




Database Denormalization: A Comprehensive Guide

Database Denormalization: A Comprehensive Guide
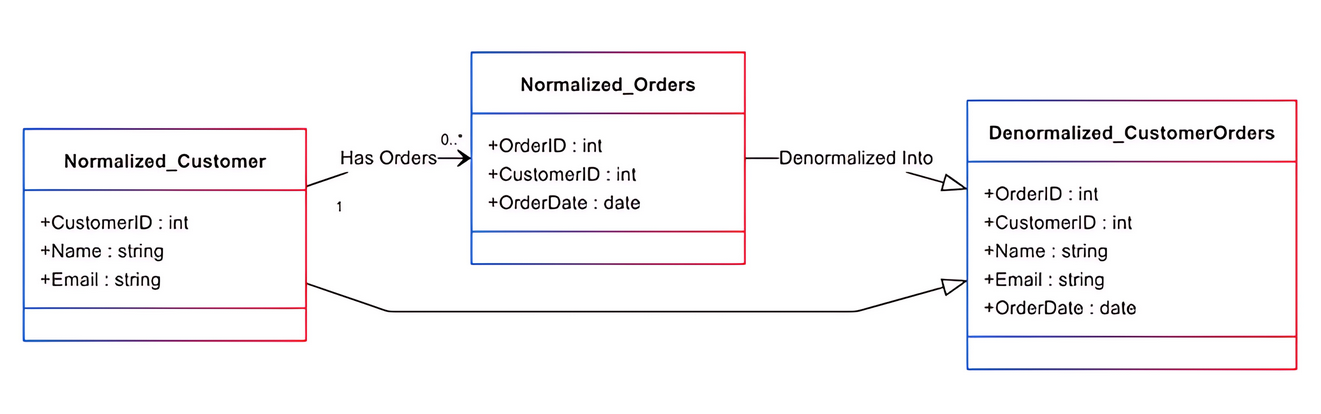
Figure 1: Database Denormalization Illustration
Why do some databases handle queries faster than others, even when dealing with large amounts of information? The answer lies in the database’s indexing, query optimization, and storage architecture. Fast data retrieval is crucial since it improves performance, user experience, and overall effectiveness.
Traditional database normalization maintains data integrity by organizing it into tables with well-defined relationships. While normalization improves data accuracy, it tends to cause a performance bottleneck in systems that use many joins. With so many tables and joins, it becomes harder to retrieve the data, slowing down application responsiveness.
One technique used for optimizing database performance is denormalization. Denormalization introduces redundant data into the database to optimize the read-heavy loads. This reduces the need for complex joins, thereby enhancing query performance.
This guide will explain the concept of database denormalization, compare it with normalization, and discuss its benefits. We will also uncover the use cases where database denormalization is beneficial and the challenges businesses might face while implementing it.
What Is Database Denormalization?
Database denormalization is an optimization technique that adds duplicate data to a previously normalized schema. This technique improves read performance by simplifying queries and reducing the number of joins.
Normalized databases suffer from multiple joins to fetch data between various tables, making them slow when working with large datasets. The denormalization technique is useful in systems that perform read operations rather than write operations.
For example, let’s say a normalized database contains three separate customer, order, and product tables. Retrieving a customer's order history with product details requires the database to join multiple tables, combining data from customers, orders, and products. A denormalized schema combines related data, such as product details, into one table to minimize joins and improve read performance.
However, a performance boost for read operations comes at a cost to write operations. Consistent data updates become more complex because the database needs to maintain redundant information.
How It Works
The denormalization process transforms normalized databases through restructuring to improve query and data retrieval speed and performance. While the normalization process eliminates duplicates while maintaining data consistency, denormalization adds duplicate data specifically to boost read operations in applications.
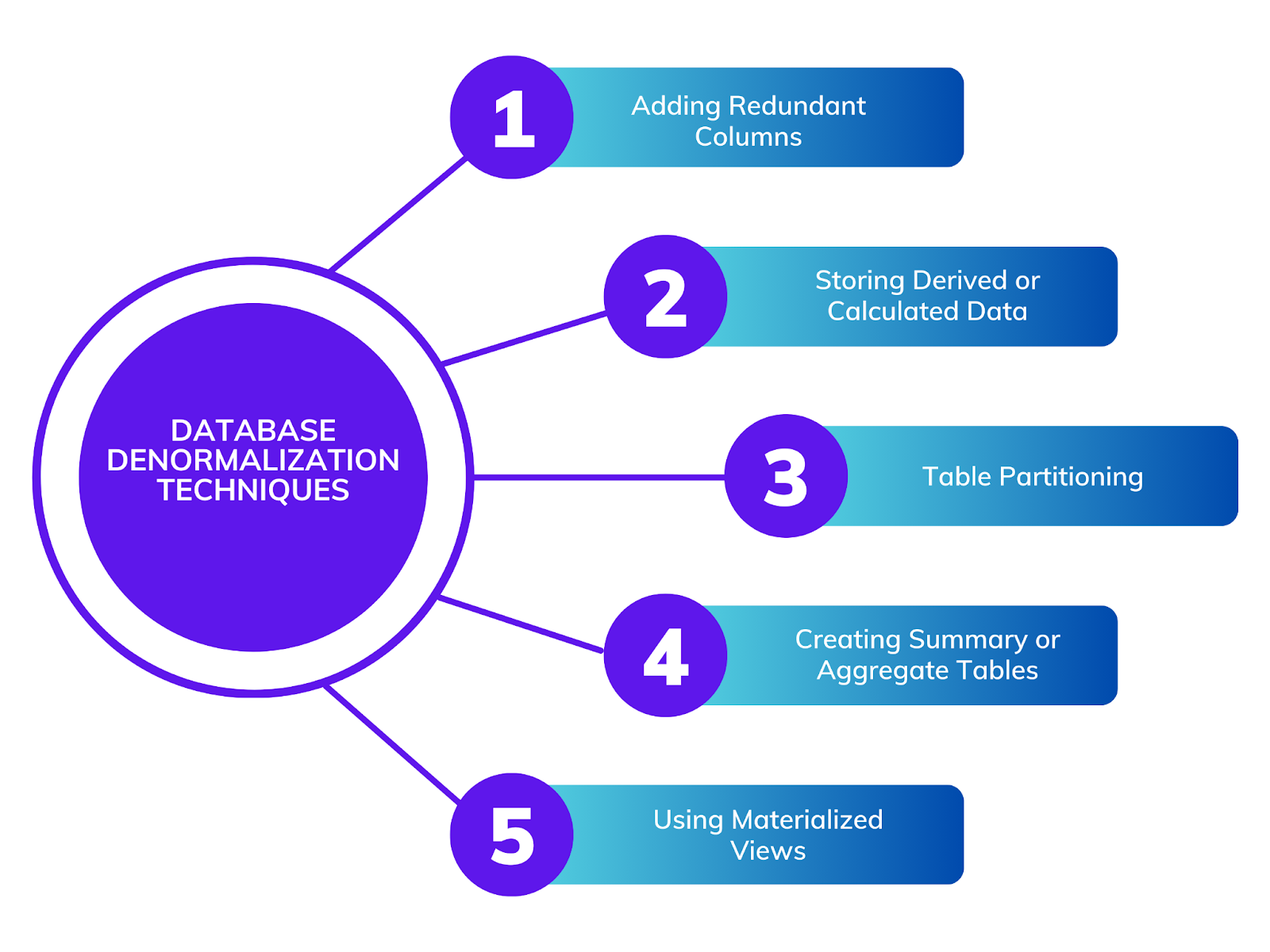
Databases that need real-time reporting, high-speed querying, and analytics widely adopt this technique. Below, we will discuss denormalization approaches and their impact on database effectiveness.
 Database Denormalization Approaches
Database Denormalization Approaches
Figure 2: Database Denormalization Approaches
Adding Redundant Columns
Adding redundant columns is a simple and standard method of denormalization. This involves adding data in multiple locations to reduce join operations. For example, a database's orders table has a foreign key named ID that connects it to the customer's table. The customer table contains essential details about each customer, such as their name, ID, and contact information.
When customer order details are analyzed, a join operation is needed to extract customer data. Joining tables can be particularly expensive and slow down overall performance. If the customer information is stored in the orders table, it eliminates the need for a join and leads to efficient data retrieval.
Though this method considerably improves the speed of queries, it increases data redundancy costs. When customer data changes, all the redundant copies must be updated for consistency. This calls for optimizing performance and managing data integrity through updates or triggers. Balancing this problem can be executed using well-defined update processes.
Storing Derived or Calculated Data
Another method of denormalization is storing and precomputing frequent calculations. In a normalized database system, calculations are done dynamically at query time. While this guarantees that the values are up to date, it also negatively affects the computation load.
System performance suffers when dealing with big datasets or numerous query requests. However, performance can be enhanced by adding these values as additional columns within existing table rows.
For example, the database can pre-store total order amounts in the orders table, so users do not need to recalculate this information when requesting their order history. The database system can deliver the value without extra processing because these values are already stored.
This technique is beneficial in the financial sector, e-commerce, and BI systems, which have a high volume of data that requires aggregated and complex calculations. However, maintaining the integrity of pre-computed values is vital. This subsequently necessitates periodic updates or trigger activations based on changes in the data.
Table Partitioning
Table partitioning is a key denormalization approach that splits big tables into partitions to enhance query processing and data retrieval speed. It provides exceptional results when processing extensive databases that contain transaction logs, audit records, and historical data sets. It is further divided into two parts:
Horizontal Partitioning: The partitioning technique divides a table into smaller partitions based on criteria such as date parameters, geographical areas, and user divisions. For example, an online retailer with millions of sales transactions can divide its orders table according to yearly partitions. Performance improves when queries need recent transactions because they require scanning a reduced data subset rather than the complete table.
Vertical Partitioning: Vertical partitioning functions differently from horizontal partitioning because it separates tables into distinct column-based sections. It divides tables into two parts by placing frequently accessed columns next to less frequently accessed ones so that queries only need to retrieve necessary data. The approach proves beneficial for wide tables containing numerous attributes because it enables queries to access only essential fields.
Both partitioning methods improve storage optimization and reduce query execution time, adding significant value to high-performance databases. However, the methods increase the complexity of indexing and partitioning and can result in query inefficiencies if proper strategies are not enforced.
Creating Summary or Aggregate Tables
Report generation and data analytics processing applications often extract real-time summary statistics from raw input. This typically takes significant processing power. Therefore, one approach is to aggregate tables. Instead of recalculation, a summary table can be used as a storage point, allowing instant access to pre-aggregated data.
Consider a retail company that analyzes sales performance across multiple regions. Creating a summary table with total sales aggregated per month for each region would make it easy to understand high-level insights.
This table could be updated in real-time, through triggers, or with scheduled batch updates. The summary table delivers faster query execution because it contains fewer rows than the original transactions table which enhances dashboard and report responsiveness.
While this method improves high-level insights, it also requires a strong data update mechanism. Batch processing or ETL pipelines can enforce up-to-date summary data retention.
Using Materialized Views
Materialized views are an advanced optimization feature that creates physical database objects containing query execution results. Standard views require dynamic query execution with each access. However, materialized views store their data on disk so users can retrieve information instantly without further processing.
Let’s take the example of an e-commerce website that monitors customer purchases. The site owners may create a materialized view that keeps track of the total spending per customer within several product categories. The database retrieves precomputed results rather than performing real-time calculations because this approach delivers faster query responses.
Materialized views can be periodically refreshed or incrementally updated depending on system requirements. The technique delivers exceptional benefits to databases requiring joins, aggregations, and multi-step transformations.
Comparison: Denormalization vs. Normalization
The selection between normalization and denormalization for database design depends on performance speed, storage efficiency, and data consistency requirements. This table shows the distinctions between denormalization and normalization.
| Aspect | Normalization | Denormalization |
| Purpose | Reduce redundancy | Improve read performance |
| Data Structure | Multiple related tables | Fewer tables, redundant data |
| Query Complexity | Complex joins | Simplified queries |
| Best For | Write-heavy applications | Read-heavy applications |
| Data Integrity | High | Potentially compromised |
| Storage Use | Efficient | Increased |
| Maintenance | Simplified | More complex |
| Update Anomalies | Minimized | Increased risk |
The database selection process demands analysis of data retrieval patterns, update speed requirements, and system performance specifications. A properly balanced database maintains operational efficiency and scalability.
Benefits and Challenges
Denormalization is an optimization method that adds redundant data to boost read operations and query execution speed. However, performance boosts may create problems with storage and anomalies. The benefits of denormalization require a balanced implementation that prevents potential risks from arising. Here are some of the benefits and challenges:
Benefits of Denormalization
Reduced application complexity: Denormalization simplifies application logic by eliminating the need for complex joins and multi-table queries. This improves the readability and simplicity of queries, leading to enhanced developer productivity.
Improved performance in distributed systems: Retrieving data from multiple nodes in distributed databases leads to delayed performance. Denormalization places duplicate data near its main access points. This lowers the need for node-to-node data retrieval. The technique proves valuable for cloud-based systems as well as horizontally scaled architectures.
Enhanced data warehousing efficiency: Data warehouses require efficient handling of analytical tasks that execute complex calculations and aggregation procedures. Denormalization benefits read performance by storing pre-joined or pre-aggregated data, eliminating the need for real-time data transformations.
Facilitates real-time analytics: Applications that perform analysis need immediate access to data for rapid insights. Denormalization reduces the requirement for complex real-time computations by storing precomputed values with redundant data.
Optimized reporting: Denormalized databases maintain preprocessed data for instant report creation and minimize the need for data transformation operations. This approach substantially advantages business intelligence applications and executive dashboards.
Challenges
Data anomalies: Data duplication creates a higher risk of data inconsistency because updates might not spread properly between all system instances. Data validation and consistency checks are important in denormalized systems to reduce the risk of anomalies.
Increased storage costs: Redundant data requires additional storage space, which increases the total database size. Cloud-based databases that use usage-based pricing models could experience higher costs due to storage requirements.
Complexity in data synchronization: Data synchronization requires every update operation to modify all data copies simultaneously, leading to performance limitations. Poor execution of data synchronization produces records containing inaccuracies or outdated information.
Potential for Data Integrity Issues: The improper execution of updates across multiple instances produces inconsistent data. This degrades operational quality and reporting accuracy. High-transaction systems require extra resources and strict validation systems to maintain data integrity.
Reduced flexibility: Multiple-table environments make schema modifications more difficult. This leads to slower development cycles and makes it harder for organizations to adapt to new business requirements.
Proper management is needed to implement denormalization to prevent data anomalies, integrity issues, and storage expenses. Organizations should implement denormalization based on identified performance requirements that match their system needs.
Use Cases
The benefits of denormalization become evident in particular use cases, but organizations should grasp its implications in different situations. Here are some of the key use cases:
Data warehousing & OLAP systems: Data warehousing and OLAP systems use denormalization methods to make complex queries and aggregations more efficient. Using denormalized schemas results in faster data retrieval because it eliminates the requirement for multiple table joins. This is essential for business intelligence applications and analytical workloads.
Low-latency applications: Denormalization benefits low-latency applications by shortening the time needed to retrieve and process data in critical environments such as financial trading platforms.
Read-heavy applications: Applications that perform more read operations than write operations can achieve better performance by using denormalization. Systems such as content management and reporting tools can achieve better read request performance by adding duplicate data.
Real-time analytics: Applications that need instant insights can benefit from denormalization by accessing pre-aggregated data. This reduces the query processing time, allowing for quick decision-making using up-to-date information.
FAQs
Is database denormalization always better for performance?
Denormalization in write-heavy systems creates data inconsistency problems because maintaining redundant data presents significant challenges. You must evaluate your application's read and write patterns before deciding on database denormalization.
Does denormalization replace normalization?
Denormalization functions as an additional step following normalization to improve performance issues. The normalization process structures data to eliminate duplication and maintain data integrity, but denormalization reintroduces data duplicates to improve read speed.
What are the risks of denormalization?
Implementing denormalization creates three main risks: data redundancy, higher storage requirements, and inconsistencies. Increased data redundancy creates potential anomalies when improperly managed, while expanded data size requires increased storage expenses.
Can I denormalize only part of my database?
Yes, database denormalization works by targeting specific database sections to optimize performance. The targeted implementation enables better read efficiency in specific areas without affecting database manageability or integrity.
How do I maintain data consistency in a denormalized database?
A denormalized database requires database triggers, constraints, and application logic to keep redundant data consistent during updates. Implementing these mechanisms maintains data synchronization across all data copies.
Related Resources
- What Is Database Denormalization?
- How It Works
- Comparison: Denormalization vs. Normalization
- Benefits and Challenges
- Use Cases
- FAQs
- Related Resources
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for Free