




検索拡張世代の評価:トゥルーレンズ+ミルバス
この記事はThe New Stackに掲載されたもので、許可を得てここに再掲載している。

大規模言語モデル(LLM)の人気の高まりは、MilvusやZilliz Cloudのような専用のベクトルデータベース、FAISSのようなベクトル検索ライブラリ、従来のデータベースと統合されたベクトル検索プラグインなど、ベクトル検索技術の台頭に拍車をかけている。
ますます、ベクトル検索は、retrieval augmented generation、またはRAGs、質問応答アプリケーションの形で、生成AIのための本質的な企業ユースケースとなっている。このスタイルの構築により、LLMは、質問に答えるためのコンテキストとして使用できる検証済みの知識ベースに簡単にアクセスすることができる。 Milvusは拡張性の高いオープンソースのベクトルデータベースこのアプリケーションのために作られたである。
RAGの構築
効果的なRAGスタイルのLLMアプリケーションを構築する場合、検索品質に大きく影響する多くの構成から選択することができる。その中には以下のようなものがある:
ベクターDBの構築
- データの選択
- 埋め込みモデル
- インデックスタイプ
アプリケーションの要件に正確に一致する高品質のデータを見つけることは非常に重要です。正しいデータがなければ、検索プロセスで適切な結果が得られない可能性があります。
データを選択した後、検索品質に大きく影響する埋め込みモデルを検討します。知識ベースが正しい情報を含んでいても、埋め込みモデルがドメインの意味理解を必要とする場合、検索結果は正しくないかもしれません。
コンテキストの関連性は、検索品質を評価するための有用な指標であり、これらの選択は検索品質に大きく影響します。
最後に、インデックスの種類はセマンティック検索の効率に大きな影響を与える。これは特に大規模なデータセットの場合に当てはまります。この選択により、想起率、スピード、必要なリソースを交換することができます。Milvusはフラットインデックス、積量子化ベースインデックス、グラフベースインデックスなど様々なインデックスタイプをサポートしています。様々なインデックスタイプ](https://milvus.io/docs/index.md)についてはこちらをご覧ください。
検索
- 検索されたコンテキストの量(上位k個)
- チャンクサイズ
トップkはよく議論されるパラメータで、検索されるコンテキスト・チャンクの数を制御する。トップkが高いほど、必要な情報が検索される可能性が高くなり、LLMが無関係な情報を回答に取り込む可能性が高くなります。単純な質問では、トップkを低くすることが最も効果的です。
チャンクサイズは、検索される各コンテキストのサイズを制御します。より大きなチャンクサイズはより複雑な質問に役立ちますが、小さなチャンクはわずかな情報量で答えられる単純な質問には十分です。
これらの選択肢の多くには、万能というものはありません。データのサイズやタイプ、使用するLLM、アプリケーションなどによって、パフォーマンスは大きく異なります。特定のユースケースに対する検索の品質を評価するための評価ツールが必要です。TruLens の出番です。
LLM の追跡と評価のための TruLens
TruLens は、RAG などの LLM アプリのパフォーマンスを評価および追跡するためのオープンソースライブラリです。TruLens を使用すれば、LLM 自体を使用して出力や検索品質などを評価することもできます。
LLMアプリケーションを構築する際、多くの人が最も重要視するのは幻覚です。RAGは、検索された文脈をLLMに提供することで、正確な情報を確保することに大いに役立つが、それを保証することはできない。私たちのアプリで幻覚がないことを検証するには、ここで評価が不可欠です。TruLensはこの必要性に対して、文脈の関連性、根拠性、回答の関連性という3つのテストを提供しています。それぞれを確認して、どのように役立つかを理解しよう。
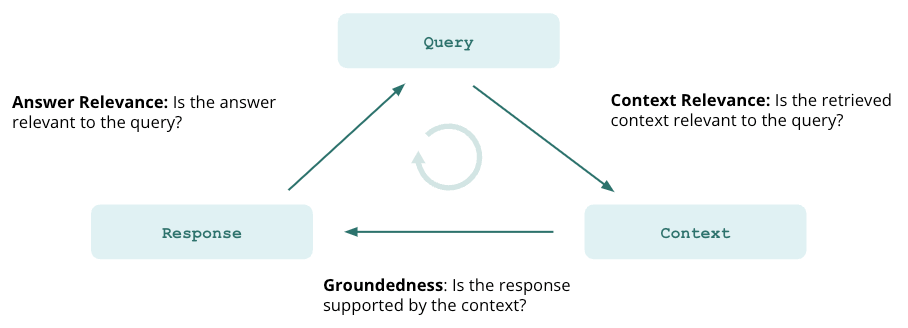
コンテキストとの関連性
RAGアプリケーションの最初のステップは検索である。検索の質を検証するために、コンテキストの各チャンクが入力クエリに関連していることを確認したい。なぜなら、LLMはこのコンテキストを使って答えを作るので、コンテキストに無関係な情報があると、幻覚に織り込まれてしまう可能性があるからである。
根拠
コンテキストが取得された後、LLMはそれを使って答えを作成する。LLMはしばしば提供された事実から逸脱し、誇張したり拡大したりして、正しく聞こえる答えを作る。私たちのアプリケーションの根拠を検証するために、回答を別々の文に分け、検索されたコンテキストの中からそれぞれを裏付ける証拠を独自に探す必要があります。
回答の関連性
最後に、私たちの回答はまだ元の質問に役立つように答える必要があります。ユーザーの入力に対する最終的な回答の関連性を評価することで、これを検証することができます。
幻覚のないRAG
この3つの要素について満足のいく評価を得ることで、我々のアプリケーションの正しさについて微妙な表現をすることができる。言い換えれば、ベクトル・データベースに正確な情報しか含まれていなければ、RAGが提供する答えも正確である。
具体化する
前に述べたように、RAGのコンフィギュレーションの選択の多くは、幻覚に大きな影響を与える可能性がある。これを説明するために、ウィキペディアの小さな都市の記事の上にRAGの質問応答アプリケーションを構築する。LlamaIndexはこのアプリケーションのフレームワークとして機能する。
この例はGoogle Colabを参照してほしい。
ウィキペディアからデータを読み込む
ベクターストアを構築するには、まずデータを読み込む必要がある。ここでは、LlamaIndexのデータローダーを使ってWikipediaから直接データを読み込みます。
from llama_index import WikipediaReader
都市 = [
"ロサンゼルス"、"ヒューストン"、"ホノルル"、"ツーソン"、"メキシコシティ"
"シンシナティ", "シカゴ"
]
wiki_docs = [].
for city in cities:
try:
doc = WikipediaReader().load_data(pages=[city])
wiki_docs.extend(doc)
except Exception as e:
print(f "Error loading page for city {city}: {e}")
エバリュエータのセットアップ
次に評価子を設定する。具体的には、前述した「文脈の関連性」、「根拠性」、「答えの関連性」の3要素を用いて、幻覚をテストする。
TruLens は、OpenAI、Anthropic、HuggingFace など、特定のモデル・プロバイダを使用する、この評価に有用なプロンプトを持つ評価者またはフィードバック関数のセットを提供します。
# OpenAI ベースのフィードバック関数コレクションクラスを初期化する:
openai_gpt4 = feedback.OpenAI()
モデルプロバイダを設定したら、最初の評価に使う質問文の関連性を選択します。この例の各評価では、評価をよりよく理解するために、思考の連鎖の理由も使用します。これはフィードバック関数の接尾辞 1_with_cot_reason で示されます。
この場合、フィードバック関数に渡すテキストを選択する必要があります。TruLens はアプリケーションをシリアライズし、JSON のような構造体でインデックスを作成する。テキストの選択には、このインデックスを使用します。TruLens には、これを簡単に行うためのヘルパー関数が多数用意されています:
- on_input()`は、LlamaIndex アプリケーションに渡されたメイン入力を自動的に検出し、フィードバック関数に渡される最初のテキストとして使用します。
- TruLlama.select_source_nodes()` は、LlamaIndex の検索で使用されるソースノードを識別します。
最後に、各コンテキストの関連性を1つのスコアに集約する必要があります。この例では、最も関連性の高いチャンクの関連性を測定するために、集約に最大値を使用します。平均値や最小値のような他の指標を使うこともできます。
# 質問と各コンテキストチャンク間の質問/発言の関連性。
f_context_relevance = Feedback(openai.qs_relevance_with_cot_reason, name = "コンテキスト関連性").on_input().on(
TruLlama.select_source_nodes().node.text
).aggregate(np.max)
Groundedness も同様に設定されるが、集計方法が少し異なる。この場合、各ステートメントの最大groundednessスコアを取り、次にすべてのステートメントの平均groundednessスコアを取ります。
grounded = Groundedness(groundedness_provider=openai_gpt4)
f_groundedness = Feedback(grounded.groundedness_measure_with_cot_reason, name = "Groundedness").on(
TruLlama.select_source_nodes().node.text # コンテキスト
).on_output().aggregate(grounded.grounded_statements_aggregator)
回答関連性は、入出力に依存するだけなので、設定するフィードバック関数としては最も簡単です。これには、新しい TruLens ヘルパー関数 .on_input_output() を使用します。
# 質問と回答の関連性。
f_qa_relevance = Feedback(openai.relevance_with_cot_reason、
name = "回答の関連性").on_input_output()
設定空間の定義
データをロードし、評価器をセットアップしたので、いよいよRAGを構築する。このプロセスでは、異なるコンフィギュレーションで一連のRAGを構築し、それぞれを評価し、最適なものを選択する。
先に述べたように、RAGの構成空間は、インパクトのあるいくつかの選択肢に限定する。この例では、インデックスタイプ、埋め込みモデル、トップk、チャンクサイズをテストする。
選択を繰り返す
設定空間を定義した後、itertoolsを使用してこれらの選択肢の全ての組み合わせを試し、それぞれを評価します。さらに、Milvusはoverwriteパラメータという素晴らしい利点を与えてくれます。これにより、他のベクターデータベースで必要とされるティアダウンやインスタンス化処理に時間を取られることなく、簡単に様々な設定を反復することができます。
各反復では、インデックスパラメータの選択をMilvusVectorStoreとストレージコンテキストを使用してアプリケーションに渡します。埋め込みモデルをサービスコンテキストに渡し、インデックスを作成します。
vector_store = MilvusVectorStore(index_params={
「index_type": index_param、
"metric_type":"L2"
},
search_params={"nprobe": 20}、
上書き=True)
llm = OpenAI(model="gpt-3.5-turbo")
storage_context = StorageContext.from_defaults(vector_store = vector_store)
service_context = ServiceContext.from_defaults(embed_model = embed_model, llm = llm, chunk_size = chunk_size)
index = VectorStoreIndex.from_documents(wiki_docs、
service_context=service_context、
storage_context=storage_context)
次に、このインデックスを使ってクエリーエンジンを構築する:
query_engine = index.as_query_engine(similarity_top_k = top_k)
構築後、TruLens を使用してアプリケーションをラップする。ここでは、識別しやすい名前を付け、アプリのメタデータとして設定を記録し、評価のためのフィードバック関数を定義する。
tru_query_engine = TruLlama(query_engine、
app_id=f"App-{index_param}-{embed_model_name}-{top_k}",
feedbacks=[f_groundedness, f_qa_relevance, f_context_relevance]、
メタデータ={
'index_param':index_param、
'embed_model':embed_model_name、
'top_k':top_k
})
この tru_query_engine は元のクエリーエンジンと同じように動作します。
最後に、評価のために小さなテストプロンプトのセットを使用し、それぞれのプロンプトに対する応答を提供するためにアプリケーションを呼び出します。OpenAI APIを連続して呼び出すので、Tenacityは指数関数的バックオフによってレート制限の問題を回避するのに役立ちます。
リトライ(stop=stop_after_attempt(10), wait=wait_exponential(multiplier=1, min=4, max=10))
def call_tru_query_engine(prompt):
return tru_query_engine.query(prompt)
for prompt in test_prompts:
call_tru_query_engine(prompt)
結果
**どのコンフィギュレーションが最も優れているか?
| インデックスの種類|埋め込みモデル|類似度トップk|チャンクサイズ | ---------- | ---------------------- | ---------------- | ---------- | | IVFフラット|text-embedding-ada-002|3|200||。

**どのコンフィギュレーションが一番成績が悪かったですか?
| インデックスの種類|埋め込みモデル|類似度トップk|チャンクサイズ | ---------- | -------------------------- | ---------------- | ---------- | | IVFフラット|多言語MiniLM L12 v2|1|500|の場合

**どのような故障モードが特定されたのか?
私たちが観察した失敗モードの1つは、間違った都市に関する情報を検索してしまうことでした。ヒューストンの代わりにツーソンに関するコンテキストが検索された。

同様に、正しい都市に関するコンテキストを検索したが、そのコンテキストは入力された質問とは無関係であったという問題も見られました。

このような無関係な文脈を与えられた補完モデルは、幻覚を見るようになった。ここで注意しなければならないのは、幻覚が必ずしも事実と違っているわけではないということだ。

さらに、無関係な回答の例も見つけた。

パフォーマンスを理解する
インデックスタイプ別
インデックスの種類は、速度、トークンの使用量、評価という点で、パフォーマンスに意味のある影響を与えなかった。これはおそらくこの例で取り込まれたデータのサイズが小さかったためであり、インデックスのタイプはより大きなコーパスに対してより重要な選択となりうる。
モデルを埋め込むことによって
Text-embedding-ada-002は、MiniLM埋め込みモデルよりもgroundedness(平均0.60に対して0.72)とanswer relevance(平均0.62に対して0.82)において優れていた。文脈関連性に関しては、2つの埋め込みモデルは同等の性能を示した。
これらの評価スコアの向上は、OpenAIの埋め込みがウィキペディアの情報により適しているためと考えられます。
類似度トップ K
トップKを増やすと、最大検索品質(コンテキストの関連性で測定)がわずかに向上した。より多くのチャンクを検索することで、レトリーバーはより多くの試行回数で高品質のコンテキストを検索することができる。
トップkを高くすると、groundedness(平均0.62に対して0.71)とanswer relevance(平均0.68に対して0.76)も向上した。より多くのコンテキストチャンクを検索することで、完了モデルが主張を行い、サポートするためのより多くの証拠を提供する。
予想通り、これらの改善は、トークンの使用量を大幅に増加させるという代償を伴います(1コールあたり平均590の追加トークン)。
チャンクサイズ
チャンクサイズを大きくすると、入力された質問とは無関係なテキストが周囲に含まれ ることになり、リトリーバの接地性が低下します。
一方、チャンクサイズを大きくすると、より多くの証拠と照合することができる。そのため、LLMが主張する場合、検索された文脈によってサポートされる可能性が高くなります。
最後に、チャンクサイズを大きくすると、1レコードあたりの平均トークン使用量が400トークン増加しました。
TruLensとMilvusでより良いRAGを作る
この投稿では、インデックスタイプ、埋め込みモデル、トップ k、チャンクサイズを含む様々な構成とパラメータを持つ RAG を構築する方法を学んだ。Milvus の大量のサポートされる設定と上書きサポートにより、このダイナミックな実験が可能になった。また、TruLens を使用して、各実験の追跡と評価を行い、新しい失敗モードを特定して説明し、最もパフォーマンスの高い組み合わせを迅速に見つけることができました。
自分で試すにはオープンソースのTruLensをチェックアウトし、オープンソースのMilvusまたはZilliz Cloudをインストールしてください。
 Josh Reini
Josh ReiniJosh is a core contributor to open-source TruLens and the founding Developer Relations Data Scientist at TruEra where he is responsible for education initiatives and nurturing a thriving community of practitioners excited about AI quality. Josh has delivered tech talks and workshops to more than a thousand developers at events including the Global AI Conference 2023, NYC Dev Day 2023, LLMs and the Generative AI Revolution 2023, AI developer meetups and the AI Quality Workshop (both in live format and on-demand through Udemy). Prior to TruEra, Josh delivered end-to-end data and machine learning and solutions to clients including the Department of State and the Walter Reed National Military Medical Center.
読み続けて

Migrating from S3 Vectors to Zilliz Cloud: Unlocking the Power of Tiered Storage
Learn how Zilliz Cloud bridges cost and performance with tiered storage and enterprise-grade features, and how to migrate data from AWS S3 Vectors to Zilliz Cloud.

What is the K-Nearest Neighbors (KNN) Algorithm in Machine Learning?
KNN is a supervised machine learning technique and algorithm for classification and regression. This post is the ultimate guide to KNN.

Vector Databases vs. NoSQL Databases
Use a vector database for AI-powered similarity search; use NoSQL databases for flexibility, scalability, and diverse non-relational data storage needs.