




Read AI Scales Conversational Intelligence with Milvus for Millions of Active Users

Sub 20-50ms
retrieval latency for millions of monthly users
5× speedup
in agentic search
Million-scale
active tenants support
Improved user experience
by powering a shift from reactive to proactive search
We've got millions of monthly active users and all of the underlying data when we're trying to go find related conversations, find updates to an action item, find referenced documents...Milvus serves as the central repository and powers our information retrieval among billions of records.
Rob Williams
Executive Summary
Read AI required a high-performance vector database to support enterprise-scale retrieval from unstructured communication sources, including meetings, chats, emails, and internal knowledge bases. By adopting Milvus as the backbone of its semantic search infrastructure, Read AI was able to index and query narrative-rich embeddings at scale, unlocking fast, accurate retrieval across billions of records.
Sub-20-50ms retrieval latency for millions of monthly users
Highly scalable to handle millions of active tenants
Major developer productivity gains
“We've got millions of monthly active users and all of the underlying data when we're trying to go find related conversations, find updates to an action item, find referenced documents...Milvus serves as the central repository and powers our information retrieval among billions of records.”--Rob Williams, Co-Founder and CTO at Read AI
About Read AI
Read AI is a leading productivity AI company helping millions of people spend more time on the work that matters most. Initially focused on reducing meeting fatigue, the company has evolved into a full-stack intelligence platform that also offers predictive next steps, enterprise search, and real-time coaching that integrates seamlessly with tools across calendars (Google Calendar, Outlook 365, Zoom Calendar), CRMs (Salesforce, HubSpot), collaboration platforms (Jira, Confluence, Notion), messaging apps (Slack, Microsoft Teams), notetaking tools (Google Docs, OneNote), email (Gmail, Outlook), and video conferencing (Zoom, Google Meet, Microsoft Teams). It ingests and contextualizes data from these sources, transforming passive interactions into structured, queryable, and actionable narratives.
Built with a consumer-first mindset, Read AI supports millions of users via a self-service model, operating at true internet scale with billions of conversation events processed across countless enterprises.
The Technical Challenge
Because of its breakneck growth, Read AI faced a fundamental challenge in organizing and retrieving unstructured communication data across a wide range of sources—from meetings and chats to CRM updates, calendars, email threads, and support tickets. Each source carries valuable signals but lives in silos, lacks consistent structure and is difficult to search effectively. The expectation: deliver intelligent, contextual outputs within 20 minutes of any interaction.
This required near-real-time data ingestion, transformation, and indexing across diverse formats. From well-structured internal meetings to sparse, third-party platforms like Slack, Gmail, and HubSpot. As usage grew, Read AI needed to support billions of records across millions of tenants, thousands of queries per second, and sub-20 - 50ms latency. Earlier solutions, including internally built stores and other vector databases such as Pinecone and Faiss, failed to meet these demands due to poor multi-tenancy support, limited filtering capabilities, or a lack of community responsiveness.
The Solution Architecture with Milvus
Read AI’s new architecture is designed to handle high-throughput, low-latency retrieval across diverse communication sources like Slack, Zoom, email, and Salesforce. These inputs pass through an embedding and narration layer that transforms raw data into structured narratives and sentiment-aware representations. Everything is stored in the Milvus vector database, effectively serving as the central repository for the information.
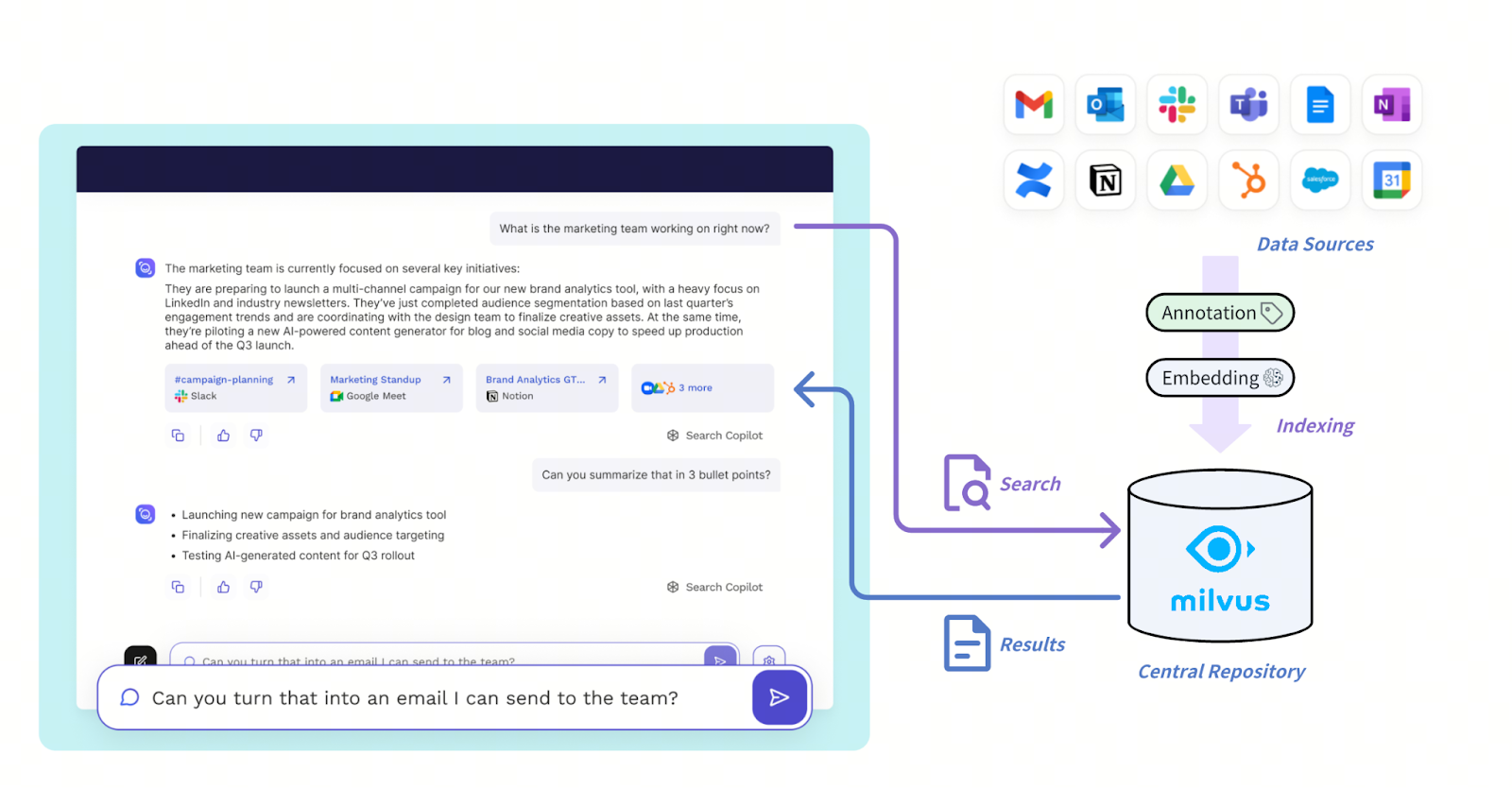 The Solution Architecture with Milvus
The Solution Architecture with Milvus
Figure: How Mivus supports the Read AI system
Read AI uses a filtered vector search that combines vector similarity with filtering based on structured metadata, for example, scoping queries to one-on-one meetings, specific employees, or time windows, thus enabling nuanced retrieval like “most disengaged sales calls” or “positive feedback in one-on-ones.” The optimized metadata filtering of Milvus is crucial for achieving sub-20-50ms latency at this scale.
"Milvus gives us a narrative-aware storage layer — not just text embeddings, but full context-aware search." — Rob Williams, Co-Founder and CTO at Read AI
Thanks to the native multi-tenancy support in Milvus, Read AI deploys a single Milvus cluster to serve millions of tenants efficiently. Queries are orchestrated through internal agent frameworks that analyze the search intention and route requests into Milvus, then post-process results for delivery via chat interfaces, summaries, or alerts. This architecture gives Read AI the scalability and flexibility to unify disparate content types while maintaining speed and precision, which are critical for real-time retrieval and retrospective analysis.
Technical Evaluation & Decision Process
Before adopting Milvus, the Read AI team evaluated several alternatives. FAISS was ruled out due to its lack of built-in multi-tenancy and limited filtering capabilities. Pinecone didn’t offer the flexibility needed to support Read AI’s search pattern and scale. A fully self-hosted, in-house solution was also considered, but couldn’t meet the scalability and maturity requirements of their use case. Milvus stood out based on several key factors:
The ability to scale to millions of users and billions of records
Consistent sub-20-50ms latency on large vector collections
Support for hybrid search workflows
Tenant-level isolation
The developer experience was another deciding factor, with clear documentation, responsive maintainers, and hands-on engineering support, especially during their proof-of-concept. The PoC phase demonstrated a fast turnaround on test workloads and provided real-time debugging assistance from the Milvus team, which gave Read AI the confidence to transition to production.
Results and Benefits of Choosing Milvus
Since deploying Milvus and alongside the company’s launch of its enterprise search tool Search Copilot, Read AI has achieved a 5× speedup in agentic search across diverse data sources, maintaining consistent retrieval latency of around 20- 50ms, even when handling queries with complex filters. The platform smoothly onboarded millions of individual user accounts into a giant cluster without disruption, demonstrating the robustness of Milvus’s distributed architecture and multi-tenancy capability.
Milvus powers a unified search layer across all communication channels—meetings, chat, email, and CRM. Elastic scaling simplifies the operation to handle enterprise cohorts or traffic spikes. Features like bulk import lead to a smooth experience when onboarding large amounts of historical data as new enterprises sign up for the service.
More importantly, Milvus powers a shift from reactive to proactive search: surfacing relevant insights, action items, and risks before users even ask, thanks to low-latency vector search over dynamic, multimodal contexts. This capability not only improves user experience but also unlocks new business opportunities as Read AI continues to focus on expanding the platform with continuous advancements in predictive recommendations and next steps.
"What we wanted was to push intelligence to the user before they even asked. Milvus is what made that viable." —Rob Williams, Co-Founder and CTO at Read AI
These technical wins translate directly into business value: free-tier users receive meaningful insights within minutes, driving retention, while enterprise customers benefit from deeper knowledge retrieval and long-term context, enhancing user trust and supporting premium upsell opportunities.
Developer & Engineering Insights
Lessons from implementation:
Structured annotation can power richer downstream LLM outputs
Vector search needs to maintain its speed, even with structured metadata filtering, to keep up the search user experience
Multi-tenant isolation and dynamic scaling are non-negotiable at the consumer scale
The team runs ongoing experiments, tracking query performance, user satisfaction, and behavioral metrics to continuously refine how agents search, filter, and rank results.
Read AI processes conversational data with not only embedding models, but also a unique narration layer. This semantic abstraction goes beyond transcripts to capture tone, intent, and key events like deal progression or engagement drop-off. As a result, users can search natural language narratives, such as "who was disengaged during the demo," rather than just matching keywords.
Roadmap
Looking ahead, Read AI is focused on improving how it balances real-time and offline workloads, with plans to build more dynamic orchestration between live streaming data and longer-term storage. They’re exploring the use of Milvus’s upcoming Vector Lake to reduce search costs by shifting offline queries with relaxed latency expectations to a warehouse-style layer backed by object storage.
Another key area of development is automated detection of knowledge gaps — identifying when critical information is missing or disconnected — and proactively surfacing insights to users before they ask. All of these enhancements support Read AI’s long-term vision: to build an “action engine” for the enterprise — a context-aware, always-on AI-powered platform that intelligently empowers knowledge workers across all communication channels.
By storing conversational context and historical insight in Milvus, Read AI extends the availability of institutional knowledge, surfacing critical information even when the original participant is offline or no longer at the company.
Conclusion
Read AI’s journey from a meeting analytics tool to a full-scale intelligence platform for the masses required an infrastructure capable of handling massive scale, heterogeneous data, and complex, real-time query demands. Milvus proved to be the right choice — not just for its raw performance and scalability, but for its flexibility in supporting annotated embeddings, metadata filtering, and multi-tenant isolation.
With Milvus as the foundation of its vector search infrastructure, Read AI delivers fast, reliable, and deeply contextual results and recommendations to millions of users. As they expand toward building an always-on, intelligent action engine for the enterprise, Milvus continues to support their need for cost-efficiency, architectural flexibility, and future-proof scale, proving that a well-designed vector database is more than just storage; it’s the backbone of modern information understanding.
What we wanted was to push intelligence to the user before they even asked. Milvus is what made that viable.
Rob Williams