




Funzioni di attivazione nelle reti neurali

Funzioni di attivazione nelle reti neurali
 Activation Functions.png
Activation Functions.png
I recenti progressi nell'intelligenza artificiale (AI ) sono stati incredibili, in particolare nel riconoscimento delle immagini, nell'elaborazione del linguaggio naturale (NLP) e nelle auto a guida autonoma. Un fattore chiave che contribuisce a questi risultati è la capacità delle reti neurali artificiali di stimare funzioni complesse e non lineari spesso presenti nei dati del mondo reale. Questa capacità è attribuita principalmente alle funzioni di attivazione, che introducono non linearità nelle reti neurali, consentendo loro di modellare relazioni e pattern complessi.
Comprendiamo a fondo le funzioni di attivazione, il loro scopo, come funzionano e perché sono importanti per le reti neurali.
Cosa sono le funzioni di attivazione?
Le funzioni di attivazione sono funzioni matematiche utilizzate nelle reti neurali per determinare l'output di un neurone, introducendo non linearità nel modello. Vengono applicate agli input dei nodi (neuroni), le unità fondamentali di una rete neurale, per produrre l'output del nodo. Una rete neurale calcola la somma pesata degli input, aggiunge un bias e poi fa passare questa somma attraverso la funzione di attivazione, che restituisce un valore modificato. Questo valore viene passato al livello successivo della rete o diventa l'output finale.
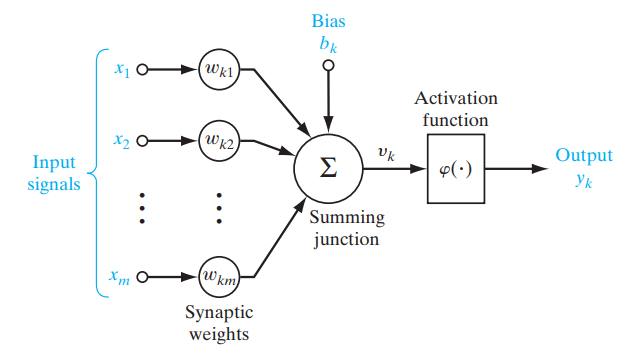 Figure- Role of an activation function in a neural network. .png
Figure- Role of an activation function in a neural network. .png
Figura: Ruolo di una funzione di attivazione in una rete neurale. | Fonte
Perché la non linearità è importante?
Per capire perché le funzioni di attivazione sono essenziali, è importante sapere perché i modelli lineari hanno delle limitazioni. Un modello lineare rappresenta una relazione in linea retta tra input e output. Funziona bene in compiti semplici, ma fallisce quando i dati sono più complessi e presentano pattern non lineari.
La non linearità consente alle reti neurali di creare confini decisionali che non sono linee rette. Pertanto, le reti neurali possono comprendere pattern non lineari nei dati che non possono essere rappresentati da modelli lineari.
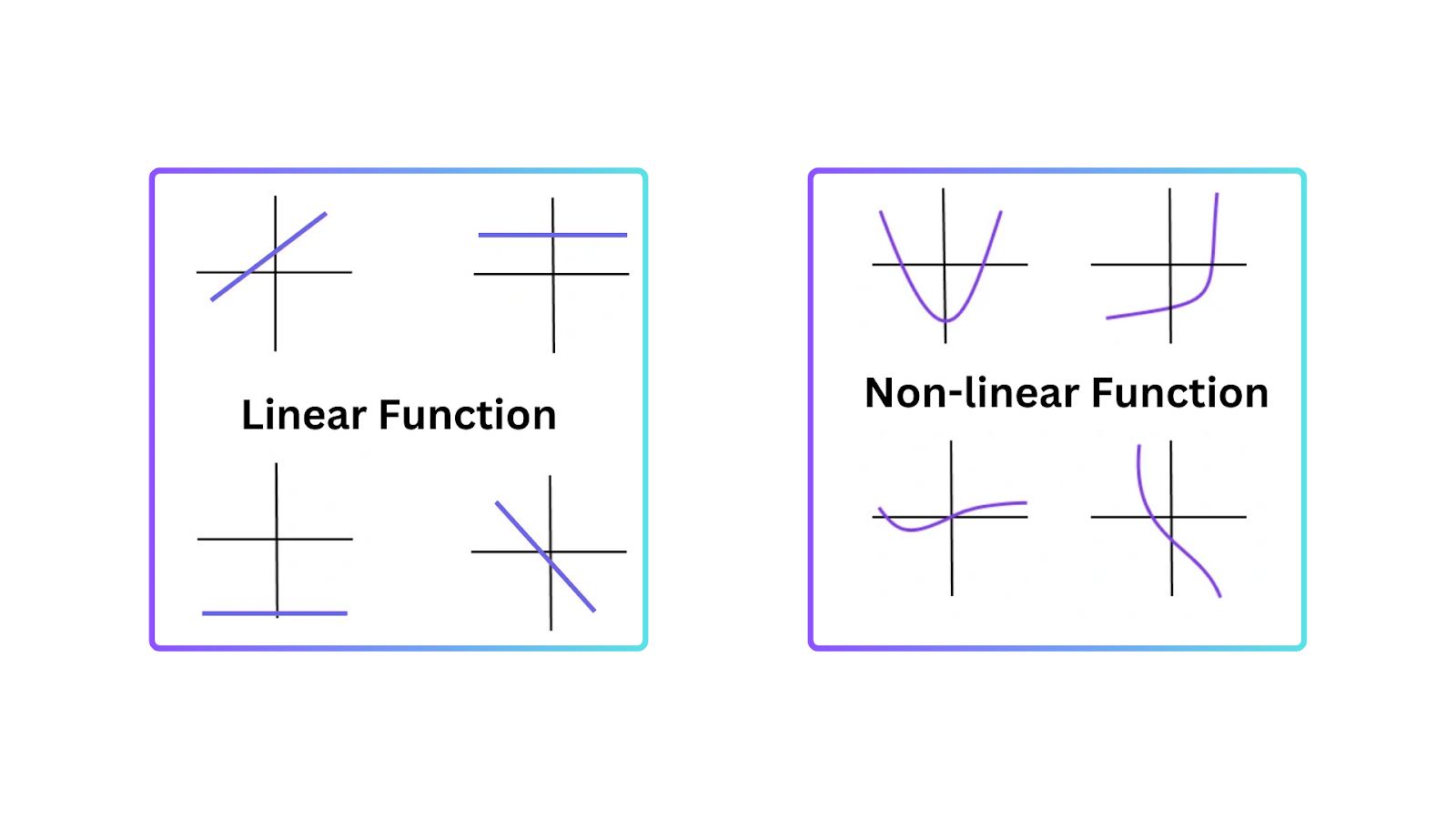 Figure- Types of Functions.png
Figure- Types of Functions.png
Figura: Tipi di funzioni
Come funzionano le funzioni di attivazione
Ora che abbiamo introdotto le funzioni di attivazione, vediamo come queste funzioni operano matematicamente per convertire il segnale di input in un segnale di output, un intervallo spesso compreso tra 0 e 1 o tra -1 e 1. In ciascun neurone di una rete neurale, i dati fluiscono attraverso i seguenti passaggi:
Input: Ogni neurone in una rete neurale riceve uno o più input. Questi input possono provenire dai dati originali immessi nella rete (nel caso del livello di input) o dagli output dei neuroni nel livello precedente.
Calcolo della somma pesata: Gli input vengono moltiplicati per i pesi corrispondenti per determinarne l'importanza. Poi, gli input pesati vengono sommati e viene restituito un singolo valore, noto come somma pesata.
Applicazione della funzione di attivazione: Una volta calcolata la somma pesata, questa viene passata attraverso una funzione di attivazione e il risultato della funzione di attivazione diventa l'output del neurone.
Questo processo si ripete in ogni neurone attraverso i livelli della rete per modificare i dati in modi più complessi.
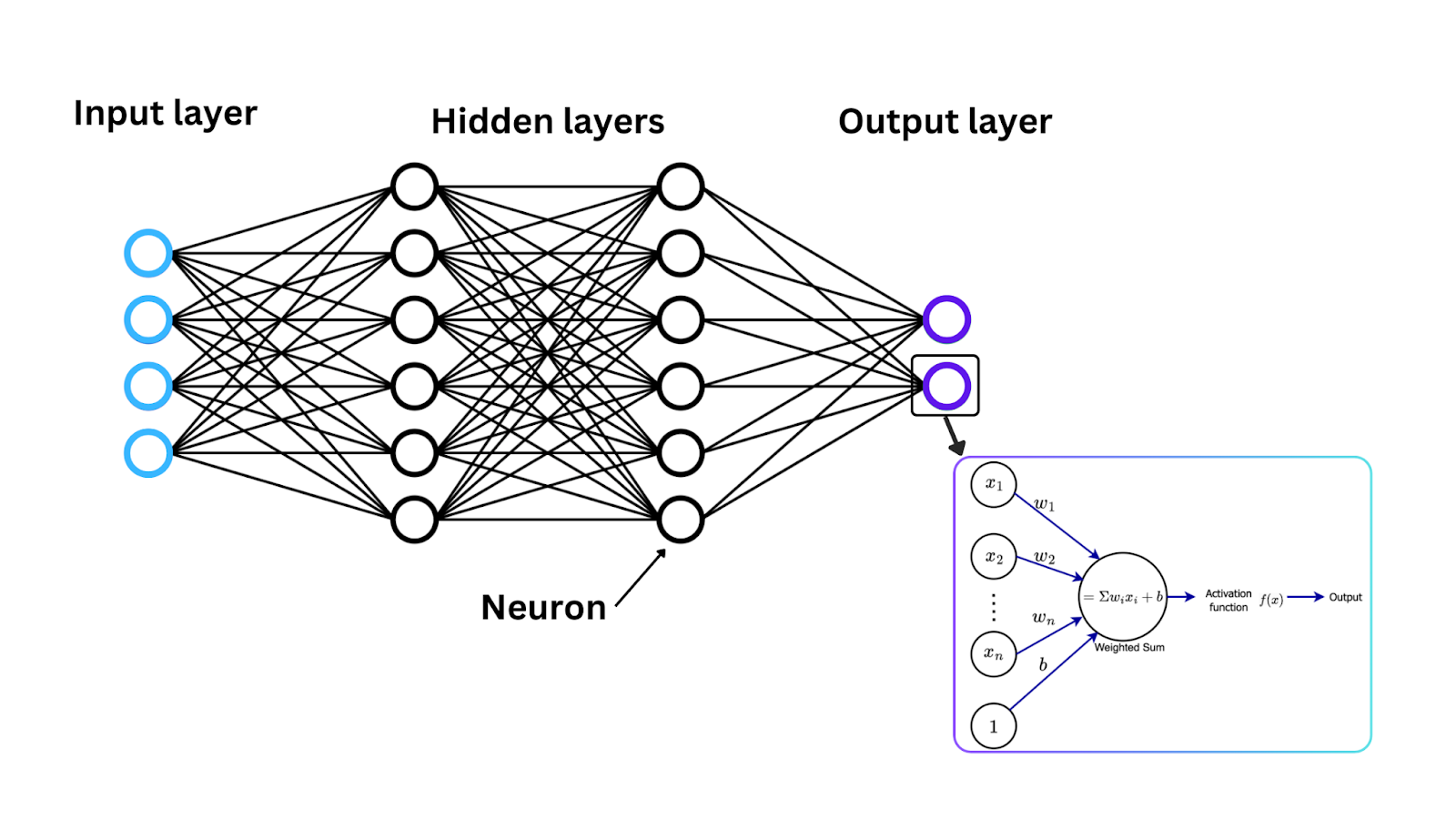 Figure- Neural network architecture, activation function, and neuron weight updates. .png
Figure- Neural network architecture, activation function, and neuron weight updates. .png
Figura: Architettura della rete neurale, funzione di attivazione e aggiornamenti dei pesi dei neuroni.
Le reti neurali utilizzano diversi tipi di funzioni di attivazione. Ogni funzione ha i propri punti di forza ed è più adatta a compiti specifici. Ad esempio, la funzione sigmoide è ottimale per problemi di classificazione binaria, softmax è utile per la previsione multi-classe e ReLU aiuta a superare il problema del gradiente evanescente.
Scegliere la funzione di attivazione giusta accelera l’addestramento e migliora le prestazioni. Ora, diamo un’occhiata ad alcune delle funzioni di attivazione più comuni:
Attivazione Sigmoide
Attivazione ReLU (Rectified Linear Unit)
Attivazione Tanh (Tangente Iperbolica)
Attivazione Leaky ReLU
Attivazione Sigmoide
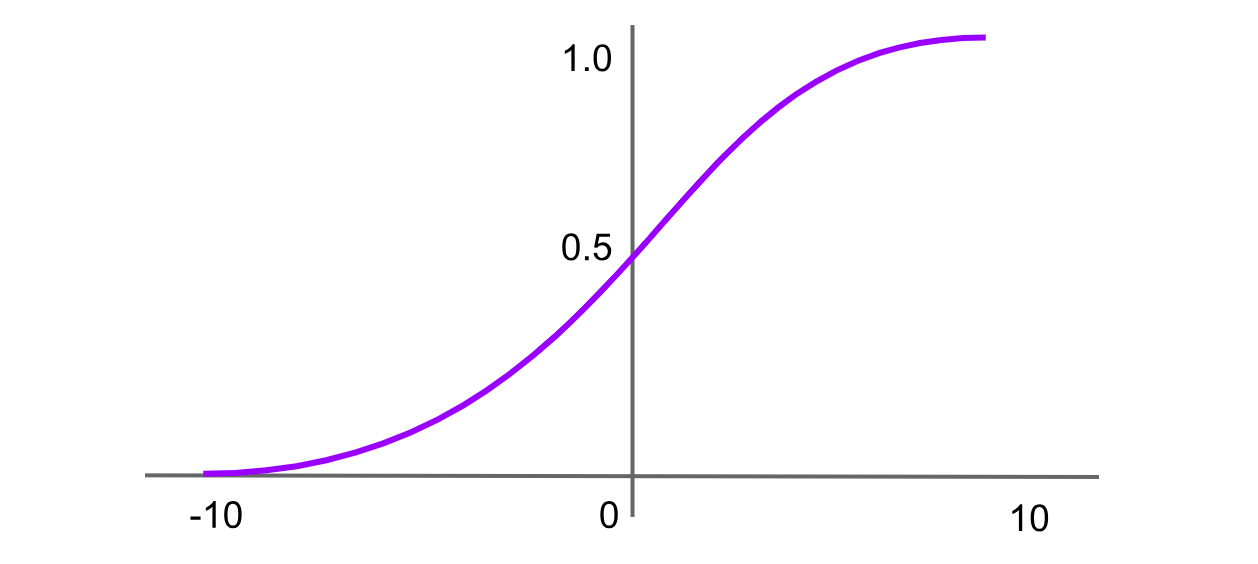 Figure- Sigmoid activation function.png
Figure- Sigmoid activation function.png
Figura: funzione di attivazione sigmoide
La funzione sigmoide, nota anche come funzione logistica, è una delle prime e più conosciute funzioni di attivazione. Mappa qualsiasi valore di input in un intervallo compreso tra 0 e 1, producendo una curva a forma di "S". La formula per la funzione sigmoide è:
Sigmoide = σ(x) = 1 / (1 + exp(-x))
Ecco il codice per definire la funzione sigmoide in Python.
import numpy as np
def sigmoid_function(x):
z = (1/(1 + np.exp(-x)))
return z
Le funzioni sigmoidi sono utili per i modelli in cui dobbiamo prevedere la probabilità come output. Ad esempio, nei problemi di classificazione binaria, vogliamo che l’output sia interpretato come una probabilità compresa tra 0 e 1.
Tuttavia, la Sigmoide presenta un problema di gradiente evanescente. Durante la backpropagation (quando la rete apprende aggiornando i pesi), i gradienti della sigmoide diventano molto piccoli, il che causa un apprendimento lento per gli strati più profondi.
Attivazione Softmax
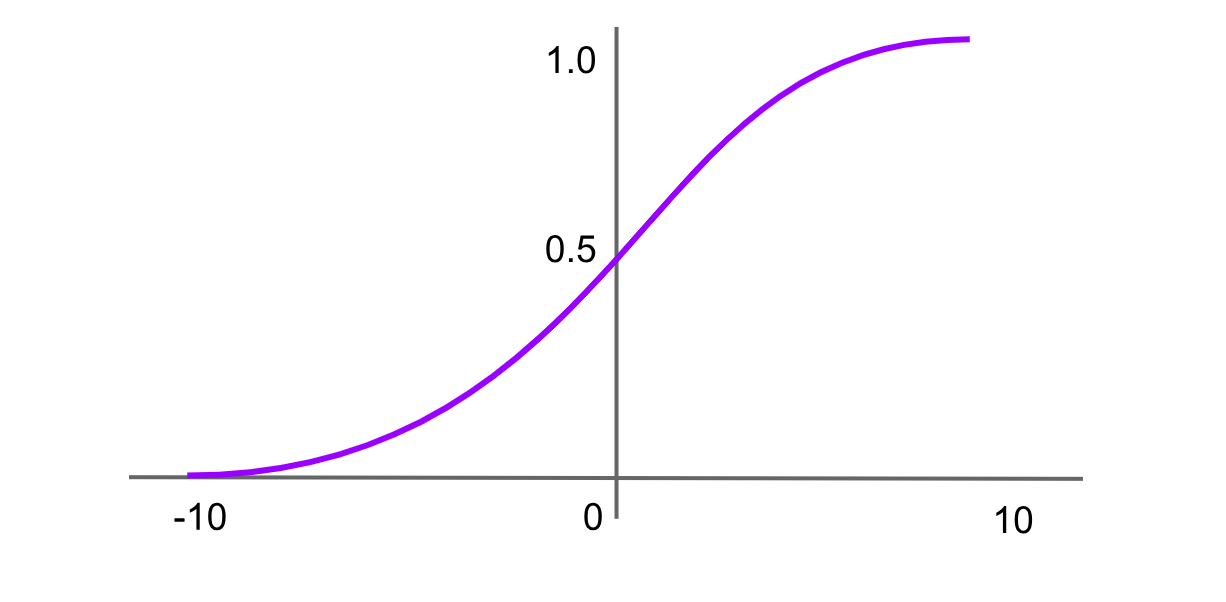 Figure- Softmax activation function.png
Figure- Softmax activation function.png
Figura: funzione di attivazione softmax
La funzione softmax è comunemente usata nello strato di output delle reti neurali per problemi di classificazione multi-classe. Prende in input un vettore di numeri reali e lo normalizza in una distribuzione di probabilità sulle classi. Ogni output è compreso tra 0 e 1, e la somma di tutti gli output è 1. La formula per la funzione softmax è:
Softmax(x)=f(xi)= exp(x) / sum(exp(x))
Scriviamolo in Python.
def softmax_function(x):
z = np.exp(x)
z_ = z/z.sum()
return z_
Tuttavia, Softmax può essere computazionalmente costosa, soprattutto nelle reti di grandi dimensioni, poiché richiede il calcolo degli esponenziali e la loro normalizzazione attraverso tutti gli output.
Attivazione ReLU (Rectified Linear Unit)
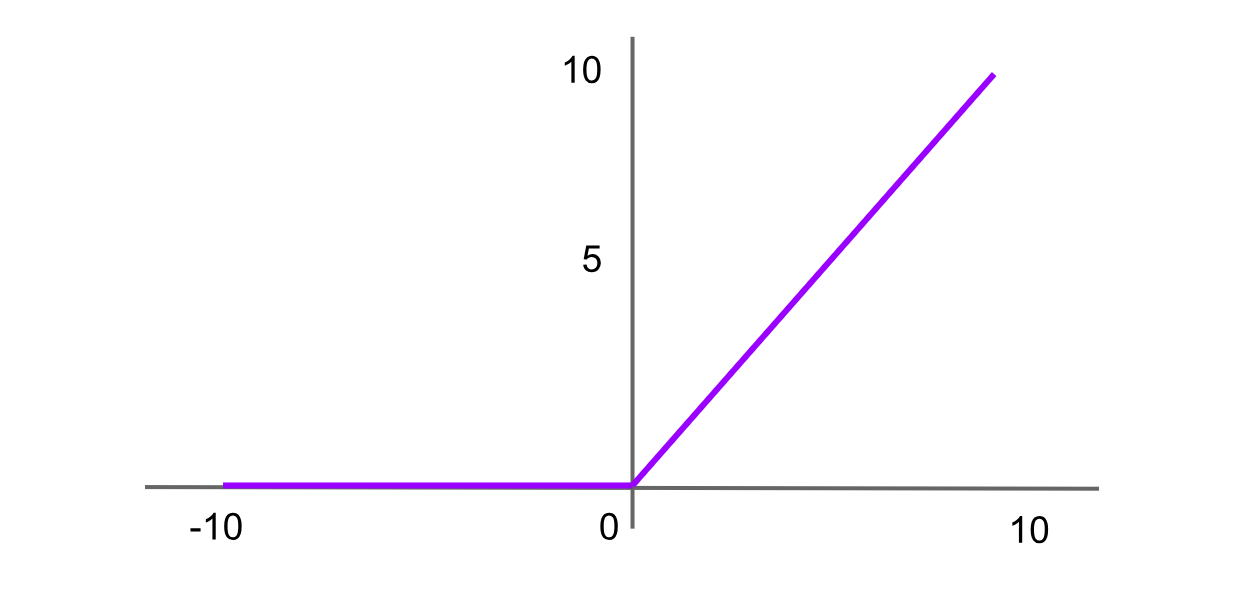 Figure- ReLU activation function.png
Figure- ReLU activation function.png
Figura: funzione di attivazione ReLU
ReLU è una delle funzioni di attivazione più utilizzate nelle reti neurali avanzate. Restituisce 0 per qualsiasi input negativo e, per i valori positivi, restituisce il valore stesso. La formula per la funzione ReLU è:
ReLU = f(x) = max(0,x)
Ecco la funzione Python per ReLU:
def relu_function(x):
if x<0:
return 0
else:
return x
ReLU è usata negli strati nascosti delle reti neurali, in particolare nei compiti di computer vision. È computazionalmente efficiente perché non ha operazioni esponenziali o di divisione. Rispetto alla sigmoide, è anche meno influenzata dal problema del gradiente evanescente. Tuttavia, c’è uno svantaggio di ReLU, ovvero il problema della “ReLU morente”. Se un neurone produce costantemente zero per tutti gli input, diventa inattivo e non può più contribuire all’apprendimento.
Attivazione Tanh (Tangente Iperbolica)
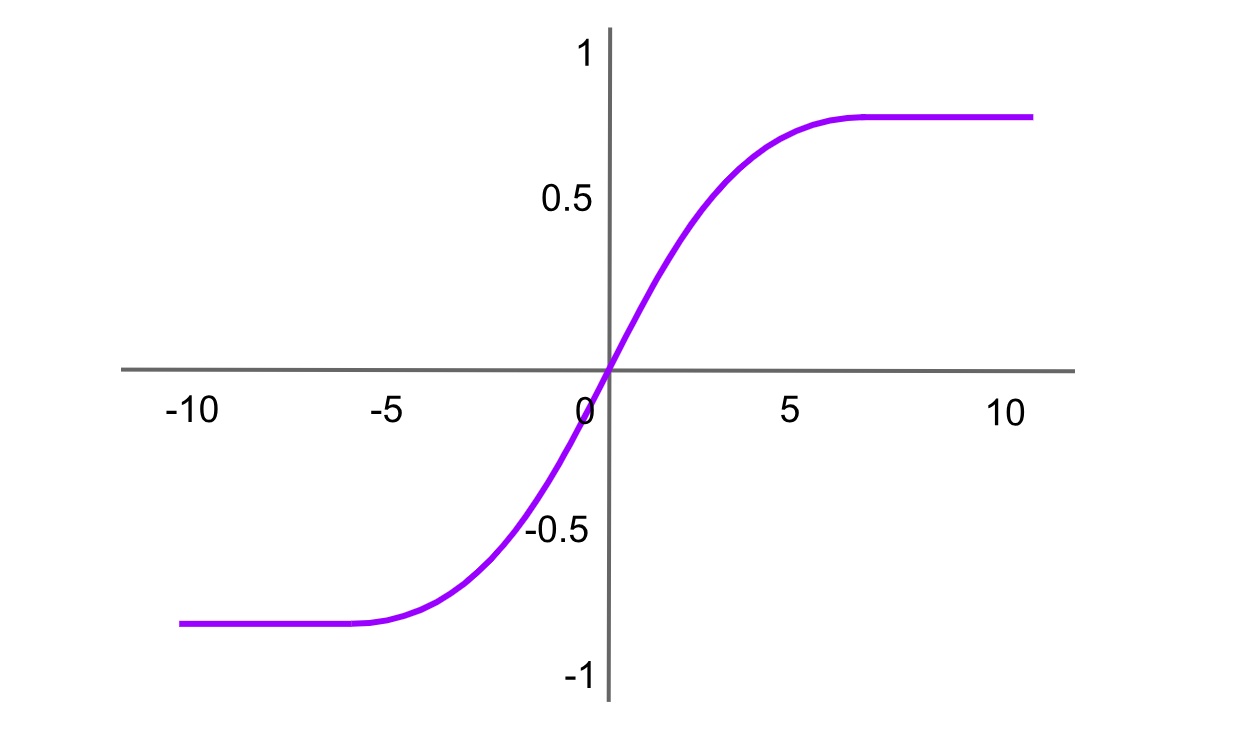 Figura- Funzione di attivazione Tanh .png
Figura- Funzione di attivazione Tanh .png
Figura: Funzione di attivazione Tanh
La funzione tangente iperbolica è simile alla funzione sigmoide ma produce valori compresi tra -1 e 1. La formula della funzione Tanh è:
tanh(x)= f(x)= 2 / (1+exp (−2x ))−1
Oppure
tanh(x)= f(x)=2sigmoid(2x)-1
Ecco il codice Python per la stessa:
def tanh_function(x):
z = (2/(1 + np.exp(-2*x))) -1
return z
La tangente iperbolica è utilizzata negli strati nascosti delle reti neurali, in particolare nelle attività di elaborazione del linguaggio naturale (NLP). Condivide alcune somiglianze con la funzione sigmoide, ma ha il vantaggio di essere centrata sullo zero, il che può accelerare l'apprendimento in determinate reti. Tuttavia, come la funzione sigmoide, anche tanh è influenzata dal problema del gradiente evanescente.
Attivazione Leaky ReLU
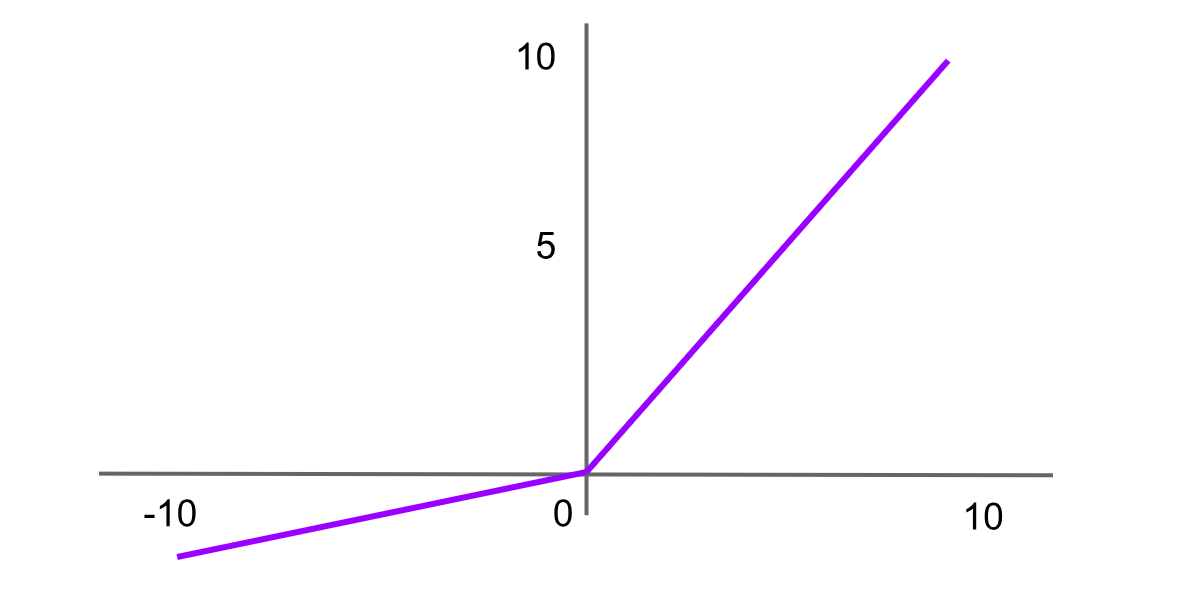 Figura- Funzione di attivazione Leaky ReLU .png
Figura- Funzione di attivazione Leaky ReLU .png
Figura: Funzione di attivazione Leaky ReLU
Leaky Rectified Linear Unit, o Leaky ReLU, è una variante di ReLU progettata per risolvere il problema della “dying ReLU” introducendo una piccola pendenza per i valori negativi invece di una pendenza piatta. Questo aiuta i neuroni a continuare ad apprendere invece di rimanere permanentemente inattivi. La formula della funzione Leaky ReLU è:
Leaky ReLU = f(x)=max(αx,x)
Qui, 𝛼 α è una piccola costante positiva (ad esempio, 0,01) per garantire che il neurone produca un piccolo valore negativo invece di zero per gli input negativi. Poiché Leaky ReLU è una variante di ReLU, il codice Python può essere implementato con una piccola modifica.
def leaky_relu_function(x):
if x<0:
return 0.01*x
else:
return x
Confronto
Per ottenere una comprensione migliore delle funzioni di attivazione, è utile confrontarle con altri componenti chiave delle reti neurali:
Funzioni di attivazione vs. funzioni di perdita
Le funzioni di attivazione definiscono come i neuroni in una rete rispondono ai segnali in ingresso. Vengono applicate agli output dei neuroni (o degli strati) per introdurre non linearità, il che aiuta la rete a comprendere schemi e relazioni nei dati.
D'altra parte, le funzioni di perdita sono utilizzate per determinare quanto bene le previsioni della rete neurale corrispondono ai valori target effettivi (la verità di riferimento). Calcolano l'errore tra l'output previsto e i risultati effettivi. Inoltre, gli algoritmi di ottimizzazione regolano i pesi della rete durante l'addestramento per minimizzare questo errore. Le funzioni di perdita includono:
Errore quadratico medio (MSE) è comunemente utilizzato per attività di regressione.
Perdita di entropia incrociata è utilizzata per attività di classificazione.
Funzioni di attivazione vs. normalizzazione
Le funzioni di attivazione controllano come i dati si spostano da uno strato all'altro e come i neuroni "si attivano" in base agli input.
Tuttavia, la normalizzazione, come la normalizzazione batch, aiuta a rendere l'addestramento più efficace. Funziona modificando la distribuzione degli input a uno strato per accelerare l'apprendimento della rete e prevenire gradienti evanescenti o esplosivi. La normalizzazione batch normalizza l'input di ciascuno strato affinché abbia una media e una varianza coerenti e aiuta la convergenza della rete a essere più facile. Altre tecniche di normalizzazione includono:
Normalizzazione layer: Normalizza attraverso ciascuno strato.
Normalizzazione instance: Solitamente utilizzata nell'elaborazione delle immagini, normalizza ciascuna istanza separatamente.
Vantaggi e sfide delle funzioni di attivazione
Le funzioni di attivazione offrono diversi vantaggi alle reti neurali, ma presentano anche sfide che devono essere affrontate. Discutiamo prima i vantaggi delle funzioni di attivazione.
Non linearità: Il vantaggio più importante delle funzioni di attivazione è che introducono la non linearità nella rete. Questo aiuta le reti a catturare pattern non lineari nei dati ed è ideale per attività come il riconoscimento delle immagini e la comprensione del linguaggio naturale.
Intervallo di output: Funzioni di attivazione come sigmoid e softmax limitano gli output entro un intervallo specifico (0-1 per sigmoid e tra -1 e 1 per tanh). Questo rende molto più semplice comprendere gli output, soprattutto nelle attività di classificazione.
Calcolo efficiente: Alcune funzioni, come ReLU, sono efficienti dal punto di vista computazionale, il che consente alle reti di scalare ed essere applicate a grandi dataset.
Ora, discutiamo le sfide delle funzioni di attivazione.
Problema del gradiente evanescente: è comune nelle reti neurali profonde, soprattutto quando si utilizzano funzioni di attivazione come sigmoid e tanh. Durante la retropropagazione, i gradienti possono diventare molto piccoli mentre si propagano attraverso più layer della rete, causando una convergenza lenta della rete e impedendole di apprendere in modo efficace.
Gradienti esplosivi: I gradienti esplosivi sono un problema in cui si accumulano grandi gradienti di errore, con conseguenti aggiornamenti molto grandi dei pesi dei modelli di reti neurali durante il processo di training. Questo rende il modello instabile e incapace di apprendere dai dati di training.
Scelta della funzione: Scegliere la funzione di attivazione ottimale per un'attività o una rete neurale può essere impegnativo e di solito richiede una certa sperimentazione. Dipende dal tipo di problema che stiamo cercando di risolvere.
Casi d'uso delle funzioni di attivazione
Le funzioni di attivazione sono componenti importanti di varie architetture di reti neurali che svolgono compiti diversi. Ecco alcune applicazioni chiave:
Classificazione delle immagini: Le Convolutional Neural Networks (CNN) utilizzano l'attivazione ReLU nei loro layer nascosti per elaborare i dati dei pixel e softmax nel layer di output per la classificazione multiclasse.
Elaborazione del linguaggio naturale (NLP): Le Recurrent Neural Networks (RNNs), Long Short-Term Memory (LSTM) e i Transformers utilizzano attivazioni tanh o ReLU nei loro layer nascosti per elaborare dati sequenziali.
Modelli generativi: Le Generative Adversarial Networks (GANs) utilizzano tipicamente ReLU o LeakyReLU nella rete generatrice per introdurre non linearità e generare output realistici, e sigmoid nella rete discriminatrice.
Diversi framework di deep learning, tra cui TensorFlow e PyTorch, forniscono un'ampia gamma di funzioni di attivazione integrate e implementazioni per creare le proprie funzioni personalizzate.
FAQ sulle funzioni di attivazione
- Che cos'è la funzione di attivazione?
Le funzioni di attivazione sono elementi fondamentali delle reti neurali che consentono loro di apprendere pattern complessi nei dati di input. Convertono il segnale di input di un nodo (neurone) in un segnale di output, che viene poi passato al layer successivo della rete neurale.
- Perché viene utilizzata la funzione di attivazione ReLU?
La funzione di attivazione ReLU introduce non linearità in una rete neurale, il che aiuta a ridurre il problema del gradiente evanescente durante il training del modello di machine learning.
- Quali sono le funzioni di attivazione più comunemente utilizzate?
ReLU, Leaky ReLU, Softmax e Swish sono funzioni di attivazione popolari.
- A cosa serve la funzione di attivazione?
Lo scopo principale di una funzione di attivazione è trasformare l'input ponderato sommato da un nodo in un valore di output, che viene poi passato al layer nascosto successivo o utilizzato come output finale.
- Si possono avere più funzioni di attivazione?
Sì, è comune avere funzioni di attivazione diverse in livelli diversi di una rete neurale. Ad esempio, una configurazione standard potrebbe usare l'attivazione ReLU nei livelli nascosti e softmax nel livello di output per un problema di classificazione multiclasse.
Ulteriori risorse
- Cosa sono le funzioni di attivazione?
- Come funzionano le funzioni di attivazione
- Confronto
- Vantaggi e sfide delle funzioni di attivazione
- Casi d'uso delle funzioni di attivazione
- FAQ sulle funzioni di attivazione
- Ulteriori risorse
Contenuto
Inizia gratis, scala facilmente
Prova il database vettoriale completamente gestito progettato per le tue applicazioni GenAI.
Prova Zilliz Cloud gratuitamente