




フィジカルAIのためのCosmos World Foundation Model Platform
GenAIについて話すとき、私たちは主にテキスト要約、Retrieval-Augmented Generation(RAG)、社内チャットボットなど、非物理分野での応用について議論します。この焦点は理解できます。なぜなら、これらのタスク向けにGenAIモデルを訓練するために必要なデータは比較的容易に入手できるからです。インターネット上には、GenAIアプリケーションを訓練するためのテキスト、画像、その他のモダリティのデータにアクセスできる豊富なソースがあります。
一方で、物理分野におけるGenAIアプリケーションの開発は、それほど進んでいません。実際のところ、物理世界でGenAIを適用することは、さまざまな業界における危険で退屈、かつ反復的なタスクを実行するうえで非常に有益になり得ることがわかっています。たとえば、高度なGenAIシステムは自動運転やロボット操作に使用できる可能性があります。
この記事では、NVIDIAチームによって開発されたCosmosというプラットフォームについて説明します。このプラットフォームは、物理世界のユースケース向けにGenAIモデルをファインチューニングするための基盤として機能します。それでは早速始めましょう!
Cosmosとは何か、そしてなぜ必要なのか
物理分野におけるGenAIアプリケーションの開発が、非物理分野ほど急速に進んでいない理由はいくつかあります。
第一の理由は、訓練データのスケーリングに関係しています。物理世界で役立つためには、AIモデルは与えられた指示と現在の状況に基づいて、次に起こり得る行動を予測できるように訓練される必要があります。これは、訓練データに画像だけでなく動画も含める必要があることを意味します。さらに、これらの動画はランダムなものであってはなりません。入力動画は、特定の状況でモデルが適切に応答するよう訓練するのに役立つ、関連する観察と行動を示す必要があります。この種のデータは見つけるのが難しいだけでなく、処理も複雑です。
第二の理由は安全性に関係しています。ご存じのとおり、物理世界でAIモデルを訓練することは、人々や環境に深刻なリスクをもたらす可能性があります。たとえば、自動運転向けに訓練されたAIシステムによるたった一つの誤予測が、重大な交通事故につながる可能性があります。したがって、モデルが周囲と安全に相互作用できる物理世界のデジタルツイン内で訓練することが望ましいのです。
Cosmosは、これらの課題に対処するためにNVIDIAによって開発されたプラットフォームです。これにより、デジタルツイン環境で物理AI(すなわち、物理世界のアプリケーション向けに設計されたAIモデル)を訓練およびファインチューニングできます。これによって、実際の物理世界で訓練またはデプロイする必要なく、物理AIモデルの現実世界での挙動をデジタルに観察できます。
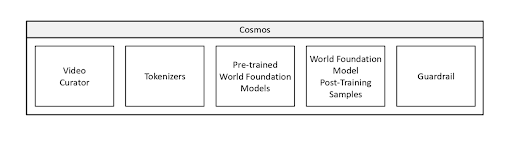
図1. Cosmosプラットフォームのコンポーネント (出典)
Cosmosプラットフォームは複数のコンポーネントで構成されており、それぞれが物理AIモデルの訓練プロセスにおける特定の段階を担います。これらのコンポーネントには、動画キュレーション、トークン化、事前訓練、事後訓練、ガードレールが含まれます。
これらのコンポーネントを実行した結果として、訓練済みの物理AIモデルが得られます。このモデルは、視覚的観察のシーケンス(すなわち動画)と、ある時点での摂動を入力として受け取り、予測された将来の観察を出力として生成します。入力される摂動は、モデルによって実行される行動やテキストベースの指示など、さまざまな形式を取り得ます。
将来の観察を完全にデジタル環境内で予測することで、このモデルは現実世界の挙動の模倣、ポリシーの観察と訓練、合成動画生成など、さまざまな用途に役立ちます。

図2. Cosmosプラットフォームで訓練された物理AIモデルの入力と出力 (出典)
Cosmosプラットフォームのコンポーネントとその仕組み
前述のとおり、Cosmos には複数のコンポーネントが含まれています:動画キュレーション、トークナイザー、事前学習、事後学習、そしてガードレールです。このセクションでは、動画キュレーションコンポーネントから始めて、これらの各コンポーネントについて説明します。
動画キュレーション
このコンポーネントの主な目的は、プロプライエタリおよびオープンソースのデータセットの両方から取得した生の動画データをキュレーションし、フィルタリングすることです。ご存じのとおり、動画データには多くのノイズが含まれていることが多いため、物理 AI の学習に使用される最終データセットの品質を確保するためにフィルタリングする必要があります。
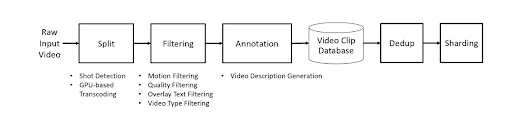
図 3. Cosmos プラットフォームにおける動画キュレーションのワークフロー (出典)
データをフィルタリングするために、Cosmos プラットフォームはいくつかのステップに従います。最初のステップは分割プロセスです。
Cosmos は動画分割にショット検出アルゴリズムを使用します。生の動画ソースは、ショットの変化がない任意の長さの短いクリップに分割されます。これにより、各動画セグメントが、モデルの学習に有用な一貫したシーンで構成されることが保証されます。
複数のベンチマークにおけるさまざまな手法の性能に基づき、Cosmos は分割プロセスに TransNetV2 を使用します。
分割後、Cosmos はクリップをさらに精緻化するために、以下を含むいくつかの動画フィルタリング手法を適用します:
モーションフィルタリング:静的なクリップや急激なカメラの動きを含むクリップを削除します。
視覚品質フィルタリング:低解像度または低品質のクリップを除外します。
テキストオーバーレイフィルタリング:クリップ内でポスト処理中に追加されたテキストを削除します。
動画タイプフィルタリング:不要な動画タイプを除外します。
次に、精緻化されたクリップのコレクションは Visual Language Model (VLM) を使用して注釈付けされます。注釈結果は、各クリップの内容を説明するテキストです。ベンチマーク結果に基づき、NVIDIA チームは注釈生成用の VLM として VILA を選択しました。
注釈が完了すると、次のステップは重複排除です。各動画は InternVideo と呼ばれる動画埋め込みモデルを使用して埋め込みに変換されます。その後、埋め込みのコレクションがクラスタリングされ、各クラスタ内のペアワイズ距離が計算されて、非常によく似た動画が特定されます。重複が見つかった場合は、より高解像度の動画が学習データセット用に選択されます。
トークナイザー
トークナイザーは、各動画を数値表現に変換するための重要なコンポーネントです。AI モデルは生の動画を直接処理できないためです。Cosmos プラットフォームで使用されるトークナイザーは、NVIDIA が開発した Cosmos-Tokenizer と呼ばれる専用トークナイザーであり、各動画に対して連続トークン化と離散トークン化の両方を生成できます。
連続トークンと離散トークンの両方を生成できることは不可欠です。なぜなら次の段階で、Cosmos は拡散戦略と自己回帰戦略という 2 つの異なるモデル事前学習アプローチを提供するためです。拡散戦略は学習に連続トークンを必要とする一方、自己回帰戦略は離散トークンに依存します。
効果的なトークナイザーの重要な側面の 1 つは、動画のような高次元データを、品質低下を最小限に抑えながら低次元表現へ圧縮する能力です。この点で、Cosmos-Tokenizer は CogVideoX-Tokenizer、FLUX-Tokenizer、VideoGPT-Tokenizer などの他のトークナイザーを上回っています。
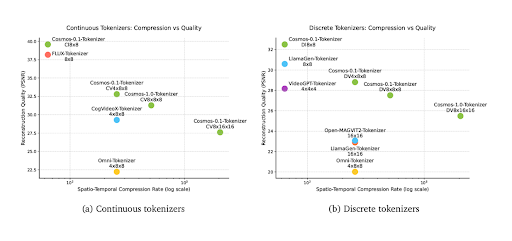
図 4. Cosmos-Tokenizer と他の動画トークナイザーにおける時空間圧縮率 - 再構成品質の性能 (出典)
Cosmos-Tokenizer の優れた性能の背後にある秘密は、その設計にあります。これは因果的時間設計を採用しており、動画内の各フレームが、そのフレーム自身とそれ以前のフレームのみを使用してトークン化されることを意味します。言い換えると、あるフレームのトークン化は、将来のフレームの影響を受けません。
長さが t 秒の任意の入力動画に対して、動画はまず2段階ウェーブレット変換を用いて4分の1にグループ化およびダウンサンプリングされます。たとえば、最初のグループはフレーム1から4、2番目のグループはフレーム5から8、というように構成されます。次に、Cosmos-Tokenizer アーキテクチャ内の一連のエンコーダブロックが、因果的な方法でダウンサンプリングされた出力を処理し、動画の次元数をさらに削減します。
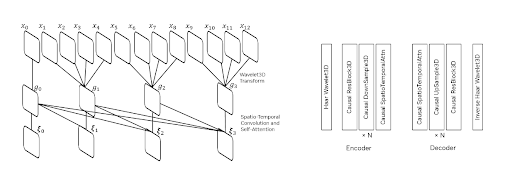
図5. Cosmos-Tokenizer の時間的因果性設計 (出典)
Cosmos-Tokenizer の各エンコーダブロックは、上の可視化に示されているように、残差層、ダウンサンプリング層、時空間アテンション層の組み合わせで構成されています。ダウンサンプリング層の出力は時空間アテンション層に渡され、動画の空間的特徴と時間的特徴の両方を捉えます。まず、入力は空間情報を捉えるために2D畳み込み層を通過し、その後、時間情報を抽出するために時間畳み込み層を通過します。
圧縮されたトークンから動画を再構築するために、トークンは Cosmos-Tokenizer の一連のデコーダブロックを使用してアップサンプリングされます。各デコーダブロックは、上の画像に示されているように、エンコーダブロックと同様の構造を持っています。唯一の違いは、入力をダウンサンプリングする代わりに、デコーダが動画を再構築するためにそれをアップスケールする点です。
モデルの事前学習 I: 拡散ベースモデル
モデル事前学習の主な目的は、現在の観測と過去の動画を入力として与えられたときに、意味のある未来の動画を生成する方法を理解するベースモデルを開発することです。Cosmos には、拡散ベースモデルと自己回帰ベースモデルという2つの異なる事前学習済みモデルがあります。このセクションでは、拡散ベースモデルについて詳しく説明します。
拡散ベースモデルは合計2つあり、1つは7Bパラメータ、もう1つは14Bパラメータを持ちます。両方のモデルは2段階のプロセスで学習されます。
第1段階では、モデルはテキストプロンプトを入力として受け取り、そのプロンプトに基づいて対応する動画を生成します。この段階の後に学習されたモデルは Text2World と呼ばれます。第2段階では、Text2World モデルは、現在の観測を表す追加の入力動画を使用してさらにファインチューニングされます。言い換えると、テキストプロンプトと入力動画の両方が与えられた場合に、モデルは最も確率の高い次の動画を予測するように学習されます。この第2段階の後に学習されたモデルは Video2World と呼ばれます。
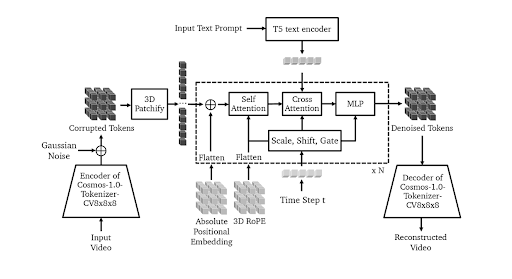
図6. Video2World 拡散ベースモデルの事前学習アーキテクチャ (出典)
上の可視化では、Video2World を学習するための全体的なセットアップを確認できます。まず、現在の観測を表す入力動画は Cosmos-1.0-Tokenizer-CV8x8x8 のエンコーダを使用してトークン化され、入力動画の連続トークンが生成されます。次に、これらのトークンはガウスノイズを追加することで破損されます。破損されたトークンは依然として高次元であるため、モデルで処理できるようにパッチ化され、平坦化される必要があります。
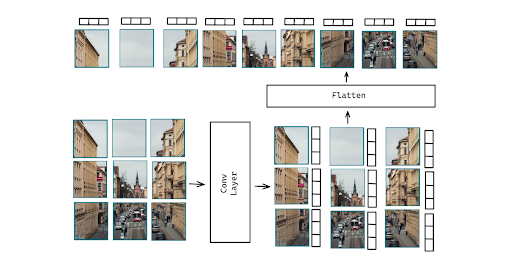
図7. 画像パッチ化プロセスの例
平坦化プロセス後に得られたテンソルは、一連の Transformer ブロックを通過します。各 Transformer ブロックでは、入力に平坦化された位置埋め込みが注入され、各ベクトル要素に絶対位置情報を追加し、学習損失を削減します。次に、出力は自己アテンション層やクロスアテンション層を含む一連のアテンション層によって処理されます。
アテンション層では、3D RoPEとタイムステップ(t)を使用して、時空間情報が入力に統合されます。モデルがテキストプロンプトに条件付けられた動画を生成できるようにするため、T5テキストエンコーダによって生成されたテキスト埋め込みが、クロスアテンション層内で入力に組み込まれます。最後に、クロスアテンション層の出力は線形層を通過し、このプロセスが複数のTransformerブロックを通じて繰り返されます。
最後のTransformerブロックは、最終的なノイズ除去済みトークンを生成します。次に、これらのノイズ除去済みトークンをアップサンプリングしてデコードする必要があり、これはCosmos-1.0-Tokenizer-CV8x8x8のデコーダによって行われます。最終結果として、予測された将来の動画が得られます。
モデルの事前学習 II:自己回帰ベースモデル
2つ目の事前学習済みモデルは、自己回帰ベースモデルです。このモデルには、50億パラメータのものと130億パラメータのものという2つのバリアントがあります。事前学習プロセスも2つの段階で構成されています。第1段階では、モデルは現在の動画観測に基づいて将来の動画フレームを予測することのみを目的として学習されます。第2段階では、テキストを追加の入力として組み込むことで、モデルがさらに事前学習されます。つまり、最終的なモデルは入力動画とテキストプロンプトの両方を入力として受け取り、将来の動画を出力として生成します。
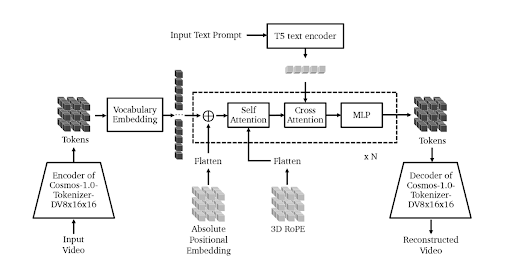
図8. Video2World自己回帰ベースモデルの事前学習アーキテクチャ (出典)
事前学習プロセスは、前のセクションで説明した拡散ベースモデルのものと非常によく似ています。まず、入力動画がトークンに変換されます。ただし、拡散ベースのアプローチとは異なり、自己回帰モデルでは連続トークンではなく離散トークンが必要です。そのため、事前学習プロセスではCosmos-1.0-Tokenizer-DV8x16x16を使用して、入力動画を離散トークンに変換します。これらの離散トークンは次に埋め込み層に入力され、次のコンポーネントで処理できる状態の埋め込みへと変換されます。
次に、入力は一連のTransformerブロックを通過します。各ブロックは、セルフアテンション層、クロスアテンション層、線形層で構成されています。各Transformerブロックでは、まず絶対位置埋め込みが入力に追加され、各トークンに絶対位置情報が与えられます。
セルフアテンション層内では、トークンの相対位置に関する情報を注入するために3D RoPEが使用されます。一方、テキスト情報はクロスアテンション層内で入力に統合されます。最後に、入力は末尾で線形層を通過します。このプロセスは、最終ブロックに到達するまで複数のTransformerブロックを通じて繰り返されます。
最後のTransformerブロックは、最終的なトークン表現を生成します。これらのトークンを予測動画に変換するには、Cosmos-1.0-Tokenizer-DV8x16x16のデコーダを使用してアップサンプリングし、デコードする必要があります。
モデルの事後学習
前のセクションで述べたように、モデルの事前学習の主な目的は、過去の動画フレームと現在の観測に基づいて一貫性のある将来の動画を生成できるベースモデルまたは基盤モデルを開発することです。このモデルを特定の領域に特化させるために、ファインチューニングなどの事後学習技術を適用できます。
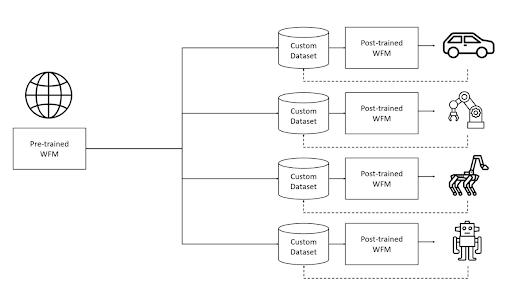
図9. 事前学習済み物理AIモデルを事後学習によって特定タスクに使用する方法の図解 (出典)
拡散ベースモデルと自己回帰ベースモデルのどちらも、カメラ制御、ロボット操作、自動運転などの特定タスクにおける動画予測で優れた性能を発揮するようにファインチューニングできます。カメラ制御を例に取りましょう。以下は、モデルをカメラ制御タスクでファインチューニングした後のフレームごとの結果例です。

図10. カメラ制御タスクでファインチューニングされた拡散ベースモデルから生成された動画の例 (Source)
カメラ制御向けにファインチューニングされたモデルは、初期動画と、左折、右折、前進、後退などの制御プロンプトに基づいて、リアルな動画を生成できます。モデルによって生成された予測動画は、実際にデプロイされる前に、現実の物理世界におけるAIシステムの挙動をシミュレートし評価するために使用できます。
ガードレール
このモデルは動画コンテンツを生成できるため、その利用を規制する安全対策を実装することが極めて重要です。NVIDIAチームは、プリガードとポストガードという2つの安全段階を導入しました。
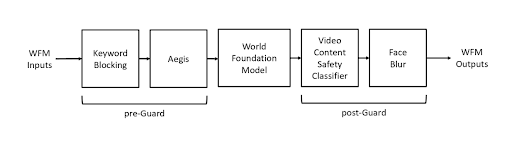
図11. Cosmosプラットフォームに実装されたガードレールのワークフロー (Source)
プリガード段階では、LLMベースのガードレールを使用して、ユーザーが送信する可能性のある有害なテキストプロンプトを検出します。プロンプトが安全でない、または有害であると判断された場合、システムは動画生成を防止し、代わりにエラーメッセージを表示します。
一方、ポストガード段階では、モデルに送信された入力動画と、モデルによって生成された動画の両方を監視します。動画コンテンツが安全かどうかを判断するために、NVIDIAチームはSigLIPモデルを使用して各フレームから埋め込みを抽出し、その後、単純なMLP分類器を用いて分類します。
ポストガード段階のもう1つの側面は、顔ぼかしフィルターです。このステップでは、RetinaFaceと呼ばれる顔検出モデルを使用して、人間の顔を含むフレームの一部をぼかし、プライバシーを確保します
拡散ベースモデルおよび自己回帰ベースモデルの実験結果
事前学習段階後の拡散ベースモデルと自己回帰ベースモデルの両方の結果は、定性的に評価されています。このセクションでは、拡散ベースモデルから始めて、両モデルによって生成された出力のいくつかを確認します。
拡散ベースモデルには、7Bパラメータと14Bパラメータの2つのバリアントがあります。全体として、どちらのモデルもテキストプロンプト条件付けによく一致した高品質な動画を生成します。

図12. 指示プロンプトを与えたVideo2World拡散ベースモデルから生成された動画の例 (Source)
上の可視化に示されているように、どちらのバリアントも高品質な動画を生成しますが、14Bモデルは各フレーム内のより細かな動きのディテールをより効果的に捉えます。さらに、複雑なシーンと安定した動きを伴う動画の生成に優れています。拡散ベースモデルによって生成された実際の動画は、Cosmos websiteで閲覧できます。
同じ傾向は自己回帰ベースモデルでも観察され、このモデルにも5Bパラメータと13Bパラメータの2つのバリアントがあります。全体として、13Bモデルは5Bモデルと比較して、よりシャープな動画とより滑らかな動きを生成します。

図13. 指示プロンプトを与えたVideo2World拡散ベースモデルから生成された動画の例 (Source)
自己回帰ベースモデルは全体として良好に機能するものの、動画生成中に一貫性のないシーンを生成することがあります。注目すべき失敗例の1つは、以下に示すように、フレーム内にランダムな物体が突然現れることです。ただし、100件のテスト入力における13Bモデルの失敗率は2%未満であることが観察されており、これらのエラーはまれな事象であることを示しています。

図14. Video2World自己回帰ベースモデルの失敗例 (Source)
現実世界における物理AIを表現するためのモデルの適性を判断するために、NVIDIAチームは2つの主要な側面、すなわち3D一貫性と物理法則との整合性に基づいて定量評価を実施しました。
3D一貫性
強い3D一貫性を維持することは極めて重要です。なぜなら、このモデルの主な目的は、実際の3D環境におけるフィジカルAIの挙動をシミュレートすることだからです。3D一貫性を評価するために、2つの指標群が観察されました。幾何学的一貫性(Sampson error、Pose estimation)とビュー合成一貫性(PSNR、SSIM、LPIPS)です。
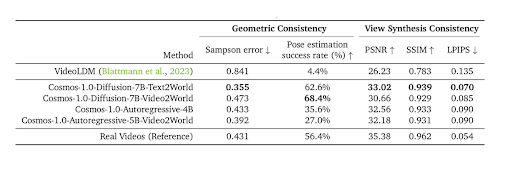
図15. Cosmosモデルにおける3D一貫性の評価 (Source)
両方の指標の結果は、拡散ベースおよび自己回帰ベースのモデルのいずれも、NVIDIAのベースラインモデルと比較して3D一貫性が大幅に向上していることを示しています。これは、これらのモデルが非常にリアルな3D動画を生成できる能力を示しており、実世界のシミュレーションにおいて価値があることを示しています。
物理法則との整合性
3D一貫性に加えて、生成された動画は、フィジカルAIの挙動が現実的であることを保証するために、物理法則にも従う必要があります。これを評価するために、NVIDIAチームは、シミュレートされた実動画と、モデルによって生成された同じシナリオの動画を比較しました。ピクセルレベル(PSNR、SSIM)、特徴レベル(DreamSim)、オブジェクトレベル(IoU)という複数のレベルでいくつかの指標が使用されました。
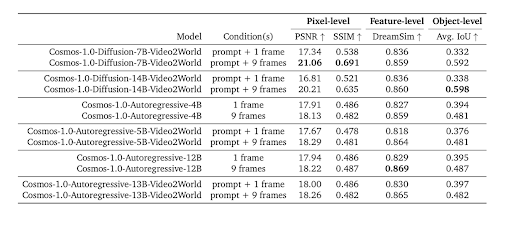
図16. Cosmosモデルにおける物理的整合性の評価 (Source)
ピクセルレベルの結果に基づくと、拡散ベースのモデルは一般に、自己回帰ベースのモデルと比較してより高品質な動画を生成します。しかし、すべてのモデルは依然として、物理法則に完全に従うことに課題を抱えています。その結果、将来のモデル能力を強化するために、データキュレーションとモデル設計の改善はすでにNVIDIAのロードマップに含まれています。
結論
NVIDIAが開発したCosmosプラットフォームは、GenAIを物理世界に統合する上での重要な進歩を表しています。データのスケーラビリティや安全性に関する懸念などの主要な課題に対処することで、Cosmosは制御されたデジタルツイン環境でフィジカルAIモデルのトレーニングとファインチューニングを可能にします。動画キュレーション、トークン化、モデルの事前トレーニング、事後トレーニング、ガードレールなどのパイプラインにより、Cosmosは、将来の観測を予測し、ロボティクス、自動運転、カメラ制御など、さまざまな物理的アプリケーション向けにリアルな動画出力を生成できるAIモデルの開発を促進します。
モデルは優れた3D一貫性を備えた高品質な動画を生成できますが、依然として対処が必要な大きな課題があります。生成された動画における物理法則へのモデルの準拠を改善するには、データキュレーションとモデル設計のさらなる改善が必要です。
読み続けて

My Wife Wanted Dior. I Spent $600 on Claude Code to Vibe-Code a 2M-Line Database Instead.
Write tests, not code reviews. How a test-first workflow with 6 parallel Claude Code sessions turns a 2M-line C++ codebase into a daily shipping pipeline.

Migrating from S3 Vectors to Zilliz Cloud: Unlocking the Power of Tiered Storage
Learn how Zilliz Cloud bridges cost and performance with tiered storage and enterprise-grade features, and how to migrate data from AWS S3 Vectors to Zilliz Cloud.

What is the K-Nearest Neighbors (KNN) Algorithm in Machine Learning?
KNN is a supervised machine learning technique and algorithm for classification and regression. This post is the ultimate guide to KNN.