




Ollama、Llama 3.2、Milvusによる関数呼び出し
2024年9月25日、ラマ3.2にアップデート。
LLMを使った関数呼び出しは、AIに世界とつながる力を与えるようなものです。LLMをユーザー定義関数やAPIなどの外部ツールと統合することで、現実世界の問題を解決するアプリケーションを構築できます。
このブログポストでは、Llama 3.2をMilvusのような外部ツールやAPIと統合して、強力でコンテキストを意識したアプリケーションを構築する方法を確認します。
関数呼び出し入門
GPT-4、Mistral Nemo、そしてLlama 3.2のようなLLMは、関数を呼び出す必要があるときにそれを検出し、その関数を呼び出すための引数をJSONで出力できるようになりました。これにより、AIアプリケーションはより多機能で強力になります。
関数呼び出しにより、開発者は次のようなものを作成できる:
データの抽出とタグ付け(例:Wikipediaの記事から人名を抽出する)のためのLLMパワー・ソリューション
自然言語をAPIコールや有効なデータベースクエリに変換するアプリケーション
知識ベースと対話する会話型知識検索エンジン
**ツール
Ollama**:LLMのパワーをあなたのラップトップにもたらし、ローカル操作を簡素化します。
Milvus**:効率的なデータの保存と検索を可能にするベクター・データベース。
ラマ3.2-3B**:3.1モデルのアップグレード版で、多言語に対応し、コンテキストの長さが128Kと大幅に長くなり、ツールの活用が可能になりました。
Llama 3.2とOllamaを使う
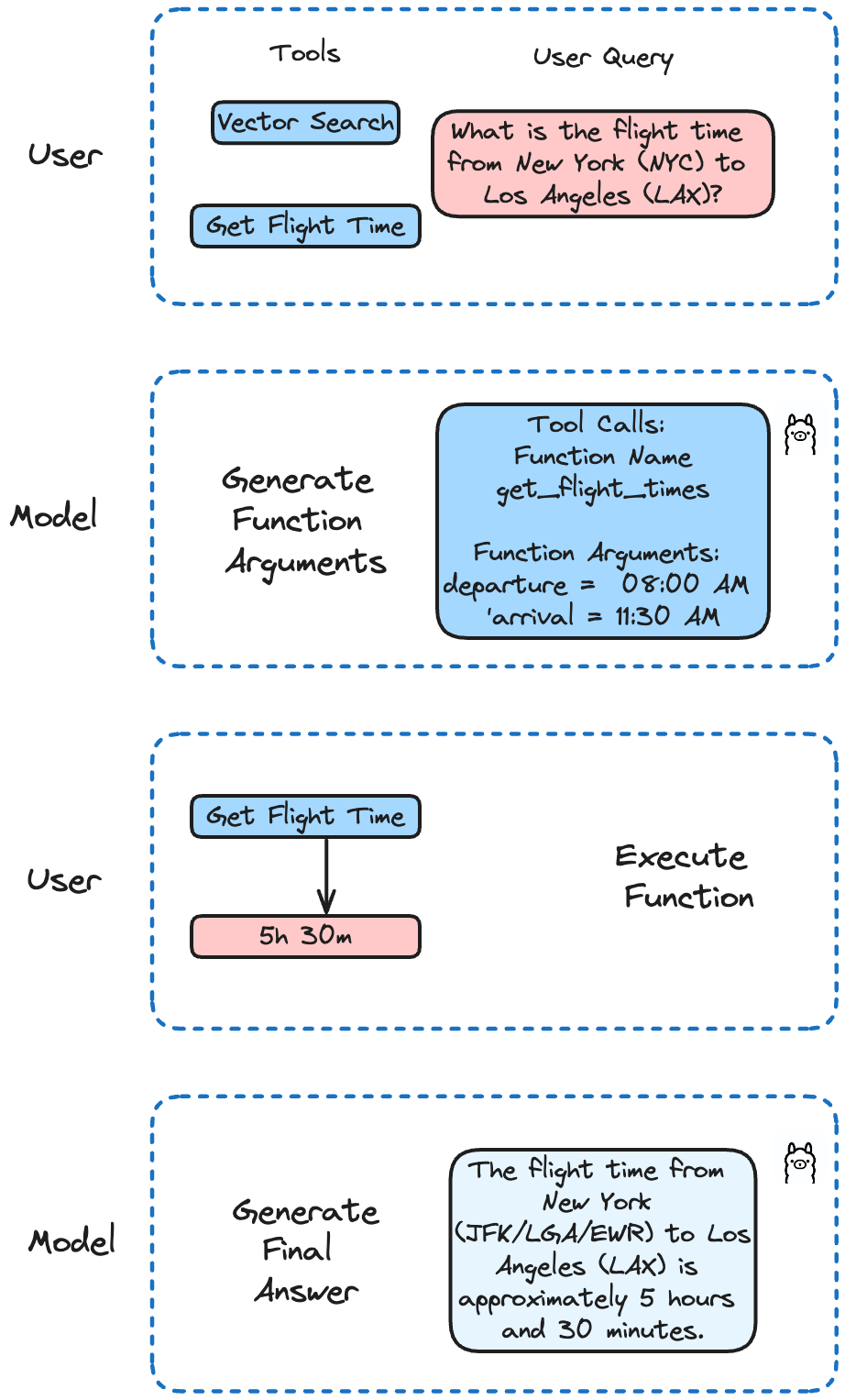
Llama 3.2は関数呼び出しの微調整を行いました。単一、入れ子、並列の関数呼び出しや、複数ターンの関数呼び出しがサポートされています。これは、AIが複数のステップや並列処理を含む複雑なタスクを処理できることを意味します。
この例では、Milvusで飛行時間を取得し検索を実行するAPIコールをシミュレートするために、さまざまな関数を実装します。Llama 3.2は、ユーザーのクエリに基づいて呼び出す関数を決定します。
Install Dependencies
まず、すべてのセットアップを行いましょう。Ollamaを使ってLlama 3.2をダウンロードする:
ollama run llama3.2
これでモデルがラップトップにダウンロードされ、Ollamaで使えるようになる。次に、必要な依存関係をインストールする:
pip install ollama openai "pymilvus[model]""
ここではMilvus Liteにmodel拡張をインストールします。model拡張をインストールすると、Milvusで利用可能なモデルを使ってデータを埋め込むことができます。
Milvus にデータを埋め込む
それでは、Milvusにデータを挿入してみましょう。これはLlama 3.2が関連性があると判断した場合、後で検索するためのデータです!
データの作成と挿入
from pymilvus import MilvusClient, model
embedding_fn = model.DefaultEmbeddingFunction()
docs = [
「人工知能は1956年に学問分野として設立されました、
"アラン・チューリングは、AIの実質的な研究を行った最初の人物です。"、
「チューリングはロンドンのマイダ・ベイルで生まれ、イングランド南部で育った、
]
vectors = embedding_fn.encode_documents(docs)
# 出力ベクトルは768次元で、先ほど作成したコレクションと一致します。
print("Dim:", embedding_fn.dim, vectors[0].shape) # 次元: 768 (768,)
# 各エンティティは、id、ベクトル表現、生テキスト、サブジェクトラベルを持つ。
data = [
{"id": i, "vector": vectors[i], "text": docs[i], "subject":"history"}。
for i in range(len(vectors))
]
print("Data has", len(data), "entities, each with fields:", data[0].keys())
print("Vector dim:", len(data[0]["vector"]))
# コレクションを作成し、データを挿入する
client = MilvusClient('./milvus_local.db')
client.create_collection(
collection_name="demo_collection"、
dimension=768, # このデモで使用するベクトルは768次元です。
)
client.insert(collection_name="demo_collection", data=data)
新しいコレクションには3つの要素があります。
使用する関数を定義する
この例では、2つの関数を定義している。最初の関数はフライト時間を取得するためのAPIコールをシミュレートします。もう一つはMilvusの検索クエリを実行するものです。
from pymilvus import model
インポート json
import ollama
embedding_fn = model.DefaultEmbeddingFunction()
# 飛行時間を取得するためのAPIコールをシミュレートする。
# 実際のアプリケーションでは、これはライブのデータベースまたはAPIからデータを取得します。
def get_flight_times(departure: str, arrival: str) -> str:
flights = {
'NYC-LAX':'NYC-LAX': {'departure': '08:00 AM', 'arrival': '11:30 AM', 'duration': '5h 30m'}、
LAX-NYC':{出発」:「02:00 PM」、「到着」:「10:30 PM」、「所要時間」:「5時間30分」}、
LHR-JFK':LHR-JFK': {'departure': '10:00 AM', 'arrival': '01:00 PM', 'duration': '8h 00m'}、
JFK-LHR':{出発時刻: '09:00 PM', '到着時刻': '09:00 AM', '所要時間': '7h 00m'}、
CDG-DXB':{出発': '11:00 AM', '到着': '08:00 PM', '所要時間': '6h 00m'}、
DXB-CDG':DXB-CDG': {'departure': '03:00 AM', 'arrival': '07:30 AM', 'duration': '7h 30m'}、
}
key = f'{出発}-{到着}'.upper()
return json.dumps(flights.get(key, {'error': 'フライトが見つかりません'}))
# 人工知能に関連するデータをベクトルデータベースで検索する
def search_data_in_vector_db(query: str) -> str:
query_vectors = embedding_fn.encode_queries([query])
res = client.search(
コレクション名="demo_collection"、
data=query_vectors、
limit=2、
output_fields=["text", "subject"], # 返されるフィールドを指定します。
)
print(res)
return json.dumps(res)
これらの関数を使えるようにLLMに指示を与える
では、定義した関数を使えるようにLLMに指示を出してみよう。
def run(model: str, question: str):
client = ollama.Client()
# ユーザークエリで会話を初期化する
messages = [{"role": "user", "content": question}] # ユーザークエリで会話を初期化する
# 最初のAPIコール:クエリと関数の説明をモデルに送信する
response = client.chat(
model=model、
messages=messages、
tools=[
{
"type":function": "関数"、
「function":{
"name":"get_flight_times"、
"description":"2都市間のフライト時間を取得"、
「パラメータ":{
"type":"object": "オブジェクト"、
"プロパティ":{
"出発":{
"type":"string": "文字列"、
"description":「出発都市(空港コード)」、
},
"arrival":{
"type":「文字列
"description":「到着都市(空港コード)"、
},
},
"required":[出発", "到着"]、
},
},
},
{
"type":関数
"関数":{
"name":"search_data_in_vector_db"、
"description":「ベクターデータベース内の人工知能データを検索する、
「パラメータ":{
"type":object": "オブジェクト"、
"プロパティ":{
"query":{
"type":"string": "文字列"、
"description":「検索クエリ
},
},
"required":["クエリ"]、
},
},
},
],
)
# 会話の履歴にモデルのレスポンスを追加する
messages.append(response["message"])
# モデルが提供された関数を使うことを決めたかチェックする
if not response["message"].get("tool_calls"):
print("The model didn't use the function. Its response was:")
print(response["message"]["content"])
リターン
# モデルによって行われた関数呼び出しを処理する
if response["message"].get("tool_calls"):
available_functions = { "get_flight_times
"get_flight_times": get_flight_times、
"search_data_in_vector_db": search_data_in_vector_db、
}
for tool in response["message"]["tool_calls"]:
function_to_call = available_functions[tool["function"]["name"]].
function_args = tool["function"]["arguments"]
function_response = function_to_call(**function_args)
# 会話にファンクションレスポンスを追加する
メッセージ.append(
{
"role":"tool"、
"content": function_response、
}
)
# 2回目のAPIコール:モデルから最終的なレスポンスを取得する
final_response = client.chat(model=model, messages=messages)
print(final_response["message"]["content"])
使用例
特定のフライトの時刻を取得できるか確認してみましょう:
question = "ニューヨーク(NYC)からロサンゼルス(LAX)までのフライト時間は?"
run('llama3.2', question)
この結果は
ニューヨーク(JFK/LGA/EWR)からロサンゼルス(LAX)までのフライト時間は約5時間30分です。ただし、この時間は航空会社、フライトスケジュール、待ち時間や遅延の可能性により異なる場合がありますのでご注意ください。最新かつ正確なフライト情報については、常にご利用の航空会社にご確認いただくことをお勧めします。
では、Llama 3.2がMilvusを使ってベクトル検索ができるか見てみましょう。
question = "人工知能が創設されたのはいつですか?"
run("llama3.2", question)
これはMilvus Searchを返す:
データ["[{'id':0, 'distance':0.5738513469696045, 'entity':{'text': '人工知能は1956年に学問分野として設立された', 'subject': 'history'}}, {'id':1, 'distance':0.4090226888656616, 'entity':{'text': 'アラン・チューリングは、AIの実質的な研究を行った最初の人物である。', 'subject': 'history'}}]"]
人工知能は1956年に学問分野として設立された。
結論
LLMを使った関数呼び出しは可能性の世界を広げます。Llama3.2をMilvusやAPIのような外部ツールと統合することで、特定のユースケースや実用的な問題に対応した、強力でコンテキストを意識したアプリケーションを構築することができます。
Milvus](https://zilliz.com/what-is-milvus)やGithubにあるコードを自由にチェックし、私たちのDiscordに参加してコミュニティと経験を共有してください。

読み続けて

Zilliz Cloud Enterprise Vector Search Powers High-Performance AI on AWS
Zilliz Cloud on AWS powers secure, scalable, ultra-fast vector search for enterprise AI apps, with BYOC, sub-10ms latency, and zero-DevOps simplicity.

Bringing AI to Legal Tech: The Role of Vector Databases in Enhancing LLM Guardrails
Discover how vector databases enhance AI reliability in legal tech, ensuring accurate, compliant, and trustworthy AI-powered legal solutions.

Building RAG Pipelines for Real-Time Data with Cloudera and Milvus
explore how Cloudera can be integrated with Milvus to effectively implement some of the key functionalities of RAG pipelines.