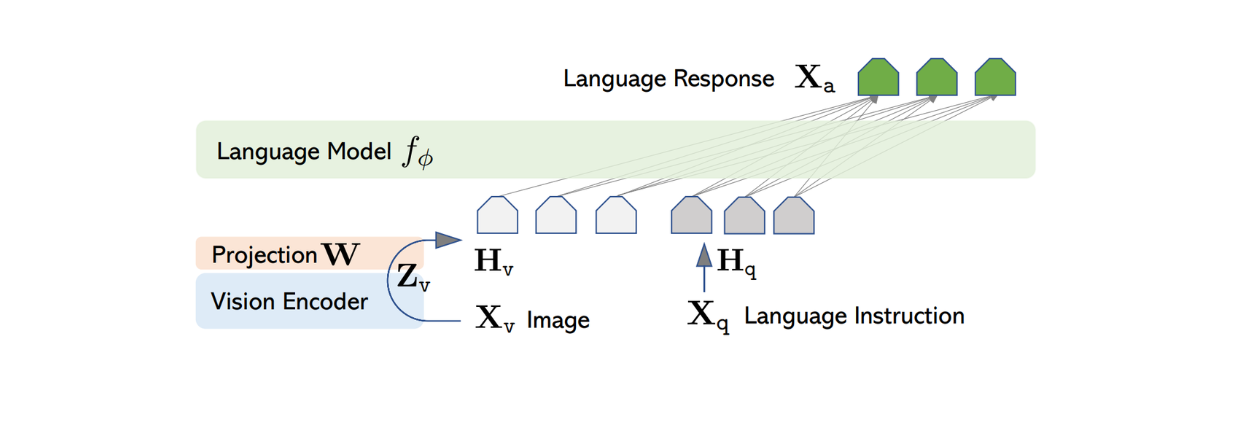
그림: LLaVA 아키텍처. 출처.
이제 이미지 피처와 텍스트 피처의 크기가 같으므로 이 두 피처를 하나로 결합하는 접근 방식이 필요합니다. 이를 위해 일반적으로 사용되는 몇 가지 접근 방식이 있는데, 단순히 토큰 피처 앞에 이미지 피처를 추가하거나([이미지 피처] + [텍스트 피처]) 게이트 교차 주의 및 Q-포머와 같은 보다 정교한 알고리즘을 사용하는 방식이 있습니다. 그런 다음 결합된 이미지와 텍스트 피처가 Vicuna에 입력되어 적절한 응답을 생성할 수 있습니다.
그러나 위에서 언급한 접근 방식을 구현하면 Vicuna 또는 기타 유사한 LLM에서 생성된 응답 품질이 최적이 아닐 수 있습니다. 이는 LLM이 순전히 텍스트 데이터로만 학습되기 때문에 예상되는 현상입니다. 따라서 한 쌍의 이미지-텍스트 입력을 기반으로 일관된 응답을 생성하려면 LLaVA를 미세 조정해야 합니다. 이 미세 조정 프로세스를 시각적 명령어 튜닝이라고 하며, 다음 섹션에서 설명합니다.
시각적 인스트럭션 튜닝을 위한 데이터 생성 프로세스
시각적 명령어 튜닝은 이미지나 동영상과 같은 시각적 입력과 결합된 텍스트 기반 명령어를 이해하고 이에 응답하도록 멀티모달 AI 모델을 훈련하는 프로세스입니다. 이 기술은 시각적 이해와 자연어 처리 기능을 연계하여 이미지 캡션, 시각적 질문에 대한 답변, 사물 인식, 정보 추출과 같은 작업을 수행할 수 있도록 모델을 지원합니다.
시각적 지시 튜닝의 주요 과제 중 하나는 공개적으로 사용 가능한 멀티모달 지시 추종 데이터가 부족하다는 것입니다. CC나 LAION과 같이 이미지와 텍스트 쌍으로 구성된 여러 데이터 세트가 존재하지만, 사용자 지시를 따르도록 시각 기반 LLM을 미세 조정하는 데 사용하기에 적합한 데이터 세트 유형은 아닙니다.
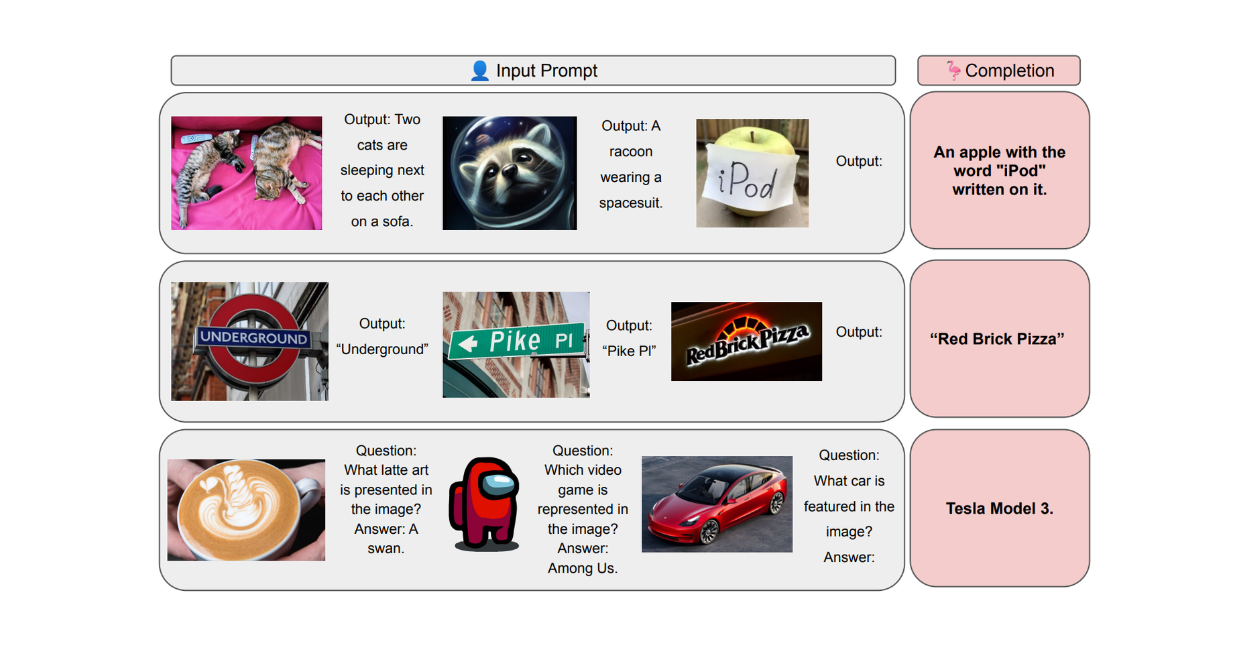
그림: CC 데이터 세트의 예시. 출처.
반면에 LLaVA를 튜닝하기 위해 방대한 양의 멀티모달 명령어 팔로잉 데이터를 수동으로 생성하려면 상당한 노력과 시간이 필요합니다. 따라서 GPT-4 또는 ChatGPT를 활용하여 멀티모달 명령어 팔로잉 데이터 생성 프로세스의 속도를 높일 수 있습니다.
위의 CC 이미지 예시에서 볼 수 있듯이 일반적인 멀티모달 데이터 세트는 각 데이터 레코드에 이미지-캡션 텍스트 한 쌍으로 구성됩니다. ChatGPT를 사용하면 이미지와 캡션이 주어지면 LLM에 이미지의 내용을 설명하도록 지시하기 위한 가능한 질문 세트를 생성할 수 있습니다. 그러면 다중 모달 명령어 추종 데이터의 형식은 다음과 같습니다: 인간: Xq Xv
하지만 이전 버전의 ChatGPT는 텍스트만 입력으로 허용한다는 것을 알고 있습니다. 특정 이미지와 관련된 질문 목록을 큐레이션하는 데 사용하려면 이미지에 대한 정보나 메타데이터를 제공해야 합니다. 작성자는 입력 이미지에 대한 필요한 정보를 ChatGPT에 제공하기 위해 캡션과 경계 상자라는 두 가지 다른 접근 방식을 사용했습니다. 캡션은 일반적으로 이미지에 대한 자세한 설명으로 구성되며, 바운딩 박스는 이미지 내 객체의 정확한 위치에 대한 유용한 정보를 ChatGPT에 제공합니다.

그림: 텍스트 전용 GPT-4의 시각적 정보를 캡처하기 위한 캡션 및 바운딩 박스의 예시. 출처.
저자들은 세 가지 유형의 멀티모달 인스트럭션 팔로잉 데이터 세트를 만들었습니다:
대화: 이는 LLM과 사용자 간의 주고받는 대화로 구성됩니다. LLM의 답변은 이미지를 보고 사용자의 질문에 대답하는 것처럼 톤이 설정되어 있습니다. 일반적인 질문에는 이미지의 시각적 내용, 이미지 속 물체 수 세기, 이미지 속 물체의 상대적 위치 등이 포함됩니다.
상세 설명: 이미지에 대한 포괄적인 설명을 생성하기 위한 질문 목록으로 구성됩니다.
복합 추론: 위의 두 가지 유형을 넘어서는 질문으로 구성됩니다. 이러한 질문은 단순히 이미지의 시각적 내용을 설명하는 대신, 단계별 추론이 필요한 답변의 논리를 설명하도록 하는 것을 목표로 합니다.

그림: 세 가지 유형의 다중 모드 명령어 예시 - 다음 데이터 세트. Source.
다음은 작성자가 대화형 데이터 세트를 생성하는 데 사용한 예제 프롬프트입니다:
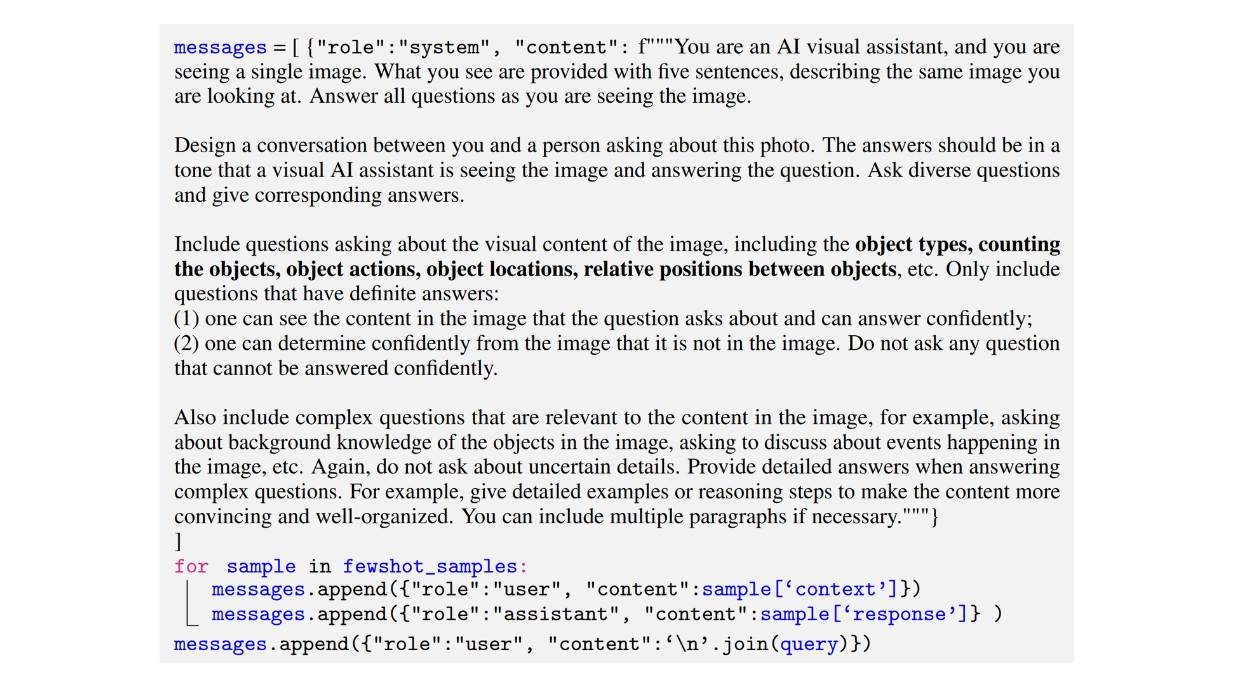
그림: 대화형 멀티모달 명령어 팔로잉 데이터세트를 생성하는 데 사용되는 프롬프트의 예. Source.
LLM으로 생성된 다중 모드 명령어 팔로잉 데이터에서 올바른 형식의 원하는 출력을 얻는 것은 매우 까다로운 작업입니다. 따라서 ChatGPT에 세 가지 유형의 멀티모달 명령어 팔로잉 데이터 세트를 모두 생성하도록 요청할 때, 저자들은 상황 내 학습의 힘을 활용하기 위해 몇 개의 샘플을 사용했습니다.
저자들은 몇 샷 샘플을 통해 수동으로 만든 몇 가지 대화 예시를 프롬프트와 함께 제공했습니다. 이러한 짧은 예시를 통해 ChatGPT가 예상 출력의 구조를 더 잘 이해할 수 있습니다. 다음은 대화 데이터 세트를 생성하기 위해 작성자가 프롬프트에서 구현한 몇 샷 샘플의 예입니다.

그림: 상황에 맞는 학습을 위해 프롬프트와 함께 전달되는 몇 샷 예제 예시. Source.
LLaVA의 교육 절차 ## 교육 절차
위에서 언급한 접근 방식으로 생성된 총 멀티모달 명령어 팔로잉 데이터는 약 15만 8천 개였습니다. 다음으로, 이 멀티모달 데이터로 LLaVA 모델을 미세 조정했습니다.
데이터 세트에서 각 이미지 Xv에 대해 LLM과 사용자 간의 멀티턴 대화가 있습니다(X1q, X1a, - - , XTq, XTa) 여기서 T는 총 턴 수입니다. 각 턴 t에 대해 답 Xta는 LLM의 응답으로 취급되며, 따라서 턴 t의 명령은 다음과 같습니다:
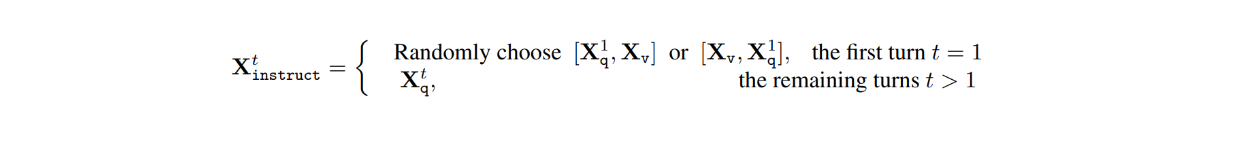
다음으로 시각적 명령어 튜닝 과정에서 기능 정렬을 위한 사전 학습과 엔드 투 엔드 미세 조정의 두 단계가 수행되었습니다.
특징 정렬을 위한 사전 학습 단계에서는 사전 학습된 CLIP 인코더의 ViT 모델 출력을 텍스트 특징과 동일한 차원의 최종 시각 특징에 매핑하는 투영 레이어를 학습하는 것이 주된 목적입니다. 이 단계에서는 596K 개의 이미지-텍스트 쌍이 포함된 필터링된 CC 데이터 세트를 사용하여 훈련 프로세스를 수행했습니다. 각 이미지 Xv에 대해 질문 풀에서 질문 Xq가 무작위로 샘플링되고 해당 Xc가 기준 진실 레이블로 사용됩니다. 따라서 훈련을 위해 샘플링된 질문은 아래 이미지에서 볼 수 있듯이 LLM에게 이미지를 간략하게 설명하도록 요청하는 질문입니다:

그림: 이미지의 내용을 간략하게 설명하라는 프롬프트의 예. Source.
이 단계에서는 투영 레이어만 훈련하기 때문에 ViT와 LLM의 가중치는 모두 고정되어 있습니다.
한편, 엔드 투 엔드 미세 조정인 두 번째 단계에서는 생성된 158K의 멀티모달 명령어 팔로잉 데이터로 LLaVA 모델을 미세 조정합니다. 이 단계에서는 ViT 가중치만 고정되고 투사 레이어와 LLM의 가중치는 미세 조정 프로세스 중에 업데이트됩니다.
LLaVA 결과
LLaVA의 성능을 평가하기 위해 GPT-4와 같은 다른 최신 모델과 BLIP-2 및 OpenFlamingo와 같은 시각 기반 모델과의 비교를 수행했습니다. 결과 평가를 위해 저자들은 텍스트 전용 GPT-4를 사용하여 유용성, 관련성, 정확성 및 세부 수준을 기준으로 응답의 품질에 점수를 매겼습니다.
첫 번째 평가로 COCO-Val-2014 데이터 세트에서 무작위로 30개의 이미지를 선정하고, 이전 섹션에서 설명한 데이터 생성 프로세스를 사용하여 세 가지 유형의 데이터 세트를 생성했습니다. 그 결과 총 90개의 데이터 포인트가 생성되었습니다: 대화 30개, 자세한 설명 30개, 복잡한 추론 30개입니다. 그런 다음 LLaVA의 응답을 텍스트 설명/캡션을 레이블로, 경계 상자를 시각적 입력으로 사용하는 텍스트 전용 GPT-4 모델의 출력과 비교했습니다. 결과는 다음과 같습니다:
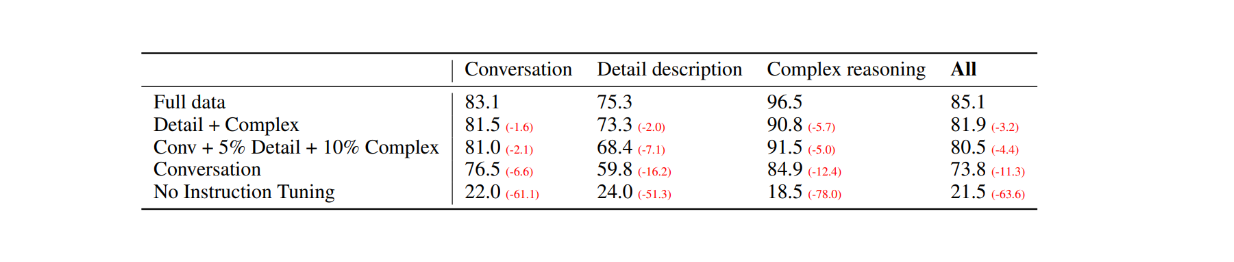
그림: 30개의 무작위 이미지에 대한 LLaVA와 텍스트 전용 GPT-4의 성능 비교. Source.
시각적 지침 튜닝을 통해 모델의 지침 수행 능력은 각 데이터 세트 유형에서 최소 50점 이상 향상되었습니다. 한편, 각 카테고리의 괄호 안의 숫자로 알 수 있듯이 LLaVA의 상대 점수는 이미지 캡션을 시각적 입력으로 사용하는 텍스트 전용 GPT-4 모델과 비교했을 때 큰 차이를 보이지 않았습니다.
또한 총 60문항으로 구성된 24개의 무작위 이미지를 먼저 촬영하여 시각 기반 모델인 BLIP-2 및 OpenFlamingo와 LLaVA의 성능을 비교했습니다. 아래 표에서 볼 수 있듯이 LLaVA의 성능은 다른 두 시각 기반 모델보다 훨씬 우수합니다. 이는 시각적 인스트럭션 튜닝의 힘을 보여주는 것으로, BLIP-2와 OpenFlamingo는 멀티모달 인스트럭션을 따르는 데이터 세트로 명시적으로 미세 조정되지 않았기 때문입니다.

그림: LLaVA와 BLIP-2, OpenFlamingo의 성능 비교 Source._
이제 모델의 실제 반응에 대한 예를 살펴보겠습니다. 치킨 너겟이 세계 지도를 형성하는 그림을 예로 들어 "_이 밈에 대해 자세히 설명할 수 있나요?"라고 질문하면 LLaVA, 텍스트 전용 GPT-4, BLIP-2, OpenFlamingo의 응답 예시를 아래에서 볼 수 있습니다.

그림: LLaVA, GPT-4, BLIP-2, OpenFlamingo의 응답 예시. Source.
그림에서 볼 수 있듯이 BLIP-2와 OpenFlamingo 모델 모두 시각적 명령어 튜닝을 통해 미세 조정되지 않았기 때문에 명령어를 따르지 못했습니다. 반면, LLaVA는 유머를 이해하는 데 있어 시각적 추론 능력을 보여주었습니다. GPT-4와 함께 지시에 따라 간결한 답변을 제공할 수 있었습니다.
ScienceQA 데이터셋에서 약 12개의 에피소드를 대상으로 미세 조정한 결과, LLaVA는 이 데이터셋의 현재 최신(SOTA) 모델인 MM-CoT 모델과 비교했을 때도 매우 경쟁력 있는 결과를 얻었습니다. 아래 표에서 볼 수 있듯이 LLaVA는 여러 피사체에서 90.92%의 전체 정확도를 달성한 반면 MM-CoT 모델은 91.68%에 그쳤습니다. 그러나 LLaVA의 결과물을 GPT-4와 결합했을 때, 그 성능은 ScienceQA 데이터 세트에서 92.53%의 정확도로 새로운 SOTA를 달성했습니다.
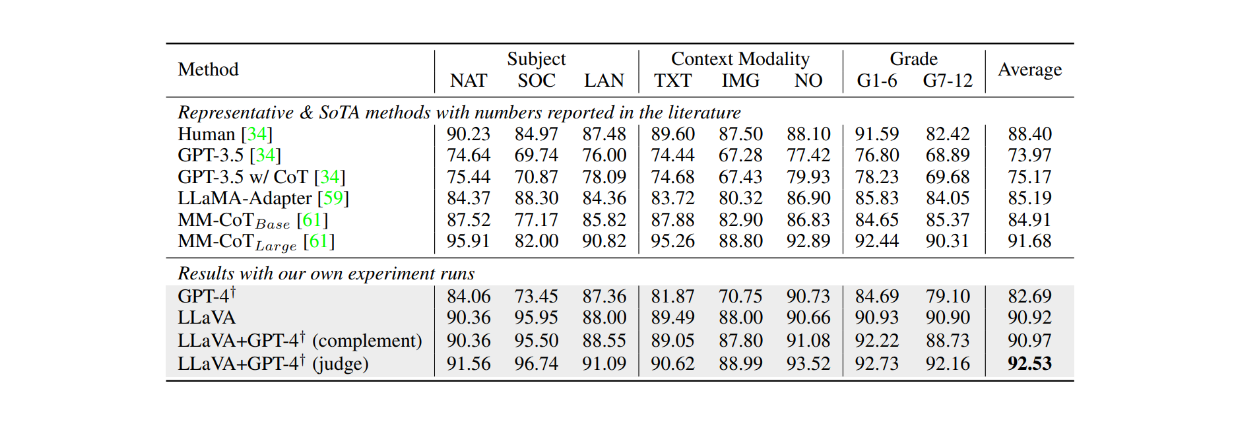
그림: ScienceQA 데이터세트에 대한 LLM의 정확도. Source.
결론
LLaVA는 텍스트 지시를 따를 수 있는 시각 기반 대규모 언어 모델(LLM) 개발의 초기 발전을 나타냅니다. 이 모델은 이미지 처리를 위해 CLIP에서 사전 학습된 비전 트랜스포머(ViT)를 언어 모델 백본으로 Vicuna와 결합하여 투영 레이어를 사용하여 두 구성 요소 간의 특징 차원을 정렬합니다. 그런 다음 이 모델은 158K 개의 멀티모달 명령어를 따르는 데이터 샘플에 대해 미세 조정됩니다.
이러한 시각적 명령어 튜닝 접근 방식 덕분에 LLaVA는 프롬프트의 명령어에 따라 주어진 이미지에 대해 복잡한 추론을 설명하고 수행할 수 있습니다. 평가 결과, LLaVA의 성능이 다른 두 가지 시각 기반 모델보다 일관되게 우수한 것으로 나타나 시각적 명령어 튜닝의 효과를 입증했습니다: BLIP-2와 OpenFlamingo.
추가 읽기
정렬 모델 설명 ](https://zilliz.com/learn/align-explained-scaling-up-visual-and-vision-language-representation-learning-with-noisy-text-supervision)
ColPali: VLM과 ColBERT 임베딩으로 문서 검색 개선 ](https://zilliz.com/blog/colpali-enhanced-doc-retrieval-with-vision-language-models-and-colbert-strategy)
콜버트: 토큰 레벨 임베딩 및 랭킹 모델 ](https://zilliz.com/learn/explore-colbert-token-level-embedding-and-ranking-model-for-similarity-search)
XLNet: 일반화된 자동 회귀 사전 학습을 통한 향상된 NLP](https://zilliz.com/learn/xlnet-explained-generalized-autoregressive-pretraining-for-enhanced-language-understanding)
계속 읽기

Introducing Zilliz Cloud Global Cluster: Region-Level Resilience for Mission-Critical AI
Zilliz Cloud Global Cluster delivers multi-region resilience, automatic failover, and fast global AI search with built-in security and compliance.

Announcing the General Availability of Single Sign-On (SSO) on Zilliz Cloud
SSO is GA on Zilliz Cloud, delivering the enterprise-grade identity management capabilities your teams need to deploy vectorDB with confidence.

Why Not All VectorDBs Are Agent-Ready
Explore why choosing the right vector database is critical for scaling AI agents, and why traditional solutions fall short in production.