




How Biomap Transforms Life Sciences Discovery at Scale with AI-Powered Vector Search Using Milvus
22× Faster
Protein Searches with reduced query times from 10–20 minutes to under one minute.
50B+
Sequence Scale expanded from hundreds of millions to tens of billions of biological sequences.
Real-Time Discovery
Sub-second responses for complex biological queries in RAG workflows.
Cross-Modal Integration
Unified proteins, DNA, RNA, text, and cellular data into a single searchable framework.
Milvus has become the bridge that connects our multi-modal foundation models with real-world applications. It's not just about performance – it's about enabling entirely new approaches to biological discovery that were previously impossible.
Xiaoming Zhang
About Biomap
Biomap is a leading life sciences AI company focused on building AI models that accelerate discovery in drug development, synthetic biology, and medical research. At the core of its platform is xTrimo, a family of large-scale foundation models purpose-built for biology. Scaling up to 210 billion parameters, xTrimo unifies proteins, DNA, RNA, cells, molecules, and scientific text into a single framework, delivering predictions and insights that traditional methods cannot match.
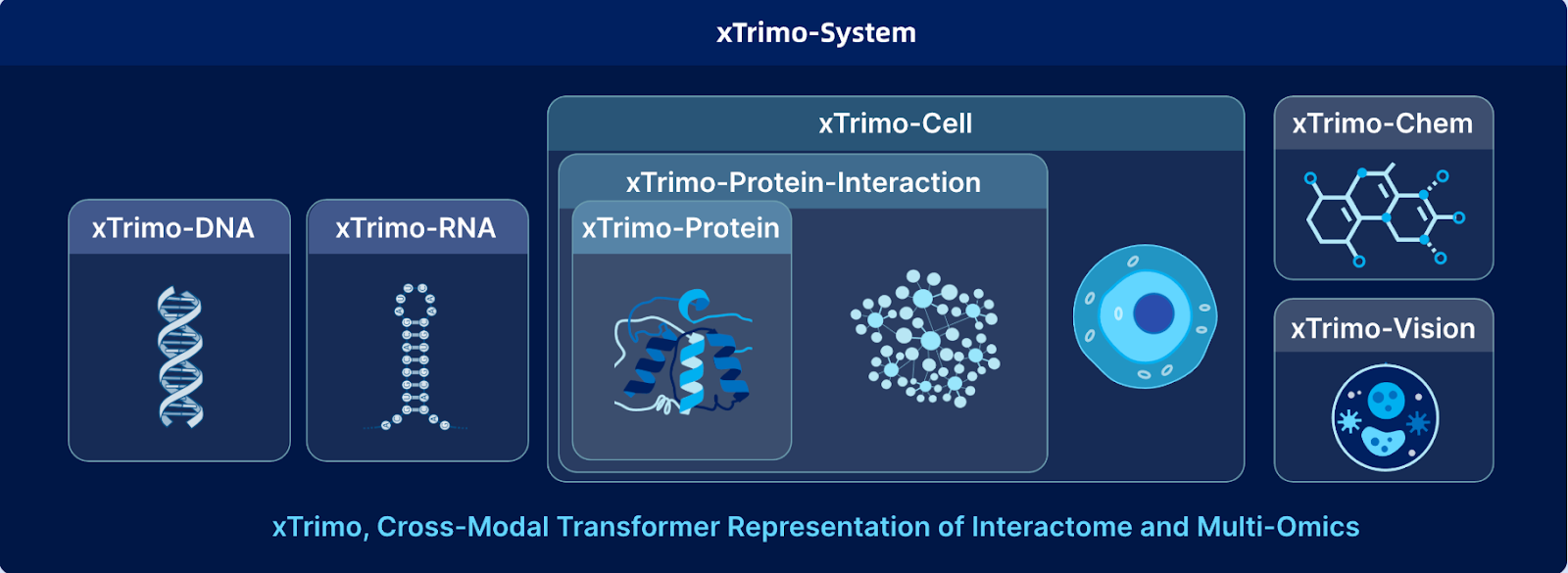
Achieving this capability required overcoming technical barriers, including noisy biological data, highly diverse formats, and the need to search across billions of sequences in real-time. Biomap addressed these challenges by developing custom embedding models for biological entities and deploying advanced data infrastructure, such as Milvus Vector Database, to enable fast and accurate retrieval at scale. With this foundation, researchers can now accelerate breakthroughs across various fields, including immunology, neurology, oncology, and the treatment of rare diseases.
Technical Barriers to Scaling Biological AI
As Biomap expanded its AI capabilities, the team ran into several bottlenecks that traditional tools could not overcome.
1. Slow Protein Search
Biomap’s protein structure prediction pipeline previously relied on Multiple Sequence Alignment (MSA), which required 10–20 minutes to return a single result. While acceptable for small-scale research, this delay was impractical for production workloads, especially when scaling to hundreds of millions—or even billions—of sequences.
2. Multi-Modal Data Complexity
Biological data inherently comes in many forms—proteins, DNA, RNA, cellular imaging, and even text. Traditional search methods were unable to effectively bridge these modalities, thereby missing the kind of cross-modal insights that are crucial for understanding complex biological systems.
3. Speed vs. Accuracy Dilemma
In biomedical research, minor errors can have major consequences. Biomap’s RAG-based discovery assistant needed both sub-second query responses for interactivity and research-grade accuracy for scientific reliability. However, most solutions forced a trade-off between speed and precision.
4. Specialized Data Requirements
Biological data has unique characteristics requiring custom indexing strategies, domain-specific embedding models, and optimization tuned for scientific workloads—capabilities that off-the-shelf solutions couldn't provide.
5. Diverse Performance Demands
Different Biomap use cases had very different needs: conversational assistants required instant answers, protein prediction could tolerate minutes per query but needed efficient batch processing, and foundational model training demanded high-throughput data pipelines. Managing these diverse requirements within a single unified infrastructure proved especially challenging.
Why Biomap Chose Milvus for Powering Biological AI at Scale
Biomap quickly realized that scaling its AI workloads would require a purpose-built vector search platform. The team first turned to Faiss, a popular vector search library, for small-scale proof-of-concepts. While Faiss performed well in early experiments, it failed when pushed with production workloads, unable to meet the scale, reliability, and flexibility requirements of real-world life sciences applications. After testing multiple alternatives, the team found that Milvus was the only solution that checked every box due to the following factors:
Open Source Flexibility: Life sciences data is highly specialized, often requiring custom indexing and algorithms tailored to biological use cases. Milvus’s open-source design gave Biomap the freedom to adapt and extend the system without constraints. As Xiaoming Zhang, VP of Technology at Biomap, explained, “If it’s not open source, there’s likely no room for such customizations, which doesn’t fit our scenarios.”
Production-Ready Stability: For production deployments, Biomap required a mature platform supported by an active user base, particularly among enterprise biotech companies. With a proven track record across industries and strong community adoption among biotech companies, Milvus offered the reliability and ecosystem support that Biomap required.
Comprehensive Feature Set: Milvus supports a wide range of index types and hybrid search capabilities, enabling the optimization of searches across proteins, DNA, RNA, text, and other modalities—all within a single system.
Performance at Scale: From interactive assistants to large-scale protein searches, Biomap needed infrastructure that could handle both sub-second queries and massive batch jobs. Milvus’s horizontally scalable architecture ensured consistent performance across workloads, regardless of their size and scale.
Community and Partnership: The Biomap team also valued Milvus’s active open-source community and the long-term partnership potential with Zilliz, the company behind Milvus.
This combination of technical depth, ecosystem maturity, and future-facing support made Milvus the clear choice for Biomap’s production infrastructure.
How Biomap Uses Milvus to Power Its Biological AI Services
Biomap deployed Milvus across three critical use cases, each addressing a unique scientific challenge and together forming the backbone of their biological AI platform.
AI Discovery Assistant (RAG)
At the heart of Biomap’s research workflows is a discovery assistant powered by advanced Retrieval-Augmented Generation (RAG). Built on LangGraph for orchestration, the assistant pulls data from vast collections of scientific literature, patents, and specialized biological databases. Such data, which is rich in formulas, protein structures, and domain-specific notation, is then converted into vector embeddings and stored in Milvus.
Milvus performs hybrid vector and full-text search to deliver the most accurate results for queries within sub-seconds. This enables researchers to search across specialized biological knowledge and receive precise answers in real time rather than spending hours sifting through the literature.
Protein Structure Prediction at Scale
Biomap also reinvented the traditional protein search pipeline by replacing slow Multiple Sequence Alignment (MSA) methods with vector search. Their proprietary protein foundation models generate high-dimensional embeddings, which are stored and queried in Milvus. This new architecture expanded their search scale from hundreds of millions to more than 5 billion protein sequences, enabling discoveries that were previously out of reach. Performance also improved dramatically: queries that once took 10–20 minutes now complete in under a minute, with higher accuracy thanks to AI-driven similarity metrics.
Cross-Modal Sample Generation for Model Training
To advance multi-modal foundation model development, Biomap relies on Milvus to connect data across biological modalities. Researchers can, for example, retrieve cellular images linked to specific protein sequences or align molecular-level and cellular-level data in a unified vector space. This capability supports sophisticated data augmentation and cross-modal association discovery, accelerating the training of models that bridge text, sequence, and image data.
Together, these applications show how Milvus enables Biomap to combine scale, accuracy, and speed across domains—from day-to-day discovery to cutting-edge biological model training.
Impact of Milvus on Biomap’s Platform
By adopting Milvus, Biomap achieved results that traditional infrastructure could not deliver, transforming both the speed and scope of their research.
Faster Searches at Billion-scale
Milvus’s high-performance indexing engine powered a 22× speedup in protein sequence searches. Queries that once took 10–20 minutes now return in under a minute, even at scales of 50 billion sequences. This represents a more than 10-fold increase in scale—from hundreds of millions to tens of billions of biological sequences—without sacrificing accuracy or reliability.
Smarter Biological Discovery
Milvus also changed how Biomap approaches discovery itself. Because search quality is directly tied to the performance of their foundation models, improvements in model accuracy translate immediately into better retrieval results. This creates a virtuous cycle: as the models evolve, the search engine powered by Milvus becomes more precise, unlocking scientific insights that static, alignment-based methods could never achieve.
Cross-Modal Breakthroughs
With Milvus, Biomap can now bridge molecular- and cellular-level data within the same vector space. This “flattening” of scale differences enables seamless cross-modal searches, supporting the training of their next-generation multi-modal foundation models. It’s a foundational step toward their long-term vision of building a comprehensive AI simulator for biology.
A Scalable Platform for Life Sciences
Ultimately, Milvus provides Biomap with the infrastructure to expand beyond internal research into broader life sciences applications. The same platform now supports customized knowledge bases and intelligent agents for pharmaceutical companies, hospitals, and synthetic biology firms—extending the benefits of fast, scalable biological AI across the entire ecosystem.
Looking Forward
Biomap’s success with Milvus has laid the groundwork for expansion across the entire life sciences ecosystem. The team is now expanding its platform to serve a range of stakeholders, including pharmaceutical companies that accelerate drug discovery, medical institutions that advance clinical research, synthetic biology firms that optimize organism design, and agricultural biotech companies that drive genetic improvements in crops. Each new use case builds on the same core infrastructure—vector search with Milvus—that makes complex biological data accessible and actionable at scale.
As Xiaoming noted, “Milvus has become the only technical choice for vector databases in our upcoming business expansion across the life sciences industry.”
This partnership goes beyond technical integration. It is creating a foundation for how biological discovery will be conducted in the future: faster, more precise, and capable of spanning modalities that were once siloed. As Biomap continues pursuing its vision of an “AI simulator for life,” Zilliz provides the vector database infrastructure that turns this ambition into reality, enabling breakthroughs that could transform both science and industry.
Milvus has become the only technical choice for vector databases in our upcoming business expansion across the life sciences industry.
Xiaoming Zhang