




How to Load Test an LLM API with Gatling
When building applications with large language models (LLMs), it's essential to ensure they can handle varying demand levels. This is where load testing comes into play. Load testing simulates real-world traffic to evaluate your API's performance under different conditions. This approach helps identify potential bottlenecks and areas for improvement, ensuring the application remains reliable and responsive.
At a recent Berlin Unstructured Data Meetup, Samir Akarioh, a developer advocate at Gatling, spoke about how to load test an LLM API using Gatling. Gatling is an open source performance-testing framework that is used to load test javascript web applications. His insights shed light on the importance of load testing LLM APIs and the different methods used. In this blog, we’ll recap his key points and discuss how to load-test large language model applications, particularly RAG apps (retrieval augmented generation) powered by vector databases like Milvus to improve performance, load and response times.
Watch the replay of Samir’s talk on YouTube.
What is Load Testing?
Load testing is a type of performance testing that evaluates how a system behaves under specific load conditions, usually with attempts to stress test the system with vast amounts of data. The primary goal is to assess whether the system can handle the expected user traffic or data volume under normal and peak conditions. During load testing, the system's behavior is monitored to identify bottlenecks, performance degradation, or failures that could impact user experience.
For LLM APIs, load testing is particularly important due to the complex nature of these systems and the high computational demands of processing natural language. Failure to conduct proper load testing can lead to service outages, slow response times, or inaccurate results, potentially damaging user trust and the overall reliability of AI-powered applications.
At this unstructured data meetup, Samir breezed through three types of load testing: capacity test, stress test, and soak test. Let's slow that down a bit and have an in-depth look at each one.
Capacity Test
A capacity test determines the maximum load your API can handle while meeting performance requirements. he goal is to identify the "sweet spot" where the system operates at its peak load without degradation in response time or throughput. For an LLM API, capacity testing finds the maximum number of requests per second it can handle while still providing accurate and timely responses.
For example, a capacity test might involve gradually increasing the number of concurrent users sending prompts to the API until response times begin to increase or accuracy starts to decrease. This information is invaluable for capacity planning and can inform decisions about when to scale up infrastructure or optimize the API.
Capacity testing helps us plan for expected traffic and understand the limits before we begin seeing performance drops. It's essential for ensuring that the system can handle anticipated growth and peak usage periods without compromising user experience.
Stress Test
While a capacity test identifies the optimal load, a stress test pushes the system beyond its limits to discover its breaking point. The purpose is to evaluate how your API behaves under extreme conditions, such as a sudden surge in requests or an unexpectedly high volume of data.
Stress testing can simulate real-world situations like a viral social media post that suddenly drives massive traffic to an AI-powered application. During these tests, it's important to monitor not just response times and throughput, but also error rates, resource utilization (CPU, memory, network), and the quality of the API's responses.
Stress testing is essential for understanding how the LLM API might fail and what happens when it does—whether it crashes, slows down, or recovers. This information is vital for improving system resilience and ensuring that it can gracefully handle unexpected spikes in usage. It can also help in designing better failover and load balancing strategies.
Soak Test
Soak testing, or endurance testing, evaluates how your API performs over an extended period. It identifies issues like memory leaks, performance degradation, or database connection saturation that might not be evident in shorter tests. For an LLM API, a soak test runs a steady stream of requests over several hours or days to observe how the system maintains performance.
The ideal duration for a soak test can vary depending on the system and its expected usage patterns. For some LLM APIs, a 24-hour test might be sufficient, while others might benefit from week-long tests to uncover subtle issues that only manifest over extended periods.
Soak tests are particularly good at revealing gradual performance degradation. For instance, they might show that response times slowly increase over time, or that the quality of generated text subtly declines after processing a large number of requests. These insights can be crucial for implementing proactive maintenance measures and optimizing long-term performance.
This test ensures that the API can handle sustained demand without deteriorating, which is crucial for applications expected to run continuously or handle long-term, consistent traffic.
Best Practices for Load Testing LLM APIs
When conducting load tests on LLM APIs, consider the following best practices:
Use realistic data and scenarios that mimic actual usage patterns.
Gradually ramp up the load to identify performance thresholds accurately.
Monitor a wide range of metrics, including response times, error rates, and resource utilization.
Test from different geographic locations to account for network latency.
Include a mix of different types of requests that your API typically handles.
Tools for Load Testing Several tools can be used for load testing LLM APIs, including:
Apache JMeter: An open-source tool that can be used for various types of load tests.
Locust: A Python-based tool that's particularly good for distributed load testing.
Gatling: A Scala-based tool that's excellent for high-volume load testing. The next section will jump into load testing with Gatling.
Load Testing an LLM API with Gatling
Gatling is a load-testing tool for web applications designed for DevOps and Continuous Integration. Since you have understood the theory of load testing, let’s see how we can practically conduct a load test on the OpenAI Chat Completions API using Gatling. Follow this guide to set up your Gatling project.
1. Setting Up the Simulation Class
First, start by importing the necessary libraries and setting up the simulation class:
import static io.gatling.javaapi.core.CoreDsl.*;
import static io.gatling.javaapi.http.HttpDsl.*;
import io.gatling.javaapi.core.*;
import io.gatling.javaapi.http.*;
These imports bring in the core DSL (Domain-Specific Language) and HTTP DSL to create scenarios and handle HTTP requests in Gatling. After importing the libraries, define the simulation class.
public class SSELLM extends Simulation {
String api_key = System.getenv("api_key");
In the above code, the SSELLM class extends Simulation , a required base class for all Gatling simulations. The api_key variable retrieves the API key from your environment variables, ensuring that sensitive information is not hardcoded.
2. Configuring the HTTP Protocol
After passing the API Key, the next step is specifying your LLM’s service base URL.
HttpProtocolBuilder httpProtocol =
http.baseUrl("https://api.openai.com/v1/chat")
.sseUnmatchedInboundMessageBufferSize(100);
The baseUrl specifies the API's base endpoint, and the sseUnmatchedInboundMessageBufferSize(100) configures the buffer size for handling server-sent events (SSE) messages that do not match any expected responses.
3. Defining the Scenario
The heart of any Gatling test is the scenario that simulates user behavior. Let's define a scenario for our test.
ScenarioBuilder prompt = scenario("Scenario").exec(
sse("Connect to LLM and get Answer")
.post("/completions")
.header("Authorization", "Bearer " + api_key)
.body(StringBody("{"model": "gpt-3.5-turbo","stream":true,"messages":[{"role":"user","content":"What is a vector database "}]}"))
.asJson(),
asLongAs("#{stop.isUndefined()}").on(
sse.processUnmatchedMessages((messages, session) -> {
return messages.stream()
.anyMatch(message -> message.message().contains("{"data":"[DONE]"}")) ? session.set("stop", true) : session;
})
),
sse("close").close()
);
In the above scenario, we simulate a user sending a request to the OpenAI Chat API and waiting for a response. The test establishes an SSE (Server-Sent Events) connection to the API. A POST request is then sent to the /completions endpoint with a message prompting the model to define a vector database. The test continues to process incoming SSE messages with asLongAs("#{stop.isUndefined()}") , which keeps the connection open until a specific condition is met.
As messages are received, sse.processUnmatchedMessages(...) checks if the response contains the "[DONE]" signal, indicating that the interaction is complete. Once this signal is detected, the session stops, and the connection is closed with sse("close").close().
4. Injecting Virtual Users
After creating the scenario, the final step is to specify the number of users to simulate and configure the protocol.
{
setUp(
prompt.injectOpen(atOnceUsers(3))
).protocols(httpProtocol);
}
}
The above code injects three virtual users into the scenario simultaneously. This simple load test checks the API's performance when handling three concurrent requests.
Use the following command to run the code:
.mvnw.cmd gatling:test
Once the code runs, Gatling will provide a file path on the terminal. This is the path to the test report. Here is a sample part of the report.
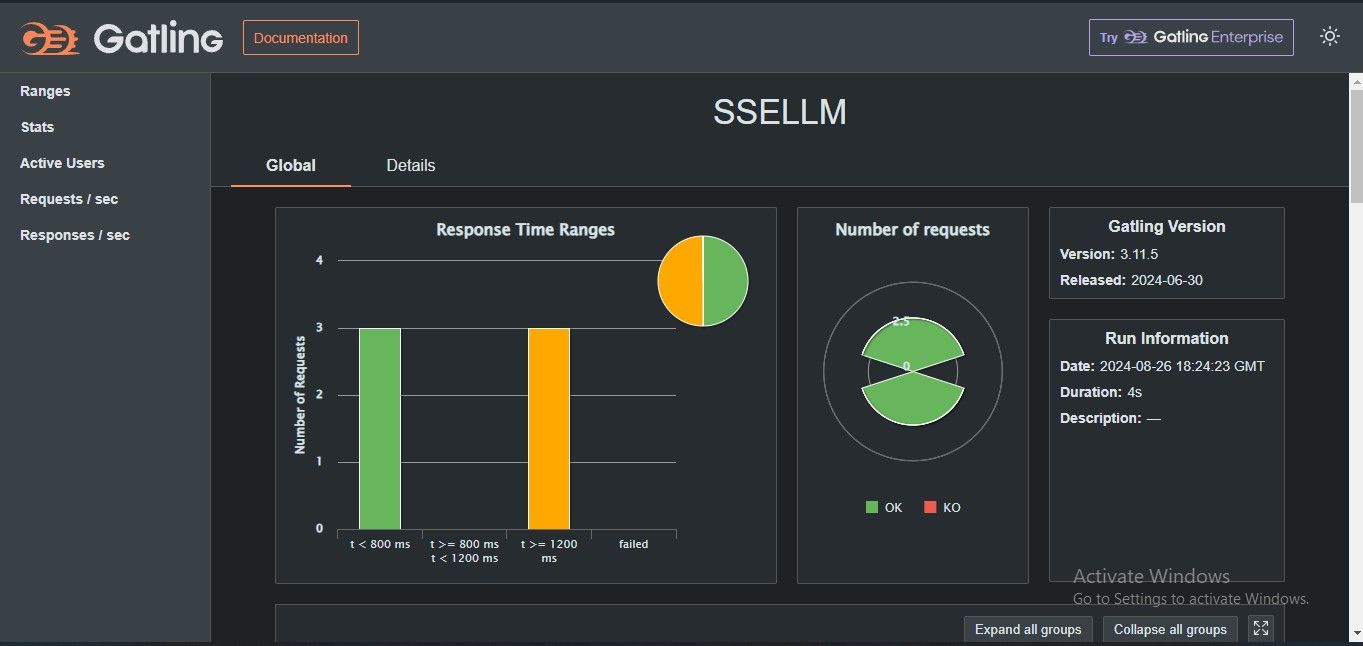 Figure 1: Gatling Response Time Range Report on testing OpenAI chat completion API
Figure 1: Gatling Response Time Range Report on testing OpenAI chat completion API
As expected for the OpenAI chat completion API, the test demonstrates that the OpenAI API handled the concurrent requests efficiently, with all responses received in good time frames. But remember, we only sent three concurrent requests and used a very short prompt.
In a real-world scenario, your LLM might receive thousands of requests concurrently and longer prompts. The longer prompts are mostly when the user provides more context to the LLM. Consider adding the number of virtual users and length of prompts during a real-world case.
Gatling is not limited to LLM APIs. You can also use it to load test APIs that power Retrieval Augmented Generation (RAG) applications. This approach will give an overall assessment of the application's performance. Let’s create a scenario where we can load-test a RAG-powered application.
But before we do that, you might ask yourself, what is RAG? Let’s understand the concept of RAG first.
Understanding Retrieval Augmented Generation (RAG)
RAG, or retrieval augmented generation, is a technique that combines the generative capabilities of a large language model (LLM) with a retrieval mechanism to fetch relevant information from a vector database such as Milvus and Zilliz Cloud (the managed Milvus). By leveraging external data as contexts, the LLM is less likely to hallucinate and generates more accurate and contextually relevant responses. In addition, RAG also enables you to retrieve private or proprietary data for your LLM as a context for more personalized responses without worrying about data security issues.
In a typical RAG setup, when a user query is received, the RAG system retrieves relevant documents or snippets from a knowledge base powered by a vector database. These documents are then used to provide context to the LLM so that the LLM generates a more informed and comprehensive response.
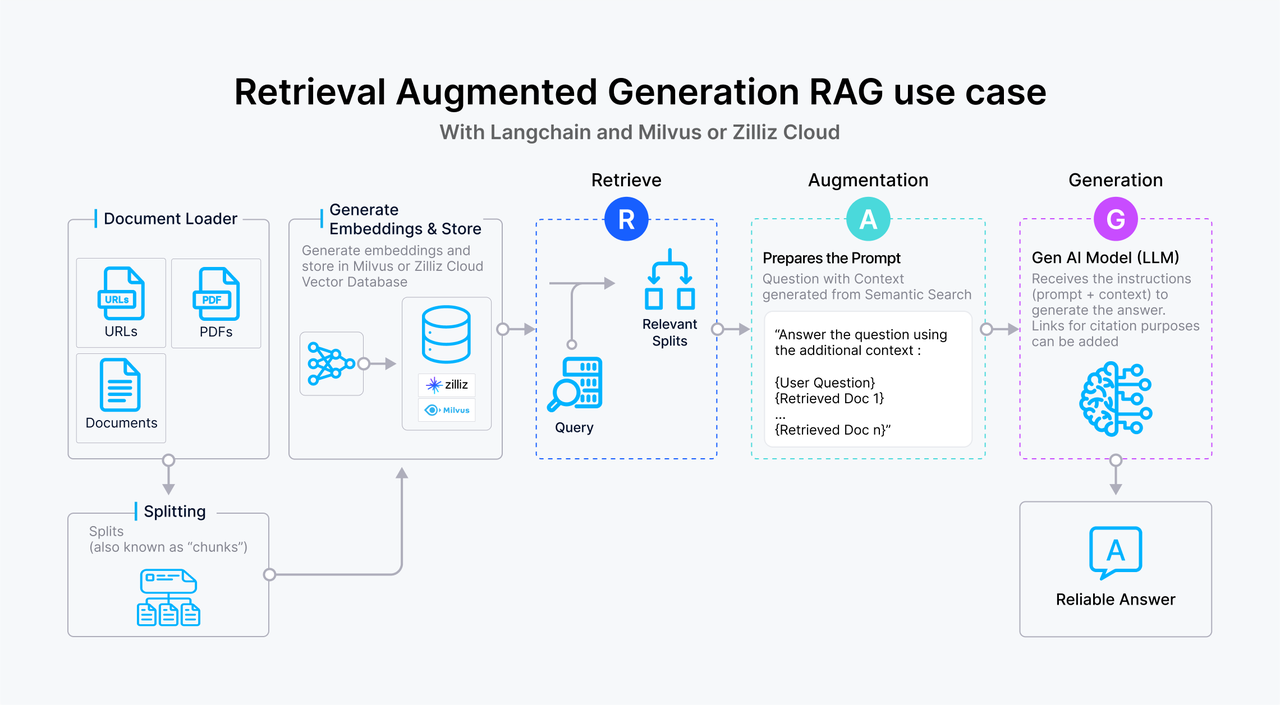 Figure 2: How RAG works
Figure 2: How RAG works
Creating A Scenario That Tests a RAG Application
Now that we’ve understood RAG, let’s learn how to load test a RAG application using Gatling.
Imagine a situation where a customer support application is powered by an LLM. Users might query the system with questions that require detailed, context-aware responses. The application leverages RAG to pull relevant documents from a vector database like Milvus to enhance the quality of these responses. These documents provide the LLM with the necessary context, enabling it to produce more accurate and informed answers.
We would design a scenario with the below processes for our load test.
Simulated User Requests: Virtual users send complex queries that require additional context. For instance, a user might ask, "How do I troubleshoot a connection issue with my device?" This question alone does not provide enough information to obtain a high-quality response from an LLM, so the system needs to retrieve relevant troubleshooting documents from the Milvus vector database.
Contextual Retrieval: The system fetches the most relevant documents from Milvus based on the user query. This step is crucial as it determines the quality of the context provided to the LLM, directly impacting the accuracy of the generated response. In a RAG pipeline, Milvus indexes a vast amount of documentation and conducts a vector similarity search to find the most relevant information quickly.
LLM Response Generation: Once the relevant documents are retrieved, they are provided as context to the LLM. The LLM then uses this information to respond to the user's query. This process generates the answer and potentially cites specific sources from the retrieved documents.
Load Testing with Concurrent Users: You then inject a higher number of virtual users to simulate peak usage conditions.
Monitoring and Analysis: When Gatling generates the report, you monitor any bottlenecks the API powering your application might encounter. It is important to note that the test results are influenced by both the large language models performance and the retrieval mechanism's efficiency under load. This gives you a comprehensive evaluation of how the whole system is performing.
Load-testing your RAG-powered app using the above scenario will ensure you identify any scalability issues.
Conclusion
Samir did a good job at providing valuable insights into load testing an LLM API using Gatling. He explained the different types of load testing and how we can load-test an LLM API. We have also expanded the article to explore how to perform load testing even further on other LLM-powered applications, such as RAG-based customer support applications. With this knowledge, you can develop API tests for your APIs, ensuring your products can scale without issues. When conducting load tests on LLM APIs, consider the following best practices:
Best Practices for Load Testing LLM APIs
Use realistic data and test cases that mimic actual usage patterns.
Gradually ramp up the load to identify performance thresholds accurately.
Monitor a wide range of metrics, including response times, error rates, and resource utilization.
Test from different geographic locations to account for network latency.
Include a mix of different types of requests that your API typically handles.
Further Resources about RAG, GenAI, and Vector Search
Keep Reading

Zilliz Cloud Enterprise Vector Search Powers High-Performance AI on AWS
Zilliz Cloud on AWS powers secure, scalable, ultra-fast vector search for enterprise AI apps, with BYOC, sub-10ms latency, and zero-DevOps simplicity.

Vector Databases vs. Object-Relational Databases
Use a vector database for AI-powered similarity search; use an object-relational database for complex data modeling with both relational integrity and object-oriented features.

Vector Databases vs. Hierarchical Databases
Use a vector database for AI-powered similarity search; use a hierarchical database for organizing data in parent-child relationships with efficient top-down access patterns.