




Migrating from S3 Vectors to Zilliz Cloud: Unlocking the Power of Tiered Storage
Unstructured data now makes up nearly 90% of all new data generated. The ChatGPT boom made this shift even clearer. Vector search has since become the default way to make sense of unstructured data — powering GenAI systems such as RAG pipelines, AI agents, recommendation engines, and chatbots.
But vector search isn’t cheap. It can require 10–100× more compute than a NoSQL workload, especially with unoptimized indexes, and in some cases, it’s even more expensive than an LLM call. When every query hits high-performance storage and memory, costs can scale faster than performance.
AWS introduced S3 Vectors to address this, combining vector search with the cost efficiency of object storage. It’s a clever idea but not without trade-offs: higher latency, lower recall, and limited flexibility for large-scale systems. Zilliz Cloud’s Tiered Storage takes a more balanced path. It stores your full dataset in object storage while using each cluster’s local SSDs and memory as intelligent caches to speed up queries and data access.
In this post, we’ll break down where S3 Vectors shine and where they fall short, then show how Zilliz Cloud’s Tiered Storage solves these limitations. You’ll also find a short tutorial on migrating your data from S3 Vectors to Zilliz Cloud in just a few steps.
S3 Vectors: Cheap, But With Clear Limits
Let’s start with what works. S3 Vectors is cheap. Storage costs just $0.06 per GB, roughly five times cheaper than most serverless vector databases. In a sample workload of 400 million vectors and 10 million queries per month, the total bill comes to around $1,200 per month — a huge drop from the five-figure bills you’d typically see elsewhere. For low-traffic or latency-tolerant workloads, it’s hard to argue with that math.
Performance Has Boundaries: The trade-offs start showing once you push for scale or responsiveness:
Collection size: Each S3 table holds up to 50 million vectors, and there’s a global cap of 10,000 tables.
Query latency: Expect around 500 ms for a 1M-vector collection and 700 ms for 10M — acceptable for background jobs, not real-time apps.
Throughput: You’ll get under 200 ms latency up to 200 QPS, but scaling beyond that isn’t easy.
Write speed: Limited to under 2 MB/s, far slower than engines like Milvus that sustain GB/s-level writes. The upside is that writes don’t block reads — but overall, it’s clearly optimized for read-heavy, static datasets.
Accuracy and Query Flexibility: Recall typically lands between 85–90%, with no tuning knobs to push it higher. Once you add filters, recall can drop sharply, sometimes below 50%. In one benchmark, after deleting half the dataset, a Top-K=20 query only returned 15 results — a clear sign that precision control is limited.
Missing Features: S3 Vectors also skips several features that developers often expect in production systems:
Top-K queries capped at 30 results.
Strict metadata limits per record.
No hybrid search, multi-tenancy, advanced filtering support, and many other enterprise-ready features.
S3 Vectors is cheap and is a solid fit for simple, large-scale retrieval tasks where query frequency is low and latency isn’t critical. But when workloads demand real-time search, hybrid retrieval, or multi-tenant architectures, its simplicity quickly becomes a bottleneck.
Zilliz Cloud Tiered Storage: Cost-Effective, Fast, and Production-Ready
AWS combined object storage with vector search to reduce costs. Zilliz Cloud takes that idea further with its new Tiered Storage, matching the same cost efficiency while delivering real production performance.
Built on open-source Milvus, Zilliz Cloud is a fully managed vector database designed for large-scale AI workloads. Its Tiered Storage architecture stores all vector data in object storage (such as AWS S3) while using each cluster’s local SSDs and memory as intelligent caches to accelerate queries and data access. The result: the low cost of S3 with the speed and flexibility of a dedicated vector database.
Under the hood, Tiered Storage manages three layers — Hot (memory), Warm (SSD), and Cold (object storage):
Hot data stays in memory for instant response times.
Warm data resides on local SSDs to balance speed and cost.
Cold data is stored efficiently in object storage for long-term retention.
The system automatically moves data between tiers based on real query patterns, maintaining over 90% cache hit rates in production testing. In practice, that means most queries are served directly from the fast layers—combining object storage economics with in-memory responsiveness.
Practical Use Cases for Zilliz Cloud Tiered Storage
1. Large-Scale Multi-Tenant RAG/AI Apps
Many production AI systems serve millions of tenants, but only a small fraction — typically 1–5% — are active at any given time. Think AI coding assistants, chat apps, or customer-support copilots.
With Tiered Storage, Zilliz Cloud automatically balances storage based on activity:
Around 95% of inactive tenant data stays in object storage, keeping storage costs close to raw S3 levels.
The active 5% lives in memory or on an SSD, ensuring low-latency retrieval during ongoing sessions.
2. Large-Scale, Low-Frequency Data Analysis
Domains like autonomous driving, robotics model training, and drug discovery generate petabyte-scale datasets — yet their query workloads are often light, ranging from a few to a few hundred queries per day. For these cases, constant in-memory storage is overkill.
Zilliz Cloud’s Tiered Storage keeps cold data in object storage while caching frequently queried samples in faster tiers. It cuts storage costs to a fraction of complete in-memory systems while preserving usable latency, letting research teams explore massive datasets efficiently and affordably — without changing their analysis workflows.
How to Move Your Data from S3 Vectors to Zilliz Cloud
Now that Zilliz Cloud’s Tiered Storage gives you S3-level cost efficiency without the performance trade-offs, the next question is simple — how do you move your data over?
Let’s use a simple example. Suppose you’ve stored 200 book records in the AWS region us-west-2, under a vector index named books. Each record contains:
A 768-dimensional content vector
The book title as the primary key
Author information stored in metadata
Prerequisites
Docker is installed and running.
The node running VTS has access to both S3 Vectors and Zilliz Cloud.
Your IAM user or role includes the
s3vectors:ListVectorspermission.
Pre-Migration Validation
Before deploying VTS, verify your S3 Vectors data and access.
import boto3
import os
aws_access_key_id = os.getenv("AWS_ACCESS_KEY_ID")
aws_secret_access_key = os.getenv("AWS_SECRET_ACCESS_KEY")
s3vectors = boto3.client("s3vectors", region_name="us-west-2", aws_access_key_id=aws_access_key_id, aws_secret_access_key=aws_secret_access_key)
resp = s3vectors.list_vectors(vectorBucketName="vectors", indexName="books", returnMetadata=True, returnData=True)
for vector in resp["vectors"]:
print(vector)
You should see 200 records returned.
{'key': 'First foot situation land bad.', 'data': {'float32': [0.7183347940444946……]}, 'metadata': {'author': 'Wendy Jones'}}
{'key': 'Face industry bit true.', 'data': {'float32': [0.9061349630355835……]}, 'metadata': {'author': 'Steven Smith'}}
{'key': 'Republican agreement probably home choose see.', 'data': {'float32': [0.26946496963500977……]}, 'metadata': {'author': 'Misty Lynch'}}
{'key': 'Before arrive design soon finally discuss.', 'data': {'float32': [0.35728317499160767……]}, 'metadata': {'author': 'Mark Johnson'}}
…………
Start Migration
1.Pull the latest VTS image (version 1.2.0 or higher):
docker pull zilliz/vector-transport-service:v1.2.0
2.Create a configuration file:
vim ./s3-vector_to_milvus.conf
3.Add the following content (modify as needed):
env {
execution.parallelism = 1
job.mode = "BATCH"
}
source {
S3Vector {
region = "us-west-2"
vector_bucket_name = "vector-bucket" # Name of your vector bucket
index_name = "books" # Name of your vector index
ak = "ak" # aws_access_key_id
sk = "sk" # aws_secret_access_key
}
}
sink {
Milvus {
url="https://in01-***.<region>.zilliz.com.cn:19530"
token="***"
database="default" # Target database
batch_size=1 # Number of records per batch (larger batches are faster but use more memory)
}
}
Save the file.
4.Run the VTS container and mount your config file:
docker run -v ./s3-vector_to_milvus.conf:/config/s3-vector_to_milvus.conf -it zilliz/vector-transport-service:v1.2.0 /bin/bash
5.Start the VTS process inside the container:
./bin/seatunnel.sh --config /config/s3-vector_to_milvus.conf -m local
Wait for the process to complete. Once finished, your data will be successfully transferred to Zilliz Cloud.
Post-Migration Verification
After the migration completes, verify your data in the Zilliz Cloud Console.
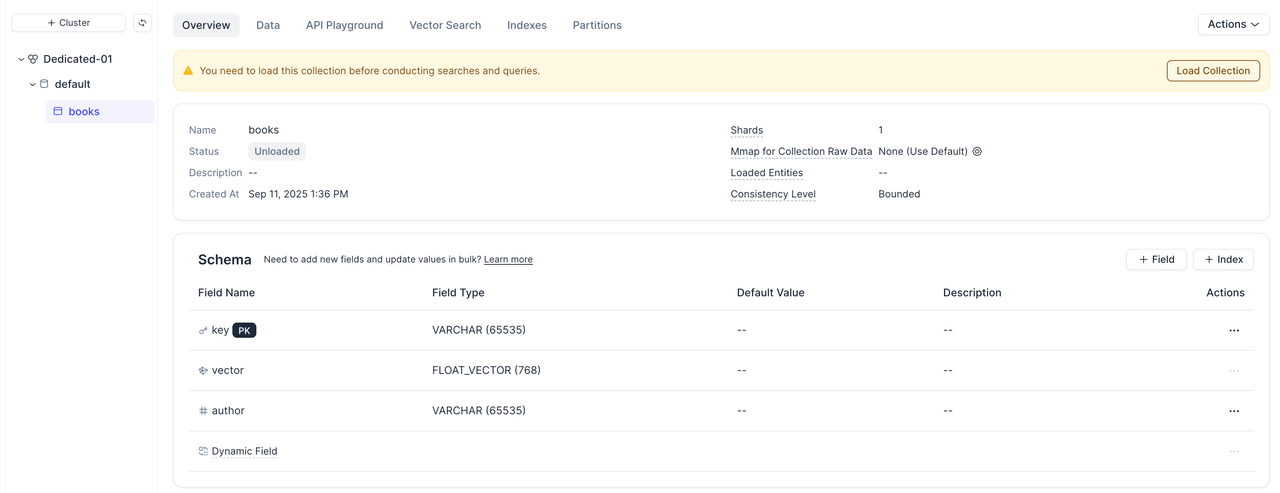
VTS automatically detects metadata fields and creates columns for each attribute. The key field is used as the primary key.
Create a vector index on the vector field.
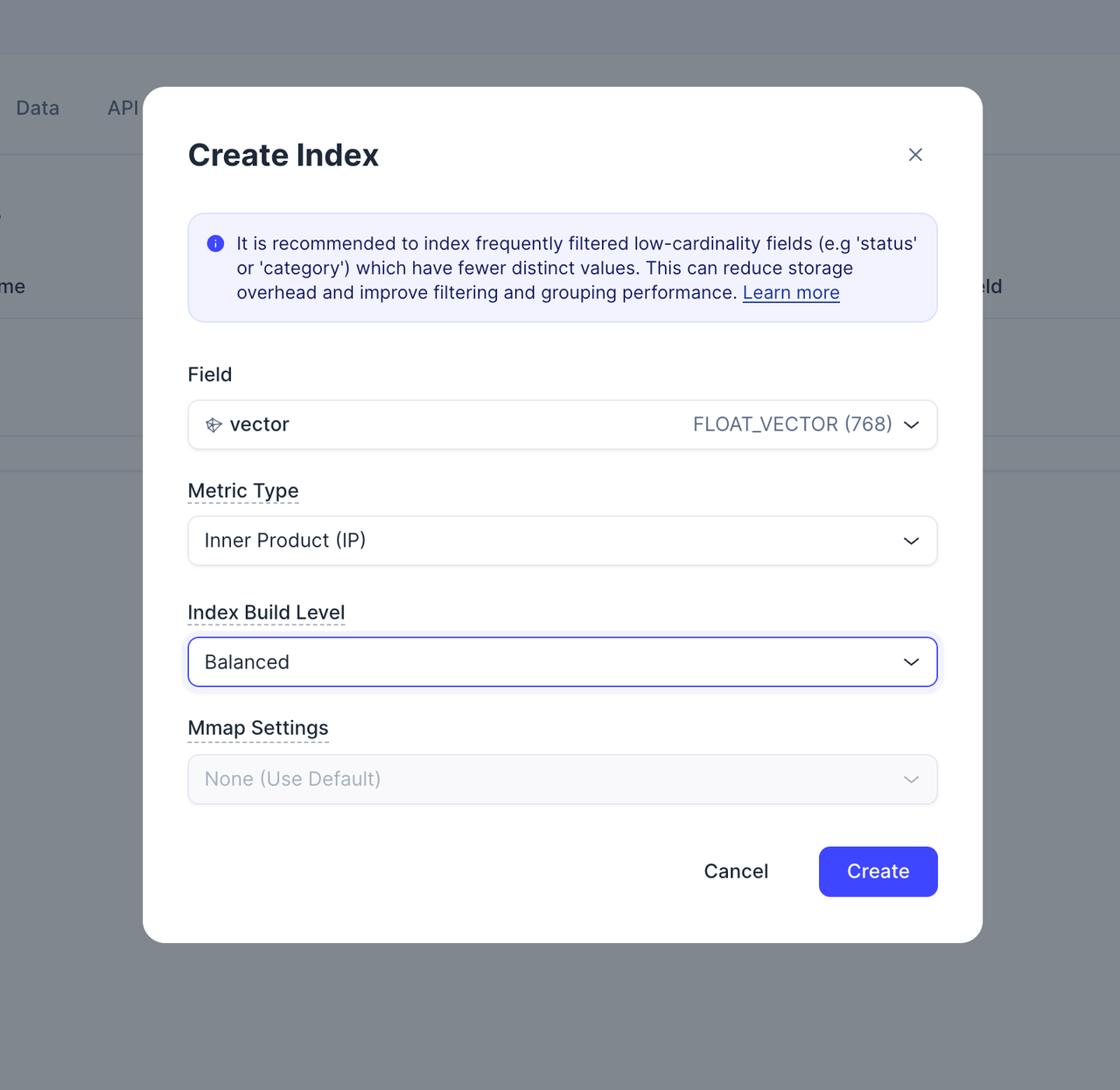
Perform Load Collection to preview the data.
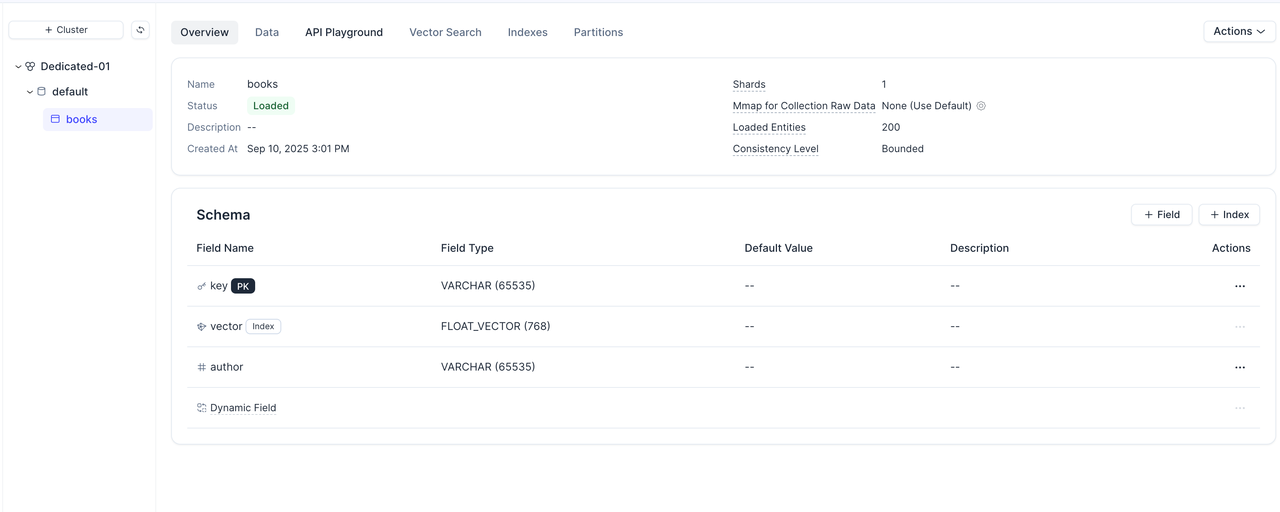
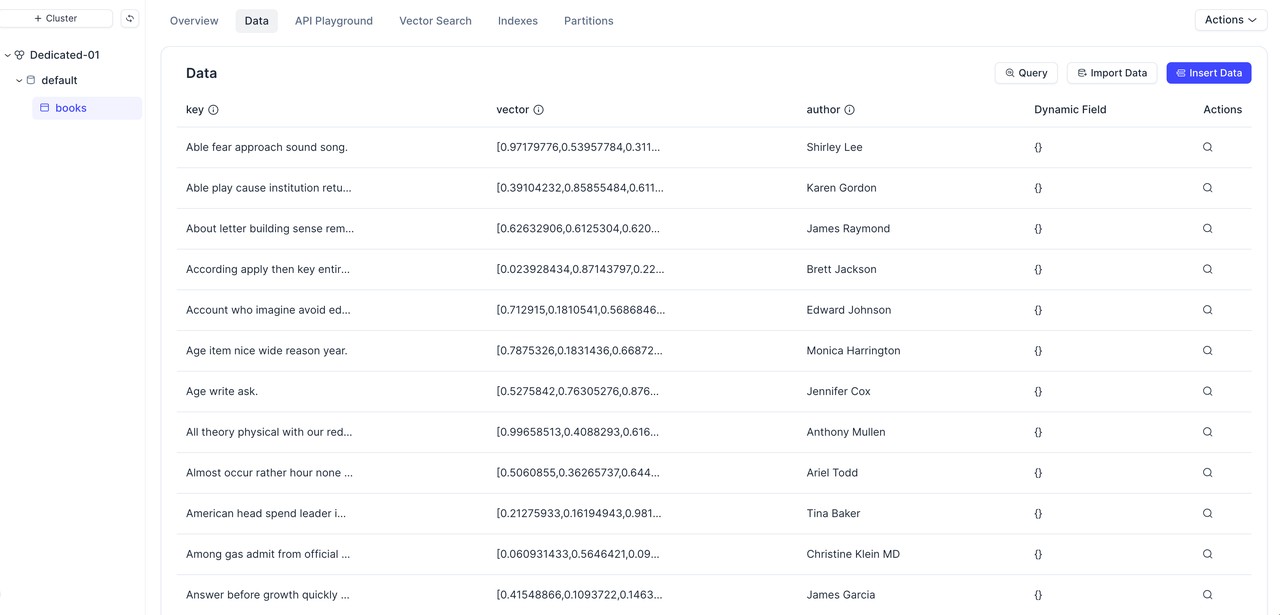
You should see that the number of records and their content exactly match those from S3 Vectors, confirming a successful migration.
Wrapping Up
S3 Vectors keeps costs low by storing embeddings in object storage — but it falls short on performance, recall, and enterprise features. Zilliz Cloud takes that same idea further, maintaining the cost advantage while adding the speed, flexibility, and reliability that real AI applications need.
For developers, this means you no longer have to choose between affordability and performance. You can scale to billions of vectors, serve active workloads from fast tiers, and still keep cold data cost-efficiently in object storage — all in one managed platform.
If you’re currently using S3 Vectors, migration takes just a few steps, and you’ll immediately see the benefits in query speed and operational simplicity. Try it out, benchmark it with your own data, and see how Zilliz Cloud changes what’s possible with large-scale vector search.
Experience Zilliz Cloud Yourself
Still not sure if Zilliz Cloud is the right fit? Sign up for free and get $100 in credits to explore the world’s leading managed vector database firsthand.
Already using another vector database? Zilliz Cloud supports seamless migration from Pinecone, Qdrant, Elasticsearch, PostgreSQL, OpenSearch, Weaviate, and even on-prem Milvus — so you can move your data with zero hassle.
If you have any future questions about migration, check our documentation or contact us—we’re here to help you get the most out of Zilliz Cloud.

Keep Reading

Introducing Zilliz Cloud Global Cluster: Region-Level Resilience for Mission-Critical AI
Zilliz Cloud Global Cluster delivers multi-region resilience, automatic failover, and fast global AI search with built-in security and compliance.

Context Engineering Strategies for AI Agents: A Developer’s Guide
Learn practical context engineering strategies for AI agents. Explore frameworks, tools, and techniques to improve reliability, efficiency, and cost.

Proactive Monitoring for Vector Database: Zilliz Cloud Integrates with Datadog
we're excited to announce Zilliz Cloud's integration with Datadog, enabling comprehensive monitoring and observability for your vectorDB deployments.