




What is Video AI?

What is Video AI?
TL;DR
Video AI is a specialized field of artificial intelligence that analyzes and extracts insights from video content by processing sequential frames of data to understand motion, activities, and temporal patterns. Unlike Image AI, which processes static images, Video AI incorporates the critical time dimension, allowing it to interpret dynamic content and recognize complex patterns that unfold over time.
Introduction
Imagine scrolling through TikTok or YouTube and instantly finding the exact video you were looking for. Smart security cameras now detect faces and alert homeowners immediately. Augmented Reality (AR) apps let you see how furniture fits in your living room in real-time. These advancements are made possible by Video AI.
Video is projected to account for 82% of all internet traffic by 2025. This massive influx of video data requires advanced technologies to analyze and manage it, making Video AI indispensable. Video AI differs from Image AI primarily due to the time dimension. While Image AI analyzes static images, Video AI processes sequences of frames over time, capturing motion and temporal patterns. This complexity necessitates the use of advanced algorithms to interpret dynamic content.
From self-driving cars to sports analytics and Netflix recommendations, industries utilize video AI to gain insights from their environment. It’s changing the way we see and understand the world. But what exactly is it, and how does it work?
This post introduces the core principles of video data and its associated challenges, as well as the differences between video AI and image AI, with a focus on the complexities of time-based analysis. You’ll learn about key use cases across industries and understand the growing need for automated video insights.
From Image AI to Video AI: Understanding the Jump
AI must go beyond static images to understand motion and events over time as video content grows. This shift introduces new challenges and requires advanced techniques for effective analysis.
Temporal Dimension & Complexity
Unlike Image AI, which processes single frames, Video AI must analyze sequences to capture movement and context. Identifying a person in an image is simple, but recognizing whether they are walking, running, or falling requires tracking changes across multiple frames. This added complexity requires specialized models, such as 3D convolutions and transformers, which process both spatial and temporal features. Handling variations in frame rate, motion blur, and continuity makes video analysis more challenging than static image recognition.
Growth of Video Data
Platforms like YouTube, TikTok, and Instagram Reels generate a large amount of video content–YouTube alone sees over 360 hours of video uploaded every minute. Businesses also rely heavily on video sources such as CCTV surveillance, which produces petabytes of footage daily, making manual review infeasible. AI is now essential for real-time monitoring, video search, and automated insights, making Video AI a critical tool across industries.
Common Video AI Use Cases
Video AI is reshaping industries by enabling automation, enhancing insights, and improving user experiences. Some of the most impactful applications include:
Surveillance & Security: AI detects intruders, anomalies, and unusual movements in real time, improving public and private security.
Sports & Entertainment: Coaches and analysts use AI to break down game footage, track players, and automatically generate highlight reels.
Augmented Reality (AR): AI enables gesture recognition, object tracking, and real-time overlays, enhancing gaming, shopping, and interactive experiences.
Content Creation: AI automates video editing, scene segmentation, and smart cropping, streamlining production for creators and media companies.
 Picture 1. Use cases of video AI
Picture 1. Use cases of video AI
Core Concepts in Video AI
Video AI incorporates temporal information, embedding representations, and advanced tracking methods. AI models must understand motion, recognize activities, and detect objects over time. This section discusses the key technical concepts that power modern Video AI.
Temporal Modeling
Unlike images, where each frame is independent, video consists of sequential frames that form a continuous flow. Capturing spatial (object details) and temporal (motion over time) features is crucial for tasks like action recognition and video summarization.
Here are three key approaches to handling temporal information:
CNN + RNN Approaches: Early Video AI models combined 2D Convolutional Neural Networks (CNNs) for frame-based feature extraction with Recurrent Neural Networks (RNNs) or Long Short-Term Memory (LSTMs) to model temporal dependencies. These methods struggled with long-range dependencies and required sequential processing. They were not scalable due to vanishing gradient problem.
3D Convolutions: Neural Networks like 3D Convolution (C3D) and Inflated 3D (I3D) extract spatial and temporal features simultaneously. These models apply 3D kernels across width, height, and time, allowing them to understand motion patterns within video.
Transformers for Video AI: Recently, transformers have completely changed the way we understand videos. Models like TimeSformerand Multiscale Vision Transformers(MViT) use self-attention mechanisms to efficiently analyze both spatial and temporal dependencies. These architectures scale better than RNNs and have achieved state-of-the-art results in action recognition and video classification.
Video Embeddings
Video AI often requires representing video clips in a compact, numerical format for tasks like search, similarity comparison, and classification. This is where video embeddings come into play.
Several deep learning architectures are used to generate video embeddings:
SlowFast Networks: This model consists of two pathways—one operating at a slow frame rate to capture spatial details and another at a fast frame rate to capture motion dynamics.
MoViNet (Mobile Video Networks): A family of efficient convolutional neural networks optimized for streaming video processing, designed to handle long video sequences with low latency.
TimeSformer: A transformer-based model that applies self-attention across both spatial and temporal dimensions, enabling video understanding without the need for 3D convolutions.
These models process raw video frames and generate fixed-length embeddings that capture essential motion and content features.
Given the size of video data, embeddings are often stored in vector databases for fast retrieval. This is useful in applications like content-based video search, video deduplication, and recommendation systems.
Action & Activity Recognition
Beyond detecting objects, Video AI must recognize actions by analyzing movement patterns over time. Action recognition involves identifying sequences of motion across multiple frames. For example, distinguishing whether a person is running, sitting, or spilling coffee requires tracking changes in posture and movement rather than relying on a single image. Training robust models for action recognition depends on large, well-annotated datasets like Kinetics and ActivityNet, which contain thousands of labeled video clips covering diverse human activities.
Video Object Detection & Tracking
Object detection in videos is more complex than in images because objects move, change appearance, and may be occluded over time. Modern models like YOLO v12 and Detectron2 detect objects in each frame, generating real-time bounding boxes. However, to maintain object identity across frames, tracking models like DeepSORT and ByteTrack associate detections over time. This is crucial for applications such as autonomous driving, sports analytics, and security surveillance, where consistent object tracking ensures accurate analysis and decision-making.
Essential Architectural Components for Video AI Systems
Building efficient Video AI systems requires powerful. Handling large video datasets demands optimized pipelines, real-time model acceleration, and scalable indexing methods.
Data Pipelines & Preprocessing
Raw video files are often too large for direct AI processing. Preprocessing helps reduce computational load while preserving essential features.
Chunking & Frame Extraction: Instead of processing entire videos, AI models analyze smaller clips or extract key frames to focus on relevant sections.
Resolution & Frame Rate Reduction: Lowering resolution (e.g., from 4K to 720p) and frame rate (e.g., 60 FPS to 30 FPS) speeds up inference, but this must be balanced against accuracy loss.
Normalization & Compression: Standardizing color, brightness, and aspect ratios ensures consistency across video sources, while compression techniques like H.264 or H.265 help manage storage without excessive quality loss.
Model Inference & Acceleration
Processing video data in real-time requires high computational power. AI models must be optimized for fast inference without compromising accuracy.
GPU Acceleration: Modern Video AI models leverage GPUs (e.g., NVIDIA TensorRT, CUDA) for parallel processing, significantly reducing inference time.
Batch Processing: Instead of analyzing frames individually, models process batches simultaneously, improving efficiency.
Model Quantization & Pruning: Converting models from 32-bit floating-point to lower precision (e.g., INT8) reduces memory usage and speeds up inference with minimal accuracy trade-offs.
Edge Computing: Running AI models on edge devices (e.g., security cameras, AR headsets) requires minimal latency and allows real-time processing without cloud dependency.
Storage & Indexing
Efficient storage and retrieval of video insights are crucial. Traditional relational databases struggle with unstructured video data, necessitating the need for alternative solutions. Instead of storing raw video, embedding models generate video embeddings, which are stored, indexed and retrieved in vector Databases for fast similarity searches. These embeddings enable content-based video retrieval, anomaly detection, and recommendation systems.
Vector Databases: The Backbone of Modern Video AI
As we just discussed that video AI systems generate massive amounts of high-dimensional vector embeddings that traditional databases struggle to handle efficiently. Vector databases like Zilliz and Milvus are purpose-built to address these specific challenges.
Why Vector Databases are Essential for Video AI
Efficient Similarity Search: Video embeddings often contain hundreds or thousands of dimensions, making traditional indexing methods ineffective. Vector databases implement specialized algorithms like Approximate Nearest Neighbor (ANN) search that can query billions of vectors in milliseconds, enabling real-time video search and retrieval.
Temporal Pattern Recognition: Videos require understanding patterns across time. Vector databases can store and query embeddings from different temporal segments, allowing AI systems to detect complex patterns like actions, scenes, and events that unfold over time.
Scale with Growing Video Data: As video content continues to dominate internet traffic, systems need to scale horizontally. Vector databases like Milvus has a distributed architecture that allows organizations to expand their video processing capabilities without compromising on query speed or accuracy.
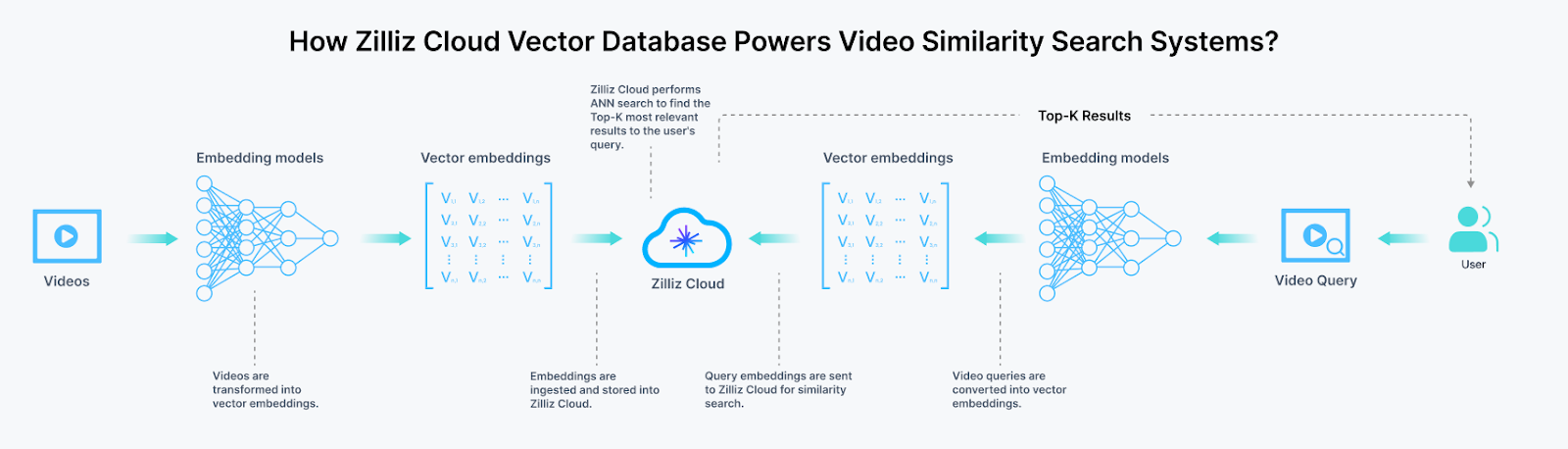 Picture 2. Video embedding and search with Zilliz | Source
Picture 2. Video embedding and search with Zilliz | Source
Key Video AI Applications Powered by Vector Databases
Content-Based Video Retrieval: Find visually similar videos or specific moments within videos without relying on manual tags or descriptions. This enables use cases like:
Detecting duplicate or near-duplicate content
Finding scenes with similar visual composition
Searching for specific actions or objects across video libraries
Real-Time Video Analytics: Process live video streams and make instant comparisons against existing databases:
Security systems that can identify suspicious activities in real-time
Sports analytics platforms that track player movements and tactics
Retail analytics for customer journey mapping and behavior analysis
Multimodal Video Understanding: Combine video embeddings with text, audio, or other metadata in a unified vector space:
Search videos using natural language queries
Find videos based on both visual content and spoken words
Create context-aware video recommendation systems
Implementing Video AI with Milvus
Milvus is an open-source vector databases purpose-built to handle high-dimensional vector embeddings. It provides the infrastructure needed to build scalable video AI applications through:
Optimized Indexing for Video Embeddings: Specialized indexing algorithms tailored for common video embedding models like SlowFast, TimeSformer, and MoViNet.
Hybrid Search Capabilities: Combine metadata filtering with similarity search to narrow results based on both semantic content and traditional attributes.
Streaming Pipeline Integration: Seamlessly connect with popular video processing frameworks to handle continuous data ingestion from multiple sources.
And more. Check this doc for more details.
Practical Implementation: Building a Video Search System with Milvus
This is a simple code snippet for building a video search system with Milvus. If you are not familiar with Milvus, check out its quickstart doc for more details.
from pymilvus import MilvusClient
import numpy as np
# Connect to Milvus
client = MilvusClient(uri="http://localhost:19530")
collection_name = "video_action_recognition"
# Create the collection (quick setup — index is auto-created)
if not client.has_collection(collection_name):
client.create_collection(
collection_name=collection_name,
dimension=512, # Vector dimension
metric_type="L2", # Similarity metric
description="Embeddings for video action recognition",
auto_id=True # Milvus will auto-generate primary keys
)
# Insert video embeddings and metadata
def insert_video_data(video_embeddings, metadata):
entities = []
for i, embedding in enumerate(video_embeddings):
entities.append({
"embedding": embedding,
"timestamp": metadata[i]["timestamp"],
"video_id": metadata[i]["video_id"],
"frame_number": metadata[i]["frame_number"],
"action_label": metadata[i]["action_label"]
})
client.insert(collection_name=collection_name, data=entities)
# Search for similar actions
def search_similar_actions(query_embedding, top_k=5):
client.load_collection(collection_name) # load before search
search_results = client.search(
collection_name=collection_name,
data=[query_embedding],
limit=top_k,
output_fields=["video_id", "timestamp", "action_label"],
search_params={"metric_type": "L2", "params": {"ef": 100}}
)
return search_results
Challenges & Considerations
Despite its rapid advancements, Video AI faces several challenges related to data quality, scalability, and ethical concerns. These factors impact model performance, deployment feasibility, and responsible AI adoption.
Data Quality & Labeling
Training accurate Video AI models requires large, well-labeled datasets, but annotating video is far more complex than labeling images.
Clip-Level vs. Frame-Level Labels: Unlike images that require a single label, videos need annotations across frames to capture movement and context. This increases annotation time and cost.
Manual Labeling Costs: High-quality labels require human annotators, making the process expensive and time-consuming, especially for large datasets.
Synthetic & Weak Labels: Researchers are exploring synthetic data (AI-generated labels) and weak supervision (using partially labeled data). These methods are promising, but they still require validation to ensure accuracy.
Scalability & Real-Time Requirements
Handling video data at scale requires robust infrastructure to process large volumes of continuous streams without compromising speed or accuracy.
Real-Time Processing: Applications such as autonomous driving, surveillance, and live video analytics require AI models that can process video in real-time. This demands optimized inference pipelines and edge computing.
Balancing Accuracy vs. Latency: High-resolution videos improve accuracy but slow down inference. Developers must strike a balance between processing speed and model precision, particularly for safety-critical tasks.
Multi-Camera Scalability: Enterprise use cases often involve hundreds of video feeds, such as those in smart cities and retail analytics. Scaling Video AI to handle simultaneous streams efficiently remains a major challenge.
Ethical & Privacy Concerns
Video AI raises significant privacy and ethical issues, especially in surveillance and facial recognition applications.
Surveillance & Facial Recognition Controversies: AI-powered surveillance can improve security but raises concerns about mass surveillance, bias, and potential misuse. Some governments have restricted facial recognition due to privacy violations.
Data Privacy Regulations: Compliance with laws like GDPR (General Data Protection Regulation) and CCPA (California Consumer Privacy Act) is essential when handling video data. They require strict policies on data storage, access, and user consent.
Bias in Video AI: Models trained on biased datasets may produce unfair outcomes, particularly in face detection, action recognition, and security applications. Ensuring diverse training data and bias-mitigation techniques is critical for ethical AI development.
Conclusion
Video AI is transforming how machines understand and analyze visual data. Unlike image AI, it incorporates the temporal dimension, making it more complex yet more powerful for applications like surveillance, sports analytics, AR, and content recommendation.
Vector databases like Milvus and Zilliz Cloud provide the essential infrastructure for building scalable, high-performance Video AI applications. By enabling efficient storage, indexing, and retrieval of high-dimensional video embeddings, vector databases make it possible to implement real-time video search, recommendation systems, and complex analytics at scale.
However, challenges like data labeling, real-time processing, and ethical concerns must be addressed to ensure responsible AI deployment. As video data continues to grow, advancements in AI models and infrastructure will bring to life even more sophisticated applications across industries.
Organizations that integrate Video AI with vector database technology gain crucial competitive advantages: faster search capabilities, more accurate recommendations, and analytics that can scale with the exponential growth of video content. This powerful combination is becoming the foundation for next-generation video intelligence systems that can derive meaning from the growing tsunami of visual data.
Related Resources
- TL;DR
- Introduction
- From Image AI to Video AI: Understanding the Jump
- Core Concepts in Video AI
- Essential Architectural Components for Video AI Systems
- Vector Databases: The Backbone of Modern Video AI
- Challenges & Considerations
- Conclusion
- Related Resources
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for Free