




Massive Text Embedding Benchmark (MTEB)

Massive Text Embedding Benchmark (MTEB)
Text-Embeddings werden oft nur mit einer kleinen Anzahl von Datensätzen aus nur einer Aufgabe getestet, was nicht zeigt, wie gut sie für andere Aufgaben funktionieren. Es ist nicht klar, ob die besten Embeddings für semantische textuelle Ähnlichkeit (STS) bei Aufgaben wie Clustering oder Reranking genauso gut funktionieren. Das macht es schwierig, Fortschritte in diesem Bereich zu erkennen, da neue Modelle und Embeddings häufig evaluiert und ständig vorgeschlagen werden, ohne einheitlich getestet zu werden.
Um dieses Problem anzugehen, haben Forschende den Massive Text Embedding Benchmark (MTEB) entwickelt. MTEB umfasst 8 Embedding-Aufgaben über 58 Datensätze in 112 Sprachen hinweg. Die Forschenden testeten 8 Embedding-Aufgaben mit 33 Modellen auf MTEB und machten ihn damit zum bisher vollständigsten Benchmark für Text-Embeddings.
Sie stellten fest, dass keine einzelne Embedding-Methode für alle Aufgaben die beste ist. Das deutet darauf hin, dass eine universelle Text-Embedding-Methode, die für alle Embedding-Aufgaben am besten funktioniert, noch nicht entwickelt wurde, selbst wenn sie hochskaliert wird. Dies unterstreicht auch die Bedeutung, die nötige Sorgfalt walten zu lassen, um die Embedding-Modelle auszuwählen, die am besten zu Ihren Anforderungen passen.
MTEB enthält Open-Source-Code, ein öffentliches Leaderboard und eine unterhaltsame MTEB Arena, in der man über Dinge abstimmen kann, etwa welche Modelle das bessere Dokument abrufen, besseres Clustering durchführen usw., beides auf der Hugging Face-Website. Dieser Benchmark wird der Community helfen, neue Methoden konsistent zu testen und Verbesserungen in der Text-Embedding-Technologie nachzuverfolgen.
Hintergrund und Motivation
Text-Embeddings sind zu einem zentralen Bestandteil vieler Aufgaben der Verarbeitung natürlicher Sprache (NLP) geworden. Diese Embeddings wandeln Wörter, Sätze oder Dokumente in numerische Darstellungen um, die ihre Bedeutung erfassen. Sie werden in verschiedenen Anwendungen wie maschineller Übersetzung, Named-Entity Recognition, Fragebeantwortung, Sentimentanalyse und Zusammenfassung verwendet.
Im Laufe der Jahre haben Forschende viele Datensätze und Benchmarks erstellt, um diese Embeddings zu testen. Zu den bekannten gehören SemEval, GLUE, SuperGLUE, Big-Bench, WordSim353 und SimLex-999. Diese konzentrieren sich typischerweise auf die Evaluierung standardmäßiger und kontextueller Wort-Embeddings.
Es gibt jedoch noch einige Lücken bei der Evaluierung von Text-Embeddings:
Nur wenige Benchmarks decken sowohl Wort- als auch Satz-Embeddings ab.
Viele Evaluierungen konzentrieren sich auf spezifische NLP-Aufgaben, nicht darauf, wie gut die Embeddings die Gesamtbedeutung von Text erfassen.
Bestehende Benchmarks berücksichtigen oft nicht, wie Embeddings in realen Anwendungen genutzt werden könnten.
Es besteht Bedarf an einem umfassenden Benchmark, der eine breite Palette von Aufgaben zum Textverständnis evaluieren kann. Dieser Benchmark sollte sowohl für NLP-Forschende als auch für Menschen nützlich sein, die an praktischen Anwendungen arbeiten. Der Massive Text Embedding Benchmark (MTEB) zielt darauf ab, diese Lücke zu schließen.
Text-Embeddings
Ein Text-Embedding ist eine Möglichkeit, Text als Liste von Zahlen darzustellen. Diese Zahlen können ein einzelnes Wort, einen Satz oder sogar ein ganzes Dokument repräsentieren. Die Liste ist in der Regel Hunderte von Zahlen lang.
Texteinbettungen werden in vielen NLP-Aufgaben verwendet. Für Wörter werden sie für Dinge wie Rechtschreibprüfung und das Finden von Wortbeziehungen genutzt. Für längere Texte werden sie in Aufgaben eingesetzt, wie etwa die Stimmung eines Textstücks zu bestimmen oder neuen Text zu generieren.
Es gibt viele verschiedene Möglichkeiten, Texteinbettungen zu erstellen. Einige beliebte Methoden sind:
Sprachmodellbasierte Methoden wie ULMFit, GPT, BERT und PEGASUS
Methoden, die auf verschiedenen NLP-Aufgaben trainiert wurden, wie ELMo
Wortbasierte Methoden wie word2vec und GloVe, die häufig in der Computer-Vision-Forschung verwendet werden
Forscher haben viele verschiedene Einbettungen erstellt - es gibt mindestens 165 zum Vergleichen. Sie haben außerdem 15 verschiedene Werkzeuge (wie Entscheidungsbäume und Random Forests) entwickelt, um die Stärken und Schwächen dieser Einbettungen besser zu verstehen.
Es gibt jedoch keine standardisierte Methode, um all diese verschiedenen Einbettungen zu vergleichen. Dies ist ein Problem, das der Massive Text Embedding Benchmark (MTEB) zu lösen versucht.
Design und Implementierung des Massive Text Embedding Benchmark
MTEB wurde mit mehreren wichtigen Zielen im Hinterkopf entwickelt:
Diversität: MTEB testet Einbettungsmodelle anhand vieler verschiedener Aufgaben. Es umfasst 8 verschiedene Arten von Aufgaben, mit bis zu 15 Datensätzen für jede. Von den insgesamt 58 Datensätzen funktionieren 10 mit mehreren Sprachen und decken insgesamt 112 Sprachen ab. Der Benchmark testet sowohl kurze Texte (auf Satzebene) als auch lange Texte (auf Absatzebene), um zu sehen, wie Modelle bei unterschiedlichen Textlängen abschneiden.
Einfachheit: MTEB ist einfach zu verwenden. Jedes Modell, das eine Liste von Texten nehmen und eine Liste von Zahlendarstellungen (Vektoren) erzeugen kann, kann getestet werden. Das bedeutet, dass viele verschiedene Arten von Modellen verglichen werden können.
Erweiterbarkeit: Es ist einfach, neue Datensätze zu MTEB hinzuzufügen. Für bestehende Aufgaben müssen Sie nur eine Datei hinzufügen, die die Aufgabe beschreibt und darauf verweist, wo die Daten auf Hugging Face gespeichert sind. Das Hinzufügen neuer Aufgabentypen erfordert etwas mehr Arbeit, aber MTEB begrüßt Beiträge aus der Community, um weiter zu wachsen.
Reproduzierbarkeit: MTEB macht es einfach, Experimente zu wiederholen. Es verfolgt verschiedene Versionen von Datensätzen und Software. Die Ergebnisse im MTEB-Paper sind als JSON-Dateien verfügbar, sodass jeder sie überprüfen oder verwenden kann.
Diese Funktionen machen MTEB zu einem umfassenden und flexiblen Werkzeug zur Bewertung von Texteinbettungsmodellen über Aufgaben hinweg, die insgesamt ein breites Spektrum an Aufgaben und Sprachen abdecken.
Aufgaben und Bewertung im Massive Text Embedding Benchmark
Massive Text Embedding Benchmark umfasst 8 verschiedene Arten von Aufgaben, um Einbettungsmodelle zu testen. Hier ist eine einfache Aufschlüsselung jeder Aufgabe:
Bitext Mining: Passende Sätze in zwei verschiedenen Sprachen finden. Die wichtigste Kennzahl ist der F1-Score.
Klassifikation: Einbettungen verwenden, um Texte in Kategorien einzuordnen. Die wichtigste Kennzahl ist die Genauigkeit.
Clustering: Ähnliche Texte gruppieren. Die wichtigste Kennzahl ist das V-Maß.
Paarklassifikation: Entscheiden, ob zwei Texte ähnlich sind oder nicht. Die wichtigste Kennzahl ist die durchschnittliche Präzision.
Reranking: Eine Liste von Texten danach ordnen, wie gut sie zu einer Suchanfrage passen. Die wichtigste Kennzahl ist MAP (Mean Average Precision).
Retrieval: Relevante Dokumente für eine gegebene Suchanfrage finden. Die wichtigste Kennzahl ist nDCG@10.
Semantische Textähnlichkeit (STS): Messen, wie ähnlich zwei Sätze sind. Die wichtigste Kennzahl ist die Spearman-Korrelation.
Zusammenfassung: Maschinell erzeugte Zusammenfassungen anhand von von Menschen geschriebenen bewerten. Die wichtigste Kennzahl ist ebenfalls die Spearman-Korrelation.
Für jede Aufgabe verwendet MTEB das Embedding-Modell, um Texte in Vektoreinbettungen umzuwandeln. Anschließend nutzt es Methoden wie Kosinus-Ähnlichkeit oder logistische Regression, um die Aufgabe auszuführen und Punktzahlen zu berechnen.
MTEB umfasst viele Datensätze für jede Aufgabe, die verschiedene Sprachen und Textlängen abdecken. Dies hilft dabei zu testen, wie gut Embedding-Modelle in verschiedenen Situationen funktionieren.
Durch die Verwendung dieser vielfältigen Aufgaben und Datensätze bietet der Massive Text Embedding Benchmark eine umfassende Möglichkeit, verschiedene Text-Embedding-Modelle zu bewerten und zu vergleichen.
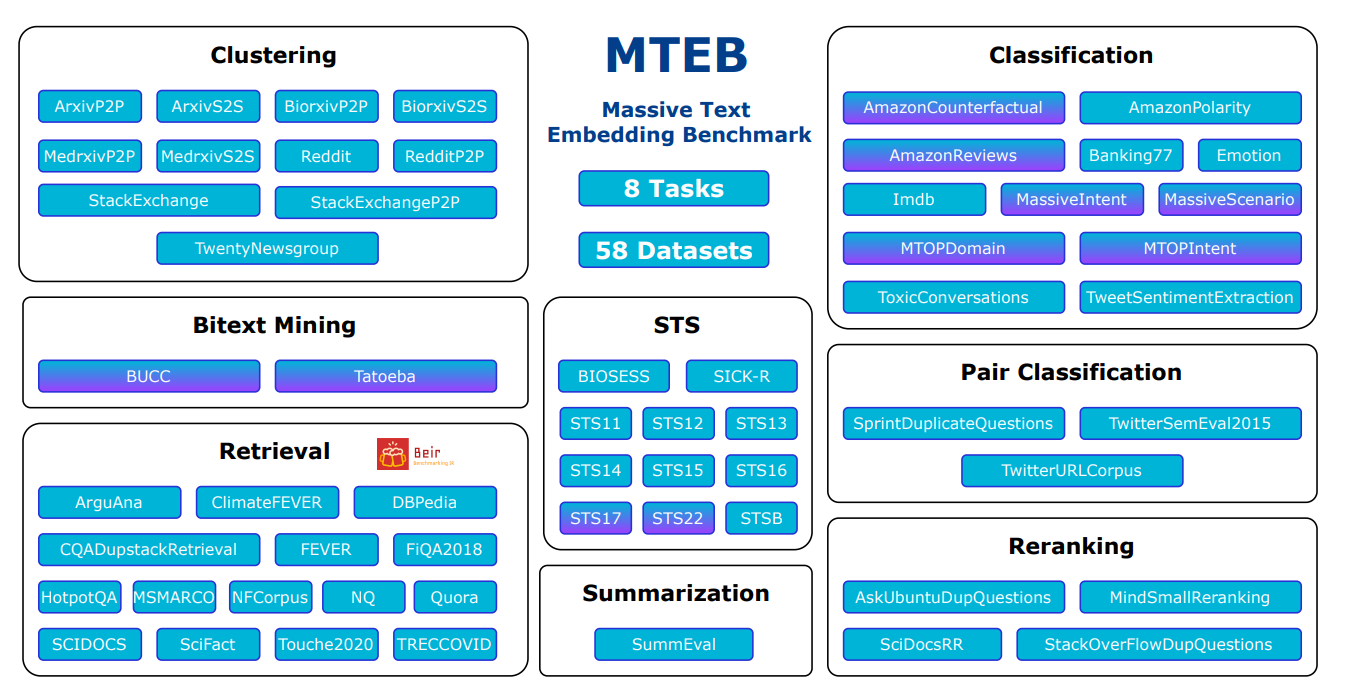 Überblick über Aufgaben und Datensätze in MTEB
Überblick über Aufgaben und Datensätze in MTEB
Quelle: MTEB: Massive Text Embedding Benchmark
Datensätze im Massive Text Embedding Benchmark
Der Massive Text Embedding Benchmark verwendet viele verschiedene Datensätze, um bestimmte Text-Embedding-Methoden und -Modelle zu testen. Diese Datensätze werden basierend auf der Länge der verglichenen Texte in drei Haupttypen gruppiert:
Satz zu Satz (S2S): Dies ist der Fall, wenn ein Satz mit einem anderen verglichen wird. Zum Beispiel besteht das Ziel bei Aufgaben zur semantischen Textähnlichkeit darin, herauszufinden, wie ähnlich zwei Sätze sind.
Absatz zu Absatz (P2P): Dabei werden längere Textstücke verglichen. MTEB legt keine Grenze dafür fest, wie lang diese sein dürfen, und überlässt es den Modellen, bei Bedarf längere Texte zu verarbeiten. Einige Aufgaben, wie Clustering, werden sowohl als S2S (Vergleich nur von Titeln) als auch als P2P (Vergleich von Titeln und Inhalt) durchgeführt.
Satz zu Absatz (S2P): Dies wird bei einigen Retrieval-Aufgaben verwendet, bei denen eine kurze Suchanfrage (Satz) mit längeren Dokumenten (Absätzen) verglichen wird.
MTEB umfasst 56 verschiedene Datensätze. Einige dieser Datensätze ähneln einander:
Einige verwenden dieselben zugrunde liegenden Textdaten (wie ClimateFEVER und FEVER).
Datensätze für ähnliche Aufgaben (wie verschiedene Versionen von CQADupstack oder STS) neigen dazu, einander ähnlich zu sein.
Die S2S- und P2P-Versionen desselben Datensatzes sind oft ähnlich.
Datensätze zu ähnlichen Themen (wie wissenschaftliche Arbeiten) neigen dazu, einander ähnlich zu sein, selbst wenn sie für unterschiedliche Aufgaben bestimmt sind.
Durch die Verwendung einer so großen Bandbreite an Datensätzen kann MTEB testen, wie gut Embedding-Modelle mit verschiedenen Textarten und unterschiedlichen Aufgaben funktionieren. Dies hilft dabei, ein vollständigeres Bild der Stärken und Schwächen jedes Modells zu vermitteln.
Modelle im ersten Benchmarking des Massive Text Embedding Benchmark
Für die erste Testrunde mit MTEB betrachteten die Forscher Modelle, die behaupten, die besten zu sein, sowie solche, die auf dem Hugging Face Hub beliebt sind. Das bedeutete, dass sie viele Transformer-Modelle testeten. Sie gruppierten die Modelle in drei Typen, um Menschen dabei zu helfen, das beste Modell für ihre Bedürfnisse auszuwählen:
Schnellste Modelle: Modelle wie Glove sind sehr schnell, verstehen Kontext aber nicht gut. Das bedeutet, dass sie insgesamt bei MTEB nicht so hohe Punktzahlen erzielen.
Ausgewogene Modelle: Modelle wie all-mpnet-base-v2 oder all-MiniLM-L6-v2 sind etwas langsamer als die schnellsten, schneiden aber deutlich besser ab. Sie bieten eine gute Mischung aus Geschwindigkeit und Qualität.
Leistungsstärkste Modelle: Große Modelle mit Milliarden von Parametern, wie ST5-XXL, GTR-XXL oder SGPT-5.8B-msmarco, schneiden bei MTEB am besten ab. Sie können jedoch langsamer sein und mehr Speicher benötigen. Zum Beispiel erstellt SGPT-5.8B-msmarco Einbettungen mit 4096 Zahlen, was mehr Speicherplatz beansprucht.
Es ist wichtig zu beachten, dass die Leistung eines Modells je nach konkreter Aufgabe und Datensatz stark variieren kann. Die Forscher empfehlen, das MTEB-Leaderboard zu prüfen, um zu sehen, welches Modell für eine einzelne Aufgabe und Ihre spezifischen Bedürfnisse am besten geeignet sein könnte.
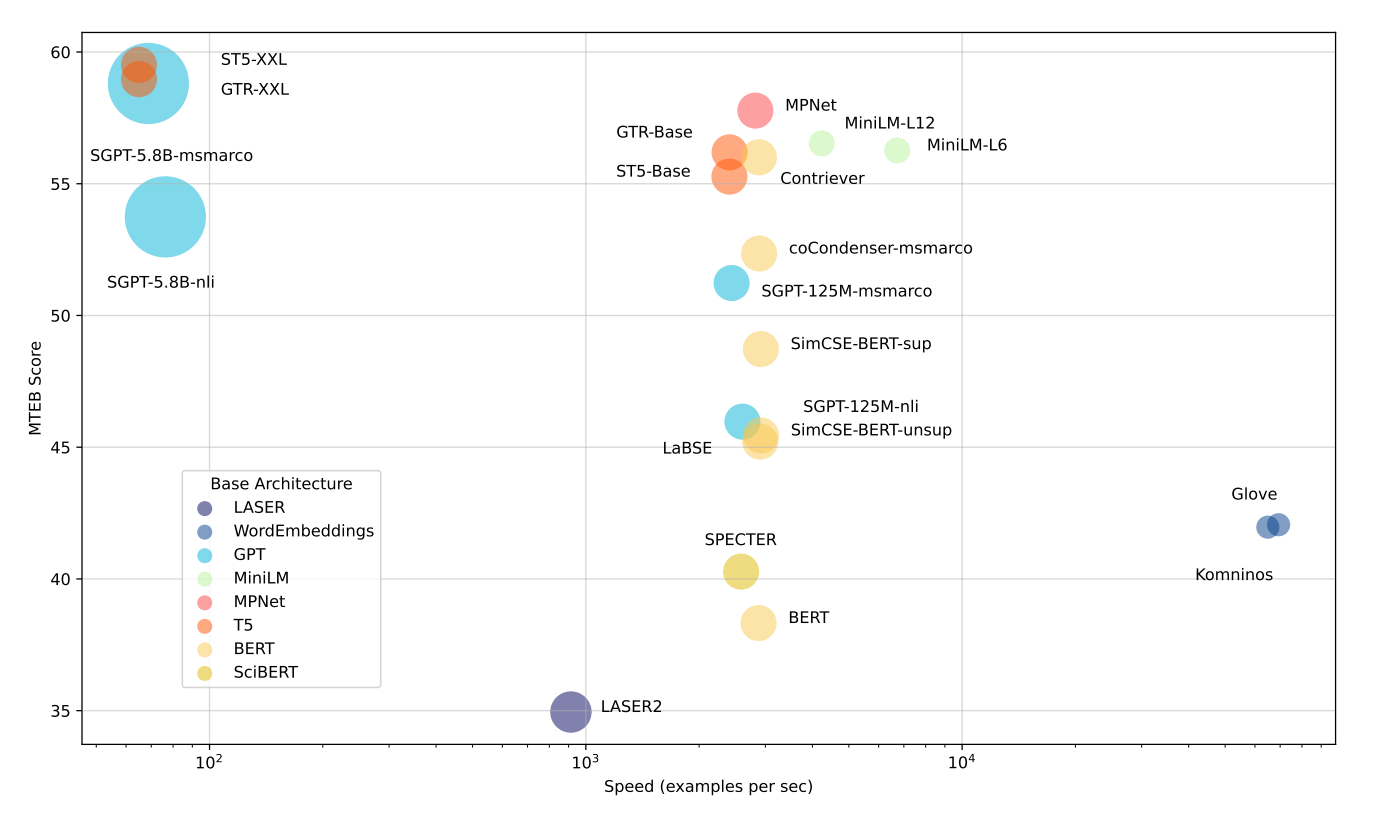 Ergebnisse der Benchmarks des ersten Tests
Ergebnisse der Benchmarks des ersten Tests
Quelle: MTEB: Massive Text Embedding Benchmark
Dieser Testansatz vermittelt ein klares Bild der Kompromisse zwischen Geschwindigkeit und Leistung bei verschiedenen Embedding-Modellen und hilft Nutzern, fundierte Entscheidungen auf Grundlage ihrer spezifischen Anforderungen zu treffen. Wenn du es selbst ausprobieren möchtest, gibt es einen großartigen Blog auf Huggigng Face, der dich durch das Benchmarking jedes Modells führt, das Vektor-Embeddings erzeugt.
Wann der Massive Text Embedding Benchmark verwendet werden sollte
MTEB ist ein Tool zum Testen, wie gut Text-Embedding-Modelle bei vielen verschiedenen Aufgaben funktionieren. Es ist in mehreren Situationen nützlich:
Dein Modell testen: Wenn du ein neues Embedding-Modell erstellt hast, kannst du MTEB verwenden, um zu sehen, wie es im Vergleich zu anderen Modellen abschneidet. Du kannst deine Ergebnisse zur öffentlichen Bestenliste hinzufügen, was dir hilft zu sehen, wie dein Modell im Vergleich zu anderen dasteht.
Das richtige Modell auswählen: Verschiedene Modelle funktionieren für unterschiedliche Aufgaben besser. Die Bestenliste von MTEB zeigt, wie Modelle bei verschiedenen Aufgaben abschneiden, und hilft dir, das beste Modell für deine spezifischen Bedürfnisse auszuwählen.
Zur Verbesserung von MTEB beitragen: MTEB ist Open Source und steht daher jedem offen, der beitragen möchte. Wenn du eine neue Aufgabe, einen neuen Datensatz, eine Methode zur Leistungsmessung oder ein Modell erstellt hast, kannst du es zu MTEB hinzufügen. Das hilft, den Benchmark noch besser zu machen.
Forschung: Wenn du Text-Embeddings untersuchst, bietet dir MTEB eine gründliche Möglichkeit, Modelle zu testen. Es kann dir zeigen, was die derzeit besten Modelle leisten können und wo es Verbesserungspotenzial gibt.
Indem MTEB eine standardisierte Möglichkeit bietet, Modelle bei vielen Aufgaben zu testen, hilft es Forschern und Entwicklern, Text-Embedding-Technologie zu verstehen und zu verbessern. Es ist ein wertvolles Tool für alle, die mit Text-Embeddings arbeiten oder sie untersuchen.
So verwendest du die Bestenliste des Massive Text Embedding Benchmark
Zuallererst: Lass dich nicht von MTEB-Scores in die Irre führen!
MTEB ist ein nützliches Tool, aber es ist wichtig, seine Grenzen zu verstehen. Obwohl es Scores anzeigt, sagt es dir nicht, ob die Unterschiede zwischen den Scores aussagekräftig sind. Viele Top-Modelle haben sehr ähnliche Durchschnittswerte, die aus vielen verschiedenen Aufgaben stammen, aber es gibt keine Informationen darüber, wie stark diese Scores variieren. Das Spitzenmodell könnte besser aussehen, aber der Unterschied könnte unwichtig sein. Nutzer können die Rohergebnisse abrufen, um dies selbst zu überprüfen. Einige Forscher haben festgestellt, dass mehrere Top-Modelle in bestimmten Sprach-Benchmarks statistisch gesehen tatsächlich gleich gut sind. Anstatt nur auf Durchschnittswerte zu schauen, ist es besser, sich darauf zu konzentrieren, wie Modelle bei Aufgaben abschneiden, die dem beabsichtigten Anwendungsfall ähneln. Dies kann mehr Einblick darin geben, wie ein Modell für eine bestimmte Anwendung funktionieren wird, als der Gesamtscore. Es ist nicht notwendig, die Datensätze im Detail zu untersuchen, aber es ist hilfreich zu wissen, welche Art von Text sie enthalten. Diese Informationen sind normalerweise in der Beschreibung des Datensatzes und durch einen kurzen Blick auf einige Beispiele verfügbar. Der Massive Text Embedding Benchmark ist ein hilfreiches Tool, aber er ist nicht perfekt. Es ist wichtig, kritisch über die Ergebnisse nachzudenken und darüber, wie sie auf spezifische Bedürfnisse anwendbar sind. Anstatt einfach das Modell mit dem höchsten Gesamtscore auszuwählen, ist es besser, genauer hinzusehen, um das beste Modell für die jeweilige Aufgabe zu finden.
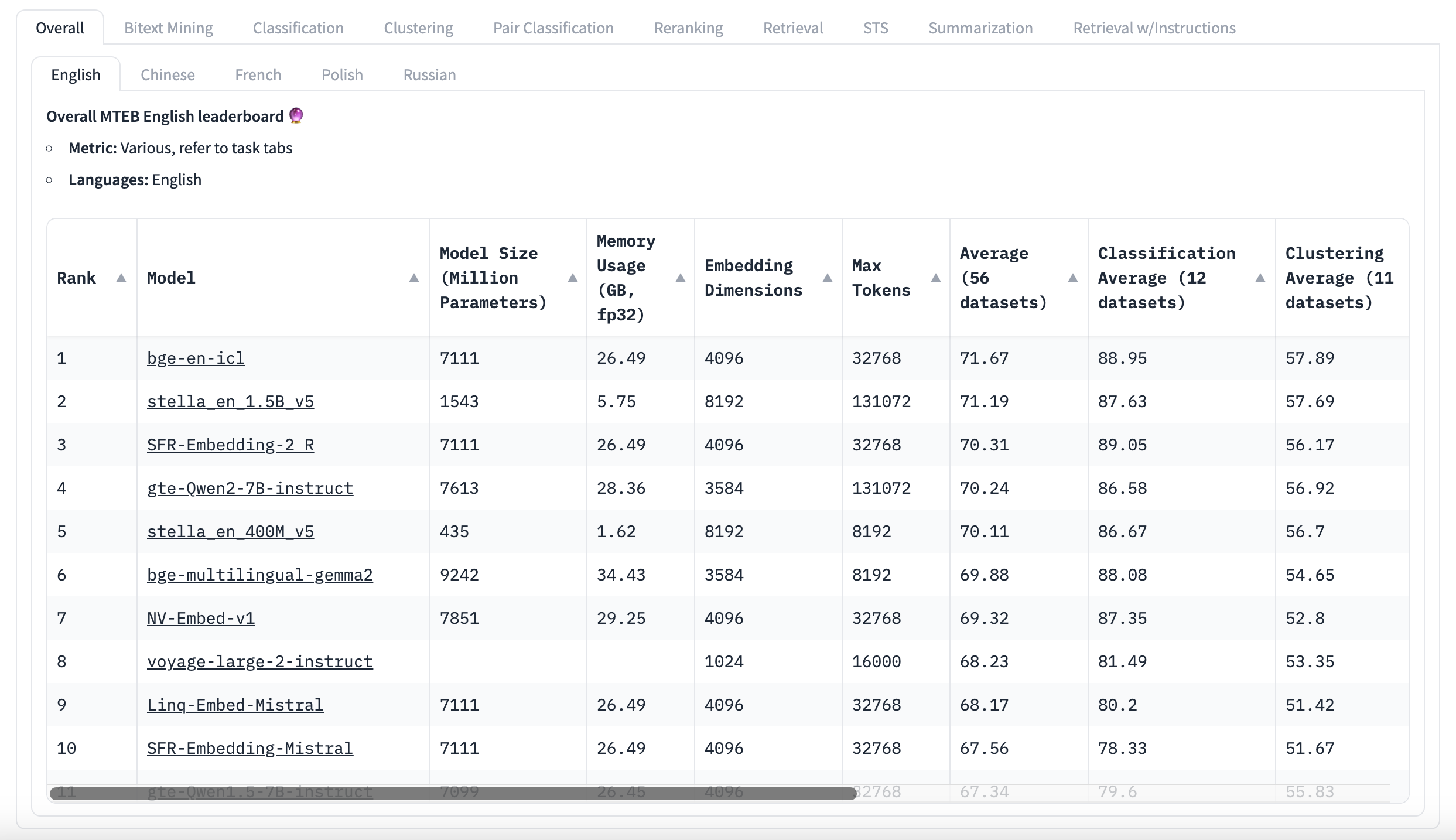 MTEB-Bestenliste Englisch
MTEB-Bestenliste Englisch
Denke daran, die Anforderungen deiner Anwendung zu berücksichtigen
Es gibt kein Einheitsmodell für jede Aufgabe. Genau deshalb gibt es den Massive Text Embedding Benchmark – um dir zu helfen, das richtige Modell für deine spezifischen Bedürfnisse auszuwählen. Wenn du dir die Bestenliste des Massive Text Embedding Benchmark ansiehst, ist es wichtig darüber nachzudenken, was deine Anwendung erfordert. Hier sind einige Dinge, die du berücksichtigen solltest:
Sprache: Unterstützt das Modell die Sprache, mit der du arbeitest?
Fachspezifisches Vokabular: Wenn du mit Finanz- oder Rechtstexten arbeitest, benötigst du ein Modell, das fachspezifische Begriffe versteht.
Modellgröße: Überlege, wo du das Modell ausführen wirst. Muss es auf einen Laptop passen?
Speichernutzung: Wie viel Computerspeicher kannst du für das Modell entbehren?
Maximale Eingabelänge: Wie lang sind die Texte, mit denen du arbeiten wirst?
Sobald du weißt, was für deine Aufgabe wichtig ist, kannst du verschiedene Modelle auf dem MTEB-Leaderboard anhand dieser Merkmale sortieren. Das erleichtert es, ein Modell zu finden, das nicht nur gut abschneidet, sondern auch zu deinen praktischen Anforderungen passt.
Indem du sowohl Leistung als auch praktische Bedürfnisse berücksichtigst, kannst du ein Modell auswählen, das für deine spezifische Situation am besten funktioniert.
Die Zilliz AI Model-Ressource
Nachdem du nun dein Text-Embedding-Modell aus dem Massive Text Embedding Benchmark ausgewählt hast, setzen wir es ein, um Text-Embeddings zu erstellen, die in Open-Source-Milvus oder Zilliz Cloud gespeichert und abgerufen werden können. Auf der Zilliz-Website findest du die Seite AI Models, die einige der beliebteren multimodalen und Text-Embedding-Modelle auflistet.
 Zilliz AI Model-Seite
Zilliz AI Model-Seite
Sobald du auf dieser Seite ein Modell auswählst, siehst du einige detaillierte Anleitungen dazu, wie du die Vektor-Embeddings mit den verschiedenen SDKs, PyMilvus und mehr erstellen kannst.
Fazit
Der Massive Text Embedding Benchmark (MTEB) ist ein bedeutender Fortschritt bei der Bewertung von Text-Embedding-Modellen. Er adressiert die Einschränkungen früherer Benchmarks, indem er eine breite Palette von Aufgaben, Sprachen und Textlängen abdeckt. Das Design von MTEB konzentriert sich auf Vielfalt, Einfachheit, Erweiterbarkeit und Reproduzierbarkeit, wodurch er zu einem wertvollen Werkzeug sowohl für Forschende als auch für Praktiker im Bereich der Verarbeitung natürlicher Sprache wird.
Der umfassendste Benchmark-Ansatz von MTEB, bei dem Modelle über 8 verschiedene Aufgaben und 58 Datensätze hinweg getestet werden, liefert ein vollständigeres Bild der Fähigkeiten eines Modells als frühere Benchmarks. Er zeigt, dass keine einzelne Embedding-Methode bei allen Aufgaben herausragt, und unterstreicht damit die Bedeutung der Wahl des richtigen Modells für spezifische Anwendungen.
Bei der Verwendung von MTEB ist es entscheidend, über die Gesamtpunktzahlen hinauszublicken und die spezifischen Bedürfnisse deiner Anwendung zu berücksichtigen. Faktoren wie Sprachunterstützung, fachspezifisches Vokabular, Modellgröße, Speichernutzung und maximale Eingabelänge sollten alle eine Rolle im Entscheidungsprozess spielen.
Obwohl MTEB ein leistungsstarkes Werkzeug ist, ist es wichtig, es kritisch zu verwenden. Die Unterschiede in den Punktzahlen zwischen Top-Modellen sind möglicherweise nicht immer statistisch signifikant, und die Leistung kann je nach spezifischer Aufgabe und Datensatz stark variieren.
Als Open-Source-Projekt begrüßt MTEB Beiträge aus der Community, wodurch es wachsen und sich an die sich wandelnden Bedürfnisse des Fachgebiets anpassen kann. Dieser kollaborative Ansatz stellt sicher, dass MTEB weiterhin eine relevante und wertvolle Ressource für die Bewertung und Verbesserung von Text-Embedding-Technologie bleibt.
Indem MTEB eine standardisierte Möglichkeit bietet, Text-Embedding-Modelle über eine breite Palette von Aufgaben und Sprachen hinweg zu bewerten, trägt es dazu bei, den Fortschritt in diesem Bereich voranzutreiben, was letztlich zu besseren und vielseitigeren Text-Embedding-Modellen für verschiedene Anwendungen führt.
Referenzen
Muennighoff, Niklas and Tazi, Nouamane and Magne, Lo{\"\i}c and Reimers, Nils. "MTEB: Massive Text Embedding Benchmark" arXiv 2022
Shitao Xiao, Zheng Liu, Peitian Zhang, Niklas Muennighoff. "C-Pack: Packaged Resources To Advance General Chinese Embedding" arXiv 2023
Michael Günther, Jackmin Ong, Isabelle Mohr, Alaeddine Abdessalem, Tanguy Abel, Mohammad Kalim Akram, Susana Guzman, Georgios Mastrapas, Saba Sturua, Bo Wang, Maximilian Werk, Nan Wang, Han Xiao. "Jina Embeddings 2: 8192-Token General-Purpose Text Embeddings for Long Documents" arXiv 2023
Silvan Wehrli, Bert Arnrich, Christopher Irrgang. "German Text Embedding Clustering Benchmark" arXiv 2024
Orion Weller, Benjamin Chang, Sean MacAvaney, Kyle Lo, Arman Cohan, Benjamin Van Durme, Dawn Lawrie, Luca Soldaini. "FollowIR: Evaluating and Teaching Information Retrieval Models to Follow Instructions" arXiv 2024
Dawei Zhu, Liang Wang, Nan Yang, Yifan Song, Wenhao Wu, Furu Wei, Sujian Li. "LongEmbed: Extending Embedding Models for Long Context Retrieval" arXiv 2024
Kenneth Enevoldsen, Márton Kardos, Niklas Muennighoff, Kristoffer Laigaard Nielbo. "The Scandinavian Embedding Benchmarks: Comprehensive Assessment of Multilingual and Monolingual Text Embedding" arXiv 2024
- Hintergrund und Motivation
- Text-Embeddings
- Design und Implementierung des Massive Text Embedding Benchmark
- Wann der Massive Text Embedding Benchmark verwendet werden sollte
- So verwendest du die Bestenliste des Massive Text Embedding Benchmark
- Die Zilliz AI Model-Ressource
- Fazit
- Referenzen
Inhalte
Kostenlos starten, einfach skalieren
Testen Sie die vollständig verwaltete Vektordatenbank, die für Ihre GenAI-Anwendungen entwickelt wurde.
Zilliz Cloud kostenlos ausprobieren