




動的スキーマとは何か?
*この投稿はYujian TangとZhenshan Caoの共同執筆によるものです。
すべてのデータベースにはスキーマがあるが、すべてが動的というわけではない。SQLデータベースにはあらかじめ定義されたスキーマがあり、通常は変更されません。データベースを作成するとき、各テーブルをどのように見せたいかをデータベースに伝え、各エントリーがそのテーブルのスキーマに適合するように強制する。NoSQLデータベースは通常、動的スキーマを持つ(あるいはスキーマレスにすることもできる)。データベースを作成する際に、各オブジェクトの属性を定義する必要はありません。
Milvus](https://zilliz.com/what-is-milvus)ベクトル・データベースの場合、ダイナミック・スキーマとは、データを追加すると変化するスキーマのことだ。例えば、動的スキーマをサポートするということは、NoSQLデータベースと同じようにデータ入力を扱い、JSON形式でデータを追加できるということです。以前のMilvusでは、スキーマは厳密に強制されていました。数ヶ月前にMilvus 2.2.9で動的スキーマオプションをリリースし、簡単に実装できるようにしました。
この記事では
- データベーススキーマとは?
- ベクターデータベーススキーマとは?
- Milvus Vector Databaseで動的スキーマを使用する方法
- Milvusにおける動的スキーマの実装方法
動的スキーマの長所と短所
ベクターデータベースにおける動的スキーマの概要
データベーススキーマとは?
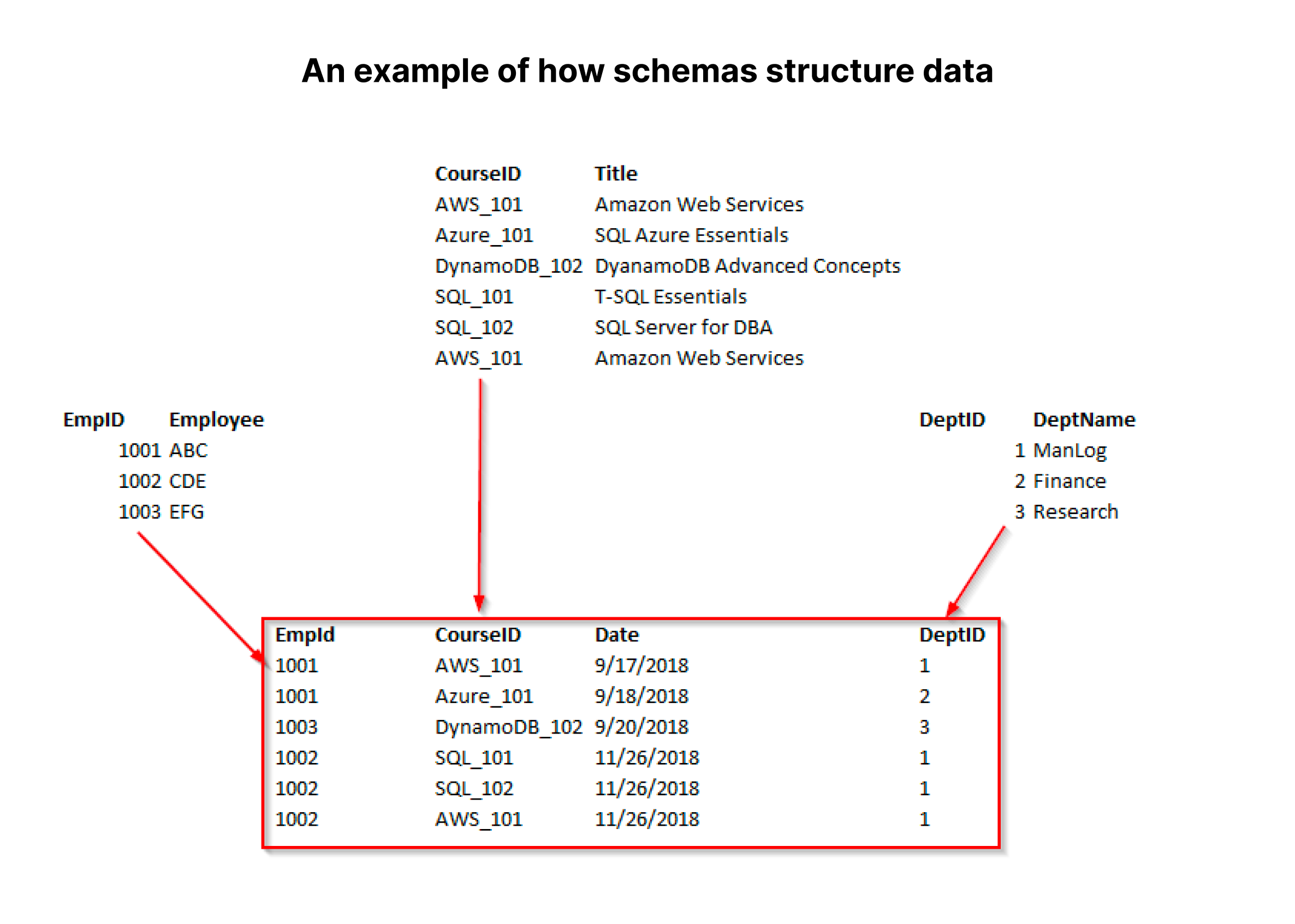
スキーマは、データベースにどのようにデータを挿入し、保持するかを構造化します。上の例は、リレーショナル・データベース用に正規化されたデータベース・スキーマを作成する方法を示しています。上の例では、中央のテーブルには4つのカラムがあります。このデータベースは4つのテーブルと各テーブルのスキーマを持つことになります。
3つのテーブルには2列のスキーマがあり、中央のテーブルには4列のスキーマがあります。カラムのスキーマにはデータ定義も含まれる。Employee"、"Title"、"DeptName "カラムはすべて文字列、またはVARCHARになります。ほとんどの場合、"CourseID "もそうでしょう。「EmpID "と "DeptID "は整数で、"Date "は日付型かVARCHAR型になるでしょう。
ベクトルデータベーススキーマとは?
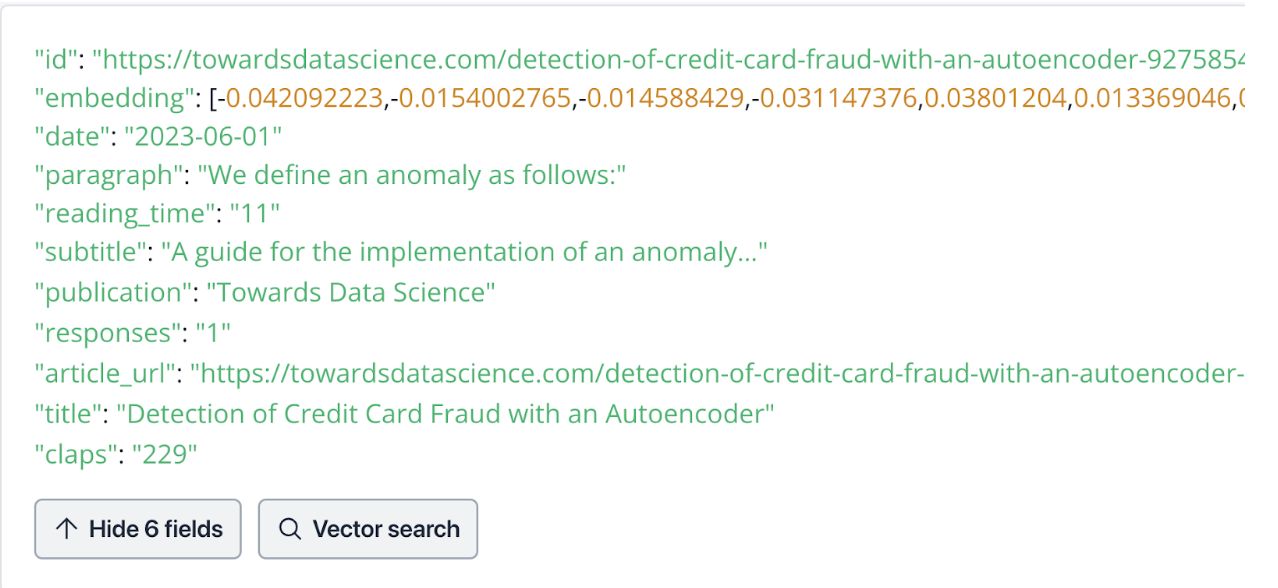
下の画像は、私がChat Towards Data Scienceプロジェクトで使用している、MilvusのフルマネージドベクトルデータベースサービスであるZillizのインスタンスへのエントリです。リレーショナルデータベースのスキーマのように定義すると、11のカラムがあります。id"、"paragraph"、"subtitle"、"publication"、"article_url"、"title "の6つの文字列またはVARCHARカラムがある。残りの5つのカラムのうち3つはINTデータ型である。"reading_time"、"respons"、"claps "である。残りの2列は、DATE型の "date "と、埋め込みベクトルである "FLOAT_VECTOR "と呼ばれるものである。
Milvusベクトルデータベースでダイナミックスキーマを使うには?
Milvusは、パフォーマンス、スケーラビリティ、および信頼性のために構築された人気のあるオープンソースのベクトルデータベースです。数ヶ月前にMilvus 2.2.9でダイナミックスキーマオプションをリリースし、簡単に実装できるようにしました。
以下のコード・スニペットは、Milvusの動的スキーマ機能を有効にして利用する方法と、動的フィールドにデータを挿入してフィルタリング検索を実行する方法を示しています。
from pymilvus import (
connections、
FieldSchema, CollectionSchema, DataType、
コレクション、
)
DIMENSION = 8
COLLECTION_NAME = "books"
connections.connect("default", host="localhost", port="19530")
fields = [
FieldSchema(name='id', dtype=DataType.INT64, is_primary=True)、
FieldSchema(name='title', dtype=DataType.VARCHAR, max_length=200)、
FieldSchema(name='embeddings',dtype=DataType.FLOAT_VECTOR,dim=DIMENSION)。
]
schema = CollectionSchema(fields=fields, enable_dynamic_field=True)
コレクション = コレクション(name=COLLECTION_NAME, schema=schema)
data_rows = [
{"id":1, "title":「蝿の王
"embeddings":[0.64, 0.44, 0.13, 0.47, 0.74, 0.03, 0.32, 0.6],
"isbn":"978-0399501487"},
{"id":2, "title":「グレート・ギャツビー
"embeddings":[0.9, 0.45, 0.18, 0.43, 0.4, 0.4, 0.7, 0.24],
"author":「F. Scott Fitzgerald"}である、
{"id":3, "title": "ライ麦畑でつかまえて":「ライ麦畑でつかまえて』、
"embeddings":[0.43, 0.57, 0.43, 0.88, 0.84, 0.69, 0.27, 0.98],
"claps":100},
]
collection.insert(data_rows)
collection.create_index("embeddings", {"index_type": "FLAT", "metric_type": "L2"})
collection.load()
vector_to_search = [0.57, 0.94, 0.19, 0.38, 0.32, 0.28, 0.61, 0.07].
result = collection.search(
data=[vector_to_search]、
anns_field="embeddings"、
param={}、
limit=3、
expr="claps > 30 || title =='The Great Gatsby'"、
output_fields=["title", "author", "claps", "isbn"]、
consistency_level="Strong")
for hits in result:
for hit in hits:
print(hit.to_dict())
作成されたコレクション "books "では、3つのフィールドを持つスキーマを定義する:id、title、embeddingsである。id は主キーであり、各行の一意な識別子である。titleはVARCHAR` 型の書籍名を表し、embedding は 8 次元のベクトル列である。この投稿では、デモのためにベクトルデータをランダムにセットしている。
schema = CollectionSchema(fields=fields, enable_dynamic_field=True)
コレクション = コレクション(name=COLLECTION_NAME, schema=schema)
定義時に CollectionSchema オブジェクトにフィールドを渡すことで、動的スキーマを有効にします。ここでは、enable_dynamic_field スキーマを追加して True に設定するだけである。
data_rows = [
{"id":1, "title":「蝿の王
"embeddings":[0.64, 0.44, 0.13, 0.47, 0.74, 0.03, 0.32, 0.6],
"isbn":"978-0399501487"},
{"id":2, "title":「グレート・ギャツビー
"embeddings":[0.9, 0.45, 0.18, 0.43, 0.4, 0.4, 0.7, 0.24],
"author":「F. Scott Fitzgerald"}である、
{"id":3, "title": "ライ麦畑でつかまえて":「ライ麦畑でつかまえて』、
"embeddings":[0.43, 0.57, 0.43, 0.88, 0.84, 0.69, 0.27, 0.98],
"claps":100},
]
上記のコードでは、3行のデータを挿入している。id=1のデータには動的フィールドisbnが含まれ、id=2のデータにはauthorが含まれ、id=3のデータには claps が含まれる。これらの動的フィールドは、文字列型(isbn と author)と整数型(claps)の異なる型を持っている。
result = collection.search(
data=[vector_to_search]、
anns_field="embeddings"、
param={}、
limit=3、
expr="claps > 30 || title =='The Great Gatsby'"、
output_fields=["title", "author", "claps", "isbn"]、
consistency_level="Strong")
上記のコードでは、ANNS(近似最近傍)検索とダイナミックフィールドに基づくフィルタリングを組み合わせたハイブリッド検索を実行しています。このクエリは expr パラメータで指定された条件を満たす行からデータを取得することを目的としている。出力されるデータには、title, author, claps, isbn フィールドが含まれる。exprパラメータでは、スキーマフィールド (title) と動的フィールド (claps`) に基づくフィルタリングを行うことができる。
コードを実行した後の出力結果は以下のようになる:
{'id': 2, 'distance':0.40939998626708984, 'entity':{'title':'title': 'The Great Gatsby', 'author': 'F. Scott Fitzgerald'}}.Scott Fitzgerald'}}。
{'id':3, 'distance':1.8463000059127808, 'entity':{'title':'title': 'The Catcher in the Rye', 'claps':100}}
動的スキーマ機能はどのように実装されていますか?
Milvusカーネルでは、非表示のメタカラムを使用して、各行のデータに異なる名前とデータ型を持つダイナミックフィールドを追加することができます。ユーザがテーブルを作成して動的フィールドを有効にすると、$metaという名前の隠しカラムがテーブルと一緒に作成される。この隠しカラムはデータ型として JSON を使用する。JSON は言語に依存しないデータ形式で、最新のプログラミング言語では JSON 形式のデータの生成と解析が広くサポートされているからである。
Milvusはデータを列構造で整理する。挿入時、各行のダイナミックフィールドのデータは1つのJSONデータにパッケージされ、すべてのJSONデータの行を合わせて隠しカラム $meta を形成する。
動的スキーマの長所と短所は?
動的スキーマには長所と短所があり、データモデリングにおけるさまざまなニーズに対応します。
長所
- 動的スキーマはセットアップが簡単なので、複雑な設定を必要とせず、幅広いユーザーがアクセスできる。
- 動的スキーマは時間の経過によるデータモデルの変更に対応するため、開発者は大幅な再構築をすることなく調整できる。
短所
- 動的スキーマによるフィルター検索は、固定スキーマよりもはるかに遅い。
- 動的スキーマへの一括挿入は複雑。
これらの課題に対処するため、Milvusはフィルタリング検索の効率を高めるベクトル化実行モデルを統合しました。ベクトル化された実行モデルは、呼び出された演算子を通して一度に一行のデータを処理する従来のボルケーノモデルとは対照的に、データのバッチ全体を同時に処理します。このコンピューティング・パラダイムは、計算中のデータ局所性を最適化し、システム全体のパフォーマンスを大幅に向上させる。
今後の展望として、Milvus 2.4では引き続きスカラーインデックス機能を強化する予定です。この機能強化の目的は、静的フィールドと動的フィールドに対する転置インデックスによるフィルタリング検索の高速化であり、動的スキーマの管理とクエリにおける性能と効率の向上を約束します。
ベクターデータベースの動的スキーマの概要
この記事では、データベースのスキーマについて見てきました。スキーマをよりよく理解するために、リレーショナルデータベースのスキーマの例を使いました。リレーショナルデータベースには、定義しなければならない厳格なスキーマがあります。スキーマは定義されたフィールドを持ち、フィールドは定義されたデータ型を持たなければなりません。Milvusのスキーマはこのように強制されていた。
しかし、実際にはMilvusは2つのフィールドがどのように定義されているかを知る必要があるだけである。ひとつはエントリーのID、もうひとつは埋め込みフィールドです。残りのフィールドは定義する必要はありませんが、定義することは可能です。enable_dynamic_field`パラメータを使って渡される動的スキーマの導入により、Milvusは他のフィールドを定義する必要がなくなった。
動的スキーマは両刃の剣であり、セットアップの容易さ、柔軟性、効率性を提供しますが、トレードオフがないわけではありません。たとえば、動的スキーマを使ったフィルタリング検索は固定スキーマよりも遅く、動的スキーマへの一括挿入はより複雑です。Milvusはベクトル化された実行モデルを利用して動的スキーマに伴う課題に対処し、システム全体のパフォーマンスを最適化します。また、Milvus 2.4ではスカラーインデックス機能を強化し、動的スキーマの管理とクエリのパフォーマンスと効率を向上させます。

読み続けて

Introducing Zilliz CLI and Agent Skills for Zilliz Cloud
Manage your vector database from your terminal or AI coding agent. Zilliz CLI and Agent Skills work with Claude Code, Cursor, Codex, and Copilot.

Why AI Databases Don't Need SQL
Whether you like it or not, here's the truth: SQL is destined for decline in the era of AI.

Why DeepSeek V3 is Taking the AI World by Storm: A Developer’s Perspective
Explore how DeepSeek V3 achieves GPT-4 level performance at fraction of the cost. Learn about MLA, MoE, and MTP innovations driving this open-source breakthrough.