




Zillizベクトル探索アルゴリズム、BIGANNの4トラックすべてを制す
BigANN](https://big-ann-benchmarks.com/neurips23.html)チャレンジは、近似最近傍(ANN)問題の実用的な変形のためのインデックスデータ構造と検索アルゴリズムの開発を促進する、ベクトル検索領域におけるクライマックスコンペティションです。Zillizは、この重要なコンペティションの主要なオーガナイザーとして、世界中の参加者の独創的なソリューションを目の当たりにしたことを誇りに思っています。Milvus](https://zilliz.com/what-is-milvus)ベクトル・データベースの作成者として、私たちは提示された課題に対して私たちの洞察と解決策を提供しなければならないと感じました。
今日、私たちは素晴らしいニュースを共有できることに興奮しています:**この記事では、BigANN 2023を紹介し、Zillizソリューションとそのパフォーマンス結果について深く掘り下げます。
BigANN 2023
ANNベンチマーク](https://ann-benchmarks.com/)は、ベクトル探索アルゴリズムを評価するための業界標準ツールですが、評価データセットが小さいため、実際の生産課題への適用には限界があります。これに対し、BigANNは、大規模なデータセットでアルゴリズムを評価し、進歩させることで、この限界に対処する、コンペティションとベンチマークの両方の役割を果たすイニシアチブとして誕生しました。
今年のBigANN 2023では、より大規模なデータセット(最大1,000万ベクトルポイント)とより複雑なシナリオを重視し、より重要な課題を導入しています。このコンペティションでは、ANNSのフィルタリング、分布外、スパース、ストリーミングの4つのトラックが用意されており、実世界のシナリオに即した現実的なテストの場が提供される。
表1:BigANN 2023の4つのトラック](https://assets.zilliz.com/bigann_four_tracks_78a2204f86.png)
**このタスクはYFCC 100Mデータセットを使用し、1000万枚の画像を選択する。各画像のCLIP埋め込みを抽出し、画像の説明、カメラモデル、撮影年、国などの側面をカバーするタグを、多様な語彙から抽出し生成する必要がある。ここでの課題は、画像埋め込みと特定のタグで構成される10万件のクエリを、データセット内の対応する画像とタグに効率よくマッチさせることである。
OOD(Out-Of-Distribution)トラック:このトラックでは、参加者にYandex Text-to-Image 10Mデータセットを紹介し、クロスモーダルデータの統合を強調する。ベースとなるデータセットには、Se-ResNext-101モデルを用いて生成された、Yandexビジュアル検索データベースからの1,000万件の画像埋め込みが含まれる。一方、クエリ埋め込みはテキスト検索に基づいており、別のモデルで処理されている。ここでの主な課題は、これらの異なるモダリティのデータ間のギャップを効果的に埋めることである。
**このトラックは、SPLADEモデルを使用してスパースベクトルにエンコードされた880万以上のテキストパッセージの広範なコレクションを特徴とするMSMARCOパッセージ検索データセットを活用する。これらのベクトルは約30,000次元であるが、スパースな性質を示す。同時に約7,000のクエリも同じモデルで処理されるが、長さが簡潔なため非ゼロ要素は少ない。このトラックにおける主要なタスクは、クエリベクトルとデータベースベクトル間の最大内積に特に重点を置きながら、与えられたクエリに対して上位の結果を正確に取り出すことである。
ストリーミング・トラック:このトラックは、3,000万点のデータからなるMSチューリング・データセットの一部に基づいている。参加者は提供された「ランブック」に従って、データの挿入、削除、検索の一連の操作を複雑に行う必要がある。これらの操作は、1時間以内に、8GBのDRAMで完了しなければならない。このトラックでは、これらの操作を処理するプロセスを最適化し、データセットの合理化されたインデックスを維持することに焦点を当てる。
このコンペティションでは、各トラックにアルゴリズム・ランキングの明確な基準が設けられている:
Filters、OOD、Sparseトラックでは、最低90%のリコール@10を達成することを条件に、QPSに基づいてアルゴリズムが評価される。
ストリーミング・トラック**では、1時間以内にランブックを完成させるという追加条件とともに、アルゴリズムがrecall@10に従ってランク付けされる。
Zillizソリューションを含むすべてのパフォーマンステストは、Azure D8lds_v5(8vCPU、16GiBメモリ)で実施された。
Zillizソリューションとそのパフォーマンス結果
以下の結果はすべて、BigANNコンペティションが定めた評価フレームワークとガイドラインに準拠しており、公平かつ包括的な比較を実現しています。
フィルタートラック
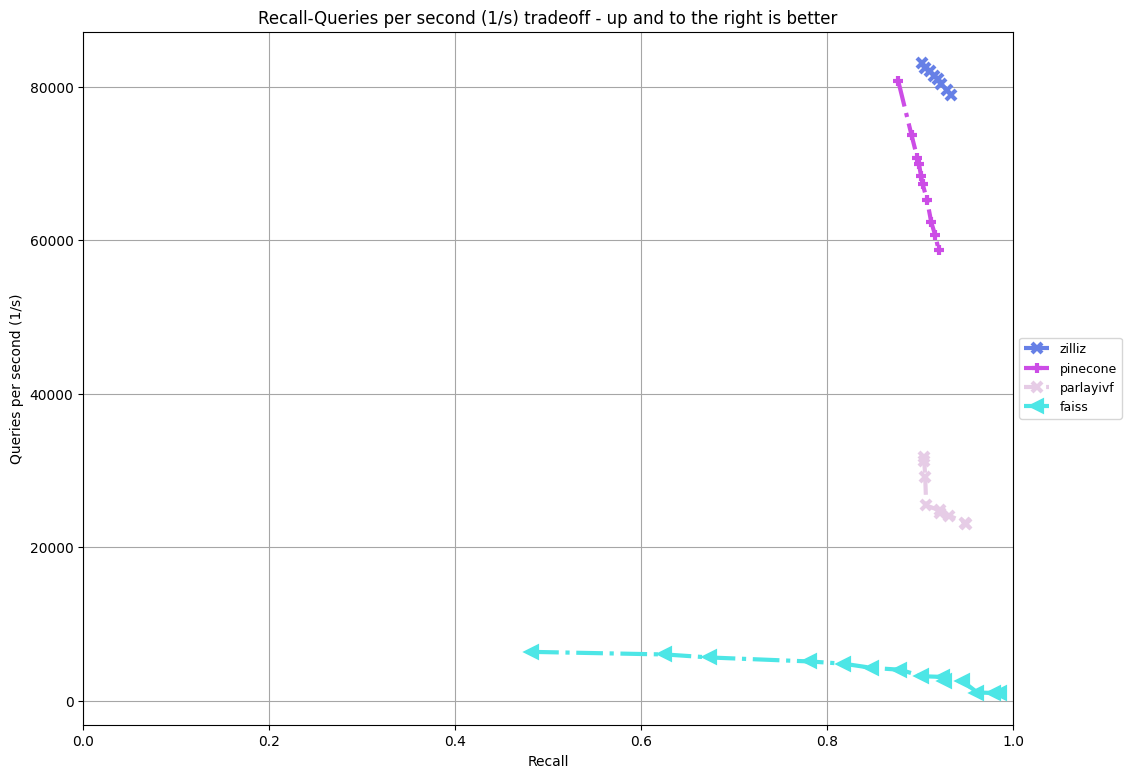
公式ベースライン(faiss)、勝者(parlayivf)、Pineconeソリューションに対する我々のFilterトラックソリューション(zilliz)の比較。90%リコール時、我々のスループットはおよそ82,000 QPSで、ベースラインの3,200 QPSの約25倍、トラック勝者の32,000 QPSの2.5倍、Pineconeソリューションの68,000 QPSよりはるかに高い_。
我々のソリューションは、グラフアルゴリズムとタグ分類に基づいている。構築段階では、各タグの潜在的な組み合わせのカーディナリティを分析する。多数のベクトルを持つ組み合わせについてはグラフを構築し、それ以外については転置インデックスを確立する。検索時には、各タグの組み合わせのユニークな特徴に基づいて、適切な検索方法を選択する。
並行して、関連するタグに従ってクエリを分類する。検索時には、対応するタグに基づいて各クエリを検索する。このアプローチには2つの利点がある:1) キャッシュの使用量を最大化できる、2) 行列の乗算による高速化が可能であり、これは特に網羅的検索の際に有益である。
データを量子化して計算を高速化し、SIMDを使用して距離計算を微調整することで、高い計算効率を実現している。
OODトラック
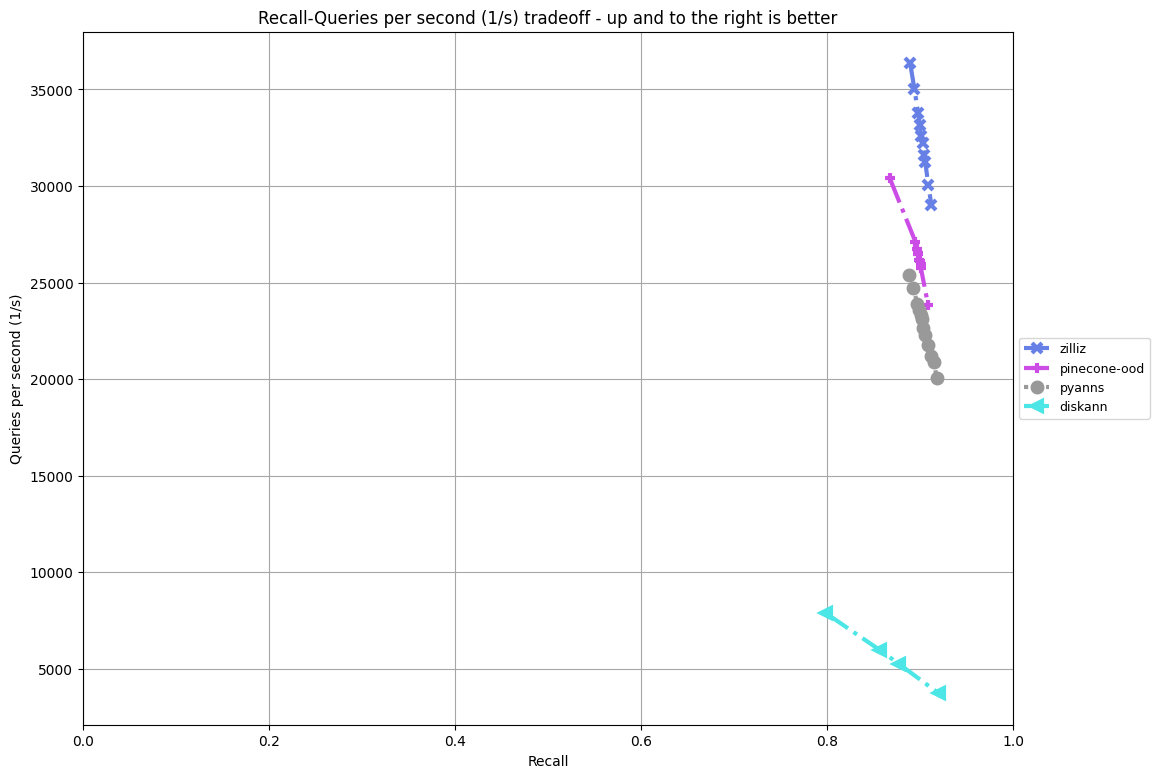
公式ベースライン(diskann)、トラック勝者(pyanns)、Pineconeソリューション(pinecone-odd)に対するOODトラックソリューションの比較。90%のリコールにおいて、我々のスループットはおよそ33,000 QPSで、ベースラインの8倍のおよそ4,000 QPSであり、トラッカーウィナーのおよそ23,000 QPSとPineconeソリューションの26,000 QPSを上回っています_。
注:このトラックには隠しクエリセットがないため、この比較は公開クエリセットを使って行っています。
我々のソリューションはグラフアルゴリズムと高度に最適化された検索プロセスの相乗効果に基づいている。
計算には、検索と絞り込みの両方に異なる精度レベルの量子化を使用し、SIMDのパワーを利用して計算を高速化する。検索の前に、クエリーベクターをクラスタリングする。グラフ探索では、クエリの各クラスタに異なる初期点を割り当てることで、各クラスタ内での連続探索に道を開く。
このクラスタリング戦略には2つの利点がある:1)異なるクラスタを順次探索することで、キャッシュの使用率が最大になること、2)多様なクラスタに適応的な初期点を割り当てることで、ベクトル分布の変化から生じる課題を軽減できること、である。
さらに、マルチレベルのビットセットデータ構造も実装する。複雑な画像検索プロセスにおいて、訪問した点をマークするためのデータ構造が必要である。従来の方法ではビットセットかハッシュテーブルに頼ることが多いが、それぞれに欠点がある。ビットセットはしばしば非効率的なメモリ使用とキャッシュミスを引き起こし、ハッシュテーブルは不利な定数のためにパフォーマンスが悪い。我々は、メモリ内のマルチレベル・ページ・テーブルからヒントを得て、マルチレベル・ビットセット・データ構造を革新した。この設計によりCPUのキャッシュ利用が最適化され、読み書きのパフォーマンスが大幅に向上しました。
スパース・トラック
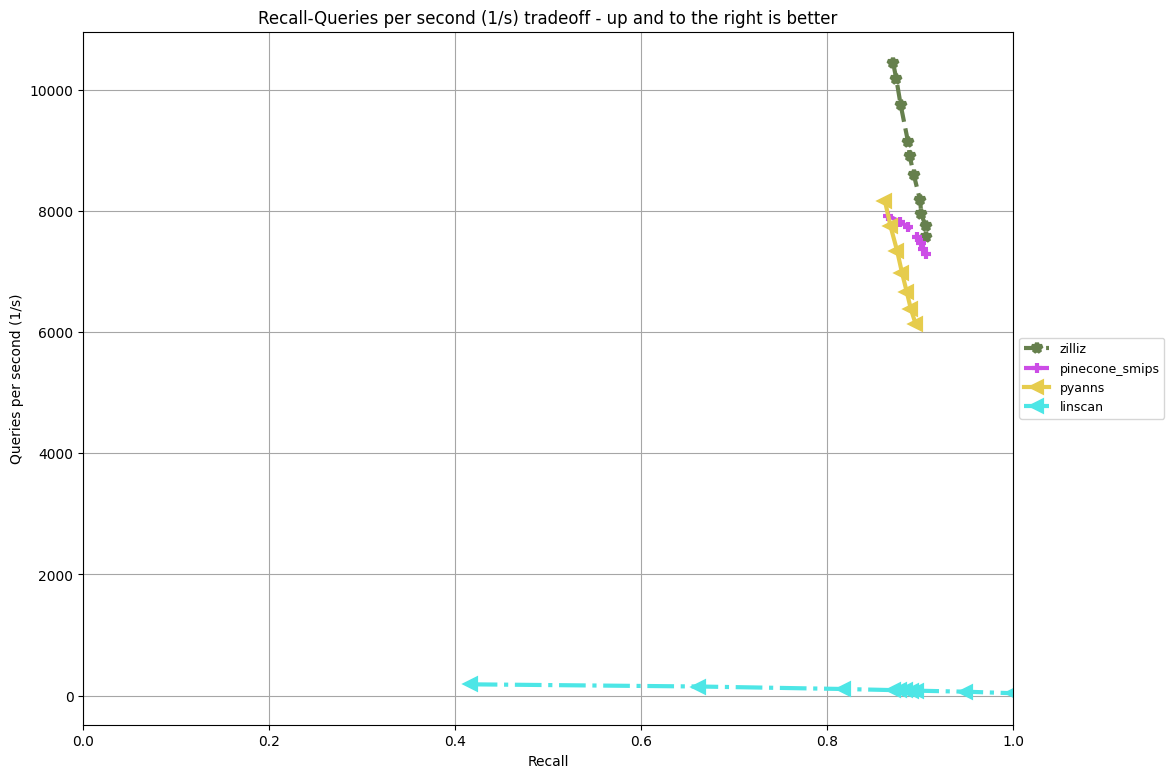
公式ベースライン(linscan)、トラック勝者(pyanns)、Pineconeソリューション(pinecone_smips)に対する我々のSparse Trackソリューション(zilliz)の比較。90%の想起において、我々のスループットは約8,200 QPSで、ベースラインの約100 QPSの82倍であり、トラックウィナーの6,000 QPSとPineconeソリューションの7,400 QPSの両方を上回った_。
このトラックにおいて、我々のソリューションは、グラフアルゴリズムとスパースベクトルによる最適化の相乗効果に基づいています。各スパースベクトルはタプル(data[float32], index[int32])のリストとして表現されます。データを処理するために多精度の量子化を導入し、グラフ探索とそれに続く精密化の計算に対応する。さらに、インデックスを int16 で表現することで、メモリ帯域幅を最適化している。
タスクは内積探索を最大化することである。内積計算では、その大きさが値の重要度に影響する。大きければ大きいほど重要度が高く、小さければ小さいほど重要度が低くなる。この洞察を利用して、グラフ探索中に絶対値の大きさが小さい値を破棄するプルーニング戦略を実装する。グラフ探索の後、完全なベクトルを用いて洗練を行う。実験の結果、想起を大きく損なうことなく、クエリベクトルの80%以上のデータをプルーニングできることがわかった。
我々は、ソートされたリストの高速な交差のためにSIMD技術を採用し、それによりスパースベクトルの内積の高効率な計算を実現している。
ストリーミングトラック
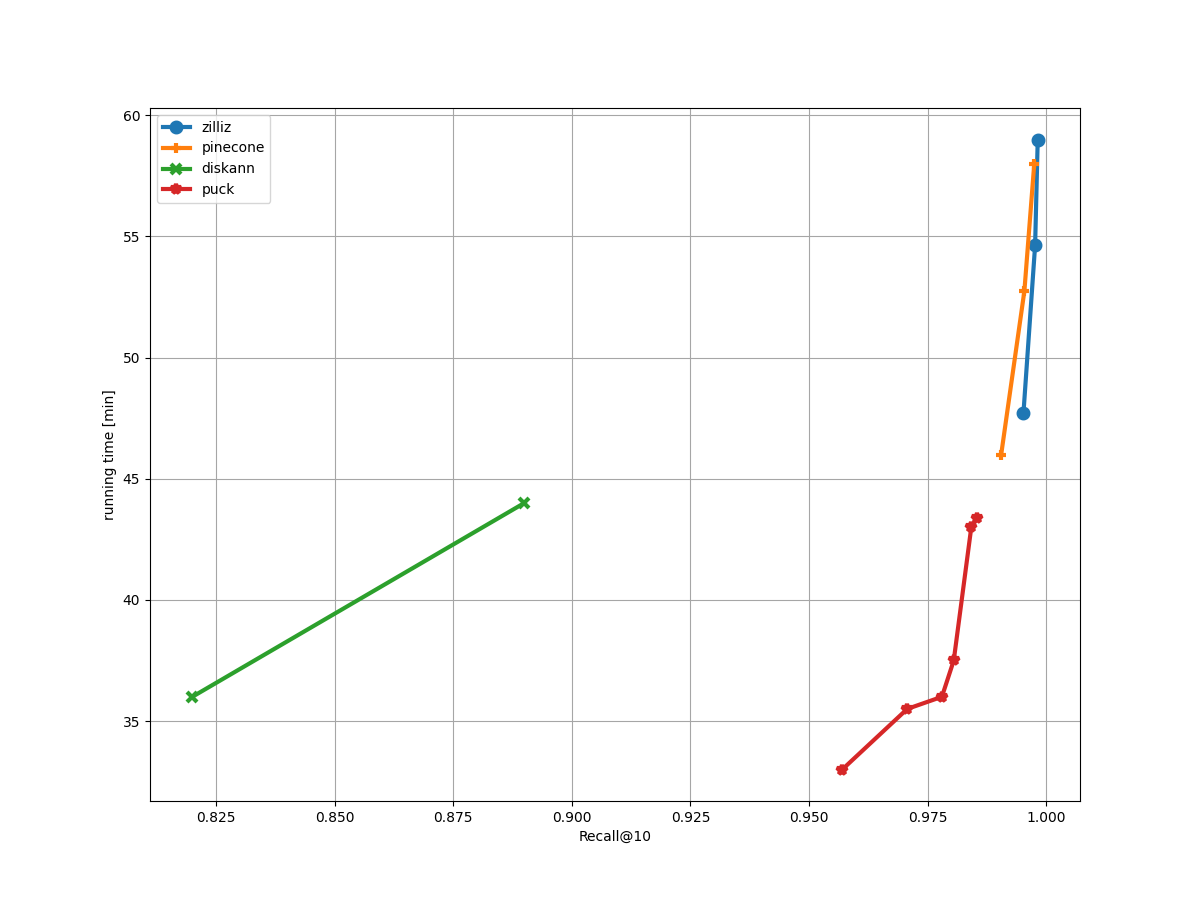
公式ベースライン(diskann)、トラック勝者(puck)、Pineconeソリューション(pinecone)に対する我々のStreaming Trackソリューション(zilliz)の比較。我々のアルゴリズムは0.9982のリコールを達成し、それぞれ0.986と0.9975のリコールを持つトラック勝者とPineconeソリューションを上回る_。
我々のストリーミング・トラック・ソリューションは、グラフ・アルゴリズムとSQ量子化に基づいている。
削除操作に対して遅延削除戦略を実装し、グラフ構造を直ちに変更することなく、削除するベクトルをマークする。指定された数の削除操作が蓄積されるまで、グラフは再構築されない。
グラフ探索と精密化の両方において、様々な精度でベクトルを量子化する。まず、グラフ探索には低精度ベクトルを用いる。しかし、我々の遅延削除戦略により、削除されたベクトルが検索結果に現れる可能性がある。そこで、削除されたベクトルを除去するためにポストフィルタリング戦略を活用する。最後に、より高精度の量子化ベクトルを用いて結果を絞り込む。
注:*我々のソリューションはオープンソースではありませんが、広く利用・複製できるように、我々の手法を説明し、バイナリをBigANNのGitHubリポジトリに公開しています。
BigANNアルゴリズムはZilliz製品に統合されます。
AIの進歩に伴い、ベクトル検索は複雑な本番シナリオをサポートするために必要不可欠となっています。複数のシナリオをカバーするBigANNは、実用的な価値を大きく高めています。私たちは、このBigANNコンペティションに積極的に参加し、挑戦的なアルゴリズム問題に取り組むことを楽しんでいます。私たちは、このプロセスから得られた洞察を製品に反映させ、より幅広い問題への影響を拡大していきます。
ぜひご参加ください!
Zillizでは、世界最高のベクトルデータベースを構築し、ベクトル検索を使用して現実世界の問題に取り組むことをお約束します。また、BigANNにインスパイアされた挑戦的なユースケースを探求する旅を続けています。私たちは、ベクトル検索、データベースシステム、AI技術に興味のある志を同じくする方々に、この道を一緒に歩んでいただける方を募集しています。興味のある方は、ぜひご連絡ください!キャリア](https://zilliz.com/careers)ページで、詳細と応募の機会をご覧ください。
*この投稿はLiu LiuとZihao Wangによって書かれました。

読み続けて

Zilliz Cloud Launches in AWS Australia, Expanding Global Reach to Australia and Neighboring Markets
We're thrilled to announce that Zilliz Cloud is now available in the AWS Sydney, Australia region (ap-southeast-2).

Data Deduplication at Trillion Scale: How to Solve the Biggest Bottleneck of LLM Training
Explore how MinHash LSH and Milvus handle data deduplication at the trillion-scale level, solving key bottlenecks in LLM training for improved AI model performance.

Optimizing Embedding Model Selection with TDA Clustering: A Strategic Guide for Vector Databases
Discover how Topological Data Analysis (TDA) reveals hidden embedding model weaknesses and helps optimize vector database performance.