




本番への道:LLMアプリケーションの評価と観測可能性
多くの機械学習チームが大規模言語モデル(LLMs))を実運用に導入する準備を進める中で、幻覚への対処や責任ある導入の確保といった大きな課題に直面している。これらの問題に取り組む前に、それらを効果的に評価し、特定することが極めて重要である。
最近、Unstructured Data Meetupで、Arize AIのMLソリューションアーキテクトであるHakan Tekgulは、迅速かつ正確なLLM評価を行うための洞察に満ちた戦略を共有した。これらのアプローチは、高い回答品質と信頼性基準を維持し、具体的なビジネス価値の提供を保証します。
[Hakan Tekgulのリプレイを見る】(https://www.youtube.com/watch?v=42wZa3NasoM&t=3327s)
イベントを見逃した方もご安心ください!ハカンのプレゼンテーションの詳細な内訳はこちらです。
GenAIデモを本番に移行するのは難しい!
LangChain](https://zilliz.com/blog/building-open-source-chatbot-using-milvus-and-langchain-in-5-minutes)やLlamaIndexのようなデモアプリケーションの作成を容易にするユーザーフレンドリーなツールを使えば、GenAIアプリケーションの構築は当初は簡単に見えるかもしれません。しかし、具体的なビジネス価値を推進できる本格的な製品に移行するのは難しい。肝心なのは、これらのアプリケーションが本番環境で一貫して信頼できる高品質の出力を提供することを保証することである。
Twitterのデモから実世界の製品に移行するのはどのようなものか](https://assets.zilliz.com/What_is_it_like_to_transition_from_a_Twitter_demo_to_a_real_world_product_ecbaaf2c6e.png)
eコマースのチャットボットの例でこの課題を説明しよう。ユーザーは休暇を計画するためにこのチャットボットと対話します。
Eコマースチャットボットのインターフェース](https://assets.zilliz.com/The_interface_of_the_e_commerce_chatbot_cb1db3bfd0.png)
このアプリケーションはユーザーから見るとシンプルに見えるかもしれないが、舞台裏のワークフローは複雑である。以下は、このワークフローの主なステップである:
チャット開始:** ユーザーはチャットボットと対話することでセッションを開始します。
パラメータ抽出**:LLMはユーザーの入力から構造化されたパラメータを抽出します。
ランキング/推奨**:モデルは、抽出されたパラメータに基づいて、潜在的な休暇先のリストを生成します。
検索と検索の組み込み**:システムは、より関連性の高い情報のためにベクトル検索を実行することによってリストを絞り込む。
レスポンスの生成:*** LLMは、検索されたデータに基づいてパーソナライズされたレスポンスを生成します。
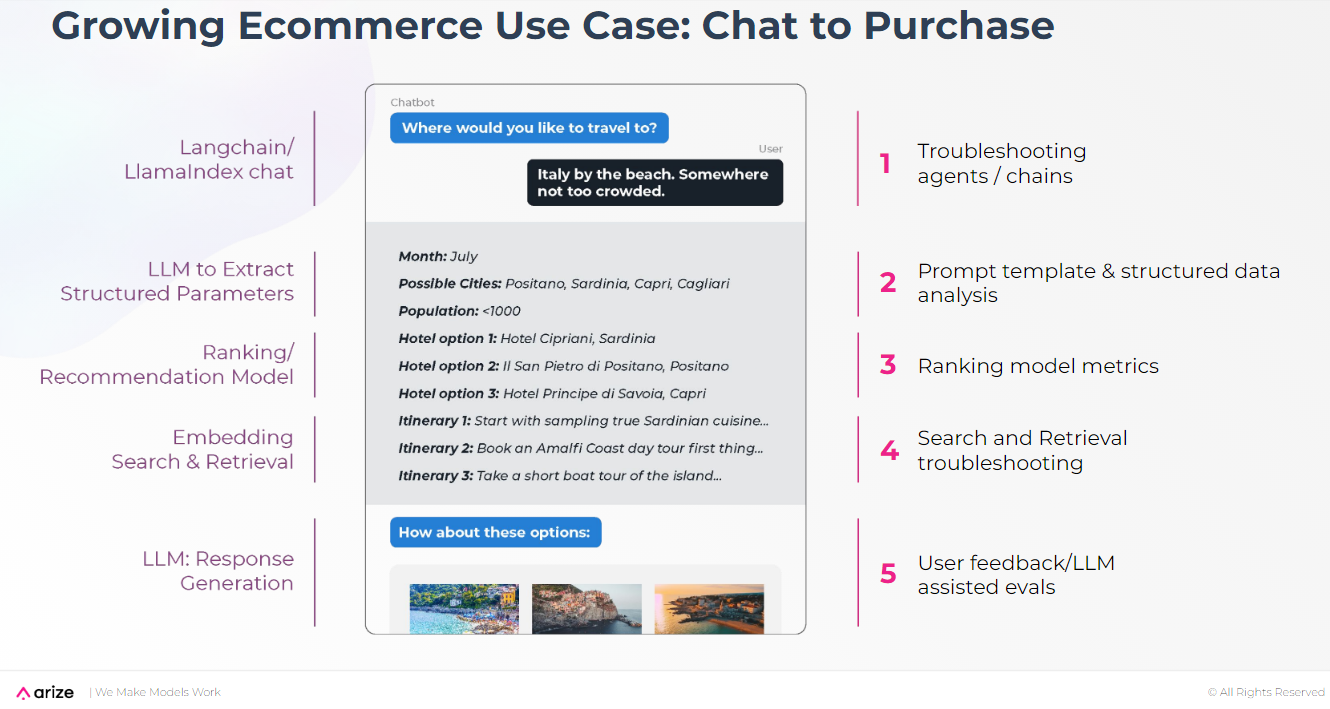 チャットボットのワークフローにおける主要ステップと潜在的なトラブルシューティング戦略
チャットボットのワークフローにおける主要ステップと潜在的なトラブルシューティング戦略
このワークフローの各ステップでは、特定の問題が発生する可能性があります。効果的なトラブルシューティングは、シームレスなユーザーエクスペリエンスと最適なパフォーマンスを確保するために不可欠です。例えば、次のようなことが必要になるかもしれません:
LangChainやLlamaIndexのようなツールがエラーなくスムーズに動作するようにする。
ユーザーの入力から正確にデータを抽出するためのプロンプトを作成し、改良する。
推薦システムを継続的に評価し、最適化する。
検索された情報の正確性と関連性を高める。
システム全体および各コンポーネントのトラブルシューティング
システムの継続的な改良と強化のためにフィードバックを活用する。
LLM Observability Comes to the Rescue!
前述の課題に取り組むには、LLMのシームレスな観測性を実現する評価ツールを活用することが重要です。アプリケーションの完全な可視性を保証するためには、LLMの可観測性に関する5つの主要な側面に注意を払う必要がある。これらの評価を巧みに行うことで、チームはアプリケーションの全体的な観測を実現し、信頼性と最適なパフォーマンスを確保することができます。
| LLM観測可能性の5つの柱 | |||
| 柱** | 説明 | 共通の課題 | 評価 |
| 評価|別個の評価LLMを用いたLLM出力の体系的な評価|出力の品質と整合性 | |||
| スパンとトレース|ワークフローのブレイクダウンの詳細な可視化|特定の故障箇所の特定 | |||
| プロンプト・エンジニアリング|プロンプト・テンプレートの反復的な改良による結果の改善|レスポンスの正確性と関連性の向上 | |||
| サーチ&リトリーバル|検索されたコンテキストの特定と改善|検索精度の向上 | |||
| ファインチューニング|LLMを特定のデータで再トレーニングし、カスタマイズされたパフォーマンスを実現|ビジネス固有のニーズに合わせる |
以下のセクションでは、「LLM評価」と「LLMスパンとトレース」カテゴリーをさらに詳しく調べ、LLMの観測可能性を最適化する上での重要性を強調します。
LLM 評価
LLM評価(LLM Evals)とは、別のLLMを「裁判官」として使ってGenAIアプリケーションの出力を系統的に評価することを指します 定期的な評価は、生成されたコンテンツが品質基準を満たし、ユーザーの期待を満たすことを保証します。例えば、休暇提案サービスでは、推奨を定期的にレビューするために評価LLMを採用しています。この評価システムは、推薦文が古くなったり無関係になったりした場合に、学習データを更新するためのレビュープロセスをトリガーする。
モデル評価とLLM評価の比較
詳細を掘り下げる前に、2つの類似したコンセプト、モデル・エヴァルとLLMエヴァルを比較してみよう。
モデル・エヴァル**は、アプリケーションの基盤となるモデルを選択し、それが一般的なユースケースに合致していることを確認するのに役立ちます。
LLMエバリュエーションは、LLMベースのアプリケーション内の特定のタスクやコンポーネントのパフォーマンスを測定します。LLM 評価には、検索、幻覚、ユーザーのフラストレーション、Q&A、要約、コード生成の評価が含まれます。
本番LLM評価-タスクパフォーマンス測定|Arize](https://assets.zilliz.com/Production_LLM_Evals_Task_Performance_Measurement_Arize_6b0b696160.png)
LLMエバルの仕組み
ジャッジLLMを使った大規模言語モデル(LLM)の性能評価は複雑に見えるかもしれませんが、適切なツールと方法論があればはるかに管理しやすくなります。Phoenix LLM Evals library](https://docs.arize.com/phoenix/evaluation/llm-evals)は、LLMの評価を迅速かつ簡単に行えるように設計されたオープンソースのツールです。このライブラリは、ジャッジLLM、評価テンプレート、モデルパラメータをまとまりのあるフレームワークに統合しています。
このプロセスはどのように機能するのでしょうか?入力データは、LLMアプリケーションによって生成された出力データとともにPhoenixライブラリに入力されます。ライブラリ内のジャッジLLMは、この入力データと出力データ、およびプロンプトテンプレートを使用して、特定のタスクに対するシステムのパフォーマンスを評価します。
 LLM評価-一般的な仕組み
LLM評価-一般的な仕組み
評価プロセスを見てみよう。Milvus](https://zilliz.com/what-is-milvus)のようなベクトルデータベースからコンテキストを検索し、ユーザーの質問と検索されたコンテキストに基づいて応答を生成する、検索拡張生成(RAG)アプリケーションを考えてみましょう。
RAG検索タスクのパフォーマンスを測定する場合、入力データ(ユーザの質問)と出力データ(参照テキスト)がPhoenixライブラリに入力される。Judge LLM は、Eval Template を使用して、参照テキストがユーザの質問にどの程度回答しているかを評価する。例えば、ユーザの質問が「フランスの伝統的なレシピを探す」であり、参照テキストが「キャラメリゼ・オニオン・ブレッド・スープ」のレシピを提供する場合、Eval Template はこの 2 つを比較して関連性を評価する。
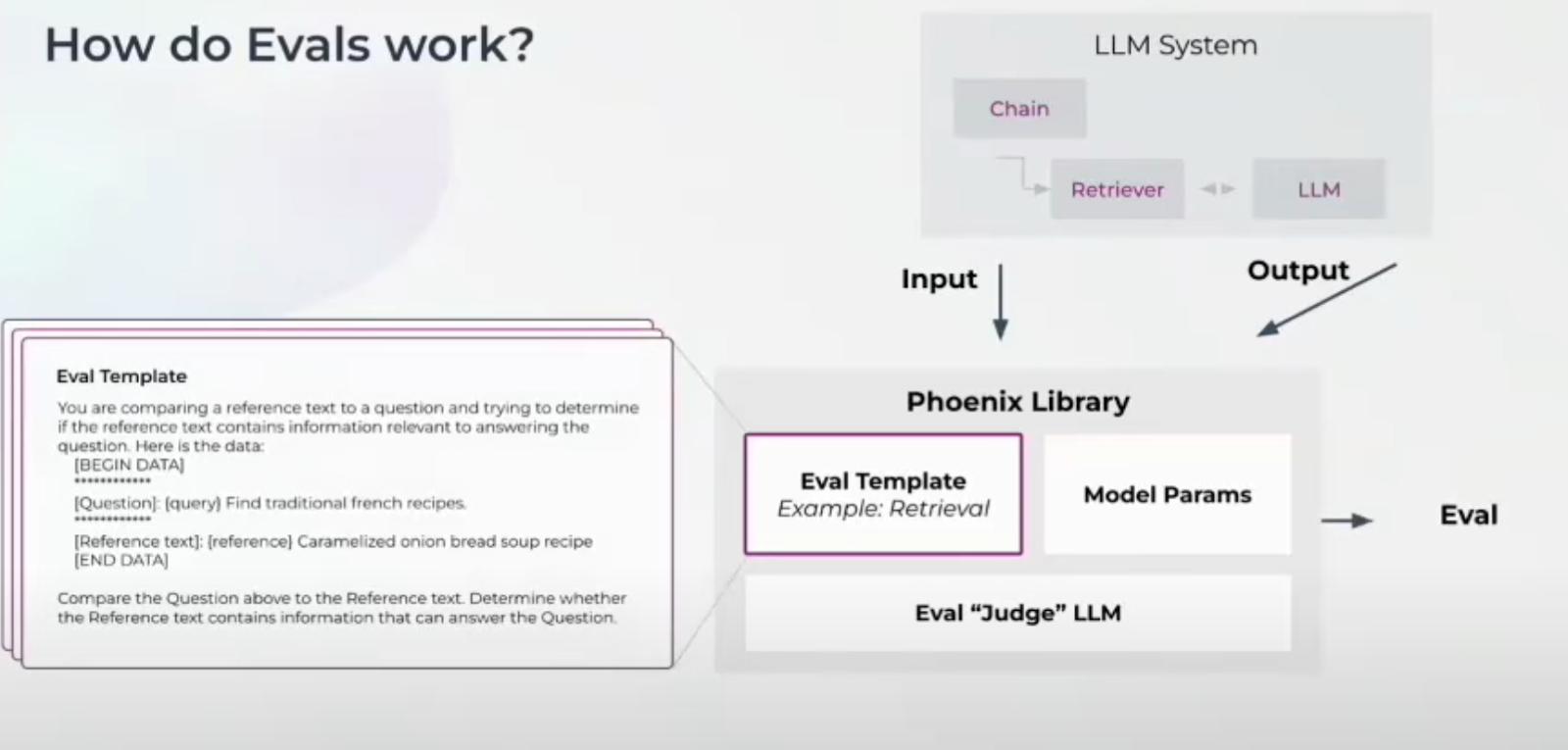 LLM評価- RAGユースケースでの動作
LLM評価- RAGユースケースでの動作
LLM評価結果のベンチマーク
LLM評価プロセスがどのように機能するかについて説明しましたが、あなたの特定のユースケースに効果的であると確信するにはどうすればよいでしょうか?その答えは、評価結果のベンチマークにあります。
以下は、結果をベンチマークするための主なステップです。
まず、私たちは人間がラベル付けした回答を含む公開データセットを利用します。これらのデータセットは、関連性を示す注釈が付いたユーザーの質問と参照テキストで構成されています。これらの確立されたデータセットにより、比較のための強固な基盤を確立します。
次に、私たちのプロンプトテンプレートの性能を、これらの公開データセットで人間が提供した回答と比較する。このステップにより、人間の判断をベンチマークとして、我々のテンプレートがどの程度適切な回答を識別できるかを評価することができる。
最後に、プロンプトテンプレートのパフォーマンスを定量化するために、精度とリコールのスコアを計算する。精度はRAGシステムによって返された関連する結果の正確さを測定し、想起はシステムがすべての関連するインスタンスを検索する能力を測定する。
これらの精度と想起のスコアは、プロンプトテンプレートが人間によってラベル付けされたさまざまな例に対してどの程度効果的に機能するかを示している。このベンチマークプロセスにより、評価およびプロンプトテンプレートの信頼性が保証され、LLMアプリケーションのパフォーマンスを評価する際に信頼することができます。
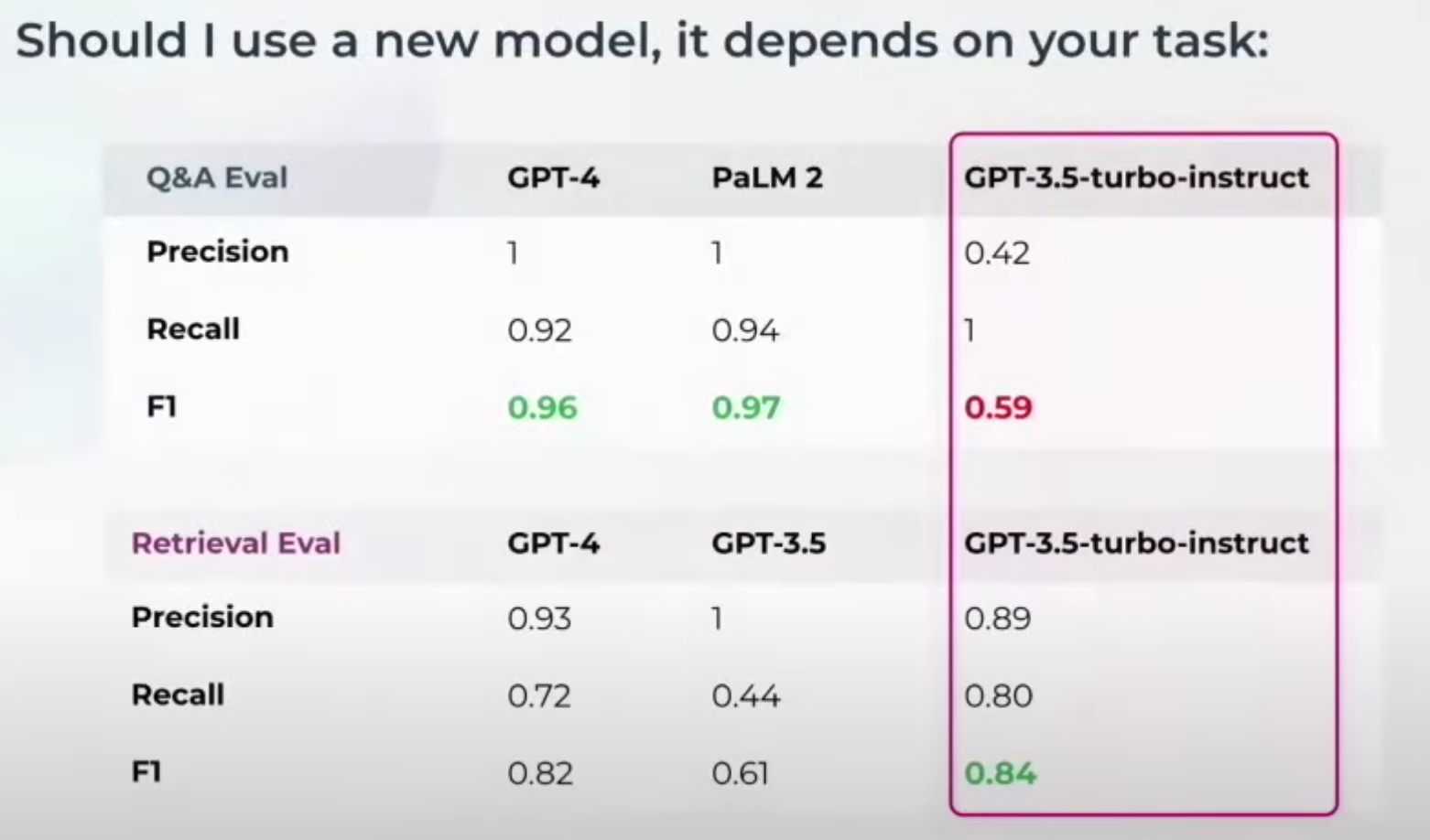
これらの測定の後、Judge LLMに使用するモデルを決定します。タスクが異なれば、異なるジャッジ・モデルが必要になるかもしれません。例えば、GPT-3.5-turbo-instruct は、Q&A の正しさの評価では良い結果を出せないかもしれないが、検索 の評価では素晴らしい結果を出すかもしれない。他のものを評価する場合は、基礎モデルを切り替える必要があるかもしれない。これがベンチマークが重要な理由だ。
これらの測定の後、次のステップはどのモデルを判定LLMに使用するかを決定することです。異なるタスクは異なるジャッジ・モデルを必要とするかもしれません。例えば、GPT-3.5-turbo-instruct は、Q&A の正しさの評価ではうまくいかないかもしれないが、検索 の評価では優れているかもしれない。異なる側面を評価するために、基礎モデルを切り替える必要があるかもしれない。このような柔軟性が、ベンチマークが重要な理由である。
LLM スパンとトレース
さて、LLMアプリケーションを全体として評価する方法を学びました。しかし、コンポーネントごとにアプリケーションのインタラクションを評価するにはどうしたらいいでしょうか?LamaIndexやLangChainのようなフレームワークで構築された検索システムのフルチェーンを考えてみましょう。Q&A評価が間違った答えを示した場合、インタラクションが失敗したことがわかりますが、まだどこを特定する必要があります。ここで、LLMスパンとトレースの概念が登場する。
様々なタイプのスパン評価により、失敗を特定することができる。例えば
チャットボットのインタラクションをチェックするためのユーザーのフラストレーション評価
属性抽出時の分類評価
検索コンポーネントを評価するための検索評価
分類プロセスのための分類評価
LLMスパンの評価](https://assets.zilliz.com/Evals_on_LLM_Spans_e909c44dd2.png)
検索評価に問題があれば、Q&Aの正しさに直接影響する。LLMスパンとトレースは、アプリケーション内のこれらの問題を可視化し、診断するのに役立つ。
Hakan氏はまた、LLM Spans and Tracesがどのように機能するかを紹介するデモを披露した。デモの詳細を見るには、YouTubeで彼のトークのリプレイを見てください。
結論
Hakan Tekgul氏の講演を振り返ると、LLMを本番環境に導入することは並大抵のことではないことがわかる。洗練されたデモから信頼性の高い、ビジネスで使えるアプリケーションになるまでの道のりには、細部にまで注意を払い、堅牢な観測可能性フレームワークを必要とする課題が山積している。
Hakan氏は、2つの主要なLLM評価戦略、LLM評価とLLMスパンとトレースを共有し、詳細な例を用いてそれらがどのように機能するかを説明した。これらのストラテジーは、LLMアプリケーションを体系的に評価し、実際のユースケースにおける信頼性と有効性を保証します。

読み続けて

We spent 8 years making vector databases faster. Then we stopped.
Rarely queried embeddings still need to stay searchable. See how Vector Lakebase enables on-demand vector search without always-on compute costs.

The Great AI Agent Protocol Race: Function Calling vs. MCP vs. A2A
Compare Function Calling, MCP, and A2A protocols for AI agents. Learn which standard best fits your development needs and future-proof your applications.

1 Table = 1000 Words? Foundation Models for Tabular Data
TableGPT2 automates tabular data insights, overcoming schema variability, while Milvus accelerates vector search for efficient, scalable decision-making.