




Databricks & Spark Connectors
Leverage Databricks' powerful data processing alongside Milvus & Zilliz Cloud's vector index and search with no custom code required
この統合を無料で利用する
Milvus & Zilliz Cloudのデータ処理とベクトル検索機能の組み合わせ
Databricksは、データ処理と機械学習タスクを簡素化する統合分析プラットフォームです。オープンソースの分散コンピューティングシステムであるApache Sparkをベースに構築されています。データエンジニア、データサイエンティスト、アナリストがビッグデータプロジェクトで共同作業できる環境を提供します。Databricksは、Sparkクラスタの複雑な管理を抽象化し、ユーザーがデータ分析と機械学習タスクに集中できるようにします。インタラクティブなノートブック、自動化されたクラスタ管理、さまざまなデータソースや機械学習ライブラリのビルトインサポートを提供する。全体として、DatabricksはSparkの使いやすさとスケーラビリティを強化し、組織が大規模データセットから洞察を導き出すことを容易にする。
Spark Milvus Connectorは、Apache SparkとMilvus間のシナジーを創出し、ユーザがMilvusのベクトルデータストレージやクエリ機能とともにSparkの処理能力を活用できるようにします。この統合により、Milvusと異なるストレージシステムやデータベース間のシームレスなデータ転送と統合、Milvus内での合理化されたデータ処理と分析、Spark MLlibやその他のAIライブラリを活用した効率的なベクトル処理操作など、さまざまな価値あるアプリケーションの利用が可能になります。
この同じコネクターはZilliz CloudとDatabricksの間でも使用でき、オフライン処理からオンライン処理へのデータ移行を簡素化し、AI主導の検索に重要な役割を果たします。
統合の主なハイライトは以下の通り:
- ベクトル生成Sparkジョブがシンプルなユーティリティ関数呼び出しでMilvusに直接データをロードできるようになり、カスタムグルーコードや追加のSparkジョブが不要になる。
- Spark-Milvusコネクタを使用してSpark DataFrameレコードをMilvusに直接挿入することで、接続を確立するコードやAPIコールが不要になり、統合が効率化される。
仕組み
SparkからMilvusにデータを転送するプロセスに飛び込もう。従来、このタスクには複雑なバックエンドのグルーコードが必要でした。しかし、Spark-Milvusコネクタを使用すると、Sparkアプリケーション内の単一の関数呼び出しに合理化されます。
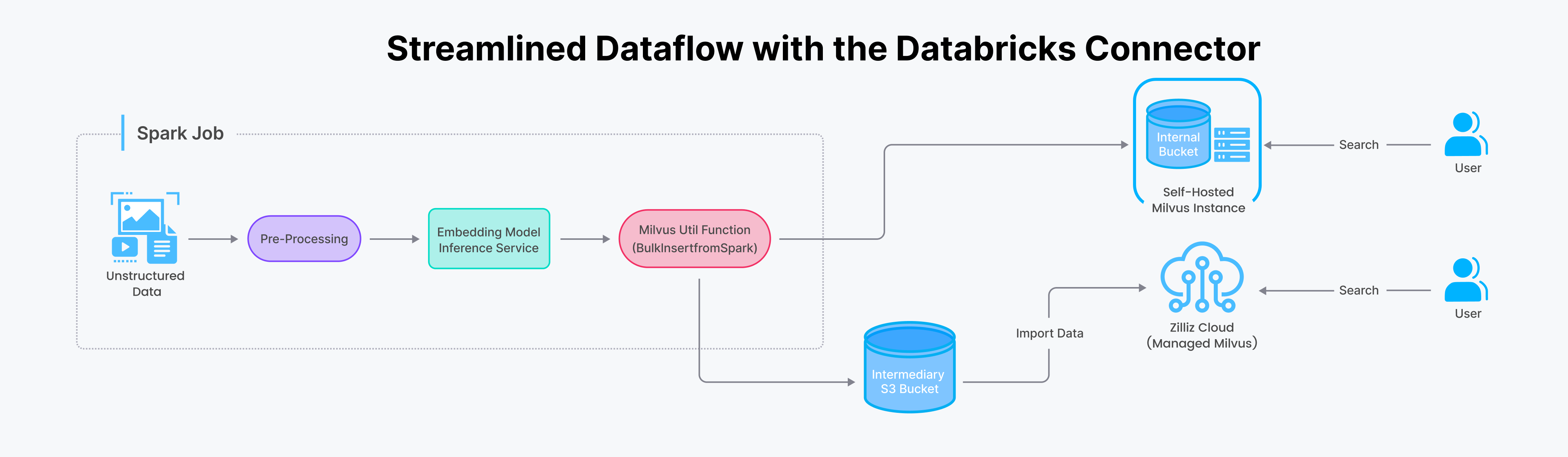 Databricksコネクタによる合理化されたデータフロー.png
Databricksコネクタによる合理化されたデータフロー.png
Spark/Databricks Connectorを使用すると、2つの方法でZilliz Cloud(またはMilvus)にデータをインポートできます:リアルタイム更新のためのストリーミングと大規模データセットのためのバッチです。効果的な使い方のステップバイステップガイドはノートブック例をご覧ください。
SparksとDatabricksコネクタの使用方法を学ぶ
Zilliz Cloud、Sparkコネクター、Databricksコネクターを使い始めるために、以下のリソースをチェックしてください。
Spark Milvusコネクタ
- ドキュメント](https://milvus.io/docs/integrate_with_spark.md)
- Github Repo](https://github.com/zilliztech/spark-milvus)
Databricks コネクタ
- ノートブック例](https://zilliz.com/databricks_zilliz_demos)