




Mistral Large、Mistral Nemo、Llamaエージェントによるマルチエージェントシステムの最適化
エージェント・システムは増加傾向にあり、開発者が知的で自律的なシステムを作るのに役立っている。大規模言語モデル (LLMs)は、多様な命令セットに従うことができるようになってきており、これらのエージェントを管理するのに理想的である。この進歩は、非常に多くの分野で、人間の介入を最小限に抑えて複雑なタスクを処理するための多くの可能性を開く。例えば、エージェント・システムは、顧客からの問い合わせに対応し、問題を解決し、顧客の嗜好に基づいて商品をアップセルすることもできる。
この投稿では、llama-agents と Mistral LLMs と Milvus を組み合わせて、インテリジェントエージェントを構築するための包括的なガイドを提供します。コスト効率の良いタスク実行のためのMistral Nemo、洗練されたオーケストレーションのためのMistral Large、効率的なベクトルデータの保存と検索のためのMilvusの活用方法を学びます。金融ドキュメントの分析やメタデータフィルタリングの実装など、スケーラブルでダイナミックなエージェントシステムを構築するための実践的な例を探ります。詳細なコード例とステップバイステップの指示に従って、あなた自身の強力なエージェントを構築してください。
フォローアロング
私はこのチュートリアルをウェビナーで説明しました。
Llamaエージェント、Ollama & Mistral Nemo、Milvus Liteの紹介
Llama-agents**はLlamaIndexを拡張したもので、LLMを使った堅牢でステートフルなマルチアクターアプリケーションを構築するためのものです。
Ollama & Mistral Nemo** - Ollamaは、Mistral Nemoのような大規模な言語モデルをローカルで実行できるAIツールです。これにより、常時インターネットに接続したり、外部サーバーに依存したりすることなく、自分の好きなようにこれらのモデルを扱うことができます。
Milvus Lite**](https://milvus.io/blog/introducing-milvus-lite.md)は、ラップトップ、Jupyter Notebook、Google Colab上で動作するMilvusのローカルで軽量なバージョンです。非構造化データ](https://zilliz.com/glossary/unstructured-data)を効率的に保存・検索することができます。
Llamaエージェントの仕組み
LlamaIndexによって開発されたLlama-agentsは、マルチエージェントコミュニケーション、分散ツール実行、ヒューマンインザループなどを含むマルチエージェントシステムを構築、反復、プロダクション化するための非同期ファーストフレームワークです!
Llama-agentsでは、各エージェントは入ってくるタスクをエンドレスに処理するサービスとみなされます。各エージェントはメッセージキューからメッセージを取り出し、公開します。
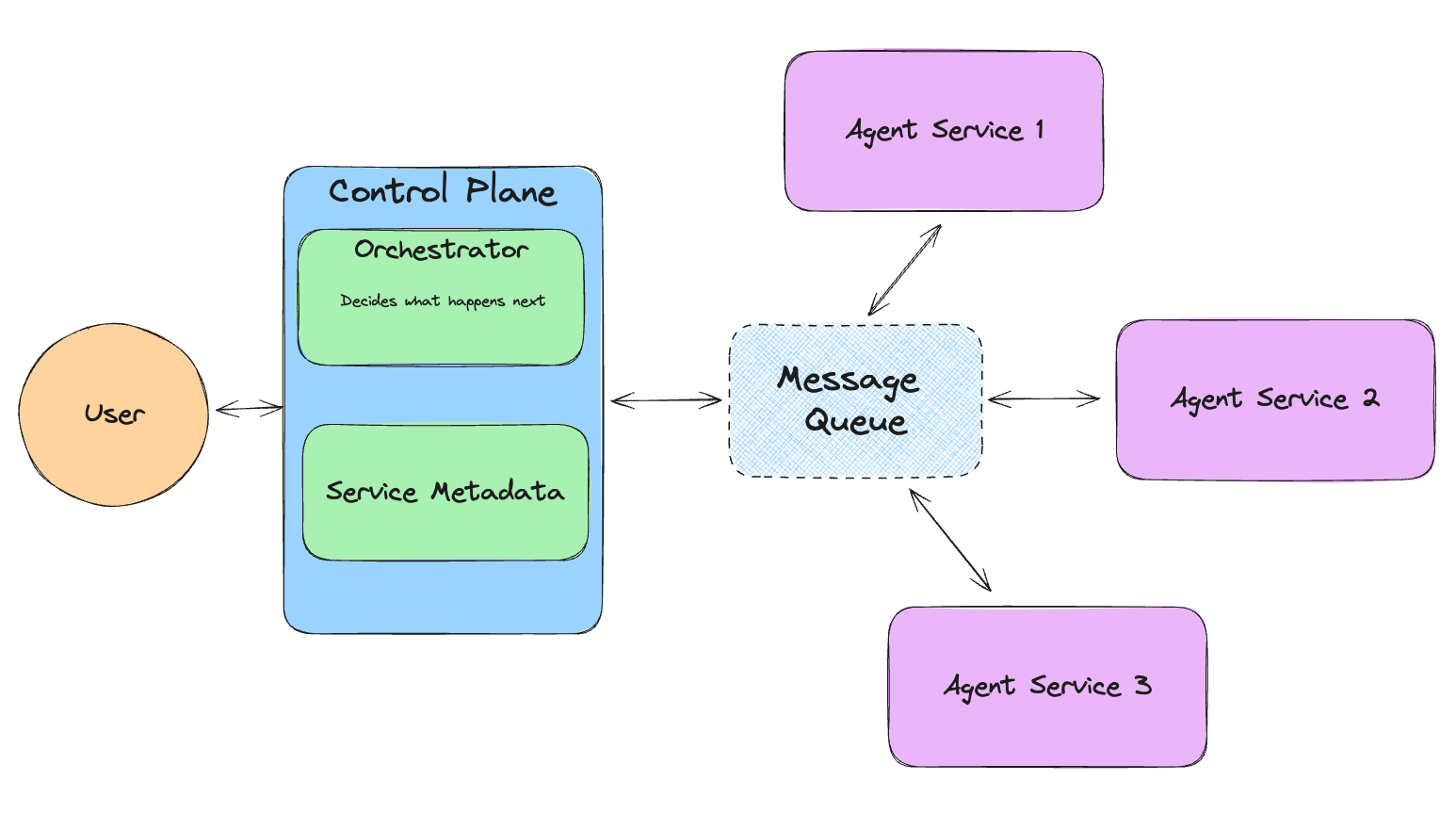 図- Llama-エージェントの仕組み.png
図- Llama-エージェントの仕組み.png
図:Llama エージェントの仕組み
依存関係のインストール
まずは必要な依存関係をすべてインストールしましょう。
pip install llama-agents pymilvus python-dotenv
pip install llama-index-vector-stores-milvus llama-index-readers-file llama-index-embeddings-huggingface llama-index-llms-ollama llama-index-llms-mistralai
# これはノートブックでコードを実行する際に必要です。
インポート nest_asyncio
nest_asyncio.apply()
from dotenv import load_dotenv
インポート os
load_dotenv()
データをMilvusにロードする
UberとLyftに関するPDFを含むllama-indexからいくつかのサンプルデータをダウンロードする。チュートリアルを通してこのデータを使用します。
mkdir -p 'data/10k/'.
!wget 'https://raw.githubusercontent.com/run-llama/llama_index/main/docs/docs/examples/data/10k/uber_2021.pdf' -O 'data/10k/uber_2021.pdf'
!wget 'https://raw.githubusercontent.com/run-llama/llama_index/main/docs/docs/examples/data/10k/lyft_2021.pdf' -O 'data/10k/lyft_2021.pdf'.
マシンにデータが入ったので、コンテンツを抽出してMilvusベクトルデータベースに格納することができる。埋め込みモデルには、bge-small-en-v1.5を使用しています。これは、コンパクトなテキスト埋め込みモデルで、リソースの使用量が少ないモデルです。
次に、Milvusにコレクションを作成し、データを格納・検索する。我々は、ベクトル類似性検索でAIアプリケーションを強化する高性能ベクトルデータベースMilvusの軽量版であるMilvus Liteを使用している。Milvus Liteはpip install pymilvusでインストールできる。
PDFはベクターに変換され、Milvusに保存されます。
from llama_index.vector_stores.milvus import MilvusVectorStore
from llama_index.core import Settings
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.core import SimpleDirectoryReader, VectorStoreIndex, StorageContext, load_index_from_storage
from llama_index.core.tools import QueryEngineTool, ToolMetadata
# このノートブックで使われるデフォルトの埋め込みモデルを定義する。
# bge-small-en-v1.5は小さなEmbeddingモデルで、ローカルで使うのに最適です。
Settings.embed_model = HuggingFaceEmbedding(
モデル名="BAAI/bge-small-en-v1.5"
)
input_files=["./data/10k/lyft_2021.pdf", "./data/10k/uber_2021.pdf"]
# 単一のMilvusベクトルストアを作成
vector_store = MilvusVectorStore(
uri="./milvus_demo_metadata.db"、
コレクション名="companies_docs"
dim=384、
overwrite=False、
)
# Milvusのベクターストアでストレージコンテキストを作成する。
storage_context = StorageContext.from_defaults(vector_store=vector_store)
# データを読み込む
docs = SimpleDirectoryReader(input_files=input_files).load_data()
# インデックスの構築
index = VectorStoreIndex.from_documents(docs, storage_context=storage_context)
# クエリエンジンを定義する
company_engine = index.as_query_engine(similarity_top_k=3)
異なるツールを定義する
我々のデータに特化した2つのツールを定義する。1つ目はLyftに関する情報を提供するもので、2つ目はUberに関するものである。より汎用的なツールを作成する方法は後で説明する。
# エージェントが使用できる様々なツールを定義する。
query_engine_tools = [
QueryEngineTools(
query_engine=company_engine、
metadata=ToolMetadata(
name="lyft_10k"、
description=(
"2021年のLyftの財務に関する情報を提供する。"
"ツールの入力として、詳細なプレーンテキストの質問を使用してください。"
),
),
),
QueryEngineTool(
query_engine=company_engine、
metadata=ToolMetadata(
name="uber_10k"、
description=(
"2021年のUberの財務に関する情報を提供します。"
"ツールの入力として詳細なプレーンテキストの質問を使用してください。"
),
),
),
]
Mistral Nemo を使ったエージェントのセットアップ 🐠 ## Mistral Nemo を使ったエージェントのセットアップ
リソースの使用量を制限し、アプリケーションのコストを削減するために、我々は Mistral Nemo と Ollama を使用しています。この組み合わせにより、ローカルでモデルを実行することができます。Mistral Nemoは小さなLLMで、最大128kトークンの大きなコンテキストウィンドウを提供する。また、推論、複数ターンの会話の処理、コードの生成など、正確な指示に従うように微調整されている。
では、Mistral Nemoを使ってエージェントをセットアップしてみよう。
from llama_index.llms.ollama import Ollama
from llama_index.core.agent import AgentRunner, ReActAgentWorker, ReActAgent
# エージェントのセットアップ
llm = Ollama(model="mistral-nemo", temperature=0.4)
agent = ReActAgent.from_tools(query_engine_tools, llm=llm, verbose=True)
# 使用例
response = agent.chat("2021年のLyftとUberの収益を比較してください。")
print(response)
このLLMは以下のようなレスポンスを生成するはずである:
> ステップ7ed275f6-b0de-4fd7-b2f2-fd551e58bfe2を実行しています。ステップ入力:2021年のLyftとUberの収益を比較せよ。
思考:ユーザーの現在の言語は英語。質問に答えるためにツールを使う必要がある。
アクション:lyft_10k
アクション入力:{'input':"2021年のLyftの総収入は?"}。
huggingface/tokenizers:並列処理がすでに使用された後、現在のプロセスがフォークされました。デッドロックを回避するために並列処理を無効にする...
この警告を無効にするには、以下の方法がある:
- 可能であれば、フォークの前に `tokenizers` を使用しないようにする。
- 環境変数 TOKENIZERS_PARALLELISM=(true | false) を明示的に設定する。
観察2021年のLyftの総収益は、主にドライバーとライダーをつなぐライドシェアリングマーケットプレイスから発生し、収益はASC606に従ってLyftプラットフォーム提供物を利用するためにドライバーから支払われる料金から認識された。
> ステップ 33064fd3-3c3a-42c4-ab5a-e7ebf8a9325b を実行中。ステップ入力:なし
そのように考えた:2021 年の Lyft と Uber の収益を比較する必要がある。
アクション:uber_10k
アクションの入力入力: {'input':「2021年のUberの総収入は?}
オブザベーション: $17,455
> ステップ7eacfef4-d9da-4cbf-ac07-18f2ff6a3951を実行中。ステップ入力:なし
思考:2021年のUberの総収入がわかった。さて、Lyft と比較する必要がある。
アクション: lyft_10k
アクション入力:{'input':「2021年の Lyft の総収入は?}
観察:2021年のLyftの総収入は、主にドライバーとライダーをつなぐライドシェアリングマーケットプレイスから生み出された。収益は、ASC606に従って、Lyftプラットフォーム提供物の利用に対してドライバーから支払われた料金から認識された。
> ステップ 88673e15-b74c-4755-8b9c-2b7ef3acea48 の実行。ステップ入力:なし
思考Uber と Lyft の 2021 年の総収入を入手した。さて、両者を比較する必要がある。
アクション比較する
アクション入力:{Uber': '17,455 ドル', 'Lyft': '36 億ドル'}。
オブザベーションエラー:エラー: `Compare`という名前のツールがありません。
> ステップ bed5941f-74ba-41fb-8905-88525e67b785 を実行中。ステップ入力:なし
考えた:Compare」ツールがないので、手動で収益を比較する必要がある。
答え2021年、Uberの総収入は175億ドル、Lyftの総収入は36億ドルだった。これは、同じ年にUberがLyftの約4倍の収益を上げたことを意味します。
メタデータフィルタリングなしのレスポンス:
2021年、Uberの総収入は175億ドル、一方Lyftの総収入は36億ドルだった。これは、同じ年にUberがLyftの約4倍の収益を上げたことを意味する。
Milvusでメタデータフィルタリングを使う
異なる種類のドキュメントごとにツールを定義したエージェントを持つことは便利ですが、処理する会社が多い場合、うまくスケールしません。より良い解決策は、Milvusが提供する メタデータフィルタリングをエージェントと共に使用することです。この方法では、異なる会社のデータを1つのコレクションに保存し、関連する部分だけを取り出すことができるので、時間とリソースを節約することができます。"
以下のコードスニペットは、メタフィルタリング機能の使用方法を示しています。
from llama_index.core.vector_stores import ExactMatchFilter, MetadataFilters
# メタデータフィルタリングの使用例
filters = MetadataFilters(
filters=[ExactMatchFilter(key="file_name", value="lyft_2021.pdf")].
)
filtered_query_engine = index.as_query_engine(filters=filters)
# フィルタリングされたクエリーエンジンでクエリーエンジンツールを定義する
query_engine_tools = [ クエリーエンジンツール
クエリエンジンツール(
query_engine=filtered_query_engine、
metadata=ToolMetadata(
name="company_docs"、
説明=(
"2021年の様々な企業の財務に関する情報を提供する。"
"ツールの入力として詳細なプレーンテキストの質問を使用する。"
),
),
),
]
# 更新されたクエリエンジンツールでエージェントをセットアップする
agent = ReActAgent.from_tools(query_engine_tools, llm=llm, verbose=True)
これで、retrieverはlyft_2021.pdf文書からのデータのみをフィルタリングするようになりました。
try:
response = agent.chat("2021年のウーバーの売上は?")
print("Response with metadata filtering:")
print(response)
except ValueError as err:
print("we couldn't find the data, reached maximum iterations")
では、テストしてみましょう。2021年のUberの収益について尋ねると、Agentはゼロの結果を取得した。
と思った:ユーザはUberの2021年の収益を知りたがっている。
アクション: company_docs
アクション入力:入力: {'input': 'Uber Revenue 2021'}.
観察:申し訳ありませんが、提供されたコンテキスト情報によると、2021年のUberの収益についての言及はありません。この情報は、主にLyftのアクティブライダー一人当たりの収益と、財務諸表に関連する重要な会計方針と見積りに焦点を当てています。
> ステップ c0014d6a-e6e9-46b6-af61-5a77ca857712 の実行。ステップ入力:なし
エージェントは、2021年のLyftの収益について質問されたときにデータを見つけることができる。
try:
response = agent.chat("2021年のLyftの収益は?")
print("Response with metadata filtering:")
print(response)
except ValueError as err:
print("we couldn't find the data, reached maximum iterations")
返された結果は
> ステップ 7f1eebe3-2ebd-47ff-b560-09d09cdd99bd を実行しています。ステップ入力:2021年のLyftの売上は?
思考:ユーザーの現在の言語は英語。質問に答えるためのツールが必要だ。
アクション:company_docs
アクション入力:{'input': 'Lyft revenue 2021'}.
観察:2021年のLyftの収益は、主にドライバーとライダーをつなぐライドシェアのマーケットプレイスから生み出された。収益は、ASC606に従って、ドライバーによるLyft Platformの利用料から認識された。さらに、アクティブライダー一人当たりの収益は、乗車頻度の増加、高収益乗車へのシフト、およびライセンス契約とデータアクセス契約からの収益により、2021年第4四半期に過去最高を記録した。
> ステップ072a3253-7eee-44e3-a787-397c9cbe80d8を実行中。ステップ入力:なし
思考:ユーザーの現在の言語は英語である。質問に答えるためのツールを使いたい。
アクション: company_docs
アクション入力:入力: {'input': 'Lyft revenue 2021'}.
観察:2021年のLyftの収益は、乗車頻度の増加、空港での乗車など高収益の乗車へのシフト、およびライセンス契約とデータアクセス契約からの収益によって牽引された。この結果、2021年第4四半期のアクティブライダー1人当たりの売上高は、前四半期と比較して過去最高となった。
> ステップ6494fe6d-27ad-484f-9204-0c4683bfa1c2を実行中。ステップ入力:なし
思考:ユーザーは2021年のLyftの収益を求めている。
アクション: company_docs
アクション入力:{'input': '2021年のLyftの収益'}。
観察:Lyftの2021年の収益は、主にドライバーとライダーをつなぐライドシェアリングマーケットプレイスから生み出された。アクティブライダー一人当たりの収益は、乗車頻度の増加や空港での乗車など高収益の乗車へのシフトにより、2021年第4四半期に過去最高を記録した。さらに、2021年第2四半期からのライセンス契約とデータアクセス契約により収益が押し上げられた。
> ステップ0076b6dd-e7d0-45ac-a39a-4afa5f1aaf47を実行中。ステップ入力:なし
回答観察Lyftの2021年の総収入は34億ドル。
メタデータのフィルタリングによる回答:
観察:Lyftの2021年の総収入は34億ドルだった。
LLMを使ってメタデータ・フィルターを自動作成する
では、LLMを使って、ユーザのクエリに基づいてメタデータフィルタを自動的に作成してみましょう。このステップにより、より動的なエージェントを持つことができます。
from llama_index.core.prompts.base import PromptTemplate
# フィルタリングされたクエリエンジンを作成する関数
def create_query_engine(question):
# 言語モデルを使用して質問からメタデータフィルタを抽出する
prompt_template = PromptTemplate(
"次の質問が与えられたら、関連するメタデータフィルタを抽出してください。"
"会社名、年、その他関連する属性を考慮してください。"
"他のテキストは書かず、MetadataFiltersオブジェクトだけを書いてください。"
「以下のようにMetadataFiltersを作成して整形する。
"MetadataFilters(filters=[ExactMatchFilter(key='file_name', value='lyft_2021.pdf')]) \n"
"特定のフィルタが指定されていない場合、空のMetadataFilters()を返します。
"質問{質問}n"
"メタデータフィルター:˶"
)
prompt = prompt_template.format(question=question)
llm = Ollama(model="mistral-nemo")
response = llm.complete(プロンプト)
metadata_filters_str = response.text.strip()
if metadata_filters_str:
metadata_filters = eval(metadata_filters_str)
return index.as_query_engine(filters=metadata_filters)
return index.as_query_engine()
この関数をエージェントと組み合わせることができます。
# メタデータフィルタリングによる使用例
question = "Uberの収益とは何ですか?これは file_name: uber_2021.pdf にあるはずです。"
filtered_query_engine = create_query_engine(question)
# フィルタリングされたクエリーエンジンでクエリーエンジンツールを定義する
query_engine_tools = [ クエリーエンジンツール
クエリエンジンツール(
query_engine=filtered_query_engine、
metadata=ToolMetadata(
name="company_docs_filtering"、
説明=(
"2021年の様々な企業の財務に関する情報を提供する。"
"ツールの入力として詳細なプレーンテキストの質問を使用する。"
),
),
),
]
# 更新されたクエリエンジンツールでエージェントをセットアップする
agent = ReActAgent.from_tools(query_engine_tools, llm=llm, verbose=True)
response = agent.chat(question)
print("Response with metadata filtering:")
print(response)
これで、エージェントは file_name というキーと uber_2021.pdf という値を持つ Metadatafilters を作成した。より高度なプロンプトがあれば、より高度なフィルタを生成することも可能である。
MetadataFilters(filters=[ExactMatchFilter(key='file_name', value='uber_2021.pdf')])
<クラス 'str'>
eval: filters=[MetadataFilter(key='file_name', value='uber_2021.pdf', operator=<FilterOperator.EQ: '=='>)] condition=<FilterCondition.AND: 'and'>.
> ステップa2cfc7a2-95b1-4141-bc52-36d9817ee86dを実行しています。ステップ入力:Uber Revenueとは?これは file_name: uber_2021.pdf にあるはずだ。
思考:ユーザーの現在の言語は英語である。質問に答えるためにツールを使う必要がある。
アクション: company_docs
アクション入力:入力: {'input': 'Uberの収益2021'}。
オブザベーション:17,455百万ドル
ミストラル・ラージですべてをオーケストレーションする
Mistral Largeは、Mistral Nemoよりもパワフルなモデルですが、より大きく、より多くのリソースを必要とします。オーケストレーターとしてのみ使用することで、インテリジェントエージェントの恩恵を受けながらリソースを節約することができます。
なぜ Mistral Large をオーケストレーターとして使うのか?
Mistral Large は Mistral のフラッグシップモデルで、非常に優れた推論能力、知識、コーディング能力を備えています。大規模な推論能力を必要とする複雑なタスクや、高度に専門化されたタスクに最適です。Mistral Largeは、高度な関数呼び出し機能を備えており、まさに私たちが様々なエージェントをオーケストレーションするのに必要なものです。
Mistral Largeでオーケストレーションすることで、エージェントフレームワーク内の関心事を分離することができます。Mistral Largeは、全てのタスクに重いモデルを適用してシステムに負担をかける代わりに、高レベルの意思決定のために予約することができ、他のエージェントをより特定の小さなタスクに向かわせることができます。このアプローチはパフォーマンスを最適化するだけでなく、運用コストを削減し、システムをよりスケーラブルで効率的にします。
このセットアップでは、Mistral Largeが中心的なオーケストレーターとして機能し、Llama-エージェントによって管理される複数のエージェントの活動を調整する。以下はその概要である:
タスクの委譲複雑なクエリを受信すると、Mistral Large はクエリの各部分を処理するのに最適なエージェントとツールを決定します。
エージェントの調整Llama-agents はこれらのタスクの実行を管理し、各エージェントが必要な入力を受け取り、出力が正しく処理され統合されるようにします。
結果合成**:ミストラル・ラージは、様々なエージェントからのアウトプットを首尾一貫した包括的なレスポンスにまとめ、最終的なアウトプットが部分の総和よりも大きなものになるようにする。
ラマ・エージェント
では、Mistral Largeを使ってすべてをオーケストレーションし、エージェントを使って答えを生成してもらおう。
from llama_agents import (
AgentService、
ToolService、
ローカルランチャー
MetaServiceTool、
ControlPlaneServer、
SimpleMessageQueue、
AgentOrchestrator、
)
from llama_index.core.agent import FunctionCallingAgentWorker
from llama_index.llms.mistralai import MistralAI
# マルチエージェントフレームワークのコンポーネントを作成する
message_queue = SimpleMessageQueue()
control_plane = ControlPlaneServer(
message_queue=message_queue、
orchestrator=AgentOrchestrator(llm=MistralAI('mistral-large-latest'))、
)
# ツールサービスの定義
tool_service = ToolService(
message_queue=message_queue、
tools=query_engine_tools、
running=True、
step_interval=0.5、
)
# ここでメタツールを定義する
meta_tools = [
await MetaServiceTool.from_tool_service(
t.metadata.name、
message_queue=message_queue、
tool_service=tool_service、
)
for t in query_engine_tools
]
# エージェントとエージェントサービスを定義する
worker1 = FunctionCallingAgentWorker.from_tools(
meta_tools、
llm=MistralAI('mistral-large-latest')
)
agent1 = worker1.as_agent()
agent_server_1 = AgentService(
agent=agent1、
message_queue=message_queue、
description="様々な企業の決算に関する質問に答えるために使用されます、
service_name="Companies_analyst_agent"、
)
インポートログ
# ロギングレベルを変更して、より冗長なロギングを有効または無効にする
logging.getLogger("llama_agents").setLevel(logging.INFO)
## ランチャーの定義
launcher = LocalLauncher(
[agent_server_1, tool_service]、
control_plane、
message_queue、
)
query_str = "ウーバーの危険因子は何ですか?"
print(launcher.launch_single(query_str))
> ウーバーの主なリスク要因としては、ブランド、価格モデル、安全事故に対する不満によるドライバー数や加盟店数の変動が挙げられる。自律走行車への投資は、人間のドライバーの必要性を減らす可能性があるため、ドライバーの不満につながる可能性もある。さらに、ドライバーの不満が抗議行動に発展し、事業中断を引き起こしたこともある。
結論
このブログポストでは、Llama-agents フレームワークでエージェントを作成し、使用する方法について説明しました:Mistral NemoとMistral Largeです。我々は、異なるLLMの長所を活用することで、インテリジェントでリソース効率の高いシステムを効果的にオーケストレーションする方法を示しました。
このブログ記事が気に入ったら、ぜひGitHubでご紹介ください。また、私たちのDiscordに参加して、あなたの経験をMilvusコミュニティと共有することも歓迎します。

読み続けて

Context Engineering Strategies for AI Agents: A Developer’s Guide
Learn practical context engineering strategies for AI agents. Explore frameworks, tools, and techniques to improve reliability, efficiency, and cost.

Zilliz Cloud Launches in AWS Australia, Expanding Global Reach to Australia and Neighboring Markets
We're thrilled to announce that Zilliz Cloud is now available in the AWS Sydney, Australia region (ap-southeast-2).

Building RAG Pipelines for Real-Time Data with Cloudera and Milvus
explore how Cloudera can be integrated with Milvus to effectively implement some of the key functionalities of RAG pipelines.