




ZillizはいかにしてGTC 2026でNVIDIAの非構造化データストーリーの中心に立つことになったのか
今年のNVIDIA GTCでは、チップ、システム、インフラに関するいつもの大量の主張が飛び交う中、Jensen Huangが別の理由で重要なスライドを映し出しました。
それは次のGPUについてではありませんでした。モデルサイズについてでもありませんでした。実際のところ、推論についてでさえありませんでした。
それはデータについてでした。
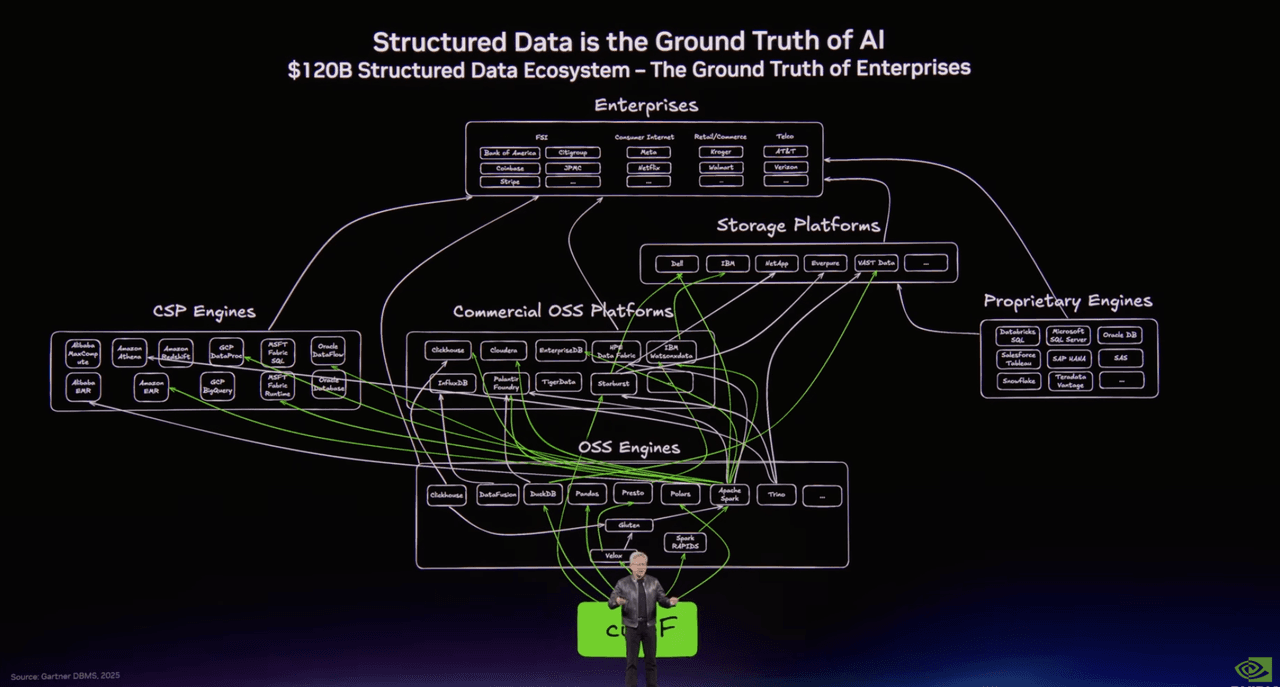
1枚のスライドは構造化データの世界を示していました。Spark、Presto、DuckDB、Polars、Snowflake、Databricks、BigQuery——何十年にもわたって分析とデータエンジニアリングを支えてきたおなじみの仕組みです。
もう1枚は、非構造化データの新興スタックを示していました。そしてその2枚目の図の中央に、オープンソースの Milvus と、エンタープライズデータベース層の Zilliz Cloud がありました。

スライドのタイトルがすべてを物語っていました:非構造化データはAIのコンテキストである。
この一文には、思わずうなずきたくなります。もちろん、AIにはコンテキストが必要です。もちろん、企業データの大半は非構造化です。もちろん、テキスト、画像、動画、音声、ログ、PDF、そしてその他すべてが、これまで以上に重要になっています。しかしスローガンを越えて考えると、より難しい問いが浮かび上がります:非構造化データがAIシステムの真の基盤になりつつあるなら、その世界のインフラは実際にはどのような姿になるのでしょうか?
そこに、より興味深い物語があります。そしてそれこそが、Milvusが専門的なベクトルデータベースから、AIスタックにおけるはるかに戦略的な位置へと移行してきた理由です。
Zilliz(Milvus)が何度も登場する理由
ZillizがGTCに登場したのは今回が初めてではなく、おそらく最後でもないでしょう。
ベクトルデータベースが現代のAIシステムにおける標準的な構成要素になるずっと前から、Milvusは、類似検索が従来のデータベースとはまったく異なるスケールで動作する必要があるという考えを中心に構築されていました。GPUアクセラレーションは後付けではありませんでした。最初から設計思想の一部だったのです。
AIが研究の話題であることをやめ、インフラの話題になったとき、そのことが重要になりました。
GTC 2023では、Jensen HuangはすでにNVIDIAのアクセラレーション ライブラリとFAISS、Redis、Milvusのようなシステムとのより深い統合に言及していました。その1年後のGTC 2024では、その関係はMilvus 2.4によってさらに具体的になりました。Milvus 2.4は、NVIDIA GPUとRAPIDS cuVSのCAGRA を組み合わせることで、ベクトルインデックス作成と検索に完全なGPUアクセラレーションをもたらしました。その結果は、見せかけの高速化ではありませんでした。一部のベンチマーク設定では、検索性能がHNSW比で最大50倍向上しました。
Milvus 2.6が登場する頃には、議論は再び進化していました。問いはもはや、GPUアクセラレーションが重要かどうかではありませんでした。それをいかにコスト効率よく使うかでした。Milvus 2.6 は、CAGRAのためのより柔軟なデプロイパターンを導入しました。そこには、グラフ構築にはGPUを使い、検索にはCPUを使うハイブリッドGPU-CPUアーキテクチャも含まれます。これは重要です。なぜなら、ほとんどの企業は、どんな代償を払ってでも可能な限り最速のシステムを求めているわけではないからです。企業が求めているのは、経済的に妥当でありながら、十分に高速であり続けるシステムです。
この点には立ち止まって考える価値があります。なぜならそれは、Milvusが重要になった理由について、より大きなことを示しているからです。これは単なるベクトル検索性能の話ではありません。ベクトル検索が実験的な機能であることをやめ、本番インフラの一部になったときに何が起こるのかという話なのです。
本番環境でベクトル検索を機能させるために必要なこと
速度だけではもはや話の中心ではなくなる。
しかし、ベクトル検索がデモを離れて実システムに入ると、速度だけでは話が終わらなくなります。
より難しい問題は、周辺のスタックを壊れやすいパイプライン、高いメモリ負荷、増大するインフラコストの寄せ集めにしてしまうことなく、エンタープライズ規模で検索を実用的にするには何が必要かということです。
その課題の一部は上流から始まります。 従来のモデルでは、PDF、画像、ドキュメントを検索可能なものに変換するには、通常、別個の解析レイヤー、チャンク化ロジック、埋め込みサービス、データベース書き込みをつなぎ合わせる必要がありました。検索システムが動き始めるのは、長い前処理チェーンがすでに処理を完了した後でした。Milvus 2.6 は、Data-in, Data-out approach, によってその境界を崩し始め、raw コンテンツをシステムに直接書き込み、データベース内部で埋め込めるようにしました。
その一部は検索レイヤーの内部にあります。 ワークロードが異なれば必要なトレードオフも異なるため、あらゆるユースケースに単一の検索戦略を強制するのではなく、複数のインデックスタイプをサポートします。圧縮もまた方程式の一部になります。Int8 や RaBitQ のような機能は派手な追加ではありませんが、より重要な目標に対応しています。すなわち、検索品質を犠牲にすることなく、メモリ負荷とコストを削減することです。
そして、その一部は単純に運用上のものです。 Milvus は、Kafka と Pulsar をスタックから不要にする、再設計された write-ahead logging アーキテクチャを導入し、複雑さとオーバーヘッドの両方を削減しました。こうしたエンジニアリングが見出しを飾ることはめったにありませんが、インフラが理論上は興味深いままで終わるのか、それとも実際に使えるものになるのかを決めるのは、まさにこの種のエンジニアリングです。
ストレージは、もう一つの分断線であることがわかります。
AI システムが成長するにつれて、すべてのデータを常に同じように扱わなければならないと見なすことのコストも増大します。大規模なマルチテナントプラットフォームでは、ある日に実際にアクティブなのはデータのごく一部にすぎないかもしれません。その大半はコールドのままです。しかし従来のフルロードアーキテクチャは、それでもなお、すべてのデータが同じローカル常駐性、同じ性能姿勢、同じコストフットプリントに値するかのように扱います。
小規模では、それは非効率に見えます。エンタープライズ規模では、それを正当化するのが難しくなります。
Milvus 2.6 は、tiered storage によってそれに対処しました。ホットデータは、レイテンシが重要なローカルに留まります。コールドデータは、低コストのオブジェクトストレージからオンデマンドでロードされます。そして両者の境界は、システムが実際に使われるにつれて動的に変化します。これは控えめなシステム最適化のように聞こえます。実際には、検索の経済性を変えます。適切なデータが適切なティアに存在するとき、ストレージコストは 70 パーセント以上低下する可能性があります。
これらのどれも、特に華やかなものではありません。しかし、インフラが成熟するのは通常そういうものです。単一の劇的なブレークスルーによってではなく、システムをより速く、より安く、より扱いやすくする一連の設計判断によってです。
そして、これらすべての機能は、Milvus のフルマネージドサービスである Zilliz Cloud で利用可能になっています。
非構造化データに関する本当の問題
しかし、より大きな変化は、実のところ Milvus だけの話ではありません。それは、AI システムが現在依存しているデータの種類に関するものです。
構造化データは、長く秩序だった形で進化してきました。行、列、スキーマ、インデックス、ウェアハウス、クエリエンジン。データそのものが、それらのシステムが構築された前提に適合していたため、ツールは数十年かけて成熟しました。レコードがどのようなものかを知っていました。どのフィールドをクエリすべきかを知っていました。それらをどのようにインデックス化するかを知っていました。
非構造化データはそのモデルを壊します。
契約書は行ではありません。医用画像、サポートのやり取りの記録、コードリポジトリ、監視フィードも同様です。これらのオブジェクトは保存できますが、保存すること自体は簡単な部分です。難しいのは、正確なフィールド一致ではなく意味を理解する形で検索可能にすることです。
だからこそ、埋め込みはすべてを変えました。 テキスト、画像、音声、その他の形式のコンテンツを高次元のベクトル空間にマッピングできるようになると、検索はもはや厳密な記号的マッチングに依存する必要がなくなりました。システムは、類似性、意図、文脈によって取得できるようになりました。
それがブレークスルーでした。
それは同時に、新たなインフラストラクチャ上の問題の始まりでもありました。
非構造化データがクエリ可能になると、企業はすぐにスケールの経済性に直面します。数百万のドキュメントは数億の埋め込みになります。モデルのアップグレードは、過去のコーパスを再埋め込みすることを意味します。検索品質はインデックス品質に依存します。本番環境ではレイテンシが重要です。ストレージコストも同様です。これらすべてを同期させ続ける運用負荷も同様です。
言い換えれば、セマンティック検索はアクセスの問題を解決しましたが、システムの問題を露呈させました。
Milvus が意味を持つのは、このような文脈においてです。
ベクトルデータベースだけでは不十分だった理由
AIネイティブ企業の第一波にとって、答えは単純でした。ベクトルデータベースを検索レイヤーとして使い、それをモデルに接続し、そこからアプリケーションを構築する、というものです。そのモデルは機能しましたし、今でも機能しています。特に、セマンティック検索がプロダクトの中核である場合にはそうです。
しかし大企業は、異なる壁に突き当たりがちです。
問題は、ベクトル検索を動かせるかどうかではありません。問題は、その後に何が起こるかです。
生ファイルはオブジェクトストレージやデータレイクに存在します。埋め込みはベクトルデータベースに存在します。メタデータはリレーショナルシステムに存在します。オフライン処理は別の場所で行われます。検索ログはさらに別のパイプラインに蓄積されます。そこへ埋め込みモデルが変わる、あるいはランキングロジックが変わる、あるいはナレッジベースにキュレーションが必要になる、あるいは検索システムがエッジケースで失敗し続ける理由を誰かが追跡したくなる。すると突然、そのシステムはもはや一つのシステムではなくなります。寄せ集めになります。
その寄せ集めは、よく知られた三つの問題を生みます。
- 第一に、データサイロです。 一つのAI機能を実行するために必要なデータが複数のシステムに分散し、それぞれが独自の形式、ライフサイクル、運用モデルを持っています。
- 第二に、反復のコストです。 埋め込みモデルが変わったとき、書き換えはデフォルトではインクリメンタルではありません。数か月に及ぶ再インデックス作成と移行作業になり得ます。
- 第三に、オンライン提供とオフライン改善の間のループが壊れていることです。 システムは本番環境でクエリに応答しますが、それを改善し得るシグナル、重複排除の出力、クラスタリングラベル、品質スコア、失敗分析は、しばしば別々の環境に存在し、検索レイヤーへきれいに戻ることはありません。
そこで、ベクトルデータベースを購入することは答えであるように感じられなくなり、より大きなアーキテクチャ上の問いの始まりのように感じられるようになります。
本当の問題が、スケールした継続的改善であるなら、アーキテクチャは変わらなければなりません。
ベクトルデータベースからAI Lakebaseへ
AIブーム以前、Databricks はデータレイクとデータウェアハウスの不自然な分断を解消することで、Lakehouse モデルの普及を後押ししました。ストレージ、分析、大規模処理のために別々のシステムを維持する代わりに、企業はより統一された基盤から作業できるようになりました。
AI時代は、非構造化データをめぐって同様の再考を迫っています。
Jensen Huang が使っているインフラストラクチャ図をよく見ると、重心が移動していることがわかります。構造化データの時代には、Spark のようなフレームワークがパイプラインの中心にありました。非構造化データの時代には、Milvus のようなベクトルインフラストラクチャがその役割を担い始めています。ベクトル検索だけが重要だからではなく、生データ、埋め込み、インデックス、アプリケーション検索の接点にますます位置するようになっているからです。
それは、より大きな可能性を開きます。もしベクトル検索を、スタックの横に後付けされた別個のサービング層として扱わなかったらどうでしょうか? もしそれがエンタープライズのデータレイクや周辺のデータワークフローと直接統合されていたらどうでしょうか?
AI Lakebase アーキテクチャ
それが AI Lakebase の背後にある考え方です。
AI Lakebase の目的は、すでに混み合っている市場にさらに別の製品カテゴリを追加することではありません。目的は、断片化されたパターンを、より一貫性のあるものに置き換えることです。
- 最下層には統合されたストレージ層があります。 そのデータの一部は、高性能なベクトル検索に最適化された Zilliz ネイティブのコレクションに存在します。一部は、企業がすでに使用しているオープン形式、Iceberg、Lance、Paimon、そしてオブジェクトストレージ内の生ファイルのまま残ります。重要なのは、データを利用可能にするためだけに、5つの異なるシステムへコピーする必要がないということです。
- その上には、リアルタイム検索のために構築された本番サービング層があります。 Zilliz Cloud では、それはミリ秒レベルのレイテンシに最適化された Cardinal 搭載のサービングクラスターを意味し、性能、容量、階層化されたホット・コールドデータ配置に応じた異なるモードを備えています。実際には、頻繁にアクセスされるデータはローカルに留まり、コールドデータは必要に応じてより安価なストレージから読み込まれることを意味します。その結果は、単により優れたシステム設計にとどまりません。コスト管理でもあります。
- そして、弾力的なコンピュート層があります: ETL、重複排除、クラスタリング、データ品質分析、再埋め込み、評価、対話的な調査のためのオンデマンドクラスターです。これらは後から接着されたサイドシステムではありません。同じ基盤の一部です。
3つの層すべてが、複数の切り離されたコピーを維持するのではなく、同じデータを共有します。
これはアーキテクチャの整理の話のように聞こえますし、実際そうです。しかし、それだけではありません。
より大きなポイントは、そのアーキテクチャによって何が可能になるかです。
AI Lakebase は単なるアーキテクチャの整理ではない
今日のほとんどの AI システムはサーブできます。体系的に改善できるものははるかに少ないです。
それは通常、モデルが間違っているからではありません。その周囲のインフラがフィードバックを高コストにしているからです。
本番システムは常にシグナルを生成します。すべてのクエリが何かを教えてくれます。すべての検索失敗が何かを教えてくれます。すべての低品質な回答、すべての重複した結果、すべての行き止まりのインタラクション、すべての類似ドキュメントのクラスター、コーパス内のすべてのノイズの多いチャンク、それらはすべて、システムの改善に利用できる情報です。
しかしほとんどのスタックでは、それらのシグナルはサービングログ、オフラインパイプライン、ノートブック、ダッシュボード、そして一回限りのスクリプトに散らばっています。システムは動いていますが、自らの経験から本当の意味で学習してはいません。
それを解決するための AI Lakebase の枠組みが Continuous Serving/Continuous Discovery(AI CS/CD) です。
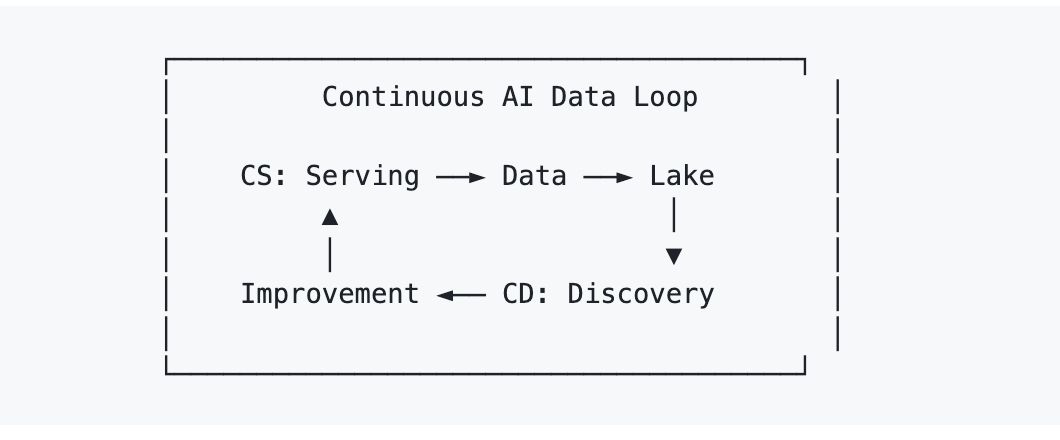
- Continuous Serving は明らかな部分です。ライブシステムが本番環境で検索と生成を処理します。
- Continuous Discovery は、あまり明らかではない部分です。システムは蓄積したもの、カバレッジのギャップ、失敗モード、クラスター構造、データ品質の問題を継続的に分析し、その結果として得られた改善を同じ運用環境へ書き戻します。
これが重要なのは、サービングとディスカバリーが同じデータ基盤を共有すると、改善は移行のように見えなくなり、反復のように見え始めるからです。重複排除の結果はライブ検索へ戻せます。品質スコアは本番ランキングに影響を与えられます。クラスターラベルは検索シグナルになり得ます。再埋め込みは、巨大な一括イベントとしてではなく、弾力的なコンピュートによって段階的に実行できます。
アーキテクチャは、静的なデータベースというよりも、生きた改善ループのように振る舞い始めます。
これは「ベクトルデータベース、ただしより高速」というよりも、はるかに重要な変化です。
AI Lakebase で高速にスケールし、高速に反復する
多くのインフラ企業はスケールを主張できます。多くは速度を主張できます。同じシステム内で、スケールと継続的な反復の両方をもっともらしく主張できる企業は、はるかに少ないです。
Zilliz は、エンタープライズ AI インフラストラクチャの次のフェーズにはその両方が必要だと主張しています。
- Scale Fast とは、ベンチマーク実行やデモ環境だけでなく、非常に大規模な本番ワークロードをサポートできる、マルチリージョン、マルチクラウドのインフラストラクチャを意味します。
- Iterate Fast とは、オフラインでの発見とオンラインでの提供が同じ運用ループの一部となるようにシステムが設計されていることを意味します。改善は後付けではなく、組み込まれています。
この区別が重要なのは、本番環境の AI は正反対の 2 つの形で失敗するからです。スケールはするものの停滞するシステムがあります。それらは大規模で高コストになり、改善がますます難しくなります。一方で、小規模な環境では迅速に反復できるものの、耐久性のある本番システムには決してならないものもあります。本当の目標はそのどちらでもありません。それは、成長しながら同時に学習できるシステムです。
それこそが、ベクトルデータベースから AI Lakebase への移行の背後にある約束です。
その移行において、ベクトルデータベースが消えるわけではありません。依然として重要です。リアルタイム検索のための提供エンジンであり続けます。しかし、それはアーキテクチャの終着点ではなくなります。Lakehouse の世界においてリレーショナルデータベースが依然として存在しながらも、それ自体がアーキテクチャ全体を定義するわけではないのと同じように、より広範なシステムの 1 つのレイヤーになります。
そして、それこそが GTC での Jensen Huang の言葉を読み解くうえで最も有用な方法かもしれません。
非構造化データが AI のコンテキストであるなら、AI アプリケーションの上限はモデルだけでなく、非構造化データのためのインフラストラクチャがどれほど成熟するかによって決まります。
そのインフラストラクチャはまだ未完成です。市場もまだ初期段階にあります。しかし、その輪郭は見え始めています。
そしてますます、Milvus はその中心に位置するようになっています。
Stay tuned!
AI Lakebase は、Milvus 3.0 の背後にあるアーキテクチャ上のアップグレードであり、Zilliz Cloud の大きな進化となります。これがどこへ向かっているのかをいち早く知りたい方は、早期アクセスについてお問い合わせください。
読み続けて

How to Install and Run OpenClaw (Previously Clawdbot/Moltbot) on Mac
Turn your Mac into an AI gateway for WhatsApp, Telegram, Discord, iMessage, and more — in under 5 minutes.

A Developer's Guide to Exploring Milvus 2.6 Features on Zilliz Cloud
Milvus 2.6 marks a shift from “vector search + glue code” to a more advanced retrieval engine, and it is now Generally Available (GA) on Zilliz Cloud (a managed Milvus service).

Similarity Metrics for Vector Search
Exploring five similarity metrics for vector search: L2 or Euclidean distance, cosine distance, inner product, and hamming distance.