




Using a Vector Database to Search White House Speeches
This article was originally published on The New Stack.
Campaign season is coming up for the U.S. presidential campaign. It’s a good time to look back at some of the speeches given by the Biden administration during his first two years in office. Wouldn’t it be great to search through some speech transcripts to learn more about the White House’s messaging about certain topics so far?
Let’s say we want to search the content of a speech. How would we do that? We could use semantic search. Semantic search is one of the hottest topics in artificial intelligence (AI) right now. It has become more important as we’ve seen the rise in popularity of natural language processing (NLP) applications like ChatGPT. Instead of repeatedly pinging GPT, which is both economically and ecologically expensive, we can use a vector database to cache the results (such as with GPTCache).
In this tutorial, we will spin up a vector database locally so we can search Biden’s speeches from 2021 to 2022 by content. The dataset that we use is “The White House (Speeches and Remarks) 12/10/2022” dataset which we found on Kaggle and made available to download via Google Drive for this example. A walkthrough notebook of this tutorial is available on GitHub.
Before we dive into the code, please make sure to download the prereqs. We need four libraries: PyMilvus, Milvus, Sentence-Transformers and gdown. You can get the necessary libraries from PyPi by running: pip3 install pymilvus==2.2.5 sentence-transformers gdown milvus.
Preparing the White House Speech Dataset
As with almost any AI/ML project based on real-world datasets, we first need to prepare the data. We use gdown to download the dataset and zipfile to extract it into a local folder. After running the code below, we expect to see a file titled “The white house speeches.csv” in a folder titled “white_house_2021_2022”.
import gdown
url = 'https://drive.google.com/uc?id=10_sVL0UmEog7mczLedK5s1pnlDOz3Ukf'
output = './white_house_2021_2022.zip'
gdown.download(url, output)
import zipfile
with zipfile.ZipFile("./white_house_2021_2022.zip","r") as zip_ref:
zip_ref.extractall("./white_house_2021_2022")
We use pandas to load and inspect the CSV data.
import pandas as pd
df = pd.read_csv("./white_house_2021_2022/The white house speeches.csv")
df.head()
When we take a look at the head of the data, what do you notice? The first thing I notice is that the data has four columns: a title, date time, location and speech column. The second thing is that there are null values. Null values aren’t always a problem, but they are for our data.

Cleaning the Dataset
Speeches without any substance (null values in the “Speech” column) are entirely useless to us. Let’s drop our null values and reexamine the data.
df = df.dropna()
df
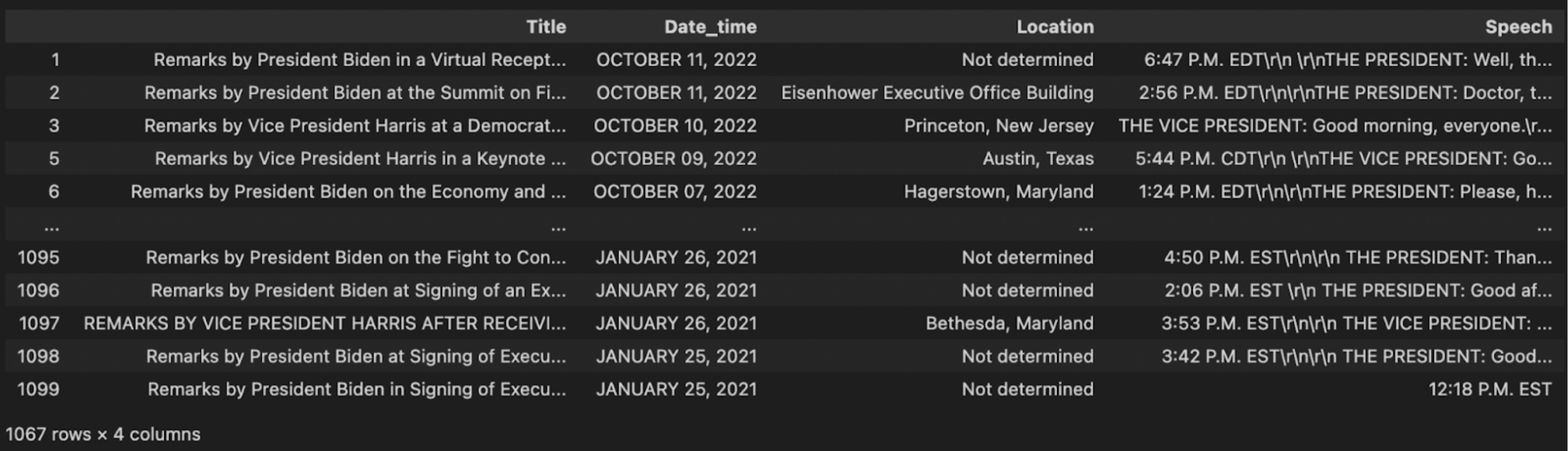
Now we see that there is actually a second problem that wasn’t immediately obvious from looking at just the head of the data. If you look at the last entry, you’ll see that this entry is just a time. “12:18 P.M. EST” is hardly a speech. It doesn’t make sense to save this entry. We can’t derive any value from saving a vector embedding.
Let’s get rid of all of the speeches that are less than a certain length. For this example, I’ve chosen 50, but you can choose whatever makes sense to you. I chose 50 through exploring many different numbers. If you look for speech transcripts between 20 and 50 characters, you’ll see many are locations or times with a few random sentences thrown in there.
cleaned_df = df.loc[(df["Speech"].str.len() > 50)]cleaned_df
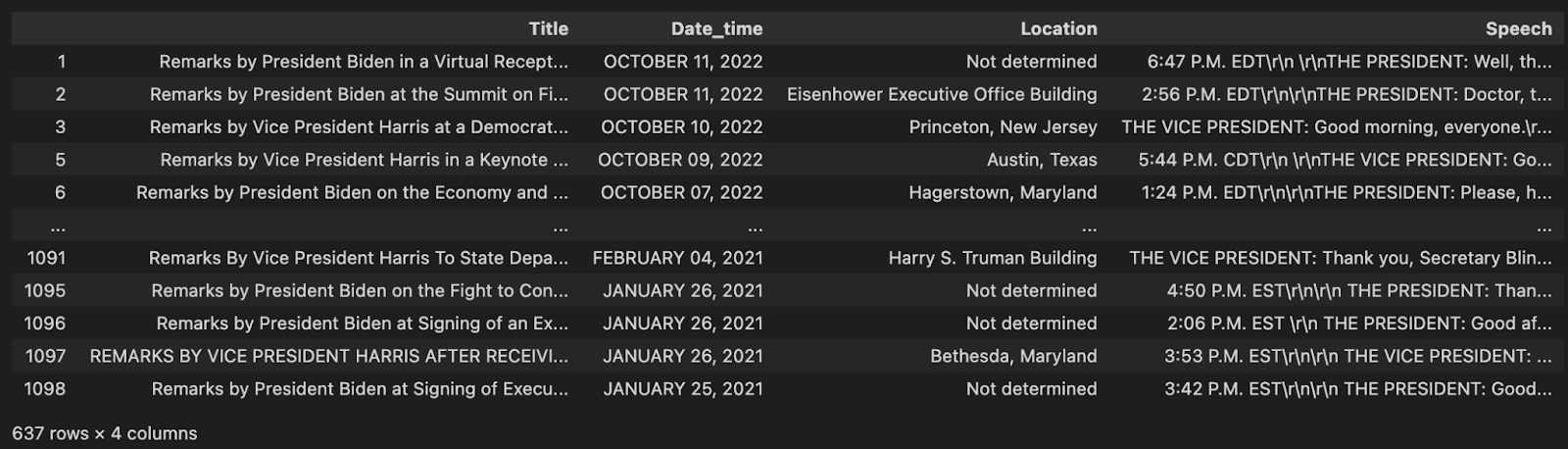
With the short, no-substance speeches taken care of, we once again look at our data to see one more issue. Many of the speeches contain \r\n values - newlines and returns. These characters are used for formatting, but don’t contain any semantic value. The next step in our data cleaning process is to get rid of these.
cleaned_df["Speech"] = cleaned_df["Speech"].str.replace("\r\n", "")
cleaned_df

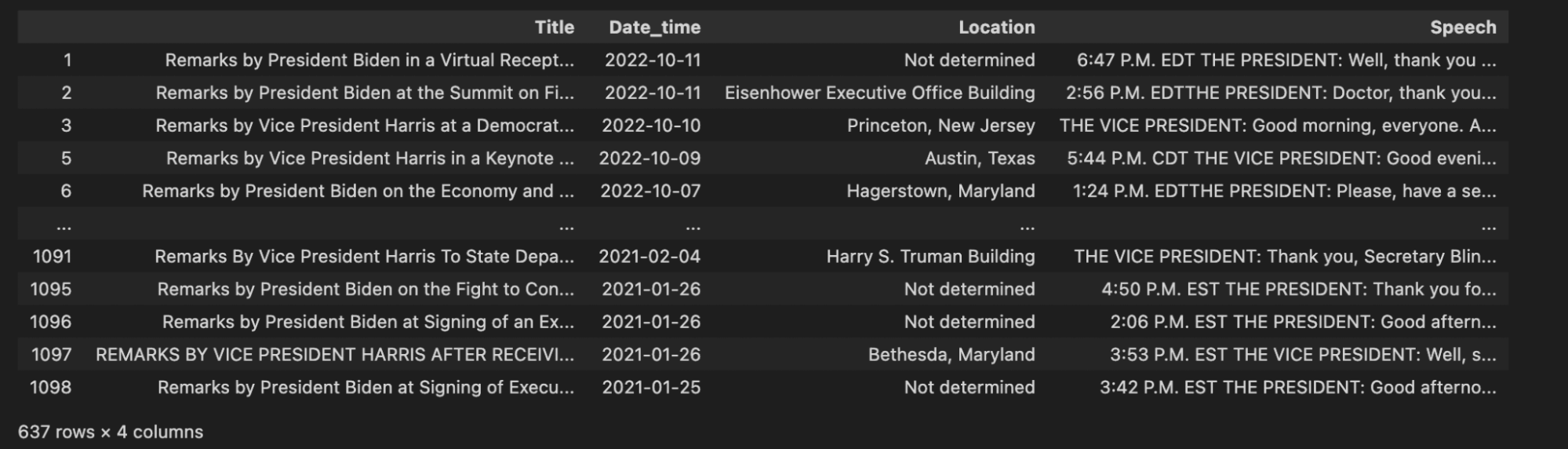
That’s looking way better. The final step is to convert the “Date_time” column into a better format to store in our vector database, and be compared to other datetimes. We use the datetime library to simply convert this datetime format into a universal YYYY-MM-DD format.
import datetime
# Convert the 'date' column to datetime objects
cleaned_df["Date_time"] = pd.to_datetime(cleaned_df["Date_time"], format="%B %d, %Y")
cleaned_df
Setting Up a Vector Database for Semantic Search
Our data is now clean and ready to work with. The next step is to spin up a vector database to actually search the speeches by their content. For this example, we use Milvus Lite, a lite version of Milvus that you can get running without Docker, Kubernetes or dealing with any sort of YAML file.
The first thing we do is define some of our constants. We need a collection name (for the vector database), the number of dimensions in our embedded vector, a batch size and a number that defines how many results we want back when we search. This example uses the MiniLM L6 v2 sentence transformer, which produces 384 dimension embedding vectors.
COLLECTION_NAME = "white_house_2021_2022"
DIMENSION = 384
BATCH_SIZE = 128
TOPK = 3
We use the default_server from Milvus. Then, we use the PyMilvus SDK to connect to our local Milvus server. If there is a collection in our vector database that has the same name as the collection name we defined earlier, we drop that collection to ensure we start with a blank slate.
from milvus import default_server
from pymilvus import connections, utility
default_server.start()
connections.connect(host="127.0.0.1", port=default_server.listen_port)
if utility.has_collection(COLLECTION_NAME):
utility.drop_collection(COLLECTION_NAME)
Like most other databases, we need a schema to load data into the Milvus vector database. First, we define the data fields that we want each object to have. Good thing we looked at the data earlier. We use five data fields, the four columns we had earlier and an ID column. Except this time we use the vector embedding of the speech instead of the actual text.
from pymilvus import FieldSchema, CollectionSchema, DataType, Collection
# object should be inserted in the format of (title, date, location, speech embedding)
fields = [
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True, auto_id=True),
FieldSchema(name="title", dtype=DataType.VARCHAR, max_length=500),
FieldSchema(name="date", dtype=DataType.VARCHAR, max_length=100),
FieldSchema(name="location", dtype=DataType.VARCHAR, max_length=200),
FieldSchema(name="embedding", dtype=DataType.FLOAT_VECTOR, dim=DIMENSION)
]
schema = CollectionSchema(fields=fields)
collection = Collection(name=COLLECTION_NAME, schema=schema)
The last thing we need to define before being ready to load data into the vector database is the index. There are many vector indexes and patterns, but for this example we use the IVF_FLAT index with 128 clusters. Larger applications usually use more than 128 clusters, but we only have slightly more than 600 entries anyway. For our distance, we measure using the L2 norm. Once we define our index parameters, we create the index in our collection and load it up for use.
index_params = {
"index_type": "IVF_FLAT",
"metric_type": "L2",
"params": {"nlist": 128},
}
collection.create_index(field_name="embedding", index_params=index_params)
collection.load()
Getting Vector Embeddings from Speeches
Much of what we’ve gone over so far applies when working with almost any database. We cleaned up some data, we spun up a database instance and defined a schema for our database. Other than defining an index, one other thing we need to do for vector databases in particular is getting the embeddings.
First, we get the sentence transformer model MiniLM L6 v2 as mentioned above. Then we create a function that performs a transformation on the data and inserts it into the collection. This function takes a batch of data, gets the embeddings for the speech transcripts, creates an object to insert and inserts it into the collection.
For context, this function performs a batch update. In this example, we are batch-inserting 128 entries at once. The only data transformation we do in our insert is turning the speech text into an embedding.
from sentence_transformers import SentenceTransformer
transformer = SentenceTransformer('all-MiniLM-L6-v2')
# expects a list of (title, date, location, speech)
def embed_insert(data: list):
embeddings = transformer.encode(data[3])
ins = [
data[0],
data[1],
data[2],
[x for x in embeddings]
]
collection.insert(ins)
Populating Your Vector Database
With a function that creates batch embeds and inserts complete, we are ready to populate the database. For this example, we loop through each row in our dataframe and append to a list of lists we use for batching our data. Once we hit our batch size, we call the embed_insert function and reset our batch.
If there’s any leftover data in the data batch after we finish looping, we embed and insert the remaining data. Finally, to finish off populating our vector database, we call flush to ensure the database is updated and indexed.
data_batch = [[], [], [], []]
for index, row in cleaned_df.iterrows():
data_batch[0].append(row["Title"])
data_batch[1].append(str(row["Date_time"]))
data_batch[2].append(row["Location"])
data_batch[3].append(row["Speech"])
if len(data_batch[0]) % BATCH_SIZE == 0:
embed_insert(data_batch)
data_batch = [[], [], [], []]
# Embed and insert the remainder
if len(data_batch[0]) != 0:
embed_insert(data_batch)
# Call a flush to index any unsealed segments.
collection.flush()
Semantic Search White House Speeches Based on Descriptions
Let’s say that I’m interested in finding a speech where the president spoke about the impact of renewable energy at the National Renewable Energy Lab (NREL) and a speech where the vice President and the prime minister of Canada speak. I can find the titles for the most similar speeches given by the members of the White House in 2021-2022 by using the vector database we just created.
We can search our vector database for speeches most similar to our descriptions. Then, all we have to do is convert the description into a vector embedding using the same model we used to get the embeddings of the speeches and then search the vector database.
Once we convert the descriptions into a vector embedding, we use the search function on our collection. We pass the embeddings in as the search data, pass in the field we are looking for, add some parameters for how to search, a limit for the number of results and the field that we want to return. In this example, the search parameters we need to pass are the metric type, which has to be the same type we used when creating the index (L2 norm), and the number of clusters we want to search (setting nprobe to 10).
import time
search_terms = ["The President speaks about the impact of renewable energy at the National Renewable Energy Lab.", "The Vice President and the Prime Minister of Canada both speak."]
# Search the database based on input text
def embed_search(data):
embeds = transformer.encode(data)
return [x for x in embeds]
search_data = embed_search(search_terms)
start = time.time()
res = collection.search(
data=search_data, # Embeded search value
anns_field="embedding", # Search across embeddings
param={"metric_type": "L2",
"params": {"nprobe": 10}},
limit = TOPK, # Limit to top_k results per search
output_fields=["title"] # Include title field in result
)
end = time.time()
for hits_i, hits in enumerate(res):
print("Title:", search_terms[hits_i])
print("Search Time:", end-start)
print("Results:")
for hit in hits:
print( hit.entity.get("title"), "----", hit.distance)
print()
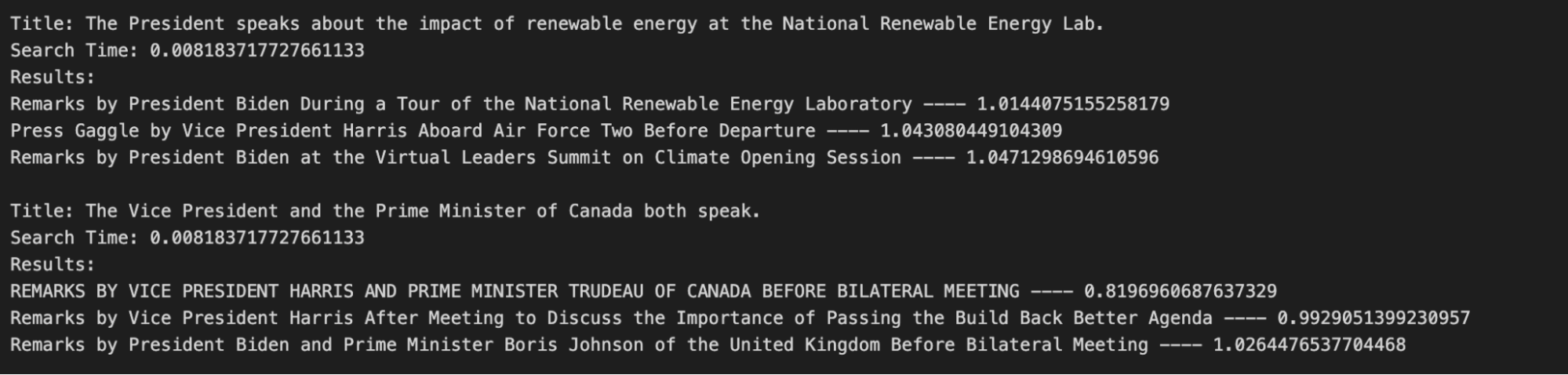
When we search for the sentences in this example, we expect to see output like the image below. This was a successful search because the titles are what we expect to see. The first description returns the title of a speech given by President Biden at NREL, and the second description returns a title reflective of a speech given by Vice President Harris and Prime Minister Trudeau.
Summary
In this tutorial, we learned how to use a vector database to semantically search through speeches given by the Biden administration before the 2022 midterm elections. Semantic search allows us to take a blurb and look for semantically similar text, not just syntactically similar text. This allows us to search for a general description of a speech instead of searching for a speech based on specific sentences or quotes. For most of us, that makes finding speeches we would be interested in way easier.

Keep Reading

Vector Databases vs. Document Databases
Use a vector database for similarity search and AI-powered applications; use a document database for flexible schema and JSON-like data storage.

Vector Databases vs. Key-Value Databases
Use a vector database for AI-powered similarity search; use a key-value database for high-throughput, low-latency simple data lookups.

Zilliz Cloud BYOC Upgrades: Bring Enterprise-Grade Security, Networking Isolation, and More
Discover how Zilliz Cloud BYOC brings enterprise-grade security, networking isolation, and infrastructure automation to vector database deployments in AWS