




Why and How to Migrate from Self-Hosted Milvus to Zilliz Cloud
Milvus is the most popular open-source vector database, trusted for its high performance and horizontal scalability. If you’ve been using Milvus, you already know how efficiently it handles similarity search and large-scale embedding workloads.
But as your datasets expand and your applications grow more complex, maintaining your own Milvus deployment can become increasingly challenging — from managing infrastructure and scaling clusters to ensuring consistent performance.
That’s where Zilliz Cloud comes in. As the fully managed cloud service for Milvus, it delivers up to 10x faster performance and provides a production-ready environment that takes care of hosting, scaling, and optimization with zero hassle — so your team can focus on building AI applications instead of managing infrastructure.
In this post, we’ll compare Milvus and Zilliz Cloud, and walk you through how to migrate from Milvus to Zilliz Cloud smoothly and start taking full advantage of your vector data — without the operational overhead.
Milvus vs. Zilliz Cloud
Milvus and Zilliz Cloud share the same foundation but are optimized for different goals.
Milvus, the open-source vector database, gives developers complete control and flexibility. Powered by Knowhere, its vector execution engine, Milvus integrates top-performing libraries like Faiss, Hnswlib, and Annoy, enhancing them with SIMD acceleration, CPU/GPU hybrid execution, and binary vector support. It automatically selects the best instruction sets (SSE, AVX2, AVX512) and supports multiple similarity metrics such as Euclidean, Inner Product, Cosine, Jaccard, Hamming, and BM25.
This makes Milvus an excellent choice for teams that want fine-grained control over vector indexing, experiment with configurations, and have the DevOps resources to manage clusters, scaling, and upgrades.
Zilliz Cloud, by contrast, takes Milvus to the next level. Built on top of Milvus, Zilliz Cloud is a fully managed, production-grade vector database service designed to eliminate operational complexity while unlocking higher performance and scalability.
At its core, Zilliz Cloud runs on Cardinal, a commercial-grade, self-optimizing vector search engine that delivers up to 10x faster performance than Milvus. With AutoIndex, it automatically selects and tunes indexing algorithms such as HNSW, IVF, and DiskANN to achieve over 96% recall without manual configuration.
But beyond speed, Zilliz Cloud offers a comprehensive platform for building and scaling AI applications:
Elastic Scaling and Cost Efficiency: Effortlessly scale compute and storage resources based on demand. Enjoy serverless autoscaling, one-click deployment, and pay-as-you-go pricing that adapts to your workload.
Advanced AI Search Capabilities: Perform vector, full-text, and hybrid (dense + sparse) search with metadata filtering and dynamic schemas, enabling complex, multimodal retrievals.
Natural Language Querying: With built-in MCP server support, developers can query data using natural language instead of manually crafting API calls.
Enterprise-Grade Reliability and Security: Zilliz Cloud provides 99.95% uptime SLA, multi-AZ redundancy, and certifications like SOC 2 Type II, ISO 27001, and GDPR compliance. It also supports RBAC, BYOC, audit logs, and encryption for enterprise data protection.
Global Reach: Deploy across AWS, GCP, and Azure, ensuring sub-100ms latency worldwide and seamless access for distributed teams.
Effortless Migration: Move from Milvus, Pinecone, Qdrant, Weaviate, Elasticsearch, or PostgreSQL using built-in migration tools — no schema rewrites or downtime required.
In short, Milvus gives you flexibility and control. Zilliz Cloud gives you performance, simplicity, and global scalability — without the maintenance burden.
Get Ready for Migration
Before you migrate to Zilliz Cloud, there are a few steps to take to make sure everything goes smoothly:
Check your current Milvus setup: Take note of your Milvus version (it must be 2.3.6 or later to support migration), your deployment type (such as Docker or Kubernetes), and any custom settings you’ve configured.
Back up your data: Always create a full backup of your Milvus data before migrating. This step is critical to avoid any data loss.
Choose your migration method: Depending on your database size and needs, you can migrate through endpoints (best for smaller, single-database moves) or using backup files (recommended for larger migrations).
For this guide, we used a standalone Milvus instance as the source. The default database includes one collection named migration_test, which contains 1,000 records.
How to Migrate Milvus to Zilliz Cloud
There are two methods of migrating from Milvus to Zilliz Cloud.
Method 1: Endpoint
Prerequisites:
Milvus:
Version: Milvus 2.3.6 or higher
Network: Must be accessible through the public internet
Authentication: If enabled, have your username and password ready
Zilliz Cloud:
User role: You must be an organization owner or project admin
Cluster resources: Make sure your Zilliz Cloud cluster has enough storage and compute capacity. You can estimate this using the CU Calculator.
Network access: Add Zilliz Cloud IP addresses to your allowlist (see the full list here)
Step-by-Step Migration:
- Open the Zilliz Cloud Console and start a new migration.
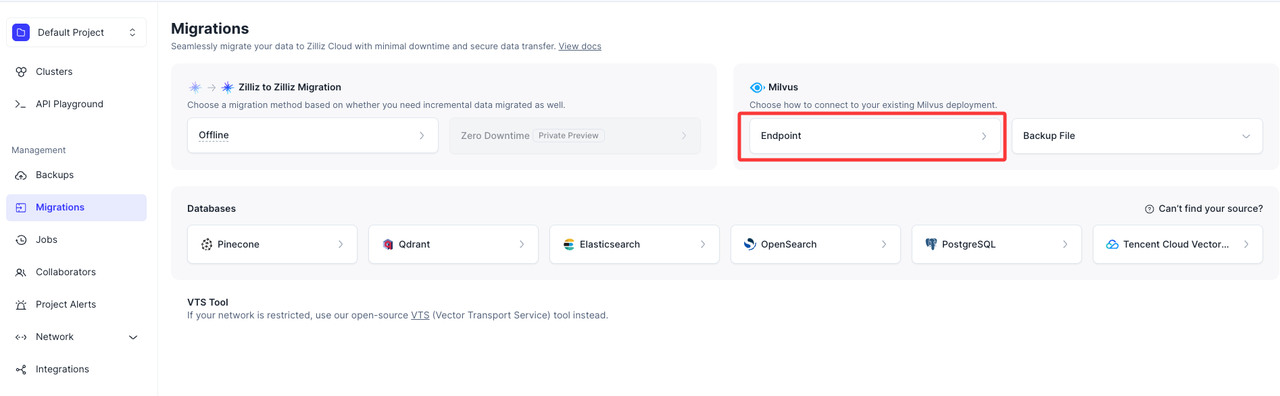
- Choose Endpoint as the migration method.
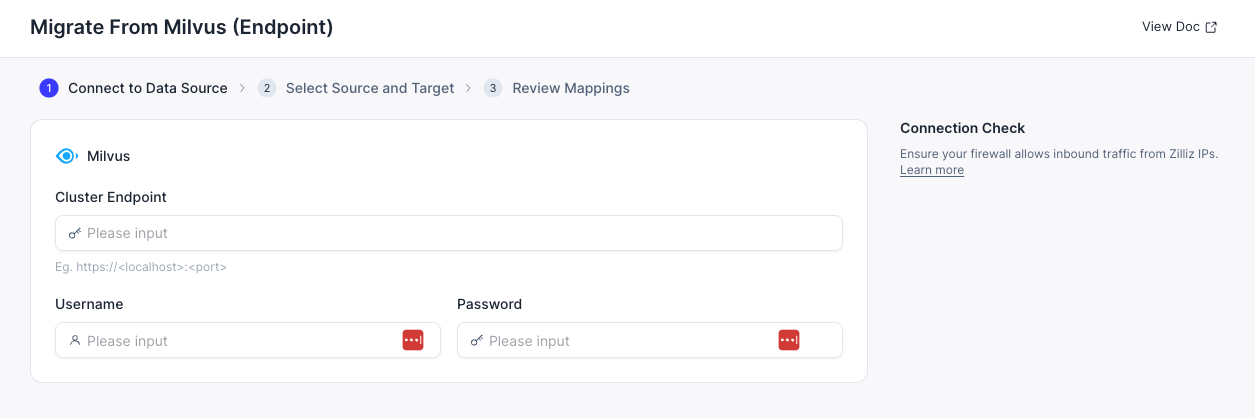
- Enter your Milvus endpoint URL, along with your username and password (if authentication is enabled).
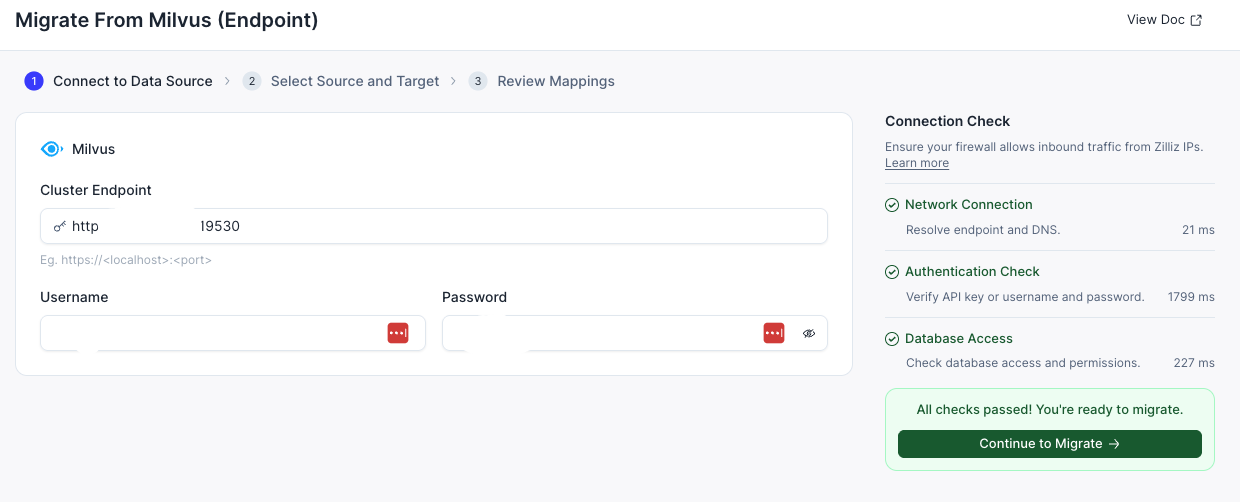
- Make sure the connection test passes.
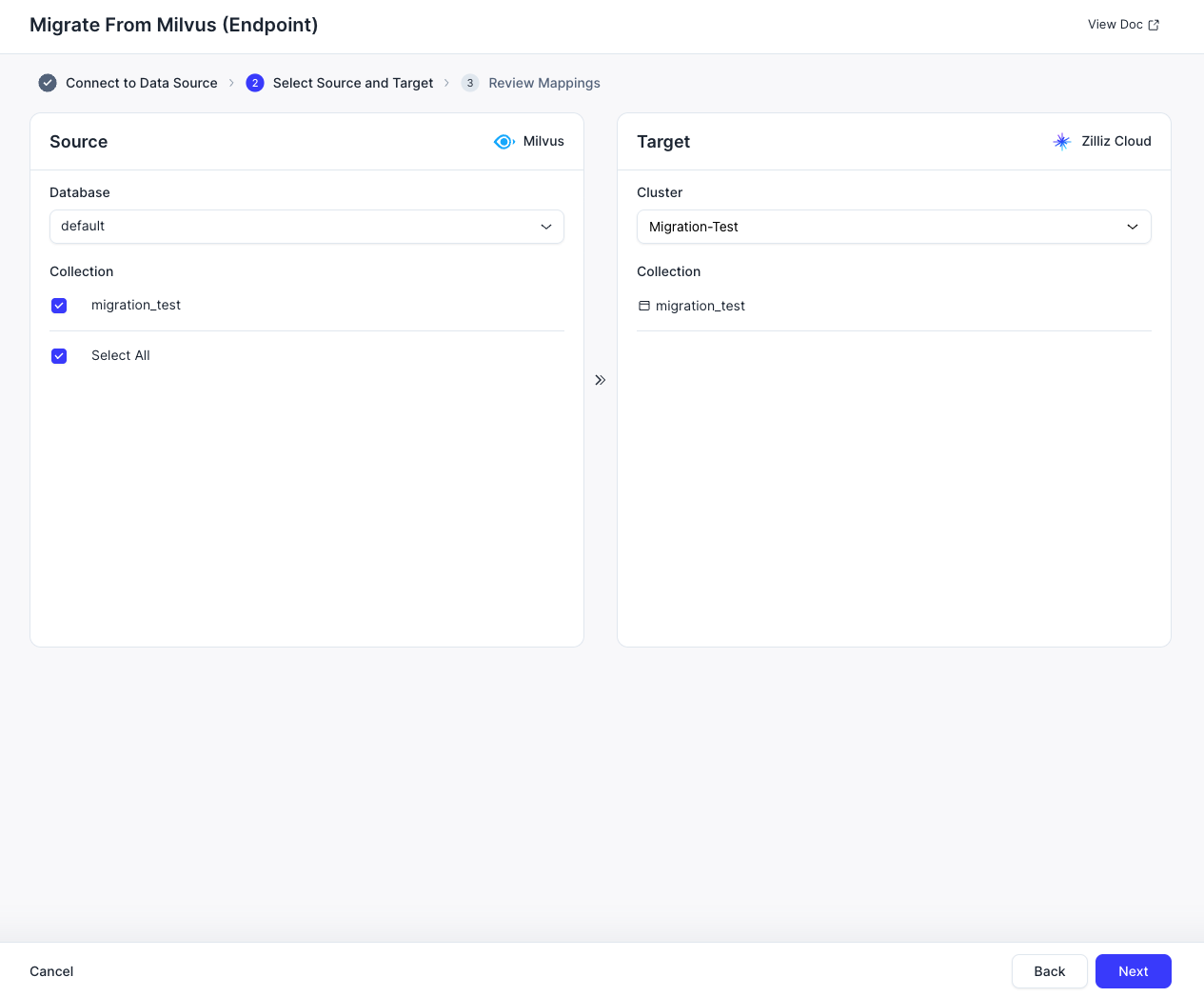
- Select the collection from your source Milvus database that you want to migrate, along with the target database instance and corresponding collection in Zilliz Cloud.
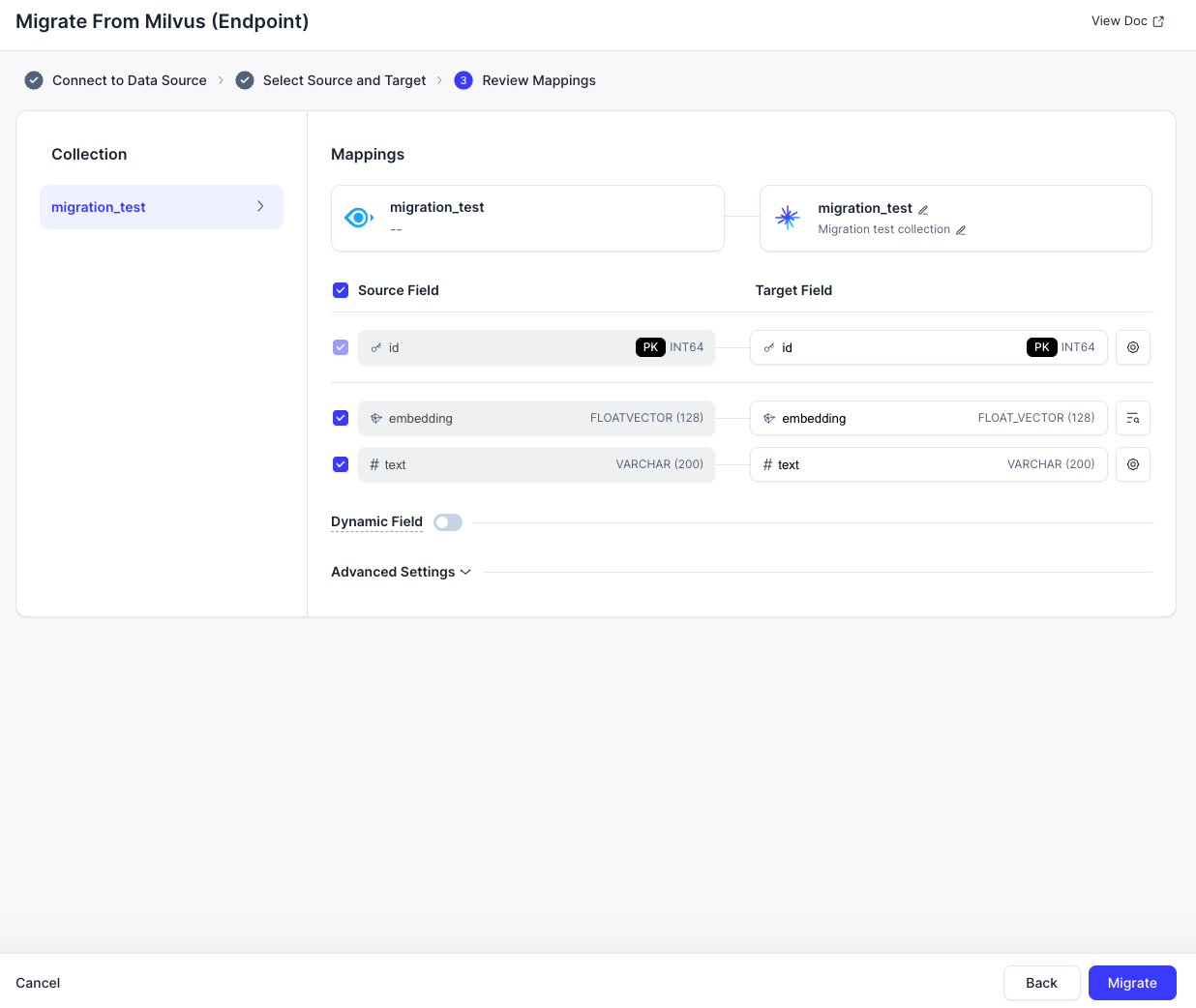
- Verify that all field mappings match correctly. Click Migrate to start the migration job.
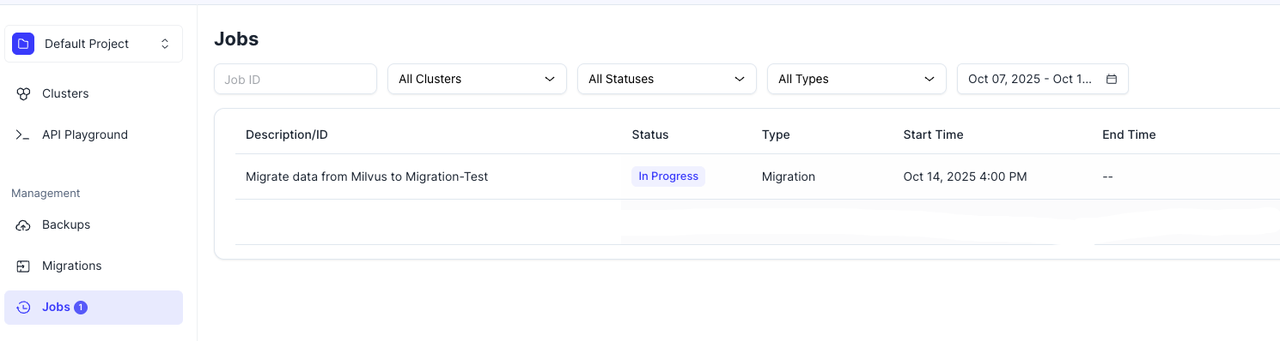
- Go to the Job Center to track progress. When the job status changes from “In Progress” to “Successful,” your migration is complete.

Final Checks After Migration:
- Manually load collections: To enable search and query operations, you’ll need to manually load the migrated collections in Zilliz Cloud.
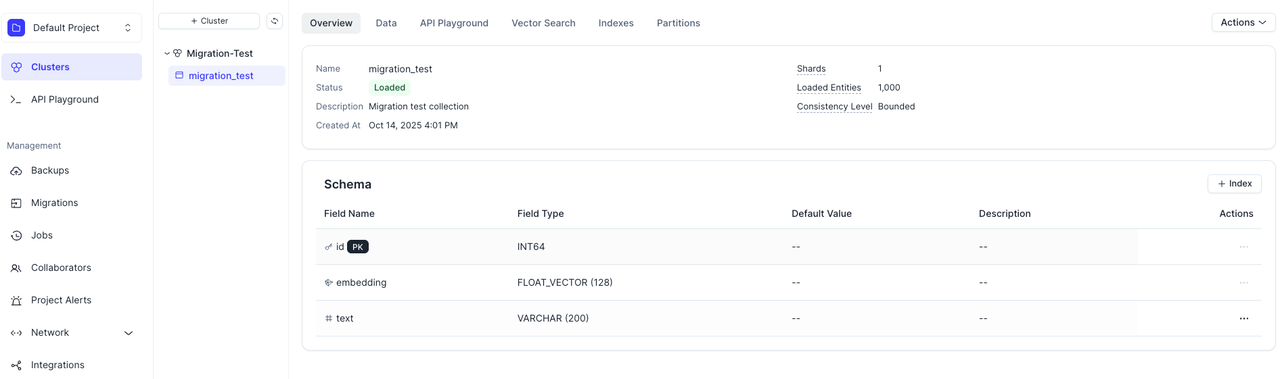
Verify data consistency: Check that the number of collections and entities in Zilliz Cloud matches your original Milvus instance. If you find any differences, you can rerun the migration.
Handle failed migrations: If a migration job fails, go to the Job Center in the Zilliz Cloud Console, cancel the job, and click View Details to review the error logs.
Method 2: Backup Files
Prerequisites:
Zilliz Cloud:
User role: You must be an organization owner or project admin
Cluster resources: Ensure your cluster has enough Compute Units (CUs) to store your data. You can estimate this using the CU Calculator.
Network access: Add Zilliz Cloud IP addresses to your allowlist (see the full list here)
Milvus:
- Backup files: You’ll need to prepare a Milvus backup file. The backup can be stored either locally or in object storage such as AWS S3 or MinIO.
How to Create and Upload Backup Files:
Download milvus-backup: Get the latest version of the milvus-backup
Create the configs Folder and Add backup.yaml
wget https://raw.githubusercontent.com/zilliztech/milvus-backup/main/configs/backup.yaml
In the same directory where your milvus-backup binary is located, create a folder named configs. Download the backup.yaml configuration file and save it into this folder.
Your directory structure should look like this:
workspace
├── milvus-backup
└── configs
└── backup.yaml
Customize backup.yaml: Open the backup.yaml file and review its configuration. Update fields such as milvus.address, milvus.port, and minio.address based on your environment.
Create a backup:
./milvus-backup --config backup.yaml create -n my_backup
Retrieve backup files:
./milvus-backup --config backup.yaml get -n my_backup
Check where your backup files are stored: Depending on your configuration, your backup files may be stored in different locations.
If using OSS (Object Storage Service): Your backup files are already stored in the OSS bucket defined by
minio.addressandminio.port.If using MinIO: You can download the backup files using either the MinIO Console or the
mc(MinIO Client) tool.
To download from the MinIO Console:
Log in to your MinIO dashboard.
Find the bucket specified in your
minio.address.Select the files inside the bucket and start downloading.
To download using the mc client:
# Configure your MinIO host
mc alias set my_minio https://<minio_endpoint> <accessKey> <secretKey>
# List all available buckets
mc ls my_minio
# Download files from a specific bucket
mc cp --recursive my_minio/<your-bucket-path> <local_dir_path>
Upload backup files to Zilliz Cloud: Once you’ve obtained the backup files, upload the subfolders inside your backup directory to Zilliz Cloud using the Zilliz Cloud Console.
backup
└── my_backup <= upload this folder
Step-by-Step Migration:
- Start the migration in the Zilliz Cloud.

Choose the backup file location based on where your backup files are stored.
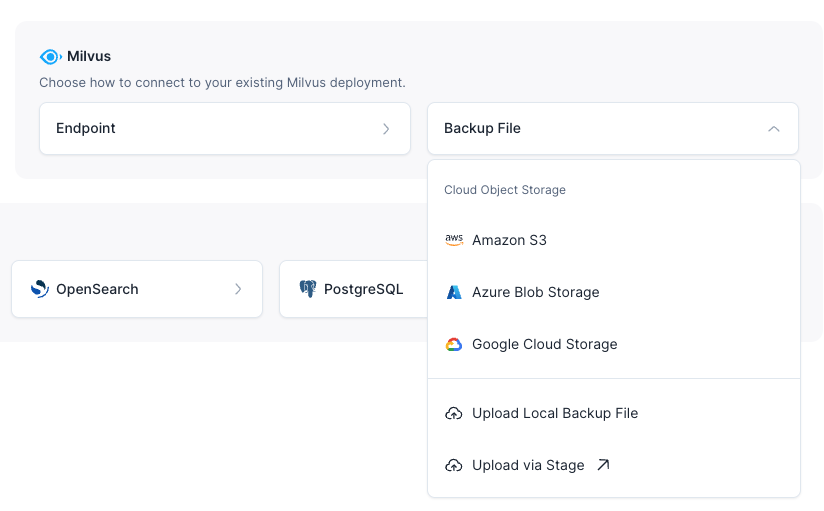
Select the backup folder.
Select the target database and collection in Zilliz Cloud where you want to restore the data.
- Go to the Job Center to track progress.
Final Checks After Migration:
Manually load collections: To enable search and query operations, you’ll need to manually load the migrated collections in Zilliz Cloud.
Verify data consistency: Check that the number of collections and entities in Zilliz Cloud matches your original Milvus instance. If you find any differences, you can rerun the migration.
Handle failed migrations: If a migration job fails, go to the Job Center in the Zilliz Cloud Console, cancel the job, and click View Details to review the error logs.
Best Practices for a Smooth Migration
To ensure your migration runs smoothly and your data integrity is maintained, keep these best practices in mind:
Verify data integrity: Before migrating, check that your backup files are complete and consistent.
Monitor progress: Keep an eye on the Job Center during migration so you can spot and resolve issues early.
Test your application: After migration, thoroughly test your application to confirm everything runs correctly on Zilliz Cloud.
The table below compares both migration methods. You can choose the one that best fits your needs.
| Migration Method | Best For | Advantages | Limitations |
|---|---|---|---|
| Via Endpoint | Migrating individual databases or small-scale deployments | Simple and straightforward; easy to manage fine-grained migrations | Can only migrate one database at a time; lower efficiency |
| Via Backup Files | Large-scale migrations or migrating multiple databases simultaneously | High efficiency; ideal for handling large datasets | Requires additional tools and storage setup; slightly more complex to operate |
Experience Zilliz Cloud Yourself
Migrating from self-hosted Milvus to Zilliz Cloud is more than just an infrastructure upgrade—it’s a step toward a faster, simpler, and more scalable future for your AI applications. Sign up for free and get $100 in credits to explore the world’s leading managed vector database firsthand.
In addition to Milvus, Zilliz Cloud also supports seamless migration from a wide range of sources — including Weaviate, Pinecone, Elasticsearch, OpenSearch, Amazon S3 Vectors, Qdrant, and PostgreSQL — with more integrations coming soon.
If you have any = questions about migration, check our documentation or contact us—we’re here to help you get the most out of Zilliz Cloud.

Keep Reading

Our Journey to 35K+ GitHub Stars: The Real Story of Building Milvus from Scratch
Join us in celebrating Milvus, the vector database that hit 35.5K stars on GitHub. Discover our story and how we’re making AI solutions easier for developers.

Vector Databases vs. Document Databases
Use a vector database for similarity search and AI-powered applications; use a document database for flexible schema and JSON-like data storage.

Introducing DeepSearcher: A Local Open Source Deep Research
In contrast to OpenAI’s Deep Research, this example ran locally, using only open-source models and tools like Milvus and LangChain.