




Data Mining: Von Rohdaten zu wertvollen Einsichten

Data Mining: Von Rohdaten zu wertvollen Einsichten
Was ist Data Mining?
Data Mining ist eine Technik zur Entdeckung von Mustern, Trends und wertvollen Erkenntnissen aus großen Datenmengen. Es hilft Unternehmen und Forschern, bessere Entscheidungen zu treffen, indem es verborgene Zusammenhänge aufdeckt, die auf den ersten Blick nicht ersichtlich sind. Durch den Einsatz von Techniken wie [Klassifizierung] (https://zilliz.com/glossary/classification), [Clustering] (https://zilliz.com/ai-faq/how-does-clustering-improve-vector-search) und Assoziationsregel-Mining verwandelt Data Mining Rohdaten in wertvolle Erkenntnisse. Ob es um die Vorhersage von Kundenverhalten, die Aufdeckung von Betrug oder die Verbesserung von Suchergebnissen geht, Data Mining spielt eine Schlüsselrolle bei der Gestaltung moderner Technologien.
Wie funktioniert Data Mining?
Data Mining analysiert große Datensätze, um versteckte Muster, Beziehungen und Trends zu finden, die für die Entscheidungsfindung genutzt werden können. Dabei werden statistische Methoden, Algorithmen für maschinelles Lernen und Datenbankmanagementtechniken eingesetzt, um Rohdaten zu verwertbaren Erkenntnissen zu verarbeiten. Der Prozess folgt einer Reihe von Schritten, um Daten zu bereinigen, zu organisieren und nützliche Informationen aus ihnen zu extrahieren. Um dies besser zu verstehen, denken Sie an eine E-Commerce-Plattform, die vorhersagen möchte, welche Kunden aufgrund ihres Surfverhaltens wahrscheinlich einen Kauf tätigen werden.
Schritte im Data-Mining-Prozess
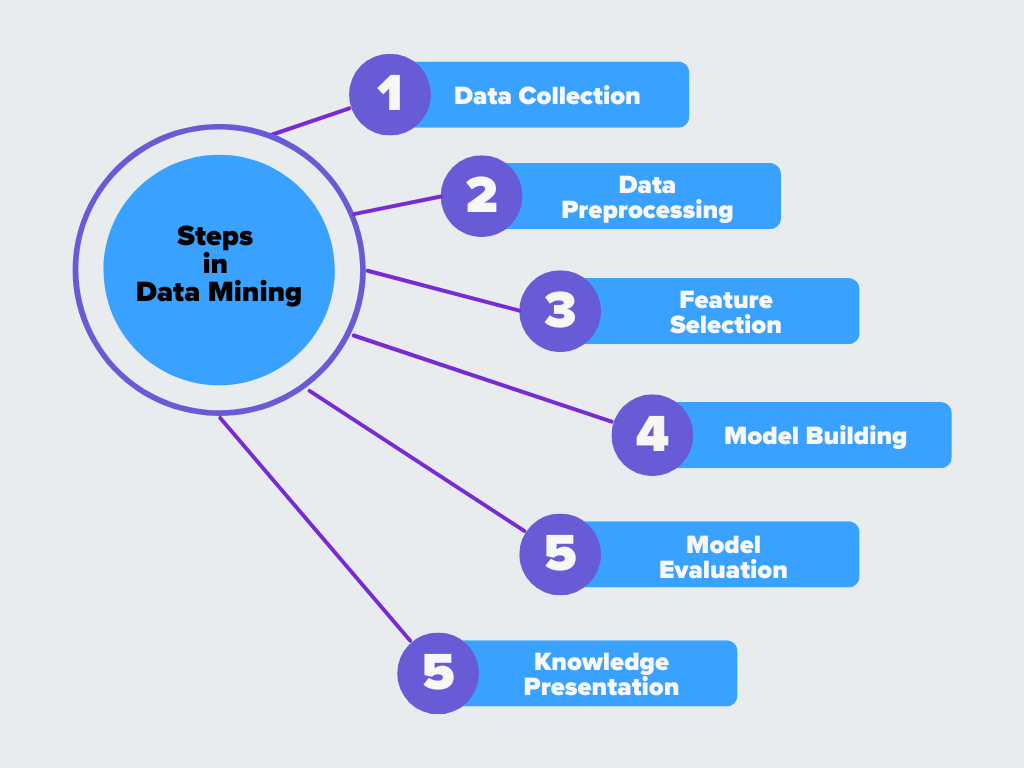 Abbildung - Schritte im Data Mining
Abbildung - Schritte im Data Mining
Abbildung: Schritte im Data Mining
1. Datensammlung
Der erste Schritt besteht darin, Daten aus verschiedenen Quellen zu sammeln, z. B. aus Datenbanken, Tabellenkalkulationen, IoT-Geräten oder Cloud-Speichern. Da die Daten oft in verschiedenen Formaten und Strukturen vorliegen, müssen sie in ein einziges System integriert werden. In diesem Schritt werden auch doppelte Datensätze behandelt und die Datensätze zusammengeführt, um eine einheitliche Ansicht zu erstellen.
**Ein Beispiel: Eine E-Commerce-Plattform sammelt Daten aus Website-Protokollen, Benutzerkonten und Kaufhistorie, um einen vollständigen Überblick über das Kundenverhalten zu erhalten.
2. Vorverarbeitung von Daten
Rohdaten sind selten perfekt. Sie können fehlende Werte, Inkonsistenzen oder Fehler enthalten, die die Genauigkeit der Ergebnisse beeinträchtigen können. Bei der Datenvorverarbeitung werden die Daten bereinigt, indem Duplikate entfernt, fehlende Werte eingefügt und Fehler korrigiert werden. Vorverarbeitungstechniken wie Normalisierung und Transformation helfen dabei, die Daten so zu strukturieren, dass sie für die Analyse bereit sind.
**Einige Kunden haben zum Beispiel unvollständige Profile, fehlende Kaufhistorie oder doppelte Datensätze, die vor der Analyse bereinigt werden müssen.
3. Auswahl der Merkmale
Nicht alle Datenpunkte sind für die Auswertung geeignet. Bei der [Merkmalsauswahl] (https://zilliz.com/ai-faq/what-is-feature-extraction) werden die Daten in ein geeigneteres Format umgewandelt, und es werden wesentliche Merkmale ausgewählt, während irrelevante entfernt werden. Beim Feature-Engineering werden auf der Grundlage vorhandener Daten neue Variablen erstellt, was ebenfalls Teil dieses Schritts ist, um die Modellleistung zu verbessern.
**So können beispielsweise Merkmale wie die Verweildauer auf Produktseiten, frühere Käufe und die Abbruchrate von Warenkörben ausgewählt werden, während weniger nützliche Daten wie IP-Adressen entfernt werden können.
4. Modellbildung
Sobald die Daten bereinigt und aufbereitet sind, werden Algorithmen angewendet, um Muster und Beziehungen zu finden. Techniken wie Clustering, Klassifizierung und Assoziationsregel-Mining helfen dabei, aussagekräftige Erkenntnisse zu gewinnen. In dieser Phase können Modelle für maschinelles Lernen trainiert werden, um Trends zu erkennen, Daten zu klassifizieren oder Vorhersagen auf der Grundlage historischer Muster zu treffen.
**Die Plattform könnte zum Beispiel ein Klassifizierungsmodell verwenden, um vorherzusagen, ob ein Nutzer aufgrund seines Surfverhaltens und früherer Käufe wahrscheinlich einen Kauf tätigen wird.
5. Modellauswertung
Nicht alle beim Mining entdeckten Muster sind hilfreich. In diesem Schritt werden die Ergebnisse validiert, um sicherzustellen, dass sie genau und aussagekräftig sind. Die Analysten vergleichen die Ergebnisse mit bekannten Daten, verwenden Leistungskennzahlen wie Genauigkeit und Wiederaufruf und verfeinern die Modelle bei Bedarf. Ziel ist es, zu bestätigen, dass die gefundenen Muster zuverlässig und auf reale Szenarien anwendbar sind.
Zum Beispiel Die Plattform testet das Vorhersagemodell, indem sie seine Ergebnisse mit den tatsächlichen Käufen vergleicht, um seine Genauigkeit zu überprüfen.
6. Präsentation des Wissens
Der letzte Schritt ist die klare und verständliche Darstellung der Erkenntnisse. Dies kann visuelle Berichte, Dashboards oder Zusammenfassungen umfassen, die von den Entscheidungsträgern verwendet werden können. Das extrahierte Wissen wird dann eingesetzt, um Prozesse zu verbessern, Geschäftsentscheidungen zu treffen oder KI-gesteuerte Systeme zu verbessern.
**Ein Beispiel: Die E-Commerce-Plattform nutzt dieses Wissen, um personalisierte Produktempfehlungen, gezielte Anzeigen und Werbeangebote zu erstellen und so den Umsatz zu steigern.
Techniken und Algorithmen im Data Mining
Data-Mining-Techniken werden in Kategorien eingeteilt, je nachdem, wie sie Daten analysieren und aussagekräftige Muster extrahieren. Zu diesen Techniken gehören überwachtes Lernen, unüberwachtes Lernen, halbüberwachtes Lernen und [Anomalieerkennung] (https://zilliz.com/ai-faq/how-does-machine-learning-improve-anomaly-detection). Jeder Ansatz eignet sich für verschiedene Arten von Problemen, von der Klassifizierung und Vorhersage bis zur Aufdeckung verborgener Strukturen in Daten.
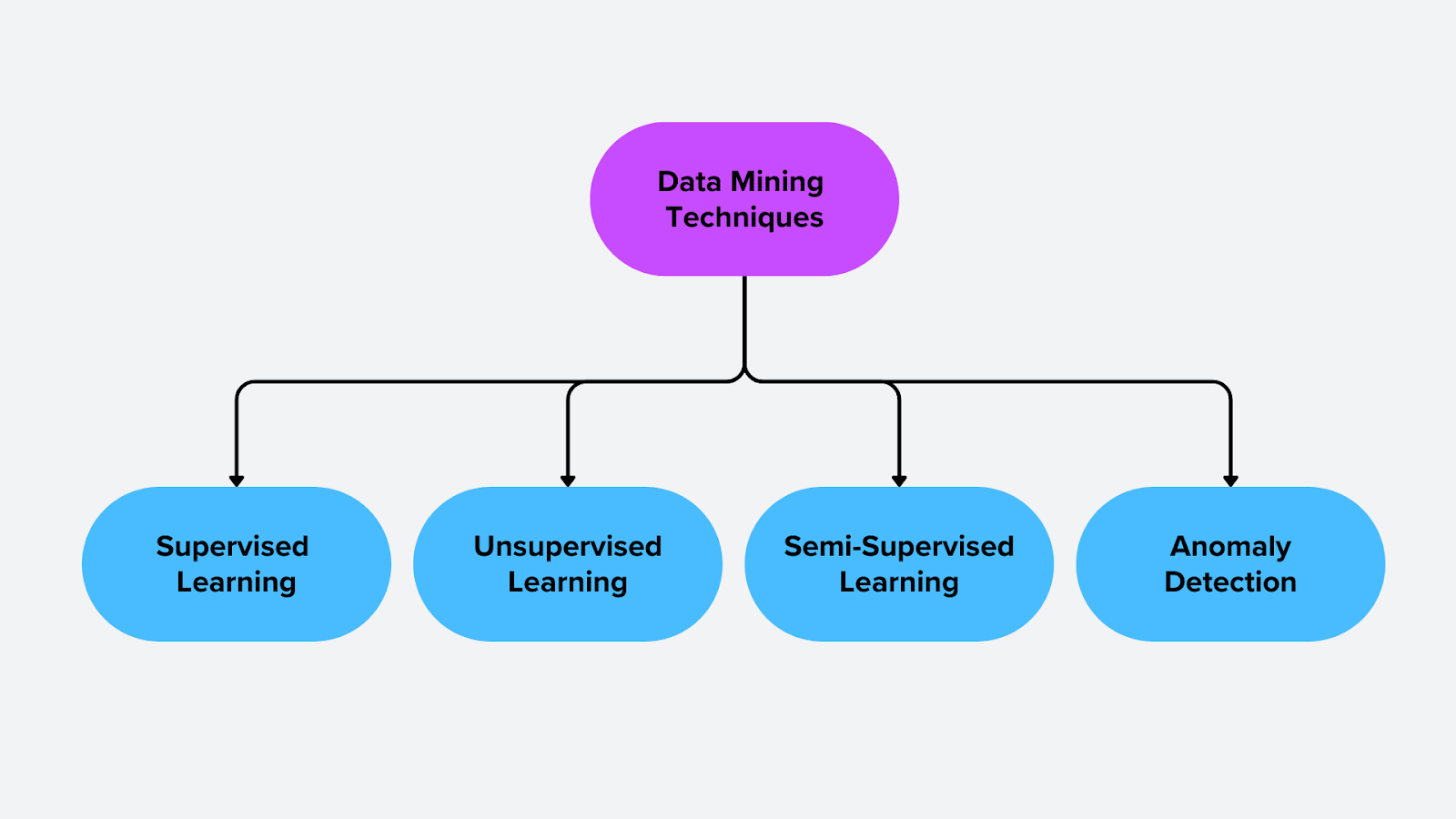 Abbildung- Techniken im Data Mining
Abbildung- Techniken im Data Mining
Abbildung: Techniken im Data Mining
1. Überwachtes Lernen
Beim überwachten Lernen wird ein Modell mit markierten Daten trainiert, wobei jeder Eingabe eine bekannte Ausgabe zugeordnet ist. Das Modell lernt aus diesen Beispielen, um die Ergebnisse für neue, noch nicht gesehene Daten vorherzusagen. Dieser Ansatz wird häufig bei Klassifizierungs-, Regressions- und Zeitreihenvorhersageaufgaben verwendet.
Abbildung - Überwachte maschinelle Lerntechniken (https://assets.zilliz.com/Figure_Supervised_machine_learning_techniques_ac73a06b9a.png)
Abbildung: Überwachte maschinelle Lerntechniken
Entscheidungsbäume: Ein regelbasiertes Modell, das Daten auf der Grundlage von Merkmalswerten in kleinere Teilmengen unterteilt und eine baumartige Struktur für die Entscheidungsfindung bildet.
Random Forests: Ein Ensemble aus mehreren Entscheidungsbäumen, das die Genauigkeit verbessert und die Überanpassung reduziert, indem es Vorhersagen aus mehreren Modellen mittelt.
Gradient Boosted Trees (GBTs): Ein sequenzieller Entscheidungsbaum-Ansatz, der frühere Fehler in jeder Iteration korrigiert, was zu einer höheren Vorhersageleistung führt.
Support Vector Machines (SVMs): Ein Klassifizierungsalgorithmus, der die optimale Grenze (Hyperebene) zur Trennung verschiedener Datenkategorien findet.
K-Nearest Neighbors (K-NN):** Ein abstandsbasierter Algorithmus, der neue Datenpunkte auf der Grundlage der Mehrheitsklasse ihrer nächsten Nachbarn klassifiziert.
Neuronale Netze](https://zilliz.com/learn/Neural-Networks-and-Embeddings-for-Language-Models): Mehrschichtige Modelle nach dem Vorbild des menschlichen Gehirns, die komplexe Beziehungen zwischen Eingabe- und Ausgabedaten lernen.
Support Vector Regression (SVR): Eine Variante der SVM, die zur Vorhersage kontinuierlicher Werte anstelle von kategorialen Bezeichnungen verwendet wird.
2. Unüberwachtes Lernen
Unüberwachtes Lernen analysiert Daten ohne beschriftete Ausgaben und identifiziert verborgene Strukturen und Beziehungen innerhalb eines Datensatzes. Es wird häufig für Clustering, die Erkennung von Anomalien und die Dimensionalitätsreduktion verwendet.
Abbildung - Unüberwachte maschinelle Lerntechniken (https://assets.zilliz.com/Figure_Unsupervised_Machine_Learning_Techniques_ecd834bff8.png)
Abbildung: Unüberwachte maschinelle Lerntechniken
K-Means Clustering](https://zilliz.com/blog/k-means-clustering): Ein Partitionierungsalgorithmus, der Daten in K Cluster unterteilt, indem er jeden Punkt dem nächstgelegenen Clusterzentrum zuordnet.
Hierarchisches Clustering: Baut eine Hierarchie von Clustern entweder durch Bottom-up- (agglomerative) oder Top-down-Methoden (divisive) auf.
DBSCAN (Density-Based Spatial Clustering): Gruppiert dicht gepackte Datenpunkte und behandelt Ausreißer als Rauschen, was es für unregelmäßige Datenverteilungen nützlich macht.
Principal Component Analysis (PCA)](https://zilliz.com/ai-faq/how-does-pca-relate-to-embeddings): Ein Verfahren zur Dimensionalitätsreduktion, das Daten in einen niedrigdimensionalen Raum transformiert, wobei die Varianz erhalten bleibt.
Autoencoder: Eine Art neuronales Netz, das komprimierte Darstellungen von Daten zur Erkennung von Anomalien und zur Merkmalsextraktion lernt.
Association Rule Mining: Identifiziert Beziehungen zwischen Elementen in einem Datensatz, häufig verwendet in der Warenkorbanalyse.
Apriori-Algorithmus: Ein Verfahren zur Suche nach häufigen Mustern, das Beziehungen zwischen Elementen durch die iterative Identifizierung häufiger Elementmengen findet.
FP-Growth-Algorithmus:** Eine effizientere Alternative zu Apriori, die eine Baumstruktur (FP-Tree) verwendet, um häufige Muster mit geringerem Rechenaufwand zu extrahieren.
3. Semi-überwachtes Lernen
Semi-überwachtes Lernen ist ein hybrider Ansatz, bei dem eine kleine Menge markierter Daten mit einer großen Menge unmarkierter Daten kombiniert wird, um die Lerngenauigkeit zu verbessern. Diese Technik ist nützlich, wenn die Beschriftung von Daten teuer oder zeitaufwändig ist.
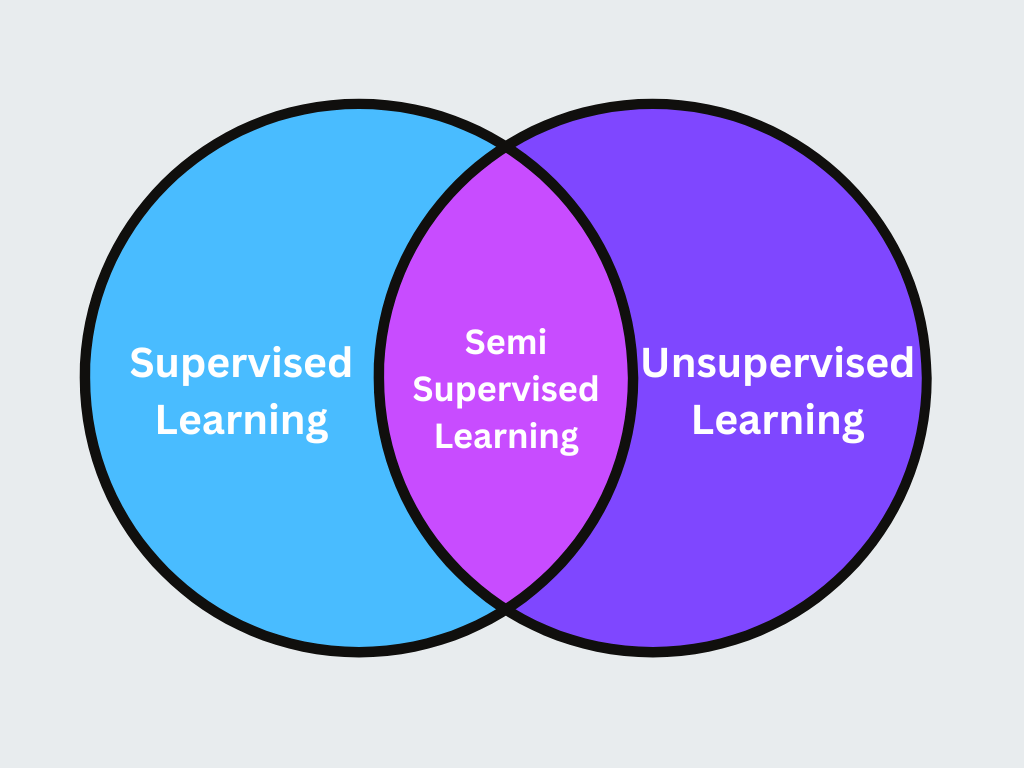 Abbildung- Semi-überwachtes Lernen.png
Abbildung- Semi-überwachtes Lernen.png
Abbildung: Halbüberwachtes Lernen
Self-Training: Ein Modell wird zunächst auf markierten Daten trainiert, macht dann Vorhersagen auf nicht markierten Daten und fügt Vorhersagen mit hoher Zuverlässigkeit dem markierten Datensatz für weiteres Training hinzu.
Graphenbasiertes halbüberwachtes Lernen: Es verwendet Graphenstrukturen, um Kennzeichnungen durch ein Netzwerk verwandter Datenpunkte weiterzugeben, was häufig in [Empfehlungssystemen] (https://zilliz.com/learn/Introduction-to-Recommendation-systems) verwendet wird.
Generative Adversarial Networks (GANs): GANs generieren neue markierte Stichproben, um das Lernen in Szenarien mit wenigen Markierungen zu verbessern, was sie für die Bild- und Spracherkennung nützlich macht.
Konsistenzregulierung: Stellt sicher, dass die Vorhersagen eines Modells auch dann konsistent bleiben, wenn die Eingaben geringfügig variieren, und verbessert so die Robustheit beim semi-supervised learning.
4. Anomalie-Erkennung & Ausreißer-Analyse
Die Erkennung von Anomalien identifiziert Datenpunkte, die erheblich von normalen Mustern abweichen. Diese Algorithmen werden häufig in den Bereichen [Betrugserkennung] (https://zilliz.com/ai-faq/can-anomaly-detection-be-used-for-fraud-detection), Cybersicherheit und industrielle Fehlererkennung eingesetzt.
 Abbildung - Anomalie-Erkennung
Abbildung - Anomalie-Erkennung
Abbildung: Anomalie-Erkennung
Z-Score-Methode: Erkennt Ausreißer, indem gemessen wird, wie viele Standardabweichungen ein Punkt vom Mittelwert abweicht.
Interquartilsbereich (IQR): Identifiziert Ausreißer durch Analyse des Bereichs zwischen dem ersten und dem dritten Quartil, wobei Extremwerte gekennzeichnet werden.
Isolation Forest](https://zilliz.com/ai-faq/what-is-isolation-forest-in-anomaly-detection): Ein baumbasiertes Modell, das Anomalien durch eine zufällige Aufteilung der Datenpunkte schneller isoliert.
Lokaler Ausreißerfaktor (LOF): Misst die relative Dichte von Datenpunkten, um Anomalien in einem Datensatz zu identifizieren.
Ein-Klassen-SVM: Eine Variante der SVM, die Abweichungen von der Mehrheitsklasse erkennt und häufig zur Betrugserkennung eingesetzt wird.
Autoencoder-basierte Anomalie-Erkennung: Verwendet Deep Learning zur Rekonstruktion von Eingabedaten und markiert Anomalien, wenn der Rekonstruktionsfehler hoch ist.
Anwendungen von Data Mining in verschiedenen Branchen
Data Mining wird in verschiedenen Branchen eingesetzt, um große Datenmengen zu analysieren, Muster aufzudecken und die Entscheidungsfindung zu verbessern. Im Folgenden finden Sie einige branchenspezifische Anwendungsfälle:
1. Finanzen
Betrugserkennung: Banken nutzen Data Mining, um Transaktionsmuster zu analysieren und verdächtige Aktivitäten zu erkennen, z. B. ungewöhnliches Ausgabeverhalten oder mehrfache fehlgeschlagene Anmeldeversuche.
Kreditwürdigkeitsprüfung und Risikobewertung: Finanzinstitute bewerten das Risikoniveau eines Kreditnehmers, indem sie die Kreditvergangenheit, Einkommensmuster und frühere Kreditrückzahlungen analysieren.
Algorithmischer Handel: Wertpapierfirmen nutzen prädiktive Analysen zur Analyse von Markttrends und zur Automatisierung von Hochfrequenzhandelsstrategien.
2. Gesundheitswesen
Krankheitsvorhersage und -diagnose: Krankenhäuser analysieren Patientenakten und Symptome, um Krankheiten frühzeitig zu erkennen, die Behandlungspläne zu verbessern und Krankenhausaufenthalte zu reduzieren.
Arzneimittelentdeckung und -entwicklung: Pharmaunternehmen nutzen Data Mining, um durch die Analyse von genetischen und klinischen Studiendaten potenzielle Arzneimittelkandidaten zu identifizieren.
Vorhersage von Patientenrückübernahmen: Gesundheitsdienstleister analysieren die Patientengeschichte, um die Wahrscheinlichkeit von Rückübernahmen vorherzusagen und Präventivmaßnahmen zu ergreifen.
3. E-Commerce & Einzelhandel
Personalisierte Empfehlungen: Online-Händler analysieren das Surf- und Kaufverhalten ihrer Kunden, um maßgeschneiderte Produktempfehlungen anzubieten.
Dynamische Preisstrategien: E-Commerce-Plattformen passen die Preise auf der Grundlage der Nachfrage, der Preise der Wettbewerber und des Kundenverhaltens an.
Abwanderungsvorhersage: Einzelhändler nutzen Data Mining, um abwanderungsgefährdete Kunden zu identifizieren und sie mit speziellen Angeboten anzusprechen, um die Kundenbindung zu verbessern.
4. Cybersecurity
Intrusion Detection Systems (IDS): Unternehmen nutzen Data Mining, um ungewöhnliche Netzwerkaktivitäten wie unberechtigte Zugriffsversuche oder Malware-Infektionen zu erkennen.
Threat Intelligence & Risikobewertung: Sicherheitsteams analysieren historische Angriffsdaten, um zukünftige Cyberbedrohungen vorherzusagen und zu verhindern.
Erkennung von Phishing und Betrug: Modelle des maschinellen Lernens erkennen Phishing-Versuche durch die Analyse von E-Mail-Mustern, URLs und Absenderverhalten.
5. Fertigung & Industrielles IoT
Vorausschauende Wartung: Fabriken analysieren Maschinensensordaten, um Ausfälle vorherzusagen, bevor sie auftreten, und so Ausfallzeiten und Reparaturkosten zu reduzieren.
Optimierung der Lieferkette: Hersteller nutzen Data Mining, um Nachfrageschwankungen vorherzusagen, Bestände zu optimieren und Verschwendung zu reduzieren.
Qualitätskontrolle und Fehlererkennung: Die Datenanalyse hilft bei der frühzeitigen Erkennung von Produktionsfehlern, indem sie Anomalien in den Fertigungsprozessen aufdeckt.
6. Telekommunikation
Netzoptimierung: Telekommunikationsunternehmen analysieren die Nutzungsmuster, um die Bandbreitenzuweisung zu optimieren und Überlastungen zu verringern.
Kundensegmentierung und Kundenbindung: Betreiber klassifizieren Kunden anhand ihres Nutzungsverhaltens und bieten maßgeschneiderte Pläne an, um die Kundenbindung zu verbessern.
Spam- und Robocall-Erkennung: Data-Mining-Techniken helfen, Spam-Anrufe und -Nachrichten auf der Grundlage von Anrufmustern und Benutzerberichten zu filtern.
7. Energie & Versorgungsunternehmen
Stromverbrauchsprognose: Energieunternehmen analysieren vergangene Verbrauchsmuster, um den künftigen Bedarf vorherzusagen und die Netzleistung zu optimieren.
Fehlererkennung in Stromnetzen: Sensoren überwachen Stromleitungen und erkennen Anomalien, um Ausfälle zu verhindern und die Wartung zu verbessern.
Smart Meter Analytics: Energieversorger nutzen Data Mining, um ungewöhnliche Energienutzungsmuster zu erkennen und potenziellen Energiediebstahl zu identifizieren.
8. Bildung
Schülerleistungsvorhersage: Schulen analysieren Schülerdaten, um gefährdete Schüler zu identifizieren und ihnen individuelle Lernunterstützung zu bieten.
Anpassungsfähige Lernsysteme: Bildungsplattformen nutzen Data Mining, um Lernmaterialien auf der Grundlage der Stärken und Schwächen der Schüler zu personalisieren.
Kursempfehlungssysteme: Universitäten analysieren die Leistungen der Schüler, um auf der Grundlage von Interessen und Karrierezielen geeignete Kurse zu empfehlen.
Vorteile von Data Mining
Entdeckt verborgene Muster: Hilft Unternehmen und Forschern, Erkenntnisse zu entdecken, die in Rohdaten nicht sofort ersichtlich sind.
Verbessert die Entscheidungsfindung: Liefert datengestützte Erkenntnisse, die die strategische Planung und Prognosegenauigkeit verbessern.
Automatisierte Trendanalyse: Dieses Tool identifiziert Trends und Verschiebungen im Verbraucherverhalten, in den Marktbedingungen und in den Finanzmustern ohne manuelle Eingriffe.
Verstärkt die Kundenpersonalisierung: Ermöglicht hochgradig zielgerichtetes Marketing durch die Analyse von Kundenpräferenzen und früheren Interaktionen.
Optimiert Geschäftsabläufe: Verbessert die Effizienz der Lieferkette, reduziert die Verschwendung und steigert die Produktivität durch die Vorhersage von Nachfrage und Ressourcenbedarf.
Verbesserung der Diagnostik im Gesundheitswesen: Unterstützt die Früherkennung von Krankheiten und personalisierte Behandlungspläne durch die Analyse von Patientendaten.
Beschleunigt die wissenschaftliche Forschung: Beschleunigt die Entdeckung von Medikamenten, die genetische Analyse und die Klimamodellierung durch die schnelle Analyse großer Datensätze.
Wie hilft Milvus beim Data Mining?
Data Mining erfordert oft die Analyse großer Mengen strukturierter und [unstrukturierter Daten] (https://zilliz.com/learn/introduction-to-unstructured-data), um aussagekräftige Muster zu entdecken. Traditionelle relationale Datenbanken haben mit hochdimensionalen und unstrukturierten Daten zu kämpfen, was sie für moderne Anwendungen wie Empfehlungssysteme, Anomalieerkennung und semantische Suche ineffizient macht. Milvus, eine Open-Source-Vektordatenbank, die von Zilliz ****engineers entwickelt wurde, ist speziell für die Verarbeitung großer, hochdimensionaler Daten konzipiert und damit ein leistungsstarkes Werkzeug für Data-Mining-Aufgaben.
1. Handhabung hochdimensionaler Daten
Moderne Data-Mining-Anwendungen stützen sich auf hochdimensionale Daten, wie z. B. Bilder [Einbettungen] (https://zilliz.com/glossary/vector-embeddings), Textdarstellungen und [Zeitreihendaten] (https://zilliz.com/learn/time-series-embedding-data-analysis), um aussagekräftige Erkenntnisse zu gewinnen. Herkömmliche relationale Datenbanken sind bei der Verarbeitung dieser Datentypen ineffizient, da sie eher für strukturierte Tabellen als für mehrdimensionale Vektordarstellungen konzipiert sind.
Milvus bietet eine dedizierte Vektordatenbank zum Speichern und Verwalten hochdimensionaler Einbettungen, was sie zu einer zentralen Infrastrukturkomponente für KI-gestütztes Data Mining macht.
Milvus unterstützt verschiedene Datenformate, darunter dichte und spärliche Vektoren, um Flexibilität für verschiedene Modelle des maschinellen Lernens und des Deep Learning zu gewährleisten.
Optimierte Vektorindizierung Strukturen (wie IVF, HNSW und PQ) erhöhen die Speichereffizienz, reduzieren Redundanzen und verbessern die Abfrageleistung in großen Datensätzen.
Die Stapelverarbeitung und Parallelisierungsfunktionen ermöglichen das schnelle Einfügen und Abrufen von Millionen von Vektoren für KI-Anwendungen, die kontinuierliche Aktualisierungen erfordern.
**Ein Beispiel: **Ein Videoanalyseunternehmen speichert Frame-by-Frame-Einbettungen in Milvus und ermöglicht so eine effiziente inhaltsbasierte Suche und Abfrage für automatisiertes Video-Tagging und -Klassifizierung.
2. Skalierbarkeit für Big-Data-Mining-Anwendungen
Big Data Mining erfordert Datenbanken, die mit wachsenden Informationsmengen skalieren können. Milvus bietet:
Cloud-native Architektur für groß angelegte Implementierungen in verteilten Umgebungen.
Effiziente Ressourcennutzung für kosteneffiziente Abfrageleistung auch bei großen Datenmengen.
Die Integration in KI-basierte Data-Mining-Pipelines ist einfach, da sie in Frameworks für maschinelles Lernen wie TensorFlow, PyTorch und Hugging Face integriert ist.
**In der Genomik speichert und durchsucht Milvus beispielsweise DNA-Sequenzeinbettungen, um Forschern zu helfen, genetische Ähnlichkeiten in Millionen von Datensätzen schnell zu finden.
3. Effiziente semantische Suche und Ähnlichkeitssuche
Die semantische und Ähnlichkeitssuche sind für moderne Data-Mining-Anwendungen, die unstrukturierte Daten wie Bilder, Texte und Multimedia enthalten, unerlässlich. Im Gegensatz zu herkömmlichen stichwortbasierten Suchen stützt sich die Ähnlichkeitssuche auf Vektoreinbettungen, um die relevantesten Ergebnisse auf der Grundlage der Bedeutung und nicht der exakten Übereinstimmungen abzurufen.
Milvus ermöglicht eine leistungsstarke Ähnlichkeitssuche durch die Nutzung von Vektoreinbettungen. Es ermöglicht den Benutzern, Ergebnisse auf der Grundlage des Kontexts und nicht auf der Grundlage exakter Wörter zu finden.
Es unterstützt Approximate Nearest Neighbor (ANN) Suchalgorithmen wie HNSW, IVF und PQ, um die Suche in großen Datensätzen zu beschleunigen.
Multimodale Suchfunktionen ermöglichen eine bereichsübergreifende Suche in Texten, Bildern und Videos, was sie ideal für Empfehlungssysteme, Content Retrieval und NLP-Anwendungen macht.
**Ein Suchsystem für juristische Dokumente kann Milvus zum Beispiel dazu verwenden, Rechtsfälle auf der Grundlage der semantischen Bedeutung und nicht nur anhand von Schlüsselwörtern abzurufen, was die Genauigkeit bei der juristischen Recherche verbessert.
Schlussfolgerung
Data Mining ist ein transformativer Prozess, der riesige Datensätze in verwertbare Erkenntnisse umwandelt und Innovationen in der Finanz- und Gesundheitsbranche vorantreibt. Unternehmen können verborgene Muster aufdecken, Abläufe optimieren und datengestützte Entscheidungen treffen, indem sie fortschrittliche Techniken wie überwachtes und unüberwachtes Lernen, Anomalieerkennung und die Suche nach häufigen Mustern nutzen. Milvus erweitert diese Möglichkeiten durch die Bereitstellung einer robusten Plattform für die Speicherung und den Abruf hochdimensionaler Daten, die eine effiziente semantische Suche und Ähnlichkeitssuche ermöglicht. Seine Fähigkeit, nahtlos mit Big-Data-Anwendungen zu skalieren, macht es zu einem unschätzbaren Werkzeug für moderne Data-Mining-Anforderungen.
FAQs zu Data Mining
1. Was sind die wichtigsten Techniken, die beim Data Mining verwendet werden?
Beim Data Mining kommen verschiedene Techniken zum Einsatz, darunter überwachtes Lernen (Entscheidungsbäume, SVMs, neuronale Netze), unüberwachtes Lernen (Clustering, Assoziationsregel-Mining), Erkennung von Anomalien und Mining häufiger Muster (Apriori, FP-Growth). Jede Technik hilft dabei, sinnvolle Erkenntnisse aus großen Datenbeständen zu gewinnen.
2. Wie unterscheidet sich Data Mining von der traditionellen Datenanalyse?
Die herkömmliche Datenanalyse stützt sich auf vordefinierte Abfragen und menschliche Interpretationen, während Data Mining automatisierte Algorithmen verwendet, um verborgene Muster, Trends und Beziehungen in Daten aufzudecken. Data Mining ist außerdem besser skalierbar und eignet sich daher für den Umgang mit Big Data und KI-Anwendungen.
3. Was sind die größten Herausforderungen beim Data Mining?
Zu den größten Herausforderungen beim Data Mining gehören der Umgang mit verrauschten und unvollständigen Daten, Datenschutz- und Sicherheitsbedenken, die Bewältigung der Rechenkomplexität und die Skalierung auf große Datensätze. Eine wirksame Vorverarbeitung und der Einsatz fortschrittlicher KI-Modelle helfen, diese Probleme zu entschärfen.
4. Wie wird Data Mining in realen Anwendungen eingesetzt?
Data Mining wird häufig zur Erkennung von Betrug im Bankwesen, für Empfehlungssysteme im elektronischen Handel, zur vorausschauenden Wartung in der Fertigung, zur Krankheitsdiagnose im Gesundheitswesen und zur Erkennung von Bedrohungen der Cybersicherheit eingesetzt. Es hilft Unternehmen, die Entscheidungsfindung zu optimieren und Prozesse zu automatisieren.
5. Welche Rolle spielen Vektordatenbanken beim Data Mining?
Vektordatenbanken wie Milvus helfen dabei, hochdimensionale Daten effizient zu speichern und abzurufen, wodurch Ähnlichkeitssuche, Clustering und die Erkennung von Anomalien beschleunigt werden. Diese Datenbanken sind für KI-gesteuerte Anwendungen wie Bilderkennung, natürliche Sprachverarbeitung und Empfehlungssysteme von Vorteil.
Verwandte Ressourcen
Was ist eine Vektordatenbank und wie funktioniert sie?](https://zilliz.com/learn/what-is-vector-database)
Klassifizierung beim maschinellen Lernen: Alles, was Sie wissen sollten](https://zilliz.com/glossary/classification)
Was ist Objekterkennung? Ein umfassender Leitfaden](https://zilliz.com/learn/what-is-object-detection)
Erstellen von KI-Anwendungen mit Retrieval Augmented Generation (RAG)](https://zilliz.com/learn/Retrieval-Augmented-Generation)
Dimensionalitätsreduktion: Vereinfachung komplexer Daten für eine einfache Analyse](https://zilliz.com/glossary/dimensionality-reduction)
- Was ist Data Mining?
- Wie funktioniert Data Mining?
- Techniken und Algorithmen im Data Mining
- Anwendungen von Data Mining in verschiedenen Branchen
- Vorteile von Data Mining
- Wie hilft Milvus beim Data Mining?
- Schlussfolgerung
- FAQs zu Data Mining
- Verwandte Ressourcen
Inhalte
Kostenlos starten, einfach skalieren
Testen Sie die vollständig verwaltete Vektordatenbank, die für Ihre GenAI-Anwendungen entwickelt wurde.
Zilliz Cloud kostenlos ausprobieren