




Multilingual Narrative Tracking in the News
Large Language Models (LLMs) have transformed how we perform various tasks, such as content generation, customer service chatbots, etc. With the growth in the use of LLMs, we need to ensure that the models are unbiased in their knowledge of current news to provide reliable responses. Multilingual narrative tracking helps in achieving this.
A narrative, a sequence of interconnected events, is a powerful tool for understanding the world around us. For instance, when Barbie’s new movie trailer was released, and Bath & Body Works launched a Barbie Edition of Candles a few days later, these two events formed a narrative. In the context of news tracking, we are essentially tracking these narratives. The Barbie Movie Campaign narrative, with its diverse coverage and sentiments across different regions and languages, is a prime example. This process of analyzing how a narrative is reported in terms of volume and sentiment across different languages (countries) is what we call Multilingual Narrative Tracking.
Robert Caulk, the Founder of Emergent Methods, recently delivered a talk on multilingual narrative tracking of news at the Berlin Unstructured Data Meetup conducted by Zilliz. Emergent Methods develops open-source software to apply AI to real-time adaptive modeling challenges.
During the talk, Robert emphasizes the need to track different narratives of news articles. He presents an architecture of embedding models combined with LLM to track Global News across diverse countries, languages, and sources.
Why Do We Need to Engineer News Contexts?
Robert discusses the main reasons why the Emergent Methods Team was looking at different approaches to engineering news context and tracking the narratives:
Enforcing journalistic Standards: It is paramount to ensure that LLMs adhere to rigorous journalistic standards. It is crucial to prevent the dissemination of unverified claims, as this could lead to misinformation and mistrust.
Source & Language Diversity: The LLM should know current news or ongoing events when developing LLMs-based services for any product, from a friendly Chatbot to a Financial Analyst Assistant. The LLM must be exposed to diverse news across languages, countries, and other demographics. The sources cannot be biased, as they would not represent the customer base democratically. For example, the Russian and US news articles will have different perspectives on issues such as the Ukraine war. We need to cover the different perspectives of any particular news narrative across various languages.
Avoiding Stale News: It is imperative to avoid outdated news. Reporting stale news can have detrimental repercussions, leading to user dissatisfaction and a loss of trust in LLM-based services.
Minimize Hallucinations: Another challenge is the hallucinations of large language models (LLMs). Hallucinations occur when LLMs generate responses with incorrect data or even fabricated information based on historical patterns in training data. The costs of hallucinations are on the heavy side when we take LLMs to the market.
Democratized News Content at Scale: The challenge of managing news content at scale is widespread. Many businesses, regardless of their size, struggle with the logistics of tracking over 1 million news articles, ensuring they are free of logical fallacies and have diversified sources. A strategic tool to address this challenge could have broad applications across numerous markets.
Engineering the Parameter Space: Enriching Articles with LLM & Building Embeddings
Robert defines the aim of engineering parameter space as: “Our objective is to create a clean parameter space to cluster on news topics across diverse perspectives “. The idea is to extract entities, especially those originating from small demographics. Robert also emphasizes the need to normalize language differences to compare narratives.
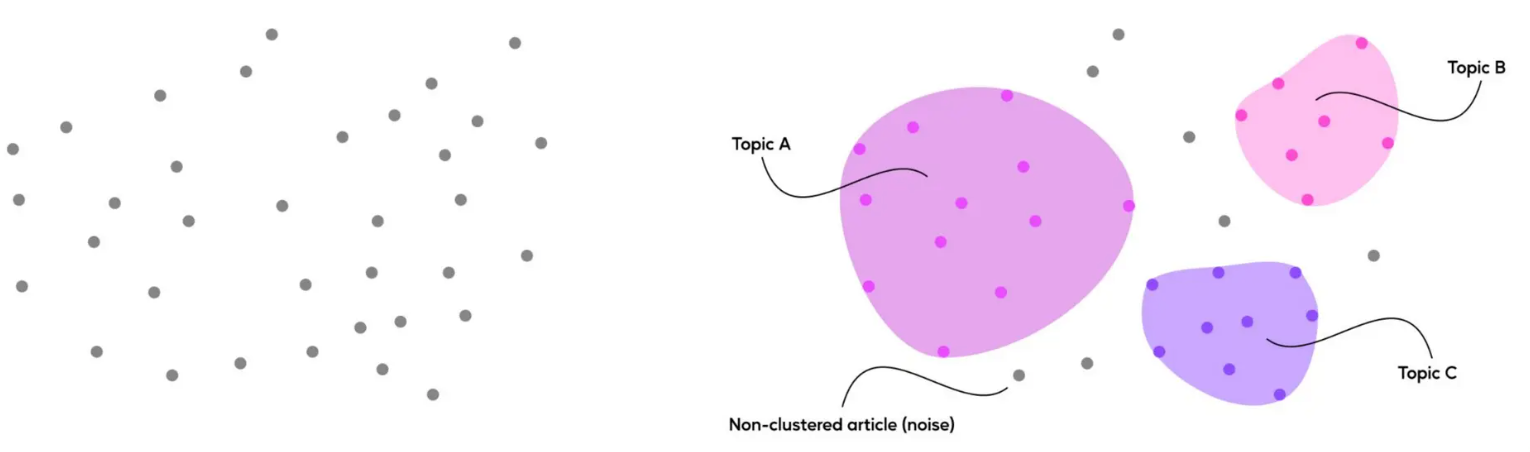 A clean and well-defined parameter space
A clean and well-defined parameter space
They have designed an approach to enriching news articles. The idea is to use large language models in multiple steps.
Supply the title and content of the article as input to an LLM.
The LLM translates and summarizes the content of the article. Unlike the traditional baseline summarizers, summarization should include evidence to support claims. This will avoid hallucinations and misinformation.
Perform the custom extraction of entities and keywords from the summarized information. This is where the GLiNER-news large language model shines. Fine-tuned for this task, it can swiftly identify and extract entities like product names, events, dates, and organizations from the text. The GLiNER-news will soon be available on the HuggingFace platform, inviting the public to experience its efficiency and effectiveness.
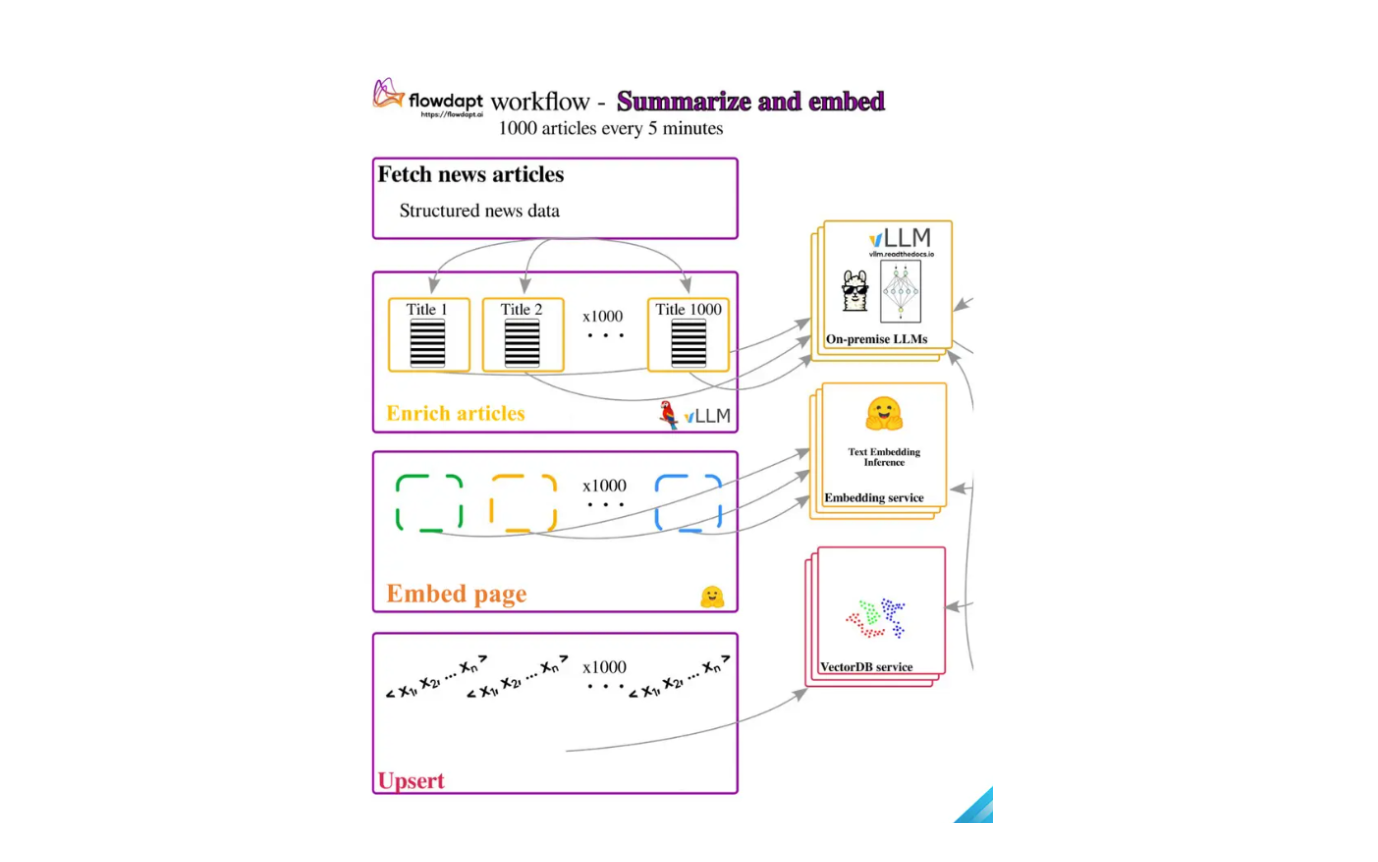
Building the embedded page: The enriched articles are converted into vector embeddings using a text embedding model and stored in a vector database like Milvus. In the future, the information can be queried from the vector database. Choosing the text embedding model and vector database is crucial.
The text embedding model will control our retrieval speed while querying. It will also affect the quality of embeddings generated. The costs incurred for creating and storing embeddings also need to be affordable. There are many options available on HuggingFace for text embedding models. The vector database we choose needs to be robust and support parallelization capabilities. We also need features like the ability to filter metadata, perform quantization, etc. Zilliz provides a robust open-source vector database, Milvus, which you can check out.
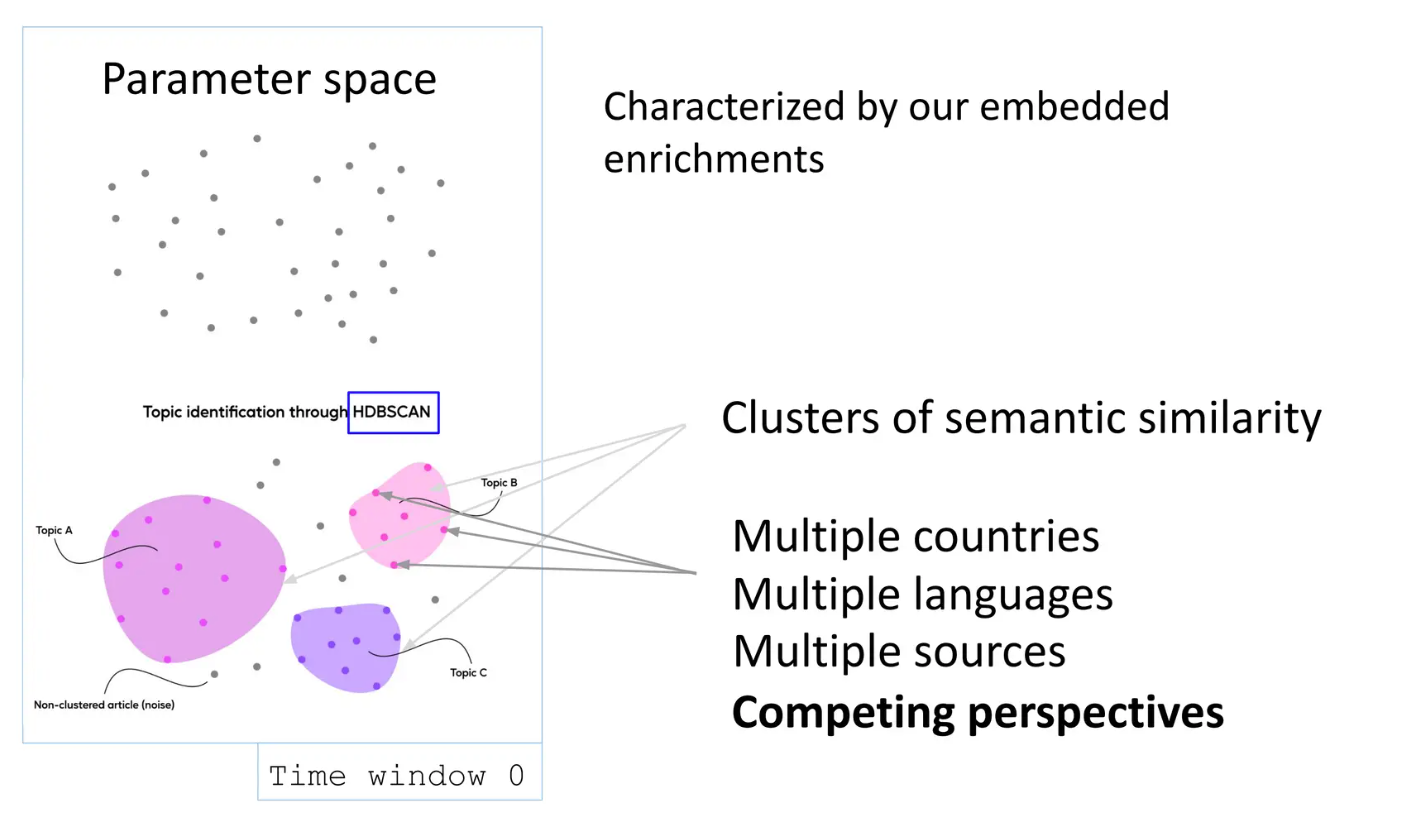
Tracking Narratives in our Parameter Space
A news narrative is a series of news reports that should have multiple points of view and often contain both accidental and intentional errors. The enriched embeddings characterize our clean parameter space.
Initially, clustering is done based on the semantic similarity of the embedded parameters. It is essential to have sources from multiple languages and sources. Robert mentions that
“Having Competing Perspectives in data is crucial to compare the reporting of a particular news narrative “
The next question is, how do we connect different news reports of the same narrative over time?
We do clustering at different time windows, following chronological sequence. We can connect the clusters at different time points through various methods. Robert also recommends a few cluster connection methods like:
You can train a binary classifier per cluster, to predict if the news article belongs to a particular narrative
You can measure how the centroid cluster changes. This can provide information on whether you are entering a new cluster or re-entering an old one (indicative of the same news narrative)
We can also use overlapping clustering techniques, such as Fuzzy C-means and soft clustering with Gaussian Mixture Models.

By this approach, we can track a particular niche over long time ranges. For example, the below image shows a narrative on Madonna’s concert reported over 6 days. On May 1st, there was an announcement of the concert, and on May 6th, there was an article on groundbreaking records set by the concert. By cluster creating & connection, we can link the two articles together in sequence. This allows us to track the coverage and sentiment through time to obtain insights. We can check how Spanish sources are reporting it, how the US is reporting it, and more.

Each cluster should be diverse in regions/countries. Through prompt engineering, we ensure each perspective is represented in the cluster. Then, we can identify alignment and contradictions between different sources of reporting. For example, how US reports s news might have a different sentiment than Russia reports.
Demonstrative Examples
Robert presents an example of tracking the narrative of “Death of Alexi Navalny”.
We measure how much coverage each country gave to report the death of Navalny. Robert chooses Russian, French, and US News coverage to compare the differences. It was observed that 0.5% of French news coverage was devoted to Navalny, whereas Russia has only 0.14%.
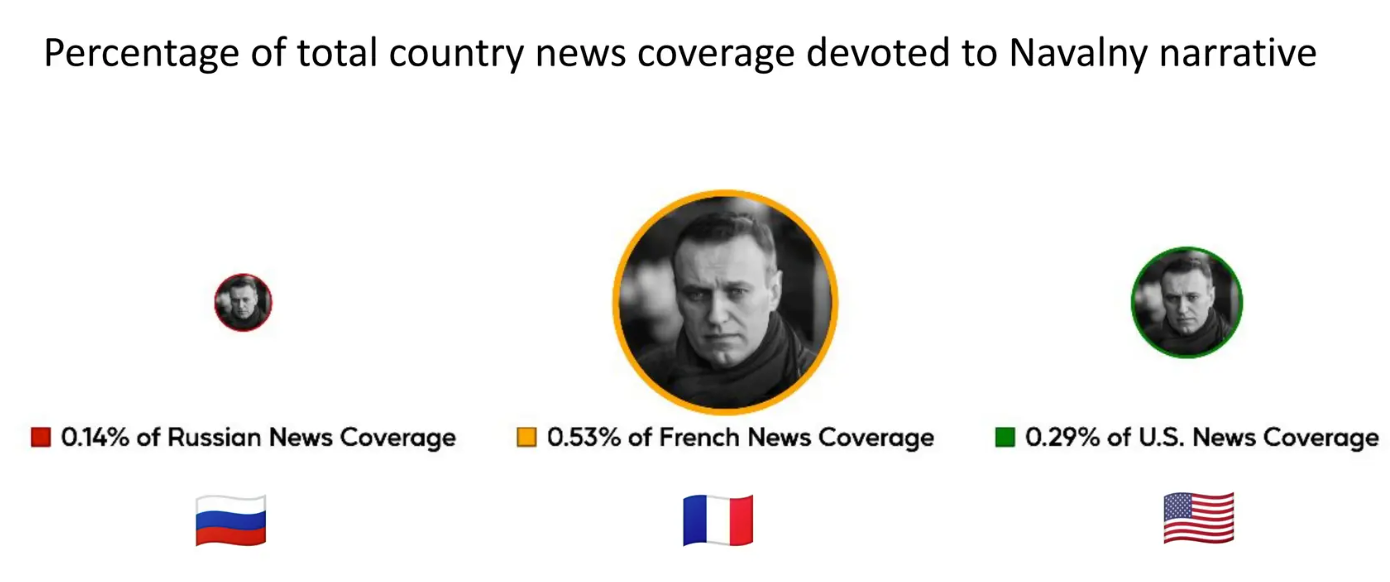
This indicates that Russia may have imposed censorship on reporting on this topic. We can also compare what news topics Russia reported compared to the news reported by French and US Media. The image below depicts a small example. It is evident that negative news coverage is very low in Russia.

Robert also shows us box plots comparing news coverage of the Russia-Ukraine conflict by different countries/languages. In this case, US media coverage seems to be unusually low.
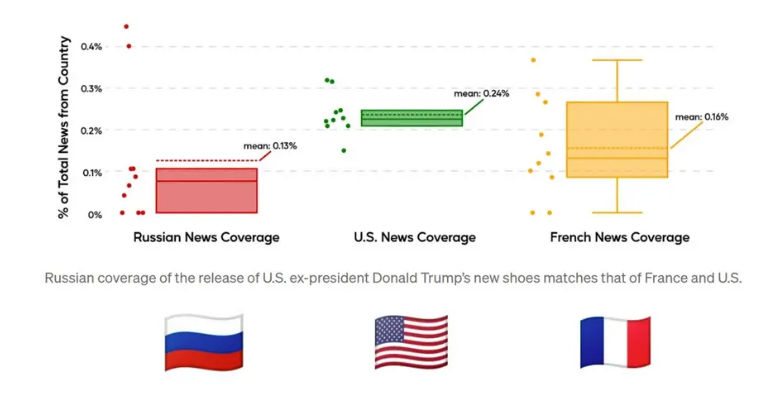
These insights can be really helpful in understanding cases where news articles are biased or selectively reported. This increases the transparency of selective reporting, and we can remove the bias while training new models on the news.
Conclusion
AI-powered Multi-Lingual Narrative tracking can increase transparency and ensure global perspectives and a more comprehensive event coverage. It paves the way for including voices from different limits and cultural backgrounds, which is essential. We can also cross-verify our information across various sources, minimizing the chances of inconsistencies. Continuous research and developments in prompt engineering and LLM architecture are needed to develop more advanced approaches
Keep Reading

Vector Lakebase: End the AI Data Silo
Learn how Vector Lakebase unifies vector search, data lakes, and AI data operations so teams can serve RAG and agents without copy-and-sync pipelines.

Zilliz Cloud Now Available in AWS Asia Pacific (Seoul)
Zilliz Cloud is now available in AWS Seoul — low-latency vector search, in-country data residency, and one-step migration for Korean AI teams. 31 regions across 5 clouds.

Why Not All VectorDBs Are Agent-Ready
Explore why choosing the right vector database is critical for scaling AI agents, and why traditional solutions fall short in production.