




Milvusにデータをシームレスに移行する方法:包括的ガイド
Milvusは、類似検索のための堅牢なオープンソースのベクトルデータベースであり、数十億から数兆のベクトルデータを最小のレイテンシーで保存、処理、検索することができます。また、非常にスケーラブルで信頼性が高く、クラウドネイティブで機能豊富です。Milvusの最新リリースでは、10倍以上の高速パフォーマンスを実現するGPUサポートや、1台のマシンでより大きなストレージ容量を実現するMMapなど、さらにエキサイティングな機能と改良が導入されています。
2023年9月現在、MilvusはGitHubで約23,000のスターを獲得しており、様々な業種から様々なニーズを持つ数万人のユーザーを抱えています。ChatGPT](https://zilliz.com/learn/ChatGPT-Vector-Database-Prompt-as-code)のようなGenerative AI技術が普及するにつれ、さらに人気が高まっている。特にretrieval augmented generationフレームワークは、大規模言語モデルの幻覚問題に対処するもので、様々なAIスタックに欠かせないコンポーネントとなっている。
Milvusへの移行を希望する新規ユーザーや、Milvusの最新バージョンへのアップグレードを希望する既存ユーザーからの需要の高まりに応えるため、私たちはMilvus Migrationを開発しました。本ブログでは、Milvus Migrationの機能をご紹介し、Milvus 1.x、FAISS、Elasticsearch 7.0以降からMilvusへの迅速なデータ移行についてご案内いたします。
Milvus Migration, 強力なデータ移行ツール
Milvus MigrationはGoで書かれたデータ移行ツールです。旧バージョンのMilvus (1.x)、FAISS、Elasticsearch 7.0以降からMilvus 2.xへのシームレスなデータ移行が可能です。
下図はMilvus Migrationの構築方法とその動作を示しています。
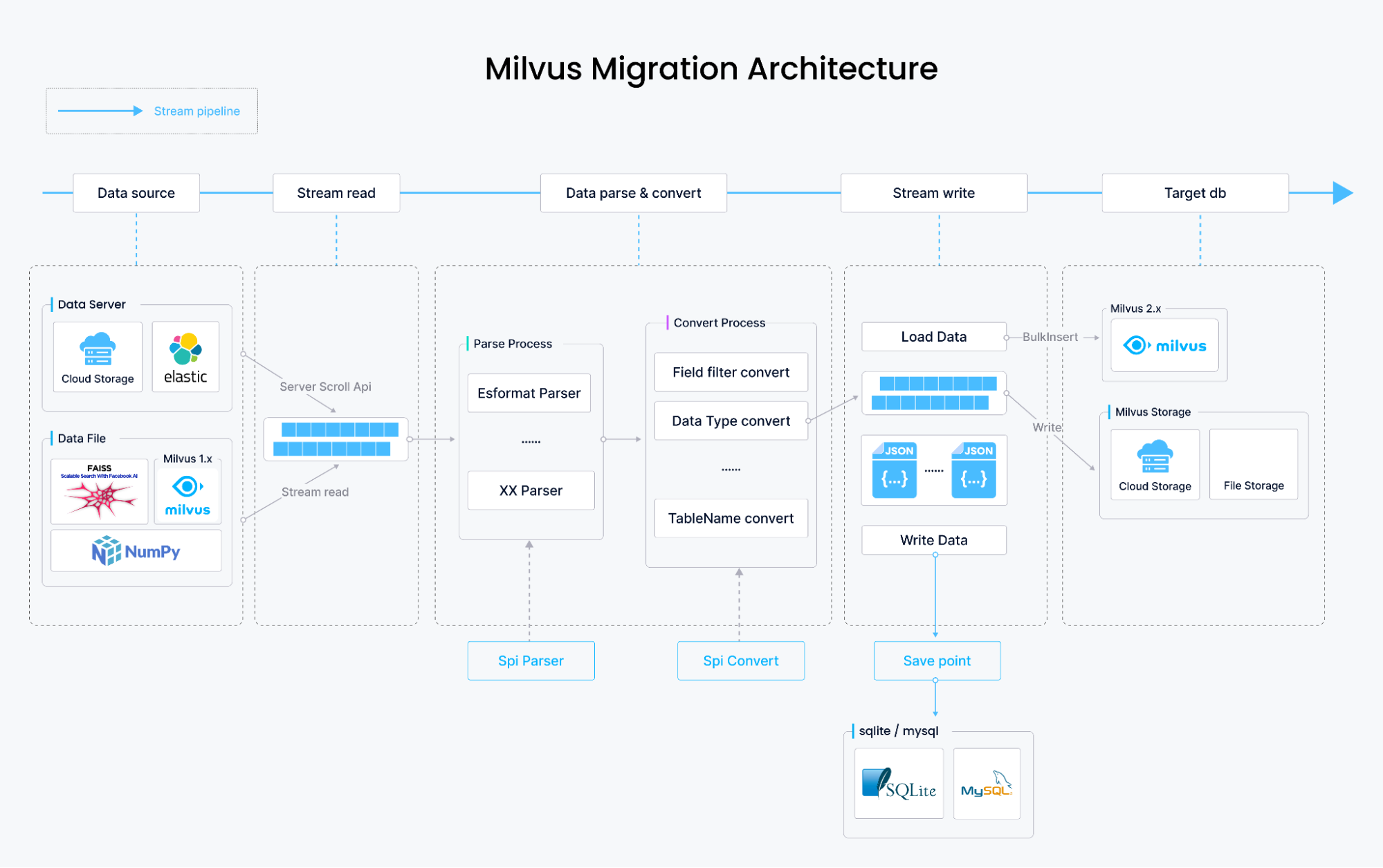
Milvusマイグレーションによるデータ移行方法
Milvus1.xおよびFAISSからMilvus2.xへ
Milvus 1.xおよびFAISSからのデータ移行では、元のデータファイルの内容を解析し、Milvus 2.xのデータ格納フォーマットに変換し、Milvus SDKのbulkInsertを使用してデータを書き込みます。このプロセス全体はストリームベースであり、理論的にはディスク容量のみに制限され、データファイルはローカルディスク、S3、OSS、GCP、またはMinioに保存されます。
Elasticsearch から Milvus 2.x へ
Elasticsearch からのデータ移行では、データの取得方法が異なります。データはファイルから取得されるのではなく、Elasticsearch の scroll API を使って順次取得されます。その後、データをパースして Milvus 2.x ストレージフォーマットに変換し、bulkInsert を使ってデータを書き込む。Elasticsearch に格納されている dense_vector 型のベクタのマイグレーションに加えて、Milvus Migration は long, integer, short, boolean, keyword, text, double などの他のフィールド型のマイグレーションもサポートしている。
Milvusマイグレーション機能セット
Milvus Migrationは、堅牢な機能セットにより移行プロセスを簡素化します:
サポートされるデータソース:
Milvus 1.x から Milvus 2.x への移行
Elasticsearch 7.0以降からMilvus 2.xまで
FAISSからMilvus 2.x
複数の相互作用モード:
Cobraフレームワークを使用したコマンドラインインターフェイス(CLI)
Swagger UIを組み込んだRestful API
他のツールにGoモジュールとして統合
多彩なファイル形式をサポート:**。
ローカルファイル
アマゾンS3
オブジェクトストレージサービス(OSS)
グーグル・クラウド・プラットフォーム(GCP)
フレキシブルなElasticsearchとの統合
Elasticsearch からの
dense_vector型ベクトルの移行long、integer、short、boolean、keyword、text、double などの他のフィールド型の移行をサポート
インターフェースの定義
Milvus Migration は以下の主要なインタフェースを提供します:
/start
:/start:マイグレーションジョブを開始します(ダンプとロードの組み合わせに相当します。)/dump`:ダンプジョブを開始する (移行元データを移行先のストレージメディアに書き込む)。
/load`:ロードジョブを開始する:ロードジョブを開始する(ターゲット記憶媒体から Milvus 2.x にデータを書き込む)。
/get_job: ジョブの実行結果を表示する:ジョブの実行結果を閲覧できるようにする。(詳細は プロジェクトの server.go を参照)
次に、このセクションでMilvus Migrationの使い方を探るために、いくつかのサンプルデータを使ってみましょう。これらの例はこちらのGitHubにあります。
Elasticsearch から Milvus 2.x へのマイグレーション
- Elasticsearchデータの準備
Elasticsearch](https://github.com/zilliztech/milvus-migration)のデータをマイグレーションするには、Elasticsearchサーバーをセットアップしておく必要があります。ベクトルデータを dense_vector フィールドに格納し、他のフィールドでインデックスを作成します。インデックスのマッピングは以下のようになります。

- コンパイルとビルド
まず、Milvus MigrationのGitHubからのソースコードをダウンロードします。そして、以下のコマンドを実行してコンパイルします。
go get
ビルドする
このステップで milvus-migration という名前の実行ファイルが生成される。
- migration.yaml`を設定する。
マイグレーションを開始する前に、データソース、ターゲット、その他の関連する設定の情報を含む migration.yaml という名前の設定ファイルを用意する必要があります。以下に設定例を示す:
# Elasticsearch から Milvus 2.x へのマイグレーション設定
dumper:
worker:
workMode:Elasticsearch
リーダー
バッファサイズ: 2500
meta:
モード: config
インデックス: test_index
フィールド
- 名前: id
pk: true
タイプ: long
- 名前: other_field
maxLen: 60
タイプ: キーワード
- 名前: data
タイプ: dense_vector
dims:512
milvus:
コレクション"rename_index_test"
closeDynamicField: false
一貫性レベル最終的に
shardNum:1
ソース
es:
urls:
- http://localhost:9200
ユーザー名:xxx
パスワード: xxx
ターゲット
モード:リモート
リモート
outputDir: outputPath/migration/test1
クラウド: aws
リージョン: us-west-2
バケット: xxx
useIAM: true
checkBucket: false
milvus2x:
エンドポイント: {yourMilvusAddress}:{port}
ユーザー名******
パスワード******
設定ファイルの詳細については、GitHubのこのページを参照してください。
- 移行ジョブの実行
これで migration.yaml ファイルの設定が完了したので、次のコマンドを実行してマイグレーションタスクを開始できます:
./milvus-migration start --config=/{YourConfigFilePath}/migration.yaml
ログ出力を観察する。以下のようなログが表示されたら、移行が成功したことを意味します。
[task/load_base_task.go:94] ["[LoadTasker] Dec Task Processing-------------->"] [Count=0] [fileName=testfiles/output/zwh/migration/test_base_task.go:94[Count=0] [fileName=testfiles/output/zwh/migration/test_mul_field4/data_1_1.json] [taskId=442665677354739304][task/load_base_task.go:76] ["[LoadTasker] Progress Task --------------->"][fileName=testfiles/output/zwh/migration/test_mul_field4/data_1_1.json][taskId=442665677354739304][dbclient/cus_field_milvus2x.go:86] ["[Milvus2x] begin to ShowCollectionRows"][loader/cus_milvus2x_loader.go:66] ["[Loader] Static: "].[collection=test_mul_field4_rename1][beforeCount=50000][afterCount=100000][increase=50000][loader/cus_milvus2x_loader.go:66] ["[Loader] Static Total"] ["Total Collections" =1["Total Collections"=1] [beforeTotalCount=50000] [afterTotalCount=100000] [totalIncrease=50000][migration/es_starter.go:25] ["[Starter]ESからMilvusへのマイグレーション終了!!!"][コスト=80.009174459][starter/starter.go:106] ["[スターター] マイグレーション成功!"][コスト=80.00928425][cleaner/remote_cleaner.go:27] ["[リモートクリーナー] ファイルのクリーニングを開始"]bucket=a-bucket] [rootPath=testfiles/output/zwh/migration][cmd/start.go:32] ["[Cleaner] clean file success!"] ["[リモートクリーナー] ファイルのクリーニングを開始します。
コマンドラインアプローチに加えて、Milvus MigrationはRestful APIを使ったマイグレーションもサポートしています。
Restful APIを利用するには、以下のコマンドでAPIサーバを起動します:
./milvus-migration server run -p 8080
サービスが実行されたら、APIを呼び出してマイグレーションを開始できる。
curl -XPOST http://localhost:8080/api/v1/start
移行が完了したら、オールインワンのベクトルデータベース管理ツールである Attu を使って、移行に成功した行の総数を表示したり、その他のコレクション関連の操作を行うことができます。
Attuインターフェイス](https://assets.zilliz.com/attu_interface_vector_database_admin_4893a31f6d.png)
Milvus 1.x から Milvus 2.x への移行
- Milvus 1.x データの準備
移行プロセスを素早く体験していただくために、Milvus Migrationのソースコードに10,000件のMilvus 1.x テストデータ レコードを用意しました。しかし、実際のケースでは、移行プロセスを開始する前に、Milvus 1.xインスタンスから独自のmeta.jsonファイルをエクスポートする必要があります。
- 以下のコマンドでエクスポートできます。
./milvus-migration export -m "user:password@tcp(adderss)/milvus?charset=utf8mb4&parseTime=True&loc=Local" -o outputDir
必ず
プレースホルダを実際の MySQL 認証情報に置き換えます。
このエクスポートを実行する前に、Milvus 1.x サーバを停止するか、データの書き込みを停止してください。
Milvus の
tablesフォルダとmeta.jsonファイルを同じディレクトリにコピーする。
注意: Zilliz Cloud(Milvusのフルマネージドサービス)上でMilvus 2.xを使用している場合、Cloud Consoleを使用して移行を開始することができます。
- コンパイルとビルド
まず、Milvus MigrationのソースコードをGitHubからダウンロードしてください。そして、以下のコマンドを実行してコンパイルします。
go get
ビルドする
このステップは milvus-migration という名前の実行ファイルを生成する。
- migration.yaml`を設定する。
migration.yaml`設定ファイルを用意し、ソース、ターゲット、その他の関連する設定の詳細を指定します。以下に設定例を示す:
# Milvus 1.x から Milvus 2.x へのマイグレーション設定
dumper:
worker:
リミット: 2
ワークモード: milvus1x
リーダー
バッファサイズ: 1024
ライター
バッファサイズ: 1024
ローダー
ワーカー
リミット: 16
meta:
モード: local
localFile: /outputDir/test/meta.json
ソース
モード:ローカル
ローカル
tablesDir: /db/tables/
ターゲット
モード: リモート
リモート
出力ディレクトリ: "migration/test/xx"
ak: xxxx
sk: xxxx
クラウド: aws
エンドポイント: 0.0.0.0:9000
リージョン: ap-southeast-1
バケット: a-bucket
useIAM: false
useSSL: false
checkBucket: true
milvus2x:
エンドポイント: localhost:19530
ユーザー名: xxxxx
パスワード: xxxxx
設定ファイルの詳細については、GitHubのこのページを参照してください。
- 移行ジョブの実行
マイグレーションを終了するには、dumpコマンドとloadコマンドを別々に実行する必要があります。これらのコマンドはデータを変換し、Milvus 2.xにインポートします。
注意:まもなくこのステップを簡略化し、1つのコマンドで移行を完了できるようにします。ご期待ください。
**ダンプ・コマンド
./milvus-migration dump --config=/{YourConfigFilePath}/migration.yaml
** ロードコマンド:**
./milvus-migration load --config=/{YourConfigFilePath}/migration.yaml
マイグレーション後、Milvus 2.xで生成されるコレクションには2つのフィールドが含まれます:idとdata` です。詳細はAttu というオールインワンのベクターデータベース管理ツールを使って見ることができます。
FAISS から Milvus 2.x へのマイグレーション
- FAISSデータの準備
Elasticsearch のデータを移行するには、FAISS データを用意する必要があります。マイグレーションをすぐに体験できるように、Milvus Migration のソースコードに FAISS テストデータ を用意しました。
- コンパイルとビルド
まず、Milvus MigrationのソースコードをGitHubからダウンロードしてください。そして、以下のコマンドを実行してコンパイルします。
go get
ビルドする
このステップで milvus-migration という名前の実行ファイルが生成される。
- migration.yaml`を設定する。
FAISSマイグレーション用の設定ファイル migration.yaml を用意し、マイグレーション元、マイグレーション先、その他関連する設定の詳細を指定する。以下に設定例を示す:
# FAISS から Milvus 2.x へのマイグレーション設定
dumper:
worker:
リミット: 2
workMode:FAISS
リーダー
バッファサイズ: 1024
ライター
バッファサイズ: 1024
ローダ
ワーカー
リミット: 2
ソース
モード: ローカル
ローカル:
FAISSFile: ./testfiles/FAISS/FAISS_ivf_flat.index
ターゲット
を作成する:
コレクション
名前: test1w
shardsNums: 2
dim: 256
metricType:L2
モード: リモート
リモート
outputDir: testfiles/output/
クラウド: aws
エンドポイント: 0.0.0.0:9000
リージョン: ap-southeast-1
バケット: a-bucket
ak: minioadmin
sk: minioadmin
useIAM: false
useSSL: false
checkBucket: true
milvus2x:
エンドポイント: localhost:19530
ユーザー名: xxxxx
パスワード: xxxxx
設定ファイルの詳細については、GitHubのこのページを参照してください。
- 移行ジョブの実行
Milvus1.xからMilvus2.xへのマイグレーションと同様に、FAISSマイグレーションでもdumpコマンドとloadコマンドの両方を実行する必要があります。これらのコマンドはデータを変換し、Milvus 2.xにインポートします。
注意: 近日中にこのステップを簡略化し、1つのコマンドで移行を完了できるようにする予定です。ご期待ください。
**ダンプコマンド
./milvus-migration dump --config=/{YourConfigFilePath}/migration.yaml
**ロードコマンド
./milvus-migration load --config=/{YourConfigFilePath}/migration.yaml
Attu](https://zilliz.com/attu)は、オールインワンのベクターデータベース管理ツールです。
今後の移行計画にご期待ください
将来的には、より多くのデータソースからの移行をサポートし、以下のような移行機能を追加する予定です:
RedisからMilvusへのマイグレーションをサポートします。
MongoDBからMilvusへのマイグレーションをサポートします。
リジューム可能なマイグレーションをサポート
ダンプとロードのプロセスを1つにまとめることで、マイグレーションコマンドを簡素化。
他の主流データソースからMilvusへのマイグレーションをサポート。
結論
Milvusの最新リリースであるMilvus 2.3は、データ管理のニーズの高まりに対応するエキサイティングな新機能とパフォーマンスの向上をもたらします。お客様のデータをMilvus 2.xに移行することで、これらの利点を引き出すことができ、Milvus移行プロジェクトは移行プロセスを合理的かつ容易にします。ぜひ一度お試しください。
***本ブログの情報は、2023年9月現在のMilvusおよびMilvus Migrationプロジェクトの状況に基づいています。最新の情報や手順については、公式のMilvus documentationをご確認ください。

読み続けて

How to Improve Retrieval Quality for Japanese Text with Sudachi, Milvus/Zilliz, and AWS Bedrock
Learn how Sudachi normalization and Milvus/Zilliz hybrid search improve Japanese RAG accuracy with BM25 + vector fusion, AWS Bedrock embeddings, and practical code examples.

Cosmos World Foundation Model Platform for Physical AI
NVIDIA's Cosmos platform enables safe, digital twin training of GenAI models for physical applications, overcoming data scarcity and safety challenges.

Zilliz Cloud BYOC Upgrades: Bring Enterprise-Grade Security, Networking Isolation, and More
Discover how Zilliz Cloud BYOC brings enterprise-grade security, networking isolation, and infrastructure automation to vector database deployments in AWS