




さまざまなベクトル埋め込みを比較する
この記事はThe New Stackに掲載されたもので、許可を得てここに再掲載している。
**異なるニューラルネットワークによって生成されたベクトル埋め込みはどのように異なり、Jupyter Notebookでどのように評価できるのか?
大規模言語モデル(LLM)がトレンドであり、我々はChatGPTのような言語アプリケーションの新しいパラダイムに直面している。ベクター・データベースはスタックの中核となるでしょう。そのため、ベクターについて理解し、なぜベクターが重要なのかを理解することが重要です。
このプロジェクトでは、モデル間のベクトル埋め込みの違いを示し、1つのJupyter Notebookで複数のベクトルデータのコレクションを使用する方法を示します。この投稿では、ベクトル埋め込みとは何か、なぜ重要なのか、そしてJupyter Notebookで異なるベクトル埋め込みを比較する方法について説明します。
ベクトル埋め込みとは何か、なぜ重要なのか?
ベクトル埋め込みはどこから来たのか](https://assets.zilliz.com/Where_do_vector_embeddings_come_from_18745c05a7.png)
簡単に言えば、ベクトル埋め込みはデータの数値表現です。主に非構造化データを表現するために使われます。非構造化データとは、画像、動画、音声、テキスト、分子画像など、正式な構造を持たないデータのことです。ベクトル埋め込みは、あらかじめ訓練されたニューラルネットワークに入力データを通し、最後から2番目の層の出力を取り出すことで生成される。
ニューラルネットワークは、異なるアーキテクチャを持ち、異なるデータセットで訓練されるため、各モデルのベクトル埋め込みはユニークになります。これが、非構造化データとベクトル埋め込みを扱うのが難しい理由だ。同じベースモデルを異なるデータセットでファインチューニングしたモデルが、どのように異なるベクトル埋め込みをもたらすかは、後ほど説明します。
ニューラルネットワークの違いは、多様な形の非構造化データを処理し、その埋め込みを生成するために、異なるモデルを使わなければならないことも意味します。例えば、画像の埋め込みを生成するのに文変換モデルを使うことはできません。逆に、画像モデルであるResNet50を使って、文の埋め込みを生成したいとは思わないでしょう。したがって、データ型に適したモデルを見つけることが重要です。
ベクトル埋め込みを比較するには?
次に、それらを比較する方法を見てみましょう。このセクションでは、Hugging FaceのMiniLMをベースにした3つの異なる多言語モデルを比較します。ベクトルを比較する方法はたくさんあります。この例では、L2距離メトリックを使用し、ベクトルインデックスとして反転ファイルインデックスを使用します。
このプロジェクトのために、私はテイラー・スウィフトの最近のアルバム・リリースに触発され、Jupyter Notebookで定義されたいくつかのデータを開発した。私の例を使ってもいいし、自分で文章を考えてもいい。データが手に入ったら、異なるエンベッディングを取得し、Milvusのようなベクトルデータベースにエンベッディングの2つのセットを保存する。3つ目のモデルの埋め込みデータを使って比較を行うために、2つの埋め込みデータを照会します。
私たちは、検索結果が異なるかどうか、そして検索結果が互いにどのくらいずれているかを見ています。本番環境では、見たい結果を知り、返された結果と照らし合わせます。
異なるモデルのベクトル埋め込みを比較する
比較するモデルは、Sentence TransformersのMiniLMを使ったベースとなる多言語言い換えモデルと、意図検出のためにファインチューニングされたバージョン、そして何のためにチューニングされたのかについてSprylabが詳細なしでファインチューニングしたバージョンの3つです。私のノートパソコンで実行できる互換性のある3つのモデルを見つけることは、このプロジェクトで最も難しい部分の1つでした。
ベクトル埋め込みを比較するためには、同じ長さ/次元のベクトルが必要です。この例では、MiniLM Sentence Transformerモデルのように384次元のベクトルを使用しています。これは各データに対して384の「特徴」や「カテゴリ」を作成するという意味ではなく、384次元空間におけるデータの抽象的な表現を生成するという意味であることに注意してください。例えば、どの次元も、品詞、文中の単語数、固有名詞かどうか、またはそのような概念的なものを表すことはありません。
ベクトル埋め込み比較データ
我々は文型変換モデルを使用しているので、データは文の形式でなければならない。比較する文は、少なくとも50文は用意することをお勧めします。例のノートブックには51個入っています。また、類似性のあるデータを使うことをお勧めします。この例では、テイラー・スウィフトの4曲の歌詞を使いました:"Speak Now"、"Starlight"、"Sparks Fly"、"Haunted"。
これらの曲を選んだのは、歌詞の多くが完全な文章になっているので、歌詞の形式から文章の形式に変えるのが簡単だからだ。また、ある仮説を検証したかった。最初の3曲は多かれ少なかれラブソングだが、最後の「Haunted」はどちらかというと別れの歌に近い。だから、「Haunted」が最初の3曲の検索結果に表示される可能性は、他の曲の検索結果に表示される可能性よりも低いという仮説を立てた。
Jupyter Notebookでベクトル埋め込みを比較する
コードを見てみよう。Milvusの軽量版であるMilvus Liteを使えば、Jupyter Notebook上でベクトル埋め込みを直接比較することができます。このサンプルコードでは、! pip install pymilvus milvus sentence-transformers が必要です。timeライブラリはオプションである。インポートを実行した後、Milvusのdefault_server` を起動し、接続を設定する。
from sentence_transformers import SentenceTransformer
from milvus import default_server
from pymilvus import connections, utility, FieldSchema, CollectionSchema, DataType, Collection
from time import time
default_server.start()
connections.connect(host="127.0.0.1", port=default_server.listen_port)
Hugging Faceから文変換モデルを取得する
ステップ1ではベクトル埋め込みモデルを取得します。この例では言い換え多言語MiniLMシリーズを使用します。最初のものは正規バージョンです。次の2つは微調整されたバージョンです。このモデルの選択により、微調整がいかにベクトルを顕著に変化させるかの明確な例が得られます。
v12 = SentenceTransformer("sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2")
ft3_v12 = SentenceTransformer("Sprylab/paraphrase-multilingual-MiniLM-L12-v2-fine-tuned-3")
ft5_v12 = SentenceTransformer("hroth/psais-paraphrase-multilingual-MiniLM-L12-v2-5shot")
データセットをベクトルデータベースの2つのコレクションにロードする。
テイラー・スウィフトのアルバム「スピーク・ナウ」から51の文章を以下にリストアップした。このコード・スニペットは自由にコピー&ペーストしてください。彼女は素晴らしい作詞家だ。
# スピーク・ナウ(テイラー・バージョン)にインスパイアされた。
# Lyrics from: スピーク・ナウ、スターライト、スパークス・フライ、ホーンテッド
文章 = [
"私は、白いベールの機会に不作法に押しかけるような女の子ではない、
「忍び込んでみると、あなたの友人と彼女の鼻水垂らしそうな小さな家族はみんなパステルカラーの服を着ていて、彼女はお菓子の形をしたガウンを着て、部屋の奥のほうで花嫁介添人を怒鳴りつけている」、
"これはきっと、あなたが思っていたようなものではない"、
"イエスと言わないで、今すぐ逃げなさい、教会から出たら裏口で会いましょう "と立ち尽くす白昼夢に我を忘れる、
"待たないで、誓いの言葉をひとつも言わないで......私の話を最後まで聞く必要があるのに、彼らは『今すぐ話せ』と言った、
"親しげなジェスチャーが交わされる"、
"そしてオルガンが死の行進のような曲を奏で始める"、
"そして私はカーテンの中に隠れている。""どうやら私は、あなたの素敵な花嫁になる人に招かれなかったようだ。
"彼女はページェントの女王のようにバージンロードを浮遊している"、
"でも、私であってほしいと願っているのは知っている......私であってほしいと願っているんでしょう?"
"私は伝道師の言葉を聞く、"今話すか、永遠にあなたの平和を保持する"、
"沈黙がある、最後のチャンスだ"、
「私は震える手で立ち上がる、
"その場にいる全員がぞっとするような視線を送るが、私はあなただけを見ている"、
"そして君は言うだろう、『今すぐ逃げよう』と" "タキシードを脱いだら裏口で会おう"、
Baby, I didn't say my vows So glad you were around When they said, "Speak now""、
"私は言った、"ああ、なんと素晴らしい曲"、
"最高の夜だった、私たちの感動が忘れられない"、
「会場全体がきらびやかなドレスに身を包み、私たちは星の光でできたようなダンスを踊っていた」、
「45年の夏、ボードウォークでボビーに出会った、
"ある夜遅く、窓の外から私を拾ってくれた......私たちは17歳で、クレイジーで、ワイルドに駆け回っていた"、
"店に入った時、彼がどんな曲を流していたか思い出せない"
"公爵夫人と王子のふりをして ヨットクラブのパーティーに忍び込んだ夜"
"彼は言った。"変えようのないことをそんなに心配している君を見ろ、そんな風に考え続けていたら、ブルースを歌いながら一生を過ごすことになるぞ"、
"彼は海の上で石を飛ばそうとして私に言った。"星の光が見えないのか、星の光が見えないのか、不可能なことを夢見ないのか"、
"ああ、ああ、彼はおかしなことを言っている ああ、ああ、私と踊ろう ああ、ああ、私たちは結婚できる 10人の子供を持って、彼らに夢の見かたを教えよう"、
"君の動きはまるで雨あられだ"
"そして私はトランプの家"
"君は無鉄砲で逃げ出したくなるような人だけど、遠くへは行けないとなんとなくわかっている"
"そして、あなたは私の目の前に立っていた......触れられるくらいの距離で......"
"私が何を考えているのか見えないことを願うほど近くに"、
「今すぐすべてを捨てて」、
"土砂降りの雨の中で会おう"
「歩道でキスして」、
"痛みを取り除いて"
"君が微笑むと火花が散る"
"そのグリーンの瞳で私をつかまえて"、"ベイビー、明かりが落ちたら"、
"君がいない時、僕を悩ませる何かをくれ"
"私の心はあなたが悪い考えであることを思い出させるために忘れてしまう"、
"あなたは一度私に触れ、それはあなたが私があなたが想像していたよりもさらに良い見つける本当に何かである"、
"私は世界の他の人のために警戒しているが、あなたと一緒に、私はそれがダメだと知っている"
"そして、私は辛抱強く待つことができたが、私は本当にあなたがそうすることを望む"
"君の髪に指を通し、ライトが乱れるのを眺める"
"ただ僕から目を離さないで......それが正しいと感じるには十分な間違いなんだ"
"そして私を階段に導いて......柔らかくゆっくりと囁いて......私はあなたに魅了されている、花火のようなベイビー"、
"君と僕はもろい一線を歩いている、ずっとそれを知っていた、でもそれが壊れるのを見るために生きているとは思わなかった"
"暗くなってきて、すべてが静かすぎて、もう何も信じられない、
「Oh, I'm holding my breath Won't lose you again"、
"何かが君の目を冷たくした"
"さあ、さあ、こんな風に私を置いて行かないで" "私はあなたを理解したと思った
"何かがひどく間違ってしまった......君は僕が欲しかった全てだ"
"君がいなくなると息ができない" "もう引き返せない、取り憑かれている
"私はただ、あなたがいないことを知っている、
]
まず、ベクトルデータベースにデータを入れるためのスキーマを定義しなければなりません。この例では両方のコレクションに同じスキーマを使うので、スキーマは1つだけでよい。ただし、コレクションは必ず2つ作成してください。
コレクションの準備ができたら、すべての文を埋め込みモデルにエンコードし、ベクトルインデッ クスパラメータを定義します。距離メトリックとしてL2を使い、4つのセントロイドを持つ逆ファイルインデックスを使う。結局、エントリーは51しかない。そしてデータをフォーマットしてMilvusにロードする。
# オブジェクトは(タイトル、日付、場所、スピーチ埋め込み)のフォーマットで挿入されるべきである。
fields = [
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True, auto_id=True)、
FieldSchema(name="文", dtype=DataType.VARCHAR, max_length=500)、
FieldSchema(name="embedding",dtype=DataType.FLOAT_VECTOR,dim=DIMENSION)、
]
schema = CollectionSchema(fields=fields)
collection_v12 = Collection(name=COLLECTION_V12, schema=schema)
collection_v12_ft5 = Collection(name=COLLECTION_V12_Q, schema=schema)
v12_embeds = {}です。
v12_q_embeds={}である。
for sentence in sentences:
v12_embeds[sentence] = v12.encode(sentence)
v12_q_embeds[sentence] = ft5_v12.encode(sentence)
index_params = { 以下のようになります。
「index_type":"IVF_FLAT"、
"metric_type":"L2",
「params":params": {"nlist":4},
}
collection_v12.create_index(field_name="embedding", index_params=index_params)
コレクション_v12.load()
コレクション_v12_ft5.create_index(field_name="embedding", index_params=index_params)
コレクション_v12_ft5.load()
for sentence in sentences:
v12_insert = [
{
"sentence": sentence、
"embedding": v12_embeds[sentence].
}
]
ft_insert = [
{
"sentence": 文、
"embedding": v12_q_embeds[sentence].
}
]
コレクション_v12.insert(v12_insert)
コレクション_v12_ft5.insert(ft_insert)
コレクション_v12.flush()
コレクション_v12_ft5.flush()
埋め込みを比較するためにベクトルストアに問い合わせる
次はいよいよ比較です。この例では、最初の2つの文を使います。3つ目のモデルを使ってベクトル埋め込みを生成します。
search_embeds = {} 検索データ
search_data = [].
for sentence in sentences[0:2]:
vector_embedding = ft3_v12.encode(sentence)
search_embeds[sentence] = vector_embedding
search_data.append(vector_embedding)
今度はMilvusに問い合わせる。これについても時間を追跡している。私が取得した検索の時間を以下に示す。検索パラメーターの下に同じメトリクスタイプを渡すことを確認してください。

start1 = time()
res_v12 = collection_v12.search(
data=search_data, # 埋め込み検索値
anns_field="embedding", # 埋め込みを横断して検索する
param={"metric_type":"L2",
「params":{"nprobe": 2}}、
limit = 3, # 1回の検索で得られる結果をtop_k件に制限する
output_fields=["sentence"])
time1 = time() - start1
print(f "Time for first search: {time1}")
start2 = time()
res_v12_ft5 = collection_v12_ft5.search(
data=search_data, # 埋め込み検索値
anns_field="embedding", # 埋め込みを横断して検索する
param={"metric_type":"L2",
「params":{"nprobe": 2}}、
limit = 3, # 1回の検索で得られる結果をtop_k件に制限する
output_fields=["sentence"])
time2 = time() - start2
print(f "Time for second search: {time2}")
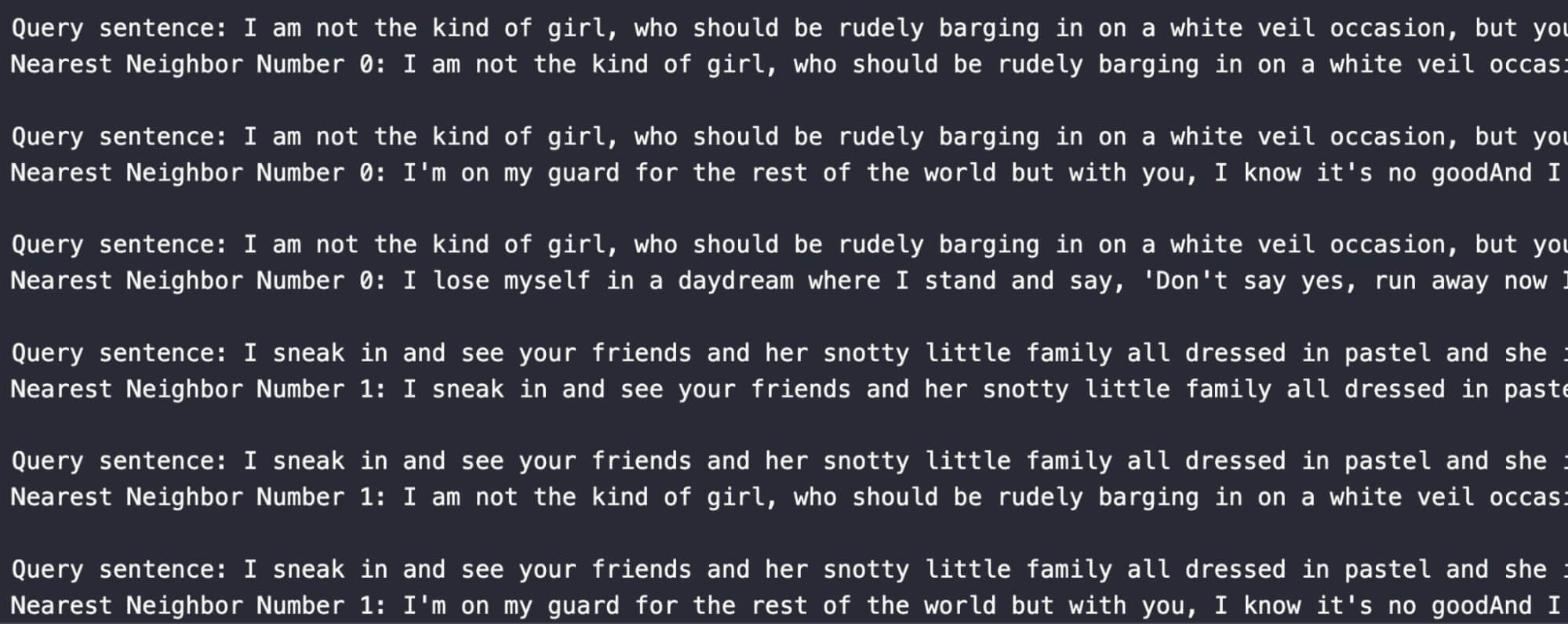
それでは結果を見て比較してみよう。オリジナルのモデルとSprylabによって微調整されたモデルの結果は驚くほど似ています。唯一の違いは、最初に返される結果が文そのものであることだ。このことは、2と3の結果は、この2つのベクトル空間において、2つの検索文の例よりも似ていることを物語っている。
for i, hits in enumerate(res_v12):
for hit in hits:
print(f "Query sentence: {sentences[i]}")
print(f "Nearest Neighbor Number {i}:{hit.entity.get('文')}。---- {hit.distance}n")

次に、微調整された2つのモデルを比較してみよう。この結果から、"I'm on my guard for the rest of the world ... "で始まる文は、両方の比較でポップアップするので、私たちの検索文と意味的に類似していることがわかるだろう。ここで興味深い点が2つある:1)最初のクエリとは異なる結果、2)2番目のクエリ文は最初のクエリのトップ3には表示されないが、逆は真である。
for i, hits in enumerate(res_v12_ft5): for hit in hits: print(f "Query sentence: {sentences[i]}") print(f "最近傍番号{i}:{hit.entity.get('文')}。---- {hit.distance}n")
## 要約
このチュートリアルでは、ベクトル埋め込みとその比較方法について学び、カスタムデータを使っていくつかの比較を行いました。ボーナスとして、2つの異なるコレクションを同時に扱う方法の例も示します。これは、異なる潜在ベクトル空間をクエリする方法です。
モデルとその微調整バージョンの違いを示しました。また、1つの結果が両方の埋め込み空間でどのように現れるかを見ました。複数のベクトル表現におけるクエリ結果は、そのクエリが多くの点で意味的に類似していることを意味する。次のステップのために、画像モデル、異次元の言語モデル、またはあなたのデータでこれを試してみてください。

読み続けて

Context Engineering Strategies for AI Agents: A Developer’s Guide
Learn practical context engineering strategies for AI agents. Explore frameworks, tools, and techniques to improve reliability, efficiency, and cost.

Zilliz Cloud Launches in AWS Australia, Expanding Global Reach to Australia and Neighboring Markets
We're thrilled to announce that Zilliz Cloud is now available in the AWS Sydney, Australia region (ap-southeast-2).

How to Build RAG with Milvus, QwQ-32B and Ollama
Hands-on tutorial on how to create a streamlined, powerful RAG pipeline that balances efficiency, accuracy, and scalability using the QwQ-32B and Milvus.