




노하우를 사용하여 지식 그래프로 RAG 강화하기
검색 증강 생성(RAG)은 밀버스 및 질리즈 클라우드(완전 관리형 밀버스)와 같은 벡터 데이터베이스를 통해 LLM에 추가 지식과 장기 기억을 제공하는 인기 있는 기법입니다. 기본 RAG는 많은 LLM 문제를 해결할 수 있지만 사용자 지정이나 검색된 결과에 대한 보다 강력한 제어와 같은 고급 요구 사항이 있는 경우에는 충분하지 않습니다.
최근 비정형 데이터 밋업에서 WhyHow의 공동 창립자인 Chris Rec은 성능과 정확도를 높이기 위해 지식 그래프(KG)를 RAG 파이프라인에 통합하는 방법을 공유했습니다. 이 블로그에서는 지식 그래프와 RAG에 대한 개요, 성능 향상을 위해 지식 그래프를 RAG 시스템에 통합하는 방법 등 강연의 핵심 내용을 다룹니다.
이 주제에 대해 더 자세히 알아보려면 YouTube에서 전체 강연을 시청하는 것이 좋습니다.
RAG의 개요와 도전 과제
RAG는 검색 기반 인공 지능 시스템과 생성 인공 지능 시스템의 장점을 모두 활용하는 방법입니다. 바닐라 RAG는 일반적으로 Milvus 같은 벡터 데이터베이스, 임베딩 모델, 대규모 언어 모델(LLM)로 구성됩니다.
RAG 시스템은 먼저 임베딩 모델을 사용하여 문서를 벡터 임베딩으로 변환하고 이를 벡터 데이터베이스에 저장합니다. 그런 다음, 이 벡터 데이터베이스에서 관련 쿼리 정보를 검색하고 검색된 결과를 LLM에 제공합니다. 마지막으로 LLM은 검색된 정보를 컨텍스트로 사용하여 보다 정확한 결과를 생성합니다.
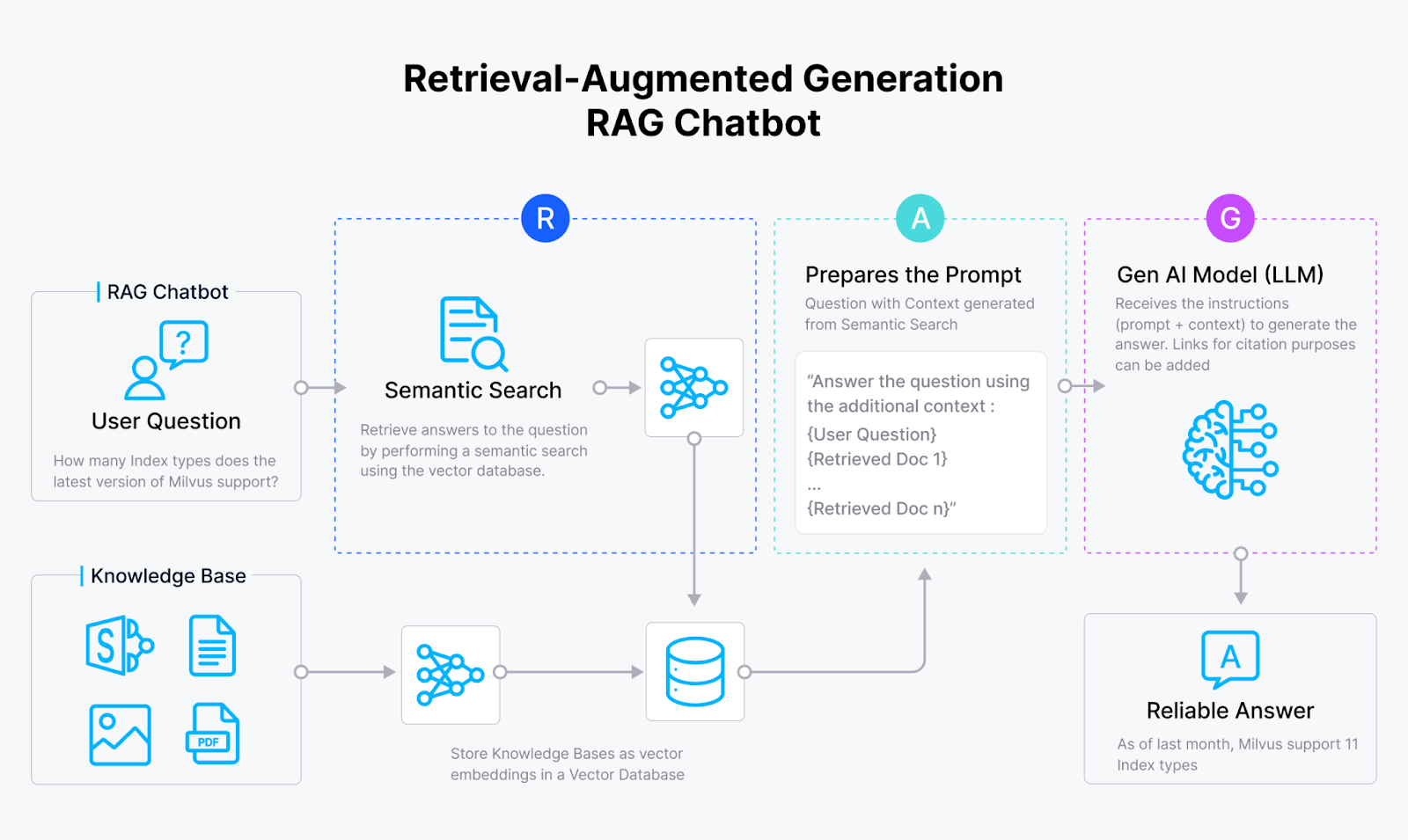 RAG 워크플로
RAG 워크플로
그림 1: RAG의 작동 방식_
바닐라 RAG는 보다 최신의 정확한 결과를 생성하는 데는 훌륭하지만 여전히 몇 가지 한계가 있습니다.
**첫째, LLM은 질문의 특정 맥락이나 영역을 완전히 이해하지 못해 부정확하거나 관련 없는 답변을 내놓을 수 있습니다. 예를 들어, '차량 수용 인원'이라는 용어는 자동차가 수용할 수 있는 승객 수 또는 도로에 들어갈 수 있는 차량 수를 의미할 수 있어 모호성을 야기할 수 있습니다.
둘째, 다양한 쿼리 유형을 정확하게 처리하기가 어렵습니다. 예를 들어 "런던에 가고 싶어요"와 같은 위치 기반 쿼리에 응답하는 것과 "직장에서 스트레스를 받아 휴가를 가고 싶어요"와 같은 추상적인 웰빙 관련 문의를 처리하는 것은 큰 차이가 있습니다.
**셋째, 유사성과 관련성을 구별하기가 쉽지 않습니다. 예를 들어, 해안에서 1마일 떨어진 '해변가 집'과 모래사장에 바로 위치한 '해변가 집'을 구별하기는 어려울 수 있습니다.
넷째, 답변의 완전성도 문제입니다. 포괄적인 질문에 대해 모든 관련 정보를 검색하는 것은 특히 최소 천만 달러를 투자하고 특별한 데이터 액세스 권한을 가진 펀드의 모든 유한 파트너(LP)를 나열하는 것과 같은 복잡한 쿼리의 경우 어려울 수 있습니다.
마지막으로, 멀티홉 쿼리는 여러 정보를 정확하게 결합해야 하므로 또 다른 복잡성을 추가합니다. 이 접근 방식에서는 쿼리를 각각 특정 조건을 가진 여러 개의 하위 쿼리로 세분화하여 최종 응답이 정확하고 완전하도록 해야 합니다.
신속한 개선, 고급 청킹 전략, 더 나은 임베딩 모델, 재순위 지정과 같은 솔루션으로 RAG와 관련된 많은 문제를 해결할 수 있지만, WhyHow는 지식 그래프를 RAG 파이프라인에 통합함으로써 다른 접근 방식을 취합니다.
지식 그래프(KG)란 무엇인가요?
지식 그래프(KG)는 데이터를 저장할 뿐만 아니라 유사하거나 서로 다른 데이터를 관계에 따라 연결하는 데이터 구조의 일종입니다. 이러한 접근 방식을 통해 모든 유형의 데이터가 될 수 있는 사물 모음을 관련성 또는 관련 정보를 제공할 수 있는 방식으로 연결할 수 있습니다.
지식 그래프는 노드, 에지 및 속성으로 구성됩니다.
그림 2- 지식 그래프의 빌딩 블록](https://assets.zilliz.com/Fig_2_Building_Blocks_of_a_Knowledge_Graph_3a3c13c822.png)
그림 2: 지식 그래프의 구성 요소
노드:
그래프에서 엔티티 또는 객체를 나타냅니다.
이러한 엔티티의 저장 값은 모든 유형의 데이터가 될 수 있습니다.
가장자리:
엔티티 간의 관계를 나타냅니다.
연결된 노드 간의 관계 특성에 대한 정보를 보유합니다.
속성: 개별 엔티티와 관련된 특성 또는 특징.
기존의 표 형식 데이터베이스와 달리 지식 그래프는 그래프 구조를 사용해 관계를 유연하게 표현하고 의미론적 이해에 중점을 둡니다. 이러한 접근 방식을 통해 복잡한 쿼리를 수행하고 특정 정보를 쉽게 추출할 수 있습니다.
RAG 시스템에 지식 그래프를 통합하면 얻을 수 있는 이점
지식 그래프를 RAG 파이프라인에 통합함으로써 시스템의 검색 기능과 답변 품질을 크게 향상시켜 성능, 정확성, 추적성 및 완전성을 크게 향상시킬 수 있습니다. 다음은 지식 그래프 기반 RAG 시스템의 주요 장점입니다:
문맥 이해도 향상
지식 그래프는 풍부하고 상호 연결된 정보 표현을 제공하므로 RAG 시스템이 개체 간의 복잡한 관계를 파악할 수 있습니다. 이러한 심층적인 문맥 이해는 보다 미묘하고 관련성 높은 응답으로 이어집니다.
정확성 및 사실 일관성 향상
지식 그래프의 구조화된 특성은 생성된 콘텐츠 전반에서 사실의 일관성을 유지하는 데 도움이 됩니다. 그래프 내에서 검증된 정보에 대한 응답을 고정함으로써 시스템은 기존 언어 모델에서 흔히 발생하는 오류와 착각을 줄일 수 있습니다.
멀티홉 추론 기능
지식 그래프를 통해 RAG 시스템은 논리적 경로를 통해 서로 다른 정보를 연결하는 멀티홉 추론을 수행할 수 있습니다. 이 기능을 통해 보다 정교한 쿼리 답변과 추론 생성이 가능합니다.
효율적인 정보 검색
그래프 구조로 복잡한 쿼리도 빠르고 정확하게 정보를 검색할 수 있습니다. 이러한 효율성은 더 빠른 응답 시간과 더 관련성 높은 콘텐츠 생성으로 이어집니다. 또한, 지식 그래프 기반 RAG 시스템은 밀버스나 질리즈 클라우드와 같은 벡터 데이터베이스에서 제공하는 기능인 벡터 및 키워드 검색과 그래프 탐색을 결합한 하이브리드 검색 방식을 허용합니다.
좀 더 구체적으로 설명하자면, 이 하이브리드 접근 방식은 다음을 가능하게 합니다:
그래프 트래버스를 통한 정확한 개체 및 관계 매칭
벡터 임베딩](https://zilliz.com/glossary/vector-embeddings)을 사용한 시맨틱 유사성 매칭
텍스트가 많은 콘텐츠에 대한 기존 키워드 기반 검색
이러한 다각적인 검색 전략은 다양한 데이터 유형과 구조에서 가장 관련성이 높은 정보를 찾는 시스템의 능력을 향상시켜 보다 포괄적이고 정확한 응답을 이끌어냅니다.
투명하고 추적 가능한 결과물
지식 그래프를 통해 시스템은 응답을 생성하는 데 사용된 정보의 출처를 명확하게 증명할 수 있습니다. 이러한 추적성은 사용자의 신뢰를 높이고 사실 확인과 검증을 더욱 쉽게 해줍니다.
도메인 간 지식 종합 ### 교차 도메인 지식 종합
단일 그래프 구조 내에서 다양한 도메인을 표현함으로써 지식 그래프 기반 RAG 시스템은 여러 분야의 정보를 보다 쉽게 합성하여 보다 포괄적이고 학제 간 인사이트를 도출할 수 있습니다.
모호성 처리 개선
지식 그래프의 관계형 구조는 개체와 개념을 명확히 구분하는 데 도움이 되며, 용어나 이름이 여러 의미나 참조를 가질 수 있는 상황에서 혼란을 줄여줍니다.
이러한 이점을 활용하여 지식 그래프로 강화된 RAG 애플리케이션은 사용자 쿼리에 대해 보다 정확하고 맥락에 맞는 포괄적인 답변을 제공할 수 있습니다.
WhyHow란 무엇인가요? 지식 그래프로 RAG를 어떻게 향상시킬 수 있나요?
WhyHow는 복잡한 데이터 검색을 지원하기 위해 지식 그래프를 구축하고 관리하기 위한 플랫폼입니다. 포괄적인 지식 그래프를 구축하는 것은 어렵고 시간이 많이 소요됩니다. WhyHow는 특정 도메인에 대한 만족스러운 KG가 나올 때까지 작은 KG를 생성하고 이를 여러 번 반복하는 방식으로 이 문제를 해결합니다. 이 접근 방식은 KG가 복잡하기 때문에 도메인에 특화되어 있고 더 간단하며 작업하기 쉽습니다.
또한 WhyHow는 개발자에게 복잡한 RAG를 수행하기 위해 비정형 데이터를 구성, 컨텍스트화 및 안정적으로 검색할 수 있는 빌딩 블록을 제공합니다. 벡터 데이터베이스로 구동되는 기존 RAG 파이프라인에 WhyHow를 통합하면 더 나은 구조, 일관성 및 제어 기능을 갖춘 RAG 시스템을 만들 수 있습니다. 아래 다이어그램은 지식 그래프로 강화된 RAG의 작동 방식을 보여줍니다.
그림 3- RAG와 WhyHow의 통합](https://assets.zilliz.com/Fig_3_Integration_of_RAG_with_Why_How_b893400b28.png)
그림 3: RAG와 WhyHow의 통합
RAG 워크플로우에 WhyHow를 통합하면 벡터 데이터베이스에서 제공하는 지식 그래프와 벡터 검색 기능의 장점을 모두 활용하여 하이브리드 그래프와 벡터 접근 방식을 취할 수 있습니다.
WhyHow로 지식 그래프로 강화된 RAG를 구축하는 방법에 대한 자세한 가이드는 Zilliz에서 주최한 비정형 데이터 밋업에서 Chris가 공유한 라이브 데모를 시청하는 것을 추천합니다.
WhyHow와 질리즈 클라우드를 사용하여 RAG 내에서 검색 워크플로우를 보다 효과적으로 제어하기
많은 개발자들은 RAG 애플리케이션의 성능과 추적성을 향상시키는 것 외에도 RAG가 검색하는 내용을 더 잘 제어할 수 있기를 희망합니다. 사용자가 잘못된 문구의 쿼리를 보내거나 사용자가 문맥상 관련이 있지만 의미상 서로 다른 데이터를 응답에 포함해야 할 때 RAG 애플리케이션이 올바른 데이터 청크를 일관되게 검색하지 못하는 경우가 종종 있기 때문입니다.
이러한 문제를 해결하기 위해 와이하우는 질리즈 클라우드와 통합하여 규칙 기반 검색 패키지를 구축했습니다. 이 Python 패키지를 통해 개발자는 고급 필터링 기능을 통해 보다 정확한 검색 워크플로우를 구축할 수 있으며, RAG 파이프라인 내에서 검색 워크플로우를 보다 효과적으로 제어할 수 있습니다. 이 패키지는 텍스트 생성을 위한 OpenAI와 저장 및 효율적인 벡터 유사도 검색 및 메타데이터 필터링을 위한 Zilliz Cloud와 통합됩니다.
규칙 기반 검색 솔루션은 이러한 작업을 수행합니다:
**벡터 저장소 생성: 청크 임베딩을 저장하기 위한 Milvus 컬렉션을 생성합니다.
분할, 청크** 및 임베딩:** LangChain의 PyPDFLoader와 RecursiveCharacterTextSplitter를 사용하여 업로드된 문서를 자동으로 분할, 청크 및 임베딩을 생성하며, OpenAI의 텍스트 임베딩 3-소형 모델을 지원합니다.
**데이터 삽입: 임베딩과 메타데이터를 Milvus 또는 Zilliz Cloud에 업로드합니다.
자동 필터링: 사용자 정의 규칙을 기반으로 메타데이터 필터를 구축하여 벡터 스토어에 대한 쿼리를 구체화합니다.
워크플로는 다음과 같습니다:
와이하우와 질리즈 클라우드의 연동 방법](https://assets.zilliz.com/How_Why_How_and_Zilliz_Cloud_work_together_8510ecf053.png)
그림 4: 규칙 기반 검색 솔루션의 워크플로우
소스 데이터는 OpenAI의 임베딩 모델을 통해 벡터 임베딩으로 변환되어 질리즈 클라우드에 저장 및 검색을 위해 인제스트됩니다. 사용자 쿼리가 발생하면 역시 벡터 임베딩으로 변환되어 질리즈 클라우드로 전송되어 가장 연관성 높은 결과를 검색합니다. WhyHow는 벡터 검색에 규칙을 설정하고 필터를 추가합니다. 검색된 결과는 원래 사용자 쿼리와 함께 LLM으로 전송되어 보다 정확한 결과를 생성하여 사용자에게 전송됩니다.
결론
LLM은 다양한 문제에 대한 해답을 찾는 데 있어 저희의 부담을 덜어주었습니다. 제공된 쿼리를 이해할 수 있을 만큼 똑똑하지만, 리소스 제약으로 인해 최신 상태로 유지하기가 어렵습니다. 따라서 검색 증강 생성(RAG) 기술은 쿼리에 대한 컨텍스트를 제공함으로써 이들에게 힘을 실어주지만, 앞서 설명한 것처럼 RAG 시스템에도 한계가 있습니다.
WhyHow는 이러한 한계를 파악하여 지식 그래프를 RAG 파이프라인에 통합하는 것이 해결책임을 강조했습니다. 지식 그래프로 RAG를 개선함으로써 RAG 시스템은 보다 관련성 있고 맥락에 맞는 정보를 검색하고, 더 적은 오답과 높은 정확도로 더 확실한 답변을 생성할 수 있습니다.
이 주제에 대해 더 자세히 알아보고 싶으시면 YouTube에서 Chris의 프레젠테이션을 시청하세요.
추가 리소스
RAG 파이프라인의 성능을 향상하는 방법](https://zilliz.com/learn/how-to-enhance-the-performance-of-your-rag-pipeline)
전체 RAG: 초개인화를 위한 최신 아키텍처](https://zilliz.com/blog/full-rag-modern-architecture-for-hyperpersonalization)

계속 읽기

Zilliz Cloud Just Landed in Claude Code
The Zilliz Cloud Plugin brings the full power of Zilliz Cloud directly into your Claude Code terminal as natural-language conversations.

Creating Collections in Zilliz Cloud Just Got Way Easier
We've enhanced the entire collection creation experience to bring advanced capabilities directly into the interface, making it faster and easier to build production-ready schemas without switching tools.

Milvus WebUI: A Visual Management Tool for Your Vector Database
Explore Milvus WebUI to monitor, manage, and optimize your vector database with real-time insights, performance tracking, and system health monitoring.