




Change Data Capture: Ihre Systeme in Echtzeit synchron halten

Change Data Capture: Ihre Systeme in Echtzeit synchron halten
Was ist Change Data Capture (CDC)?
Change Data Capture (CDC) ist eine Methode, die verwendet wird, um Änderungen an Daten zu erkennen und zu verfolgen, während sie innerhalb einer Datenbank stattfinden. Anstatt Aktualisierungen manuell zu überwachen oder wiederholt abzufragen, erfasst CDC automatisch Einfügungen, Aktualisierungen und Löschungen in Echtzeit oder nahezu in Echtzeit. CDC-Techniken wie Transaktionsprotokolle und Datenbank-Trigger erleichtern es Unternehmen, Datenkonsistenz und -integrität über verschiedene Systeme und Bereitstellungsumgebungen hinweg aufrechtzuerhalten. Dadurch wird sichergestellt, dass nachgelagerte Systeme und Anwendungen – ob sie traditionelle Analysen oder vektorbasierte KI-Modelle unterstützen – stets über die neuesten Daten verfügen.
Zum Beispiel verfolgt CDC in einer Vektordatenbank Echtzeitaktualisierungen von Embeddings für Aufgaben wie semantische Suche oder Betrugserkennung, bei denen die neuesten Daten für genaue Ergebnisse erforderlich sind.
Entwicklung der Datenintegration: Die Rolle von CDC
In der Vergangenheit war Batch-Verarbeitung der primäre Ansatz für die Datenintegration. Sie verursachte jedoch Verzögerungen, da Datenaktualisierungen in großen Mengen zu geplanten Intervallen verarbeitet wurden, oft Stunden oder Tage nachdem Änderungen aufgetreten waren. Diese Einschränkung machte sie ungeeignet für Anwendungen wie semantische Echtzeitsuche für KI-gestützte Chatbots oder Empfehlungssysteme, die auf Vektordatenbanken angewiesen sind, um hochdimensionale Daten zu analysieren.
CDC löst dieses Problem, indem Änderungen erfasst werden, sobald sie auftreten, und Systeme in Echtzeit aktualisiert werden. Diese Technik ermöglicht es Unternehmen, ihre Datenbanken zu synchronisieren, Echtzeit-Dashboards zu betreiben und reaktionsfähige Anwendungen zu erstellen. Der Aufstieg von CDC fiel mit dem Wachstum moderner verteilter Systeme und cloudnativer Architekturen zusammen, bei denen zeitnahe Datenreplikation und -integration entscheidend sind. Anstatt mit veralteten Daten aus periodischen Aktualisierungen zu arbeiten, können Unternehmen Änderungen nun erfassen und darauf reagieren, sobald sie auftreten. Dieser Wandel hat CDC zu einem wesentlichen Bestandteil moderner Datenstrategien gemacht, indem er Unternehmen hilft, in Echtzeit reaktionsfähig und wettbewerbsfähig zu bleiben.
Wie funktioniert Change Data Capture?
Stellen Sie sich vor, Sie verfolgen die Interaktionen eines Kunden auf einer E-Commerce-Plattform. Jede Interaktion, wie Stöbern, Hinzufügen zum Warenkorb oder Kaufen, erzeugt neue Daten. CDC streamt diese geänderten Daten in Echtzeit an eine Vektordatenbank wie Milvus, wo ihre Vektorrepräsentationen, auch bekannt als Vektor-Embeddings, für Aufgaben wie personalisierte Empfehlungen oder Betrugsprävention aktualisiert werden können.
Lassen Sie uns dies in Schlüsselkomponenten und Mechanismen aufschlüsseln, um zu verstehen, wie CDC funktioniert.
Schlüsselkomponenten von CDC
Damit CDC funktionsfähig ist, arbeiten mehrere Komponenten zusammen. Das folgende Diagramm veranschaulicht den CDC-Prozess.
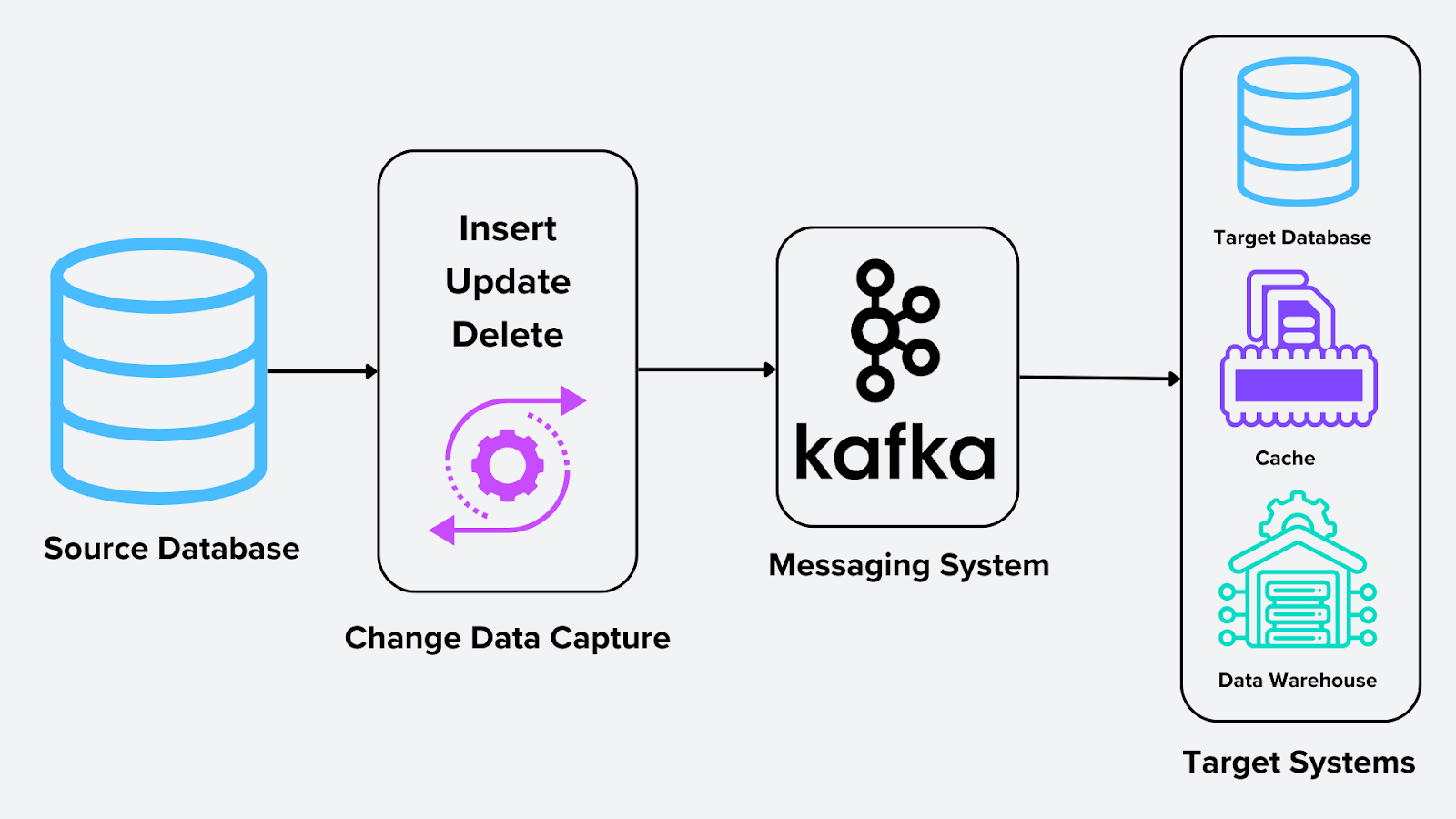 Abbildung- Change Data Capture Process .png
Abbildung- Change Data Capture Process .png
Abbildung: Change Data Capture-Prozess
Quelle: Das System, in dem Änderungen entstehen; dies können relationale Datenbanken, NoSQL-Systeme oder Vektordatenbanken sein. Im Fall einer Vektordatenbank wie Milvus könnte die Quelle aus Deep-Learning-Modellen oder Bilderkennungsmodellen generierte Embeddings sein.
CDC Engine: Der Kernprozess, der Änderungen erfasst und formatiert. Für Vektordatenbanken könnte dies bedeuten, in Milvus gespeicherte Embeddings mithilfe von Tools wie Milvus-CDC oder Confluent Kafka Connect zu aktualisieren.
Messaging-System: Ein Messaging-System wie Apache Kafka dient als Rückgrat für die Verteilung von Änderungen in Echtzeit. Es fungiert als Vermittler, der erfasste Änderungen speichert und an ein oder mehrere Zielsysteme streamt. Dies gewährleistet Skalierbarkeit und Zuverlässigkeit in der Datenpipeline.
Zielsysteme: Die Ziele, an die die verarbeiteten Datenänderungen gesendet werden. Beispiele sind:
Data Warehouses (z. B. Snowflake, BigQuery) für Analysen.
Caches für schnellere Abfrageantworten.
Datenbanken für Replikation und Synchronisierung über Systeme hinweg.
Überblick über CDC-Mechanismen
Es gibt drei primäre Möglichkeiten, wie CDC Änderungen aus einer Datenbank erfassen kann. In den folgenden Beispielen verwenden wir SQL-Datenbanken zur Veranschaulichung.
1. Log-Based CDC
Diese Methode stützt sich auf das Transaktionsprotokoll der Datenbank, eine Funktion auf Systemebene, die alle Datenbankänderungen (Einfügungen, Aktualisierungen und Löschungen) aufzeichnet. Die CDC-Engine liest diese Protokolle und extrahiert die relevanten Änderungen für die nachgelagerte Nutzung. In Vektordatenbanken könnte dies bedeuten, Aktualisierungen von Einbettungsvektoren zu erfassen, wenn sie in Milvus eingefügt oder geändert werden.
Wie es funktioniert:
Das Transaktionsprotokoll ist die einzige Wahrheitsquelle für alle Datenbankoperationen.
Das CDC-Tool überwacht das Protokoll und identifiziert und erfasst kontinuierlich Änderungen, ohne die primäre Datenbank zu beeinträchtigen.
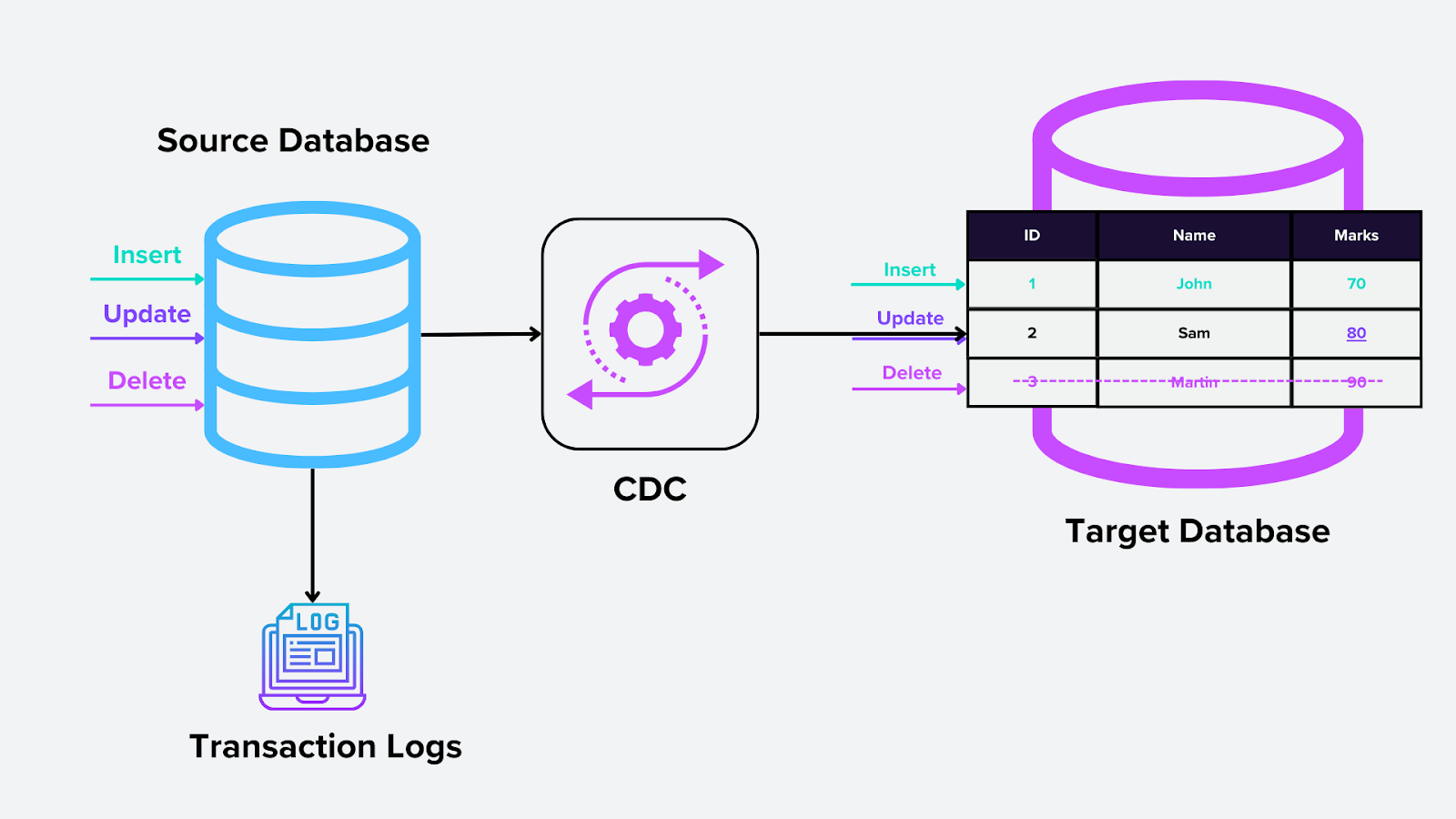 Figure- Log-based CDC.png
Figure- Log-based CDC.png
Abbildung: Log-based CDC
Vorteile:
Hohe Performance: Minimale Auswirkungen auf die Datenbank, da direkt aus Protokollen gelesen wird.
Umfassend: Erfasst alle Änderungen, einschließlich Triggern, gespeicherten Prozeduren oder anderen indirekten Methoden.
Skalierbar: Funktioniert gut mit Systemen mit hohem Transaktionsaufkommen.
Nachteile:
Komplexität: Erfordert eine tiefe Integration in die interne Protokollstruktur der Datenbank, die je nach Datenbanktyp variieren kann.
Kompatibilität: Nicht alle Datenbanken stellen Transaktionsprotokolle für externen Zugriff bereit.
2. Trigger-Based CDC
Dieser Ansatz verwendet Datenbank-Trigger, also benutzerdefinierte Logik, die automatisch ausgeführt wird, wenn eine bestimmte Änderung (z. B. Einfügen, Aktualisieren oder Löschen) in einer Tabelle erfolgt. Beispielsweise könnten Trigger automatisch einen Milvus-Vektorindex aktualisieren, wenn neue Einbettungen hinzugefügt werden.
Wie es funktioniert:
Trigger werden zu interessierenden Tabellen in der Datenbank hinzugefügt.
Wenn Änderungen auftreten, erfasst der Trigger diese und sendet die Informationen an einen angegebenen Ort oder eine Tabelle für die nachgelagerte Verarbeitung.
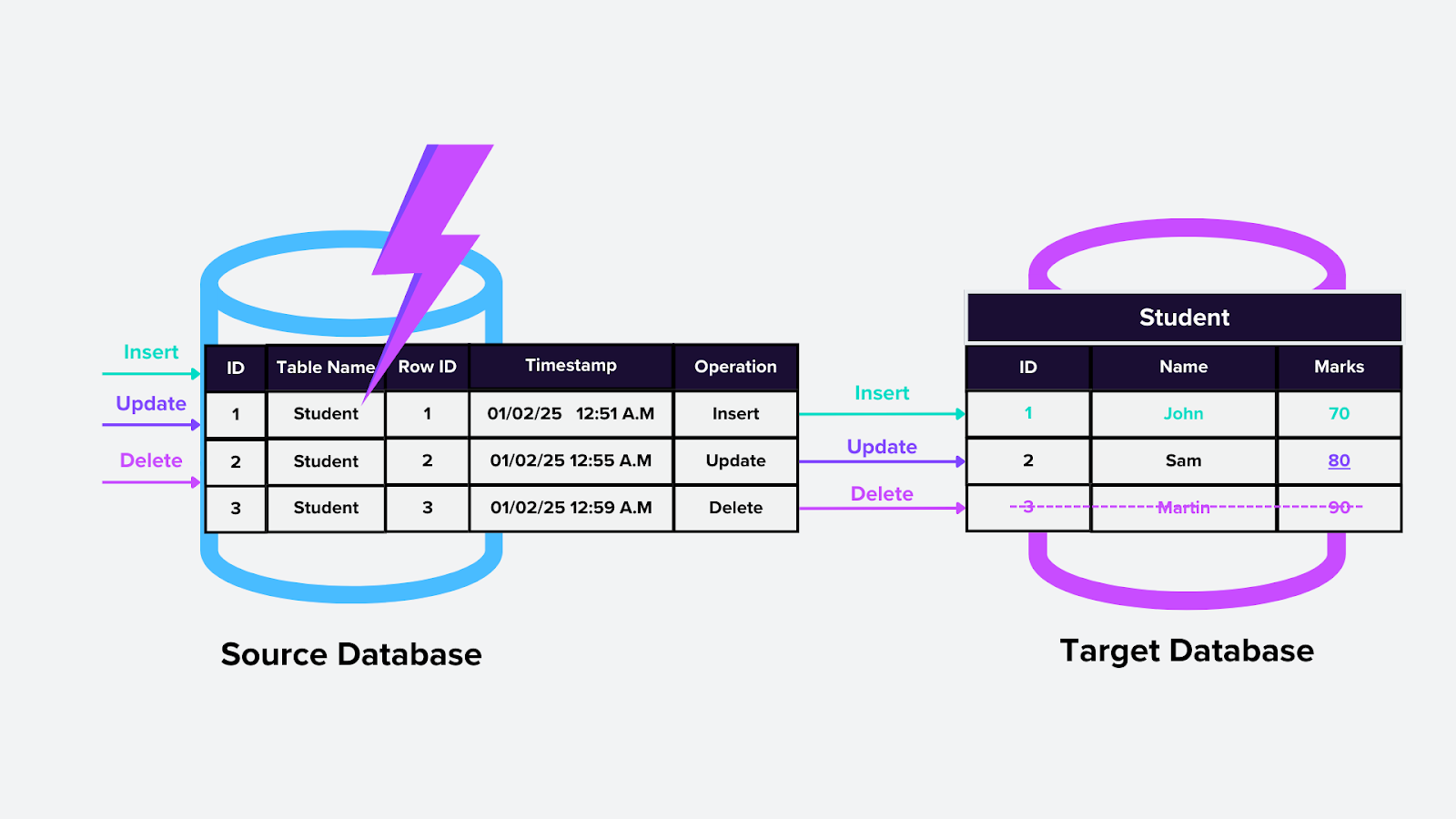 Figure- Trigger-based CDC.png
Figure- Trigger-based CDC.png
Abbildung: Trigger-based CDC
Vorteile:
Flexibel: Kann angepasst werden, um Änderungen für spezifische Anwendungsfälle zu verfolgen.
Breit unterstützt: Fast alle relationalen Datenbanken unterstützen Trigger.
Nachteile:
Performance-Auswirkung: Trigger verursachen zusätzlichen Aufwand für die Datenbank, insbesondere bei Transaktionen mit hoher Frequenz.
Wartungsherausforderungen: Das Verwalten und Aktualisieren von Triggern über mehrere Tabellen hinweg kann schwierig werden.
Fehleranfällig: Schlecht geschriebene Trigger können Performance-Engpässe verursachen oder Edge Cases nicht erfassen.
3. Query-Based CDC
Diese Methode beinhaltet das Ausführen periodischer Abfragen gegen die Datenbank, um Änderungen zu erkennen. Die Abfragen vergleichen typischerweise Zeitstempel oder Versionen, um neu geänderte Datensätze zu identifizieren, z. B. das Abfragen einer Vektordatenbank nach aktualisierten Einbettungen.
Wie es funktioniert:
Die CDC-Engine führt Abfragen in geplanten Intervallen aus und identifiziert Änderungen anhand bestimmter Kriterien (z. B. letztes Änderungsdatum).
Erkannte Änderungen werden anschließend nachgelagert gesendet.
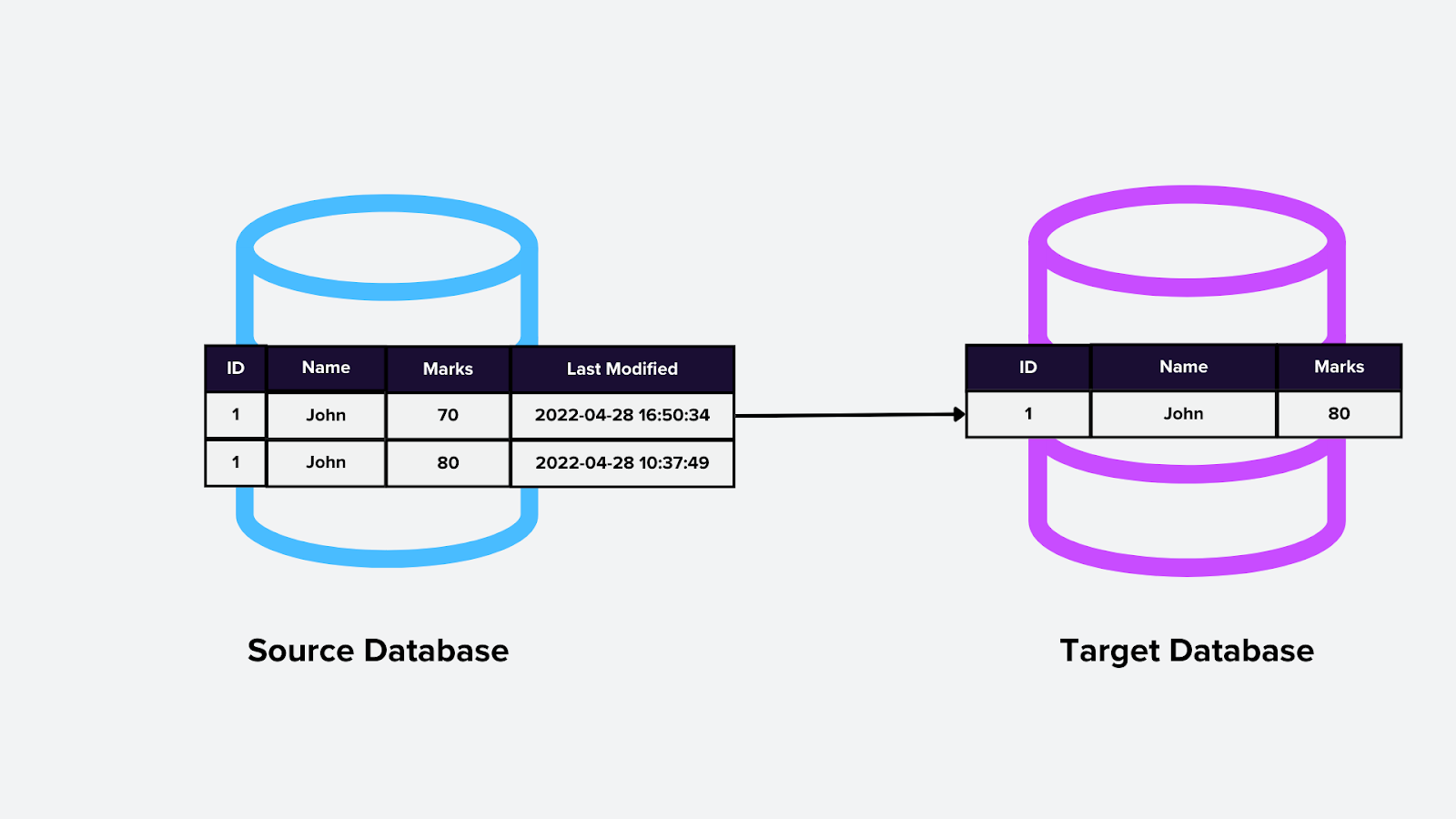 Figure- Query-based CDC.png
Figure- Query-based CDC.png
Abbildung: Query-based CDC
Vorteile:
Einfache Einrichtung: Erfordert keine tiefe Datenbankintegration oder -änderung.
Datenbankunabhängig: Funktioniert mit nahezu jeder Datenbank, die Abfragen unterstützt.
Nachteile:
Latenz: Nicht Echtzeit, da es vom Abfragezeitplan abhängt.
Performance-Overhead: Häufige Abfragen können die Datenbank belasten.
Begrenzte Genauigkeit: Änderungen können übersehen werden, wenn Datenmodifikationen zwischen Abfrageintervallen auftreten.
Vergleich von CDC-Mechanismen
Die folgende Tabelle bietet schnelle Einblicke in verschiedene CDC-Mechanismen und ihre Anwendungsfälle:
| Mechanismus | Echtzeit | Performance-Auswirkung | Einfachheit der Einrichtung | Eignung für Anwendungsfälle |
| Log-Based | Ja | Niedrig | Mittel | Transaktionssysteme mit hohem Volumen |
| Trigger-Based | Ja | Mittel-Hoch | Niedrig-Mittel | Anwendungsfälle, die benutzerdefinierte Änderungslogik erfordern |
| Query-Based | Nein | Hoch | Hoch | Einfache Setups mit seltenen Änderungen |
Tabelle: Vergleich von CDC-Mechanismen
CDC mit Milvus: Echtzeit-Datenintegration für Vektordatenbanken
Milvus, eine Open-Source-Vektordatenbank (entwickelt von Zilliz-Ingenieuren), die für die Verwaltung unstrukturierter Daten wie Vektor-Embeddings aus Machine-Learning-Modellen entwickelt wurde, verfügt über ein eigenes CDC-Tool, Milvus-CDC, das ausdrücklich für die Handhabung von Datenreplikations- und Synchronisierungsaufgaben innerhalb von Milvus-Instanzen konzipiert ist. Milvus-CDC erfasst inkrementelle Datenänderungen für eine nahtlose Synchronisierung zwischen Quell- und Ziel-Milvus-Instanzen. Dies unterstützt Aufgaben wie inkrementelle Backups, Notfallwiederherstellung und persistente Datenreplikation bei gleichzeitiger Wahrung der Datenintegrität und -konsistenz. Milvus-CDC umfasst zwei Hauptkomponenten: den HTTP Server, der Benutzeranfragen verwaltet, Aufgaben ausführt und Aufgabenmetadaten pflegt, und Corelib, das die Aufgabensynchronisierung übernimmt, mit einem Reader, der Daten aus der Quell-Milvus-Instanz und der Message Queue extrahiert, und einem Writer, der diese Änderungen verarbeitet und an die Ziel-Milvus-Instanz sendet.
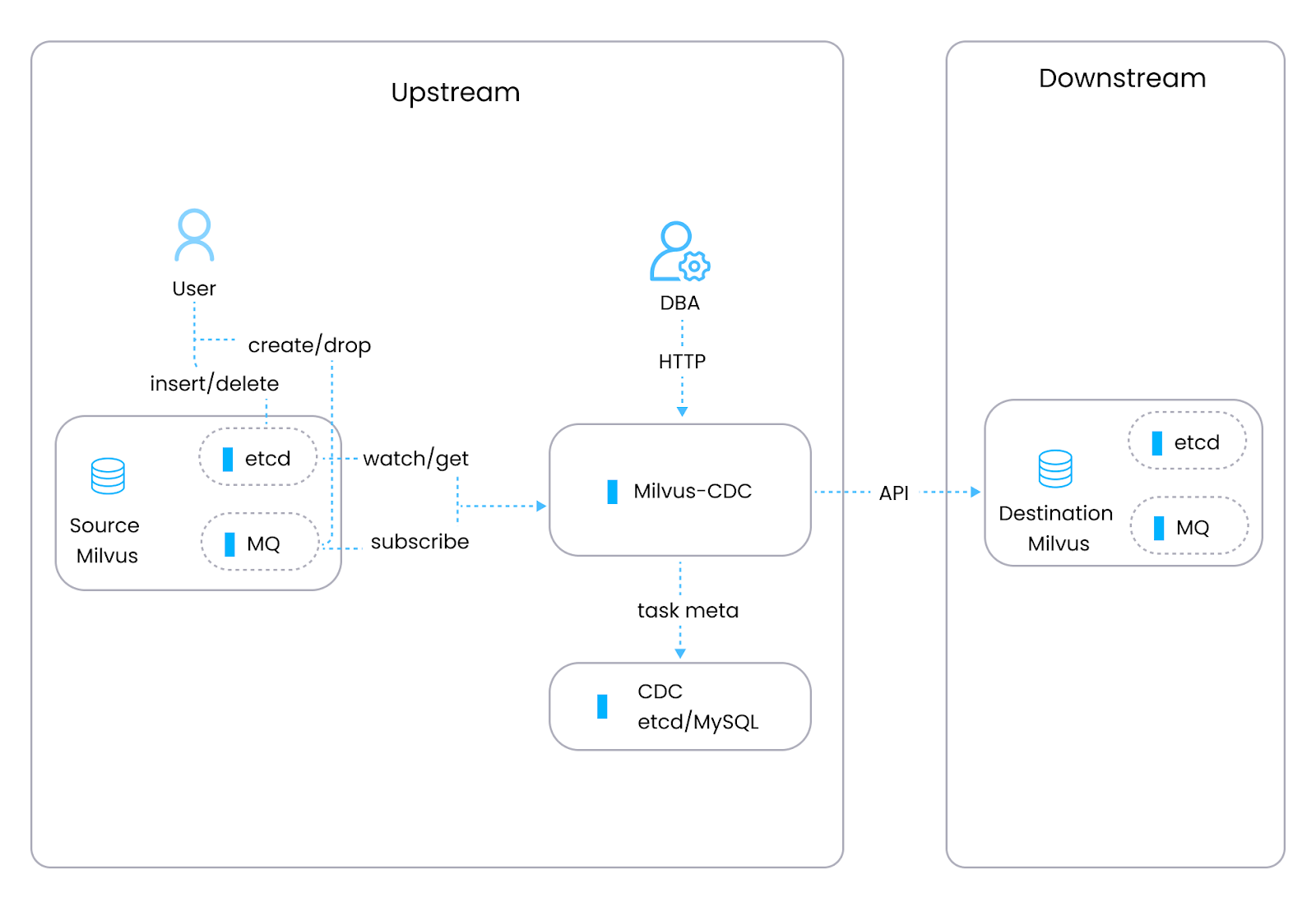 Figure- The Milvus-CDC architecture.png
Figure- The Milvus-CDC architecture.png
Abbildung: Die Milvus-CDC-Architektur
Milvus-CDC: Hauptfunktionen
Sequenzielle Datensynchronisierung: Stellt sicher, dass Änderungen angewendet werden, um die Datenkonsistenz über Milvus-Instanzen hinweg zu bewahren.
Inkrementelle Datenreplikation: Erfasst und repliziert Änderungen, wie Einfügungen und Löschungen, von der Quell-Milvus- zur Zielinstanz.
Aufgabenverwaltung: Benutzer können CDC-Aufgaben mithilfe von OpenAPI erstellen, verwalten und löschen, um sie in verschiedene Workflows zu integrieren.
Integration mit zukünftigen Systemen: Es gibt Pläne, die Unterstützung für die Integration mit Stream-Processing-Systemen zu erweitern.
CDC auf Milvus mit Kafka
Während Milvus-CDC ausdrücklich auf Milvus zugeschnitten ist, bietet die Integration von Milvus mit Apache Kafka einen weiteren Ansatz für CDC. Kafka ist ein zentraler Hub, der Datenänderungen aus verschiedenen Quellen mithilfe von CDC-Tools wie dem Kafka Sink connector erfasst und weitergibt. Diese Änderungen werden anschließend in Milvus aufgenommen, um die Vektordatenbank mit den neuesten Embeddings oder Feature-Vektoren auf dem aktuellen Stand zu halten.
Um Kafka mit Milvus zu verbinden, können Sie dieser Anleitung folgen: Kafka mit Milvus verbinden.
Rolle von CDC in verteilten Datenbanken und Cloud-Native-Anwendungen
Da Unternehmen verteilte Datenbanken und Cloud-Native-Anwendungen einführen, um große, geografisch verteilte Workloads zu bewältigen, spielt CDC eine entscheidende Rolle bei der nahtlosen Datensynchronisierung über diese komplexen Systeme hinweg.
Datensynchronisierung über verteilte Systeme hinweg: In verteilten Datenbanken werden Daten oft über mehrere Knoten oder Regionen verteilt, um Leistung und Skalierbarkeit zu verbessern. CDC propagiert diese auf einem Knoten vorgenommenen Änderungen sofort an andere, um die Konsistenz im gesamten System aufrechtzuerhalten.
Echtzeit-Datenaustausch in Cloud-Native-Architekturen: Cloud-native Anwendungen stützen sich häufig auf microservices, jeweils mit eigener Datenspeicherung. CDC ermöglicht es diesen Diensten, Echtzeit-Updates zu teilen, ohne auf aufwendige Batch-Prozesse angewiesen zu sein, um ereignisgesteuerte Architekturen zu unterstützen.
Replikation für hohe Verfügbarkeit und Disaster Recovery: Verteilte Systeme verwenden häufig Datenreplikation für hohe Verfügbarkeit. CDC erfasst und repliziert Änderungen auf Backup-Knoten oder Failover-Systeme.
Optimierung von Datenpipelines: In Umgebungen, in denen mehrere Systeme von gemeinsam genutzten Datensätzen abhängen, bietet CDC einen Mechanismus, um Echtzeitänderungen in Analyseplattformen, Data Lakes oder Message Queues einzuspeisen.
Anwendungen von CDC in Vektordatenbanken
Hier sind spezifische Anwendungsfälle von CDC, insbesondere in KI-Anwendungen, die mit einer Vektordatenbank arbeiten:
Semantische Suche: CDC aktualisiert die Vektordatenbank mit den neuesten Embeddings, wodurch semantische Suchsysteme genaue und relevante Ergebnisse liefern können. Beispielsweise kann eine Unternehmenssuchmaschine präzise Antworten auf Basis von Echtzeit-Updates für Dokument- oder Abfrage-Embeddings liefern.
Empfehlungssysteme: Vektordatenbanken verwenden Embeddings, um personalisierte Empfehlungen zu erzeugen. CDC streamt Echtzeitänderungen, wie neues Nutzerverhalten oder Produktaktualisierungen, sodass sich Empfehlungssysteme schnell an sich entwickelnde Daten anpassen.
Betrugserkennung: In Finanzsystemen werden Embeddings aus Transaktionsdaten kontinuierlich in einer Vektordatenbank aktualisiert. CDC stellt sicher, dass diese Updates in Echtzeit gestreamt werden, um ungewöhnliche Aktivitäten sofort zu erkennen und potenziellen Betrug zu kennzeichnen.
Bild- und Videoerkennung: Für Anwendungen wie das Tagging oder das Finden visuell ähnlicher Inhalte hält CDC Vektor-Embeddings, die aus Bildern oder Videos generiert werden, in der Datenbank aktuell. Dies ermöglicht genaue und schnelle Ergebnisse für Echtzeit-Anwendungsfälle, wie Social-Media-Moderation oder visuelle Suche im E-Commerce.
Chatbots und virtuelle Assistenten: CDC hilft RAG-basierten LLM-Chatbots, Echtzeit- und präzise Antworten bereitzustellen. Beispielsweise werden Embeddings, die Live-Nutzerinteraktionen oder aktualisierte Wissensdatenbanken repräsentieren, sofort erfasst und aktualisiert, was die Leistung des Chatbots verbessert.
Anomalieerkennung: Die CDC ist in der Cybersicherheit hilfreich, wo ungewöhnliche Muster im Netzwerkverkehr oder in Systemprotokollen sofortige Aufmerksamkeit erfordern.
Vorteile von CDC
CDC bietet erhebliche Vorteile für moderne Datenarchitekturen, damit diese effizient arbeiten und fundierte Entscheidungen treffen können. Hier sind die wichtigsten Vorteile:
Echtzeit-Einblicke: CDC stellt die aktuellsten Daten bereit, um schnelle Entscheidungsfindung zu unterstützen. Daher können Unternehmen Leistung und Trends sofort überwachen.
Reduzierte Datenlatenz: Beseitigt Verzögerungen, die durch traditionelle Batch-Verarbeitung verursacht werden. Da Änderungen nahezu sofort systemübergreifend widergespiegelt werden, verbessern sie die Reaktionsfähigkeit in Anwendungen, die von synchronisierten Daten abhängen.
Skalierbarkeit in großen Systemen: Es verarbeitet große Mengen an Datenänderungen und eignet sich daher für groß angelegte Datenbanken und verteilte Umgebungen.
Nahtlose Datenreplikation und Migration: Diese Funktion erleichtert die Echtzeit-Datenreplikation zwischen Systemen für hohe Verfügbarkeit, Disaster Recovery und Lastverteilung. Sie vereinfacht außerdem Datenbankmigrationen durch synchronisierte Daten während Übergängen mit minimaler Ausfallzeit.
Unterstützung für ereignisgesteuerte Architekturen: Betreibt ereignisgesteuerte Anwendungen, indem nachgelagerte Workflows oder Prozesse auf Grundlage von Datenänderungen ausgelöst werden. Daher verbessert es die Automatisierung und Reaktionsfähigkeit in Geschäftsprozessen.
Datengenauigkeit und -konsistenz: Alle verbundenen Systeme verfügen über konsistente und genaue Daten, wodurch Fehler und Inkonsistenzen reduziert werden. Daher bietet es eine zuverlässige Grundlage für die Entwicklung robuster datengetriebener Lösungen.
Herausforderungen bei der Implementierung von CDC
Die Implementierung von CDC kann komplex sein, und Unternehmen müssen mehrere Herausforderungen bewältigen, um effiziente und zuverlässige Abläufe sicherzustellen. Zu den wichtigsten Hürden gehören:
Performance-Overheads: Das Erfassen und Verarbeiten von Änderungen in Echtzeit kann eine zusätzliche Belastung für die Datenbank darstellen, die die Leistung primärer Anwendungen beeinträchtigt. Außerdem können ressourcenintensive Methoden wie Trigger oder häufige Abfragen die Antwortzeiten der Datenbank verschlechtern. Die Balance zwischen Geschwindigkeit, Genauigkeit und Zuverlässigkeit erfordert ein optimiertes Pipeline-Design.
Umgang mit Schemaänderungen: Änderungen am Datenbankschema, wie das Hinzufügen von Spalten, das Ändern von Datentypen oder das Anpassen von Tabellenstrukturen, können CDC-Pipelines unterbrechen.
Netzwerk- und Speicheraspekte: Kontinuierliches Datenstreaming in CDC erfordert ausreichende Speicherkapazität und effiziente Komprimierungstechniken, um ausufernde Kosten zu vermeiden. Die Zunahme des Netzwerkverkehrs kann die Bandbreite belasten, insbesondere in geografisch verteilten Systemen.
Datenintegrität in der CDC-Pipeline: Ausfälle oder Inkonsistenzen in der Pipeline können die Genauigkeit nachgelagerter Systeme beeinträchtigen. Der Umgang mit Ereignissen außerhalb der Reihenfolge und das Lösen von Konflikten in verteilten Umgebungen kann zusätzliche Komplexität verursachen.
Tool-Kompatibilität und Anbieterbindung: Einige CDC-Lösungen sind an bestimmte Datenbanken oder Technologien gebunden, wodurch die Flexibilität in heterogenen Umgebungen eingeschränkt wird. Der Wechsel von Tools oder das Upgrade von Systemen kann eine Neuentwicklung von CDC-Prozessen erfordern.
Sicherheits- und Compliance-Risiken: Das Streaming sensibler Daten in Echtzeit erfordert robuste Verschlüsselung und Zugriffskontrollen, um unbefugten Zugriff zu verhindern. Die Einhaltung von Datenschutzvorschriften wie GDPR oder CCPA kann die CDC-Implementierung erschweren.
Tools und Frameworks für CDC
Für die Implementierung von CDC stehen mehrere Tools und Frameworks zur Verfügung, die jeweils über einzigartige Funktionen verfügen, die auf spezifische Anwendungsfälle zugeschnitten sind. Hier ist eine Liste beliebter Optionen:
Debezium**: Eine Open-Source-CDC-Plattform, die auf Apache Kafka basiert. Debezium unterstützt verschiedene Datenbanken wie MySQL, PostgreSQL, MongoDB und SQL Server. Sie ist ideal für Echtzeit-Datenstreaming und die Integration mit ereignisgesteuerten Architekturen.
Oracle GoldenGate: Eine robuste CDC-Lösung auf Unternehmensniveau von Oracle. GoldenGate unterstützt leistungsstarke Datenreplikation und Echtzeit-Integration über heterogene Datenbanken hinweg. Es wird häufig für Disaster Recovery und Migration eingesetzt.
AWS Database Migration Service (DMS): ****Ein vollständig verwalteter Service von Amazon, der CDC für verschiedene Datenbanken unterstützt, sowohl On-Premises als auch in der Cloud. Er vereinfacht Datenmigration und -replikation, ohne erheblichen Overhead zu erfordern.
Qlik Replicate: Früher bekannt als Attunity Replicate, unterstützt Qlik Replicate CDC für eine breite Palette von Datenbanken und Dateisystemen. Es ist für schnelle, skalierbare Datenreplikation und Integration in Analyseplattformen konzipiert.
Confluent Kafka Connect: Als Teil des Confluent-Ökosystems bietet Kafka Connect CDC-Funktionen zum Streamen von Datenänderungen in Kafka-Themen. Es integriert sich außerdem nahtlos in die Kafka-Plattform für die Ereignisverarbeitung in Echtzeit.
Fazit
CDC spielt eine entscheidende Rolle in modernen Datensystemen durch Echtzeit-Updates und Integration über Plattformen hinweg. Durch die Behebung der Einschränkungen der Batch-Verarbeitung unterstützt CDC Echtzeit-Analysen, ereignisgesteuerte Architekturen und nahtlose Datensynchronisierung. Tools wie Apache Kafka verbessern CDC zusätzlich, indem sie Änderungen in nachgelagerten Systemen optimieren, einschließlich Vektordatenbanken wie Milvus. Dies hilft Unternehmen, unstrukturierte Daten zu verarbeiten, den Betrieb zu skalieren und reaktionsschnelle Anwendungen zu erstellen.
Verwandte Ressourcen
- Was ist Change Data Capture (CDC)?
- Entwicklung der Datenintegration: Die Rolle von CDC
- Wie funktioniert Change Data Capture?
- CDC mit Milvus: Echtzeit-Datenintegration für Vektordatenbanken
- Rolle von CDC in verteilten Datenbanken und Cloud-Native-Anwendungen
- Anwendungen von CDC in Vektordatenbanken
- Vorteile von CDC
- Herausforderungen bei der Implementierung von CDC
- Tools und Frameworks für CDC
- Fazit
- Verwandte Ressourcen
Inhalte
Kostenlos starten, einfach skalieren
Testen Sie die vollständig verwaltete Vektordatenbank, die für Ihre GenAI-Anwendungen entwickelt wurde.
Zilliz Cloud kostenlos ausprobieren