




Cómo Inkeep y Milvus crearon un asistente de IA basado en GAR para una interacción más inteligente
Como desarrolladores, buscar en la documentación técnica de diversas plataformas o servicios puede resultar tedioso. La documentación técnica típica contiene numerosas secciones y jerarquías que pueden resultar confusas o difíciles de navegar. En consecuencia, a menudo perdemos mucho tiempo buscando las respuestas que necesitamos. Para muchos desarrolladores, añadir un asistente de IA a la documentación técnica puede suponer un ahorro de tiempo, ya que podemos simplemente preguntar a la IA sobre nuestras dudas, y ella nos proporcionará respuestas o nos redirigirá a las páginas y artículos pertinentes.
En un reciente Unstructured Data Meetup organizado por Zilliz, Robert Tran, cofundador y director técnico de Inkeep, habló de cómo Inkeep y Zilliz crearon un asistente basado en IA para su sitio de documentación. Ahora podemos ver este asistente en acción en los sitios de documentación de Zilliz y Milvus.
En este artículo exploraremos los detalles técnicos presentados por Robert Tran. Así que, sin más preámbulos, empecemos con la motivación que hay detrás de la integración de un asistente de IA en las páginas de documentación técnica.
La motivación para integrar un asistente de IA en la documentación técnica
La documentación técnica es una fuente esencial de información que todas las plataformas deben proporcionar para ayudar a sus usuarios o desarrolladores. Debe ser intuitiva, completa y útil para guiar a desarrolladores de todos los niveles de experiencia en el uso de las características y funcionalidades disponibles en las plataformas.
Sin embargo, a medida que las plataformas introducen numerosas funciones nuevas, su documentación técnica puede volverse excesivamente compleja. Esta complejidad puede confundir a muchos desarrolladores a la hora de navegar por la documentación técnica de una plataforma. Los desarrolladores suelen estar bajo presión para obtener resultados rápidamente, y el tiempo dedicado a buscar información en la documentación técnica puede distraerles del trabajo real de codificación y desarrollo.
Muchas plataformas ofrecen funciones básicas de búsqueda en su documentación técnica para ayudar a los desarrolladores a encontrar rápidamente el contenido que necesitan, de forma similar a como buscamos en Google. Los usuarios pueden escribir palabras clave y la plataforma les ofrecerá una lista de páginas potencialmente relevantes para responder a sus preguntas. Sin embargo, estas funciones básicas de búsqueda a menudo no comprenden el contexto de la consulta del usuario, lo que conduce a resultados de búsqueda irrelevantes o incompletos.
Figura - Preguntas típicas de los desarrolladores sobre Milvus .png](https://assets.zilliz.com/Figure_Typical_questions_asked_by_developers_about_Milvus_e5f5974c96.png)
Figura: Preguntas típicas de los desarrolladores sobre Milvus_.
Como desarrolladores, sabemos que nuestras preguntas son a menudo más matizadas y a veces demasiado complejas para las funcionalidades básicas de búsqueda. Por ejemplo, al navegar por la documentación técnica de Zilliz, los desarrolladores suelen hacer preguntas muy técnicas como "¿Cómo incluir vectores dispersos junto a vectores densos durante el proceso de recuperación?" o "¿Cómo escalar el cluster dinámicamente?". Las funcionalidades básicas de búsqueda no suelen responder satisfactoriamente a preguntas tan matizadas y complejas.
La incorporación de un asistente de IA resuelve estos problemas. Un asistente de IA puede entender la intención de los desarrolladores y el significado semántico de sus consultas, lo que permite a los desarrolladores obtener la información que necesitan en cuestión de segundos. Los desarrolladores solo tienen que escribir su consulta y el asistente de IA les dará una respuesta o les redirigirá a la página relevante exacta en lugar de rebuscar entre un montón de contenido, lo que resulta tedioso y lleva mucho tiempo.
Además, los asistentes de IA suelen utilizar los últimos avances en procesamiento del lenguaje natural (NLP), como los modelos de lenguaje de gran tamaño (LLM, la búsqueda vectorial y la generación aumentada de recuperación (RAG). De hecho, el enfoque RAG está en el corazón de este asistente de IA, ya que le permite comprender los matices que subyacen a las preguntas de los usuarios y devolver respuestas precisas y pertinentes en cuestión de segundos.
En la próxima sección, hablaremos de los métodos que hay detrás de un asistente de IA.
El concepto de Generación Aumentada de Recuperación (RAG)
Retrieval Augmented Generation (RAG) es un método que combina técnicas avanzadas de PLN como la búsqueda vectorial y los LLM para generar respuestas precisas a las consultas de los usuarios.
Figura- Flujo de trabajo RAG.png](https://assets.zilliz.com/Figure_RAG_workflow_5bfbcccddf.png)
Figura: RAG workflow._
En pocas palabras, el flujo de trabajo de un método GAR es bastante sencillo. En primer lugar, los usuarios formulamos una consulta. A continuación, el método RAG busca los documentos pertinentes que puedan contener la respuesta a nuestra pregunta. A continuación, nuestra consulta y los documentos relevantes se combinan en una consulta coherente antes de ser enviados a un LLM. Por último, el LLM genera la respuesta a nuestra consulta utilizando los documentos pertinentes proporcionados.
Como podemos ver, el concepto principal del GAR es proporcionar a un LLM el contexto relevante para responder a nuestra consulta. Este enfoque tiene al menos dos ventajas: en primer lugar, reduce el riesgo de que el LLM alucine, es decir, que genere respuestas inexactas y falsas. En segundo lugar, la respuesta generada por el LLM estará más contextualizada y adaptada a nuestra consulta. Esto es especialmente útil cuando hacemos preguntas al LLM sobre el contenido de documentos internos.
Hay cuatro pasos de la GAR que debemos tener en cuenta a la hora de implementarla: ingesta, indexación, recuperación y generación.
Ingesta: consiste en recopilar y preprocesar los datos. También puede recopilarse la información pertinente y los metadatos de cada registro.
Indexación: implica el proceso de almacenamiento de datos con un método de indexación optimizado para su rápida recuperación. En este paso, los datos preprocesados se transforman en incrustaciones vectoriales utilizando un modelo de incrustación y, a continuación, se almacenan en una base de datos vectorial como Milvus con algoritmos de indexación avanzados como FLAT, FAISS o HNSW.
Recuperación: implica operaciones de búsqueda vectorial para cotejar la consulta del usuario con los datos almacenados. En este proceso, la consulta del usuario se transforma primero en una incrustación vectorial utilizando el mismo modelo de incrustación utilizado para transformar los datos almacenados. A continuación, se realiza una búsqueda de similitudes entre la consulta del usuario y los datos almacenados para encontrar la información más relevante en la base de datos vectorial.
Generación: implica la utilización de un LLM para producir la respuesta final. En primer lugar, la consulta del usuario y el contexto más relevante de la etapa de recuperación se combinan en un mensaje. A continuación, el LLM genera una respuesta a la consulta del usuario basándose en el contexto proporcionado en la solicitud.
Figura - Pasos del GAR..png](https://assets.zilliz.com/Figure_Steps_of_RAG_12c42b1f3d.png)
Figura: Pasos del GAR.
Hay varios factores que debemos tener en cuenta a la hora de aplicar cada uno de los pasos mencionados. Por ejemplo, durante la etapa de ingestión, tenemos que pensar en la fuente de los datos, el enfoque de limpieza de datos y el método de fragmentación. En la fase de indexación, hay que tener en cuenta el modelo de incrustación y la base de datos vectorial que queremos utilizar, así como los algoritmos de indexación apropiados para nuestro caso de uso.
En la siguiente sección, analizaremos las implementaciones detalladas de RAG realizadas por Inkeep y Zilliz para crear un asistente de IA para las páginas de documentación de Zilliz y Milvus.
Métodos utilizados por Inkeep y Zilliz para construir un asistente de IA
Para construir un asistente de IA, Inkeep y Zilliz utilizan una combinación de diferentes técnicas para la implementación RAG. Inkeep se encarga de las partes de ingestión y generación, mientras que Zilliz proporciona apoyo a Inkeep en los pasos de indexación y recuperación.
Como se ha mencionado en la sección anterior, el primer paso de la implementación del GAR es la ingesta. En este paso, Inkeep recopila datos textuales relacionados con Zilliz y Milvus de diversas fuentes, como [documentación] técnica (https://milvus.io/docs), soporte y preguntas frecuentes, y [repositorios de GitHub] (https://github.com/milvus-io/milvus). A continuación, estos datos textuales se limpian y trocean para garantizar que cada pieza de información no sea ni demasiado amplia ni demasiado granular.
También se recopilan los metadatos de cada registro fragmentado antes de pasar al siguiente paso. Estos metadatos incluyen:
Tipo de fuente: si los datos proceden de un repositorio de GitHub, documentación técnica, página de soporte y preguntas frecuentes, etc.
Tipo de registro: como la versión de los datos, si es texto o código. Si es código, también se indica el lenguaje de programación.
Referencias jerárquicas: incluyendo los hijos, padres y hermanos de cada punto de datos. Esto es importante ya que los datos se recogen de los sitios web de Zilliz.
URL, etiquetas, rutas: como las URL de las que se toman los datos. Estos metadatos son muy útiles para proporcionar enlaces a citas o fuentes en la respuesta generada por el LLM.
Fechas: como la fecha de publicación de cada dato.
Una vez que Inkeep ha recopilado los datos y sus metadatos, el siguiente paso es el método de indexación.
En el método de indexación, los datos preprocesados deben transformarse en incrustaciones vectoriales para permitir la búsqueda de similitudes en el paso de recuperación. Para transformar cada punto de datos en una incrustación vectorial, Inkeep y Zilliz utilizan tres métodos de incrustación diferentes: un modelo de incrustación dispersa tradicional, un modelo de incrustación dispersa basado en el aprendizaje profundo y un modelo de incrustación densa.
Figura - Incrustaciones dispersas y densas..png](https://assets.zilliz.com/Figure_Sparse_and_dense_embeddings_42cddb000f.png)
Figura: Incrustaciones dispersas y densas.
La incrustación dispersa es especialmente útil para procesos de búsqueda sencillos, basados en palabras clave y booleanos . Por tanto, los documentos relevantes obtenidos de una incrustación dispersa suelen contener las palabras clave de la consulta. En cambio, la incrustación densa es más útil para captar el matiz o el significado semántico de la consulta. Los documentos obtenidos a partir de una incrustación densa pueden contener o no las palabras clave de la consulta, pero su contenido será muy relevante.
Hay dos tipos diferentes de modelos que pueden utilizarse para transformar los datos en incrustación dispersa: modelos tradicionales/estadísticos y modelos basados en aprendizaje profundo. Para el asistente de IA, Inkeep y Zilliz utilizan BM25 como modelo tradicional y SPLADE/BGE-M3 como modelo basado en el aprendizaje profundo.
Para transformar los datos en incrustación densa, hay muchos modelos de aprendizaje profundo entre los que elegir, como los modelos de incrustación de OpenAI, Sentence-Transformers, VoyageAI, etc. Para el asistente de IA, Inkeep y Zilliz utilizan tres modelos de incrustación diferentes: MS-MARCO, MPNET y BGE-M3.
Una vez transformados todos los datos en sus representaciones de incrustación dispersa y densa, las incrustaciones se almacenan en una base de datos vectorial para permitir una rápida recuperación. Para construir el asistente de IA, Inkeep y Zilliz utilizan Milvus como base de datos vectorial. Ahora la pregunta es: ¿por qué necesitamos utilizar una combinación de incrustaciones dispersas y densas cuando podría bastar con elegir una de ellas?
Figura- Ilustración de la búsqueda híbrida..png](https://assets.zilliz.com/Figure_Hybrid_search_illustration_d231b60be2.png)
Figura: Ilustración de la búsqueda híbrida.
Utilizar tanto la incrustación dispersa como la densa proporciona flexibilidad en el paso de recuperación. Por ejemplo, si la consulta es breve (menos de 5 palabras), puede bastar con una incrustación dispersa. En cambio, si la consulta es larga, la incrustación densa nos dará, en la mayoría de los casos, un resultado de mayor calidad. Además, si utilizamos Milvus como base de datos vectorial, podemos aprovechar la potencia de hybrid search, es decir, la búsqueda de similitudes utilizando una combinación de incrustación dispersa y densa. También podemos realizar una búsqueda de similitud con incrustación densa o dispersa con filtrado de metadatos si lo deseamos.
Al implementar la búsqueda híbrida para encontrar el contenido más relevante para nuestra consulta, también debemos tener en cuenta el método reranking. Esto se debe a que obtendremos resultados de similitud a partir de dos métodos diferentes, y necesitamos un enfoque para combinar estos resultados. Para ello, Inkeep y Zilliz aplicaron dos métodos diferentes de reordenación: la puntuación ponderada y la fusión recíproca de rangos (RRF).
El concepto de puntuación ponderada es sencillo: asignamos un peso a cada método. Por ejemplo, podemos asignar un 60% de peso al resultado de similitud de la incrustación densa y un 40% al de la incrustación dispersa. Mientras tanto, en la RRF, las puntuaciones de los contextos se calculan sumando sus rangos recíprocos a través de dos métodos diferentes, a menudo con una pequeña constante adicional k para evitar la división por cero.
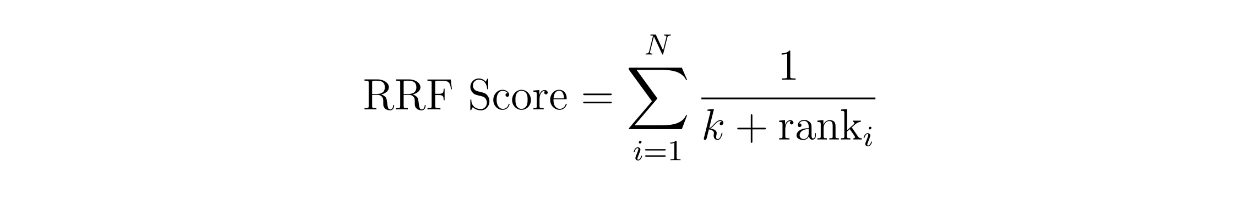 function rrf score.png
function rrf score.png
donde N es el número de métodos, que debería ser dos ya que estamos implementando una búsqueda híbrida entre una incrustación dispersa y una incrustación densa. La variable 'rank' es el rango de un contexto en el método i, y k es una constante.
Utilizando la ecuación RRF anterior, podemos calcular la puntuación RRF de cada contexto. El contexto con la puntuación RRF más alta será seleccionado como el contexto más relevante para una consulta.
Una vez obtenido el contexto relevante, la consulta original y el contexto más relevante se combinan en un mensaje coherente. Este mensaje se envía a un LLM para generar la respuesta final. Para el LLM, Inkeep utiliza modelos de OpenAI y Anthropic.
Demostración del asistente Milvus AI
En esta sección, vamos a proporcionar una breve introducción sobre cómo utilizar el asistente de IA construido por Inkeep y Zilliz. Si quieres seguirlo, puedes consultarlo en las páginas de documentación de Zilliz o Milvus. Para esta demostración, utilizaremos el asistente de IA de la página de documentación de Milvus.
Cuando abra la página de documentación de Milvus, verá el botón "Preguntar a la IA" en la parte inferior derecha de la pantalla. Haga clic en este botón para acceder al asistente AI.
 captura de pantalla 1.png
captura de pantalla 1.png
A continuación, aparecerá una pantalla emergente que le pedirá que pregunte cualquier cosa que desee encontrar en la documentación de Milvus. Opcionalmente, también puede realizar una búsqueda básica haciendo clic en la opción "Buscar" situada en la parte superior derecha de la pantalla emergente.
Digamos que queremos saber cómo transformar nuestros datos en incrustaciones vectoriales utilizando BGE-M3 con el Milvus Python SDK. Sólo tenemos que escribir nuestra pregunta y el asistente de IA nos dará una respuesta.
 captura de pantalla 2.png
captura de pantalla 2.png
Además de proporcionarnos una respuesta, el asistente de IA también nos dará citas o páginas relevantes donde podemos encontrar más información relacionada con la respuesta generada.
 captura de pantalla 3.png
captura de pantalla 3.png
Conclusión
La integración de un asistente de IA en la documentación técnica, tal y como lo construyeron Inkeep y Zilliz, demuestra cómo las soluciones avanzadas de IA pueden mejorar la productividad de los desarrolladores y la experiencia de los usuarios. RAG es el componente central de este asistente de IA, ya que este método ayuda al LLM a proporcionar respuestas más precisas y contextualizadas a consultas matizadas y complejas.
RAG consta de cuatro pasos clave: ingesta, indexación, recuperación y generación. Las bases de datos vectoriales como Milvus son un componente clave en el proceso de RAG, ya que realizan los pasos de indexación y recuperación. Los métodos utilizados en cada paso deben considerarse cuidadosamente en función del caso de uso específico. En este artículo, también hemos visto un ejemplo de cómo Inkeep y Zilliz aplicaron diversas estrategias en cada paso de la RAG para construir un sofisticado asistente de IA.
Para saber más sobre cómo Milvus e Inkeep construyeron este asistente de IA, echa un vistazo a la repetición de la charla de Robert en YouTube.
Más información
Generative AI Resource Hub | Zilliz](https://zilliz.com/learn/generative-ai)
Modelos de IA de alto rendimiento para tus aplicaciones de GenAI | Zilliz](https://zilliz.com/ai-models)
Construir aplicaciones de IA con Milvus: tutoriales y cuadernos](https://zilliz.com/learn/milvus-notebooks)
Únase a la comunidad Milvus de desarrolladores de IA](https://zilliz.com/community)
¿Qué es RAG?](https://zilliz.com/learn/Retrieval-Augmented-Generation)
Sigue leyendo

Zilliz Cloud On-Demand Compute: Pay Only for What You Use
The customer case behind Zilliz Cloud On-Demand: how a $10K vector search bill came down to under $500, and the engineering changes that made it possible.

Zilliz Cloud Now Available in Azure North Europe: Bringing AI-Powered Vector Search Closer to European Customers
The addition of the Azure North Europe (Ireland) region further expands our global footprint to better serve our European customers.

Zilliz Cloud Delivers Better Performance and Lower Costs with Arm Neoverse-based AWS Graviton
Zilliz Cloud adopts Arm-based AWS Graviton3 CPUs to cut costs, speed up AI vector search, and power billion-scale RAG and semantic search workloads.