




NVIDIA MerlinとMilvusを使用したレコメンダーワークフローにおける効率的なベクトル類似度検索
この投稿は、NVIDIA MerlinのMediumチャンネルで最初に公開されたものを、許可を得て編集し、ここに再投稿したものです。NVIDIAのBurcin BozkayaとWilliam Hicks、ZillizのFilip HaltmayerとLi Liuが共同で執筆したものである。
序論
最新のレコメンダーシステム(Recsys)は、検索、フィルタリング、ランキング、関連アイテムのスコアリングのための、データ取り込み、データ前処理、モデルトレーニング、ハイパーパラメータチューニングの複数の段階を含むトレーニング/推論パイプラインで構成されている。レコメンダーシステムパイプラインの重要な構成要素は、特に大規模なアイテムカタログが存在する場合、ユーザーに最も関連するものの検索や発見である。このステップでは、一般的に、ユーザーと商品/サービス間の相互作用について学習するディープラーニングモデルから作成された、商品とユーザー属性の低次元ベクトル表現(すなわち、埋め込み)のインデックス付きデータベースに対する近似最近傍(ANN)検索が行われる。
NVIDIA Merlinは、あらゆる規模で推薦を行うエンドツーエンドのモデルをトレーニングするために開発されたオープンソースのフレームワークで、効率的なベクトルデータベースのインデックスと検索フレームワークと統合されている。そのようなフレームワークの中で最近注目を集めているのが、Zillizによって作成されたオープンソースのベクトルデータベースであるMilvusである。Milvusは高速なインデックスとクエリ機能を提供する。Milvusは最近、AIワークフローを維持するためにNVIDIA GPUを使用するGPUアクセラレーションサポートを追加した。GPUアクセラレーションのサポートは素晴らしいニュースです。なぜなら、アクセラレーションされたベクトル検索ライブラリは、高速な同時クエリーを可能にし、開発者が多くの同時リクエストを期待している今日のレコメンダーシステムにおけるレイテンシー要件にプラスの影響を与えるからです。Milvusは、5M以上のdockerプル、GitHub上の〜23kスター(2023年9月現在)、5,000以上のエンタープライズ顧客、および多くのアプリケーションのコアコンポーネントを持っています(使用ケースを参照)。
このブログでは、MilvusがMerlin Recsysフレームワークとどのように連携し、トレーニングや推論を行うかを紹介する。Milvusがアイテム検索段階において、非常に効率的なtop-kベクトル埋め込み検索でMerlinをどのように補完し、推論段階においてNVIDIA Triton推論サーバ(TIS)とどのように使用できるかを示します(図1参照)。私たちのベンチマーク結果は、Merlin Modelsによって生成されたベクトル埋め込みとNVIDIA RAFTを使用するGPUアクセラレーションMilvusによって、37倍から91倍という驚くべきスピードアップを示しています。私たちがMerlinとMilvusの統合を示すために使用したコードと詳細なベンチマーク結果は、私たちのベンチマーク研究を促進したlibraryとともに、こちらから入手できます。
ライブラリ](https://assets.zilliz.com/Multistage_recommender_system_with_Milvus_ee891c4ad5.png)
図1.Milvusフレームワークが検索ステージに貢献するマルチステージ推薦システム。元の多段階図の出典:このブログ記事.。
レコメンダーが直面する課題
レコメンダーの多段階の性質と、それらが統合された様々なコンポーネントやライブラリの利用可能性を考えると、重要な挑戦はエンドツーエンドのパイプラインで全てのコンポーネントをシームレスに統合することである。我々のノートブックの例では、統合がより少ない労力で行えることを示すことを目的としている。
レコメンダーワークフローのもう一つの課題は、特定のパイプライン部分を高速化することである。GPUは大規模なニューラルネットワークのトレーニングに大きな役割を果たすことは知られているが、ベクターデータベースやANN検索に追加されたのはごく最近のことだ。電子商取引の商品在庫やストリーミング・メディア・データベースのサイズが大きくなり、これらのサービスを利用するユーザー数が増加するにつれて、CPUはRecsysワークフローで何百万人ものユーザーに対応するために必要なパフォーマンスを提供しなければなりません。この課題に対処するために、他のパイプライン部分でGPUアクセラレーションが必要になりました。このブログのソリューションでは、GPUを使用した場合にANN検索が効率的であることを示すことで、この課題に対処しています。
ソリューションの技術スタック
まず、この作業を行うために必要な基本的なことを復習することから始めましょう。
NVIDIA Merlin: NVIDIA GPU上のレコメンダーを高速化する高レベルAPIを持つオープンソースライブラリ。
NVTabular](https://github.com/NVIDIA-Merlin/NVTabular):入力された表データを前処理し、特徴エンジニアリングを行う。
Merlin Models](https://github.com/NVIDIA-Merlin/models): ディープラーニングモデルの学習用で、今回はユーザーとの対話データからユーザーとアイテムの埋め込みベクトルを学習する。
Merlin Systems](https://github.com/NVIDIA-Merlin/systems): TensorFlowベースのレコメンデーションモデルと他の要素(例えば、フィーチャーストア、MilvusによるANN検索)を組み合わせ、TISで提供する。
Triton Inference Server](https://github.com/triton-inference-server/server): ユーザの特徴ベクトルが渡され、商品の推薦が生成される推論段階。
コンテナ化:上記はすべて、NVIDIAがNGCカタログで提供しているコンテナを介して利用可能です。我々は、Merlin TensorFlow 23.06コンテナを使用した。
Milvus 2.3](https://github.com/milvus-io/milvus/releases/tag/v2.3.0):GPUアクセラレーションによるベクトルインデックス作成とクエリ。
Milvus 2.2.11](https://github.com/milvus-io/milvus/releases):上記と同じですが、CPU上で実行します。
Pymilvus SDK](https://zilliz.com/product/integrations/python): PythonインターフェースでMilvusサーバに接続し、ベクトルデータベースインデックスを作成し、クエリを実行する。
Feast:エンドツーエンドのRecSysパイプラインの一部として、ユーザーとアイテムの属性を(オープンソースの)フィーチャストアに保存し、取得します。
また、いくつかの基盤となるライブラリやフレームワークも使用されています。例えば、Merlinは、RAPIDS cuDFで利用可能なcuDFやDaskなどのNVIDIAライブラリに依存しています。同様に、Milvusは、GPUアクセラレーションのプリミティブのためにNVIDIA RAFTに依存し、検索のためにHNSWやFAISSのような修正されたライブラリに依存している。
ベクトルデータベースとMilvusの理解
近似最近傍(ANN)はリレーショナルデータベースでは扱えない機能です。リレーショナルデータベースは、あらかじめ定義された構造と直接比較可能な値を持つ表データを扱うように設計されています。リレーショナルデータベースのインデックスは、データを比較し、各値が他の値より小さいか大きいかを知ることを利用した構造を作成するために、これに依存しています。埋め込みベクトルは、ベクトル内の各値が何を表しているかを知る必要があるため、この方法で直接比較することはできません。一方のベクトルが他方のベクトルより必ずしも小さいかどうかは言えないのだ。唯一できることは、2つのベクトル間の距離を計算することだ。2つのベクトル間の距離が小さければ、それらが表す特徴は似ていると推測でき、大きければ、それらが表すデータはより異なっていると推測できる。しかし、このような効率的なインデックスにはコストがかかります。2つのベクトル間の距離を計算するには計算コストがかかり、ベクトルインデックスは容易に適応できず、時には変更できないこともあります。この2つの制限のために、リレーショナルデータベースではこれらのインデックスの統合はより複雑であり、目的別ベクトルデータベースが必要とされる理由である。
Milvusは、リレーショナル・データベースがベクトルでぶつかる問題を解決するために作られ、これらの埋め込みベクトルとそのインデックスを大規模に扱うために一から設計された。クラウドネイティブのバッジを満たすために、Milvusはコンピューティングとストレージ、そしてクエリ、データ管理、インデックス作成といった異なるコンピューティングタスクを分離している。ユーザーは、データ挿入が多い場合でも、検索が多い場合でも、他のユースケースに対応できるように各データベース部分を拡張することができる。挿入リクエストが大量に発生した場合、ユーザーはインデックスノードを一時的に水平方向と垂直方向に拡張して、取り込みを処理することができる。同様に、データのインジェストはないが検索が多い場合、ユーザーはインデックスノードを減らし、代わりにクエリノードをスケールアップしてスループットを向上させることができます。このシステム設計(図2参照)では、並列コンピューティングの考え方で考える必要があり、その結果、さらなる最適化のために多くのドアが開かれた、コンピューティングに最適化されたシステムが生まれました。
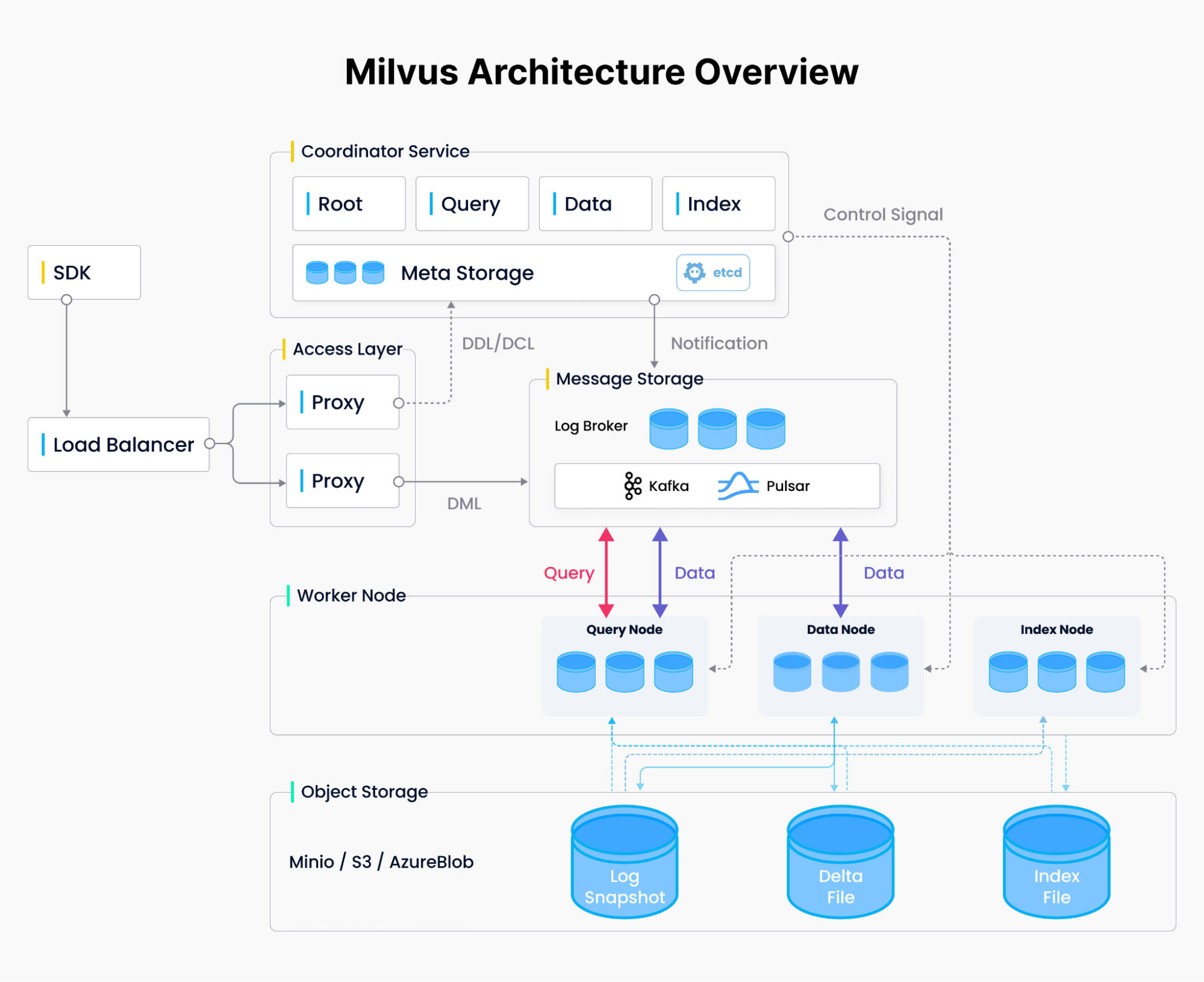
*図2.Milvusのシステムデザイン
Milvusはまた、ユーザがシステムをできるだけカスタマイズできるように、多くの最先端のインデックスライブラリを使用している。CRUD操作、ストリームデータ、フィルタリングを扱う機能を追加することで、それらを改良している。後ほど、これらのインデックスがどのように異なるのか、それぞれの長所と短所について説明する。
解決策の例:MilvusとMerlinの統合
ここで紹介するソリューション例では、アイテム検索段階(ANN検索により最も関連性の高いk個のアイテムが検索される段階)におけるMilvusとMerlinの統合を示す。以下に説明するRecSys challengeからの実際のデータセットを使用する。我々は、ユーザーとアイテムのベクトル埋め込みを学習する2タワー深層学習モデルを訓練する。このセクションはまた、収集するメトリクスや使用するパラメータの範囲など、我々のベンチマーク作業の青写真を提供する。
我々のアプローチには以下が含まれる:
データの取り込みと前処理
2タワー深層学習モデルのトレーニング
Milvusインデックス構築
ミルバス類似度検索
各ステップについて簡単に説明し、詳細については我々のnotebooksを参照されたい。
データセット
YOOCHOOSE GmbHは、RecSys 2015 challengeのために、この統合とベンチマーク研究で使用するデータセットを提供し、Kaggleで入手可能である。これは、セッションID、タイムスタンプ、クリック/購入に関連するアイテムID、アイテムカテゴリなどの属性を持つ、ヨーロッパのオンライン小売業者からのユーザのクリック/購入イベントを含み、yoochoose-clicks.datファイルで利用可能です。セッションは独立しており、リピーターユーザーを示唆するものはないので、各セッションを別個のユーザーのものとして扱う。データセットには9,249,729のユニークなセッション(ユーザー)と52,739のユニークなアイテムがある。
データの取り込みと前処理
データの前処理に使用するツールはNVTabularで、MerlinのGPUアクセラレートされた、非常にスケーラブルな特徴エンジニアリングと前処理コンポーネントである。NVTabularを使用して、データをGPUメモリに読み込み、必要に応じて特徴を並べ替え、パーケットファイルにエクスポートし、トレーニング用にトレーニングと検証の分割を作成します。この結果、7,305,761のユニークユーザーと49,008のユニークアイテムが訓練対象となりました。また、各列とその値を整数値に分類する。これでデータセットは2タワーモデルで学習する準備が整いました。
モデルのトレーニング
Two-Tower](https://github.com/NVIDIA-Merlin/models/blob/main/examples/05-Retrieval-Model.ipynb)ディープラーニングモデルを使って、ユーザとアイテムの埋め込みを学習・生成します。モデルを訓練した後、学習したユーザとアイテムの埋め込みを抽出することができる。
DLRM](https://arxiv.org/abs/1906.00091)モデルは、推薦のために検索されたアイテムをランク付けするために学習され、特徴ストアは、ユーザとアイテムの特徴を格納し、取得するために使用されます(この場合、Feast)。マルチステージワークフローの完全性のために、これらを含める。
最後に、ユーザとアイテムのエンベッディングをparquetファイルにエクスポートし、後でMilvusベクトルインデックスを作成するために再ロードできるようにする。
Milvusインデックスの構築とクエリ
Milvusは推論マシン上で起動される "サーバ "を介して、ベクトルインデックスの作成と類似度検索を容易にします。ノートブック#2では、MilvusサーバーとPymilvusをpipインストールし、デフォルトのリスニングポートでサーバーを起動します。次に、関数 setup_milvus と query_milvus を用いて、簡単なインデックス(IVF_FLAT)の構築とそれに対するクエリの実演を行う。
ベンチマーク
Milvusのような高速で効率的なベクトルインデックス/検索ライブラリを使用するケースを実証するために、2つのベンチマークを設計した。
1.Milvusを使って、我々が生成した2つの埋め込みデータを使ってベクトルインデックスを構築する:1)7.3Mユニークユーザのユーザ埋め込み(85%訓練セット(インデックス作成用)と15%テストセット(クエリ用)に分割)、2)49K商品のアイテム埋め込み(訓練とテストは半々に分割)。このベンチマークは各ベクトルデータセットに対して独立して行われ、結果は別々に報告される。
2.Milvusを使用し、49Kのアイテム埋め込みデータセットのベクトルインデックスを構築し、このインデックスに対して7.3Mのユニークユーザーの類似性検索をクエリする。
これらのベンチマークでは、GPUとCPU上で実行されるIVFPQとHNSWインデックス作成アルゴリズムを、様々なパラメータの組み合わせと共に使用した。詳細は我々のGitHubページに掲載されている。
検索品質とスループットのトレードオフは、特に実運用環境では重要な性能検討事項である。Milvusでは、インデックス作成パラメータを完全に制御することで、与えられたユースケースに対してこのトレードオフを検討し、グランドトゥルースでより良い検索結果を得ることができます。これは、スループット率や1秒あたりのクエリー数(QPS)の減少という形で、計算コストの増加を意味するかもしれない。我々はANN検索の品質をリコール指標で測定し、トレードオフを示すQPS-リコール曲線を提供する。そして、ビジネスケースの計算リソースやレイテンシ/スループット要件から、許容可能な検索品質レベルを決定することができる。
また、我々のベンチマークで使用されているクエリーバッチサイズ(nq)にも注目してほしい。これは、複数の同時リクエストが推論に送信されるワークフロー(例えば、電子メールの受信者リストにリクエストされ送信されるオフライン推薦や、到着した同時リクエストをプールして一度に処理することで作成されるオンライン推薦)で有用である。ユースケースによっては、TISはこれらのリクエストをバッチ処理することもできる。
結果
Milvusによって実装されたHNSW(CPUのみ)とIVF_PQ(CPUとGPU)インデックスタイプを使用して、CPUとGPUの両方で3セットのベンチマークの結果を報告します。
アイテム対アイテムベクトル類似検索
この最小のデータセットでは、与えられたパラメータの組み合わせに対する各実行は、アイテムベクトルの50%をクエリベクトルとして取り、残りのものから上位100の類似ベクトルをクエリする。HNSWとIVF_PQは、それぞれ0.958-1.0と0.665-0.997の範囲で、テストしたパラメータ設定で高いリコールが得られた。この結果は、HNSWがリコールにおいてより優れた性能を発揮することを示唆しているが、小さなnlist設定のIVF_PQは非常に同等のリコールを生成する。また、想起値はインデックス作成とクエリーパラメータによって大きく変化することに注意すべきである。我々が報告する値は、一般的なパラメータ範囲での予備実験と、選択されたサブセットへの更なるズーミングの後に得られたものである。
与えられたパラメーターの組み合わせに対して、HNSWを使用した場合、CPUで全てのクエリーを実行する合計時間は5.22秒から5.33秒の間(mが大きくなるにつれて速くなり、efでは比較的変わらない)、IVF_PQを使用した場合は13.67秒から14.67秒の間(nlistとnprobeが大きくなるにつれて遅くなる)である。図3に見られるように、GPUアクセラレーションには顕著な効果があります。
図3は、IVF_PQを使用し、この小さなデータセットをCPUとGPUで実行した場合のリコール・スループットのトレードオフを示しています。GPUでは、テストしたすべてのパラメータの組み合わせにおいて、4倍から15倍のスピードアップが得られることがわかります(nprobeが大きくなるほど、スピードアップは大きくなります)。これは、各パラメータの組み合わせについて、GPUによるQPSとCPUによる実行のQPSの比を取ることによって計算されます。全体として、このセットはCPUやGPUにとってほとんど課題がなく、後述するように、より大きなデータセットでさらなる高速化が期待できます。
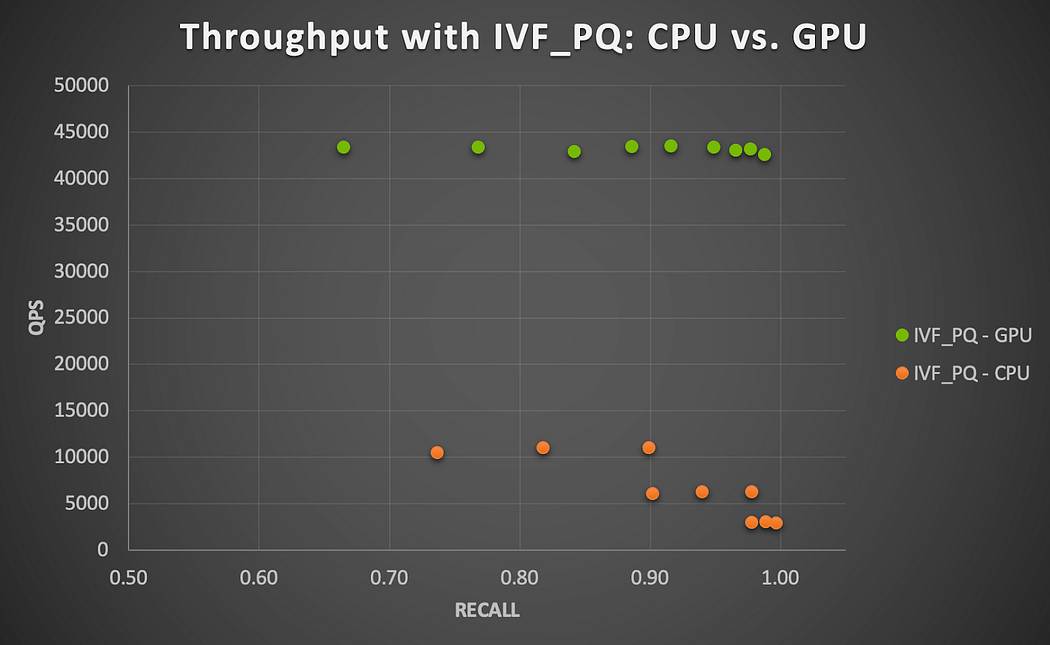
図3.NVIDIA A100 GPU上で動作するMilvus IVF_PQアルゴリズムによるGPU高速化(item-item類似探索)。
ユーザ対ユーザのベクトル類似検索
より大きな2つ目のデータセット(7.3Mユーザ)を用いて、85%(~6.2M)のベクトルを "train"(インデックス化されるベクトルセット)として確保し、残りの15%(~1.1M)を "test "またはクエリベクトルセットとして確保した。この場合、HNSWとIVF_PQは、それぞれ0.884-1.0と0.922-0.999のリコール値で、非常に優れた性能を発揮する。しかし、これらは計算負荷が高く、特にIVF_PQはCPUでの計算負荷が高い。CPU上でHNSWを使用した場合の全クエリの実行時間は279.89~295.56秒、IVF_PQを使用した場合の実行時間は3082.67~10932.33秒である。
しかし、推論サーバーが数百万アイテムのインベントリに対してクエリを実行するために何千もの同時リクエストを想定している場合、CPUベースのクエリは実行不可能かもしれない。
図4に示すように、A100 GPUは、IVF_PQのすべてのパラメータの組み合わせにおいて、スループット(QPS)において37倍から91倍(平均76.1倍)という驚異的なスピードアップを実現しました。これは小規模なデータセットで観測された結果と一致しており、数百万の埋め込みベクトルを持つMilvusを使用してGPUの性能が合理的にスケールすることを示唆しています。
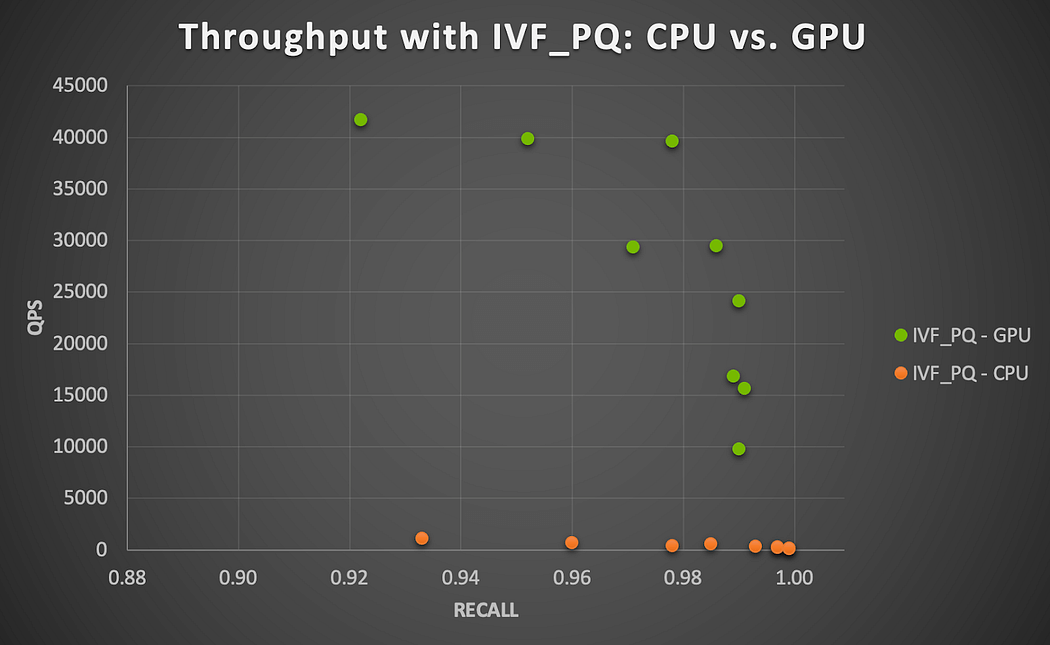
図4.NVIDIA A100 GPU上で動作するMilvus IVF_PQアルゴリズムによるGPU高速化(ユーザー-ユーザー類似性検索)。
以下の詳細な図5は、IVF_PQを用いてCPUとGPUでテストしたすべてのパラメータの組み合わせについて、再現率とQPSのトレードオフを示しています。このグラフの各ポイントセット(上はGPU、下はCPU)は、ベクトルインデックス/クエリパラメータを変更した際に、スループットを犠牲にして高いリコールを達成するために直面したトレードオフを表しています。GPUの場合、より高いリコールレベルを達成しようとすると、QPSがかなり低下することに注意してください。
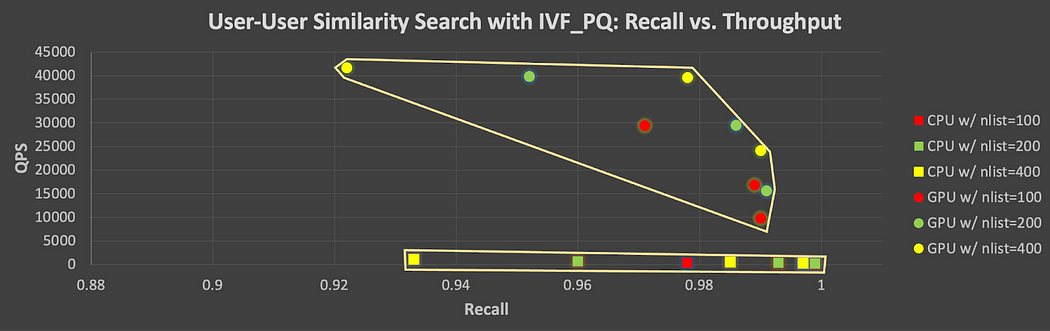
図5.IVF_PQを用いてCPUとGPUでテストされたすべてのパラメータの組み合わせにおけるリコールとスループットのトレードオフ(ユーザー対ユーザー)。
ユーザー対アイテム ベクトル類似探索
最後に、ユーザー・ベクトルがアイテム・ベクトルに対してクエリされるという、もう1つの現実的なユースケースを考えます(上記のノートブック01で示したとおりです)。この場合、4.9 万のアイテム・ベクトルがインデックス化され、7.3 万のユーザ・ベクトルがそれぞれ上位 100 の最も類似したアイテムに対してクエリされます。
HNSWでもIVF_PQでも、CPUでは49Kアイテムのインデックスに対して7.3Mを1000バッチでクエリするのは時間がかかるようです。GPUの方がこのケースをうまく処理できるようです(図6参照)。CPU上でnlist = 100のときのIVF_PQによる最高精度レベルは、平均で約86分で計算されるが、nprobe値が大きくなるにつれて大きく変化する(nprobe = 5のときは51分、nprobe = 20のときは128分)。NVIDIA A100 GPUは、性能を4倍から17倍と大幅に高速化します(nprobeが大きくなるほど高速化)。IVF_PQアルゴリズムは、その量子化技術により、メモリフットプリントを削減し、GPUアクセラレーションと組み合わせた計算実行可能なANN探索ソリューションを提供することも覚えておいてください。
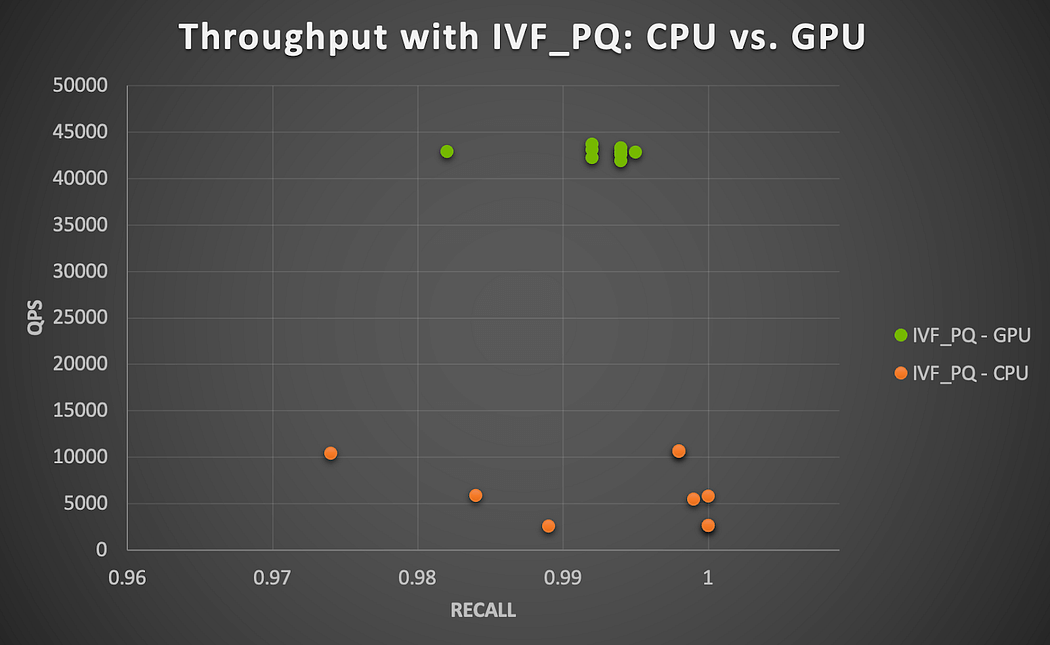
図6.NVIDIA A100 GPU上で動作するMilvus IVF_PQアルゴリズムによるGPU高速化(ユーザー項目の類似性検索)。
図5と同様に、IVF_PQでテストしたすべてのパラメータの組み合わせについて、リコール-スループットのトレードオフを図7に示します。ここでも、スループットを向上させるために、ANN 検索の精度を若干あきらめる必要があることがわかりますが、特に GPU で実行した場合、その差はかなり小さくなっています。このことは、GPUを使用することで、高い想起を達成しながら、比較的一貫して高いレベルの計算性能が期待できることを示唆しています。
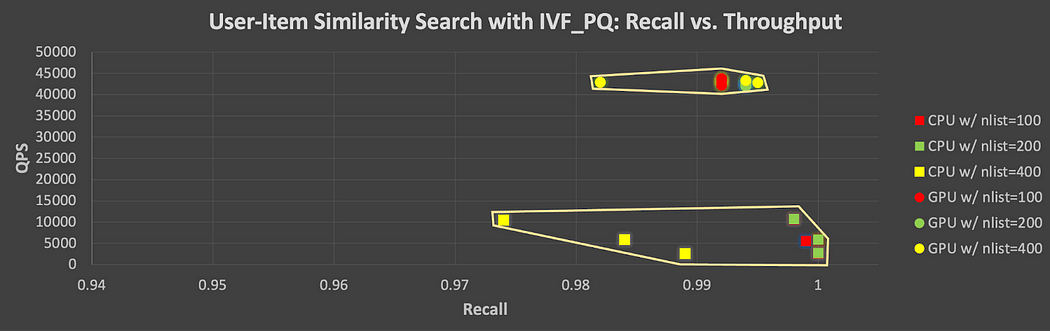
図7.IVF_PQを用いてCPUとGPUでテストした全パラメータの組み合わせのRecall-Throughputトレードオフ(ユーザー対アイテム)。
結論
ここまでお読みいただいた方には、最後にいくつかの結論をお伝えしたい。現代のRecsysの複雑さとマルチステージの性質は、すべてのステップでパフォーマンスと効率を必要とすることを思い出していただきたい。このブログが、RecSysパイプラインで2つの重要な機能の使用を検討する説得力のある理由になったことを願っています:
NVIDIA MerlinのMerlin Systemsライブラリを使用すると、効率的なGPUアクセラレーションベクトル検索エンジンであるMilvusを簡単にプラグインすることができます。
RAPIDS RAFT](https://github.com/rapidsai/raft)のような技術で、GPUを使用してベクトルデータベースインデキシングやANN検索の計算を加速します。

これらの結果から、今回紹介したMerlinとMilvusの統合は、学習と推論のための他のオプションに比べて非常に性能が高く、複雑さもはるかに少ないことが示唆される。また、両フレームワークは活発に開発されており、多くの新機能(例えば、Milvusによる新しいGPU加速ベクトルデータベースインデックス)がリリース毎に追加されている。ベクトル類似性検索は、コンピュータビジョン、大規模言語モデリング、レコメンダーシステムなどの様々なワークフローにおいて重要な要素であるという事実が、この取り組みをより価値のあるものにしている。
最後に、本作品とブログ記事の作成にご尽力いただいたZilliz/Milvus、Merlin、RAFTチームの皆様に感謝申し上げます。MerlinとMilvusをRecsysやその他のワークフローに導入する機会がありましたら、ぜひご連絡ください。

読み続けて

Notion's Vector Search Is Excellent. Their Next Problem Is Harder.
Notion solved vector search scaling in two years. The next bottleneck — offline context engineering, unified data, and the real-time/offline gap — is harder.

Will Amazon S3 Vectors Kill Vector Databases—or Save Them?
AWS S3 Vectors aims for 90% cost savings for vector storage. But will it kill vectordbs like Milvus? A deep dive into costs, limits, and the future of tiered storage.

Announcing VDBBench 1.0: Open-Source VectorDB Benchmarking with Your Real-World Production Workloads
Discover VDBBench 1.0, an open-source tool for benchmarking vector databases with real-world production data, streaming ingestion, and concurrent workloads.