




How Delivery Hero Implemented the Safety System for AI-Generated Images
As a multinational online food delivery company, Delivery Hero connects customers with restaurants in their respective areas. Therefore, it's crucial for the company to understand the needs of both parties to maintain their overall satisfaction with Delivery Hero's services.
In a presentation at the Zilliz Unstructured Data Meetup in Berlin, Iaroslav Amerkhanov and Nikolay Ulyanov, two data scientists at Delivery Hero, discussed their research project to streamline the needs of restaurant vendors and customers.
<< Watch the replay of the meetup talk >>
Based on internal statistics, Delivery Hero found an interesting fact: products with an image attached to them on the app are ordered much more frequently than products without an image. Specifically, 86% of the products ordered on the app have an image attached. After conducting A/B testing, they also found that the conversion rate increases by 6-8% just by adding an image to a product. This finding means that the image of a product is one of the crucial factors for customers before ordering food from vendors on the Delivery Hero app.
However, asking each restaurant or vendor to provide an image of their products can be cumbersome, as not every vendor can provide appealing pictures. Therefore, data scientists at Delivery Hero proposed a sophisticated approach to generating high-quality pictures of a product by leveraging AI advancements. Their approach consists of two stages: the food image generation and the safety system.
Let's discuss the food image generation stage first.
Food Image Generation
Delivery Hero implements two approaches to generate a product image: one involves calling the API of available generative AI platforms, and the other uses the image inpainting method.
Food Image Generation with Popular Image Generation Model
Several AI models are available for generating high-quality, photorealistic images, including DALL-E, Midjourney, and stable diffusion. For this purpose, Delivery Hero uses DALL-E to generate a food image.
Like the GPT-3 model, DALL-E uses Transformer-decoder blocks as its backbone. This is not surprising, as the Transformer architecture is highly versatile and capable of generating data in different modalities, such as texts and images. In essence, DALL-E is trained to generate images from text descriptions.
 Example images generated by DALL-E from text descriptions
Example images generated by DALL-E from text descriptions
Using DALL-E to generate an image is straightforward. The only requirement is to provide a text prompt that describes the image you want it to generate. The prompt used by Delivery Hero to generate a food image is as follows:
a professional photo of {dish} and {dish\_attributes} on a nice plate, {background} background
With this prompt, Delivery Hero generates high-quality images of a dish with specific attributes and backgrounds.
 High-quality images of a dish with specific attributes and backgrounds generated by DALL-E.png
High-quality images of a dish with specific attributes and backgrounds generated by DALL-E.png
Food Image Generation with Image Inpainting
Delivery Hero's second approach to generating food images involves an inpainting technique. Image inpainting refers to the process of replacing specific areas of an image.
Overall, there are four steps implemented by Delivery Hero to generate food images using this approach:
Image selection: Select an image of a dish from their data hub.
Object detection: Detect the food object in the image using an object detection model. As an output, a bounding box of the detected food is obtained.
Image masking: Remove the areas inside the bounding box by replacing the pixel values with black or white.
Image inpainting: Use an image generation model to fill the removed areas of the image with the dish of our choice.
 Image generation with the inpainting technique
Image generation with the inpainting technique
Delivery Hero uses two models for this approach: Grounding DINO for object detection and DALL-E for image inpainting.
Now, let's dissect each point of the image inpainting approach above. We can skip the image selection step, as it is straightforward. The more interesting one is the object detection step using Grounding DINO.
In a nutshell, Grounding DINO is an object detection model that takes a pair of text and images as input. It uses three different input fusion approaches: a feature enhancer, a language-guided query selection, and a cross-modality decoder to effectively combine the text and image input to produce a powerful object detection model.
The high-level architecture of the feature enhancer and cross-modality decoder is quite similar to the Transformer-block architecture, which includes attention layers and feed-forward neural networks. However, both components have sophisticated image-to-text and text-to-image cross-attention layers to fuse the text and image input, as shown in the visualization below
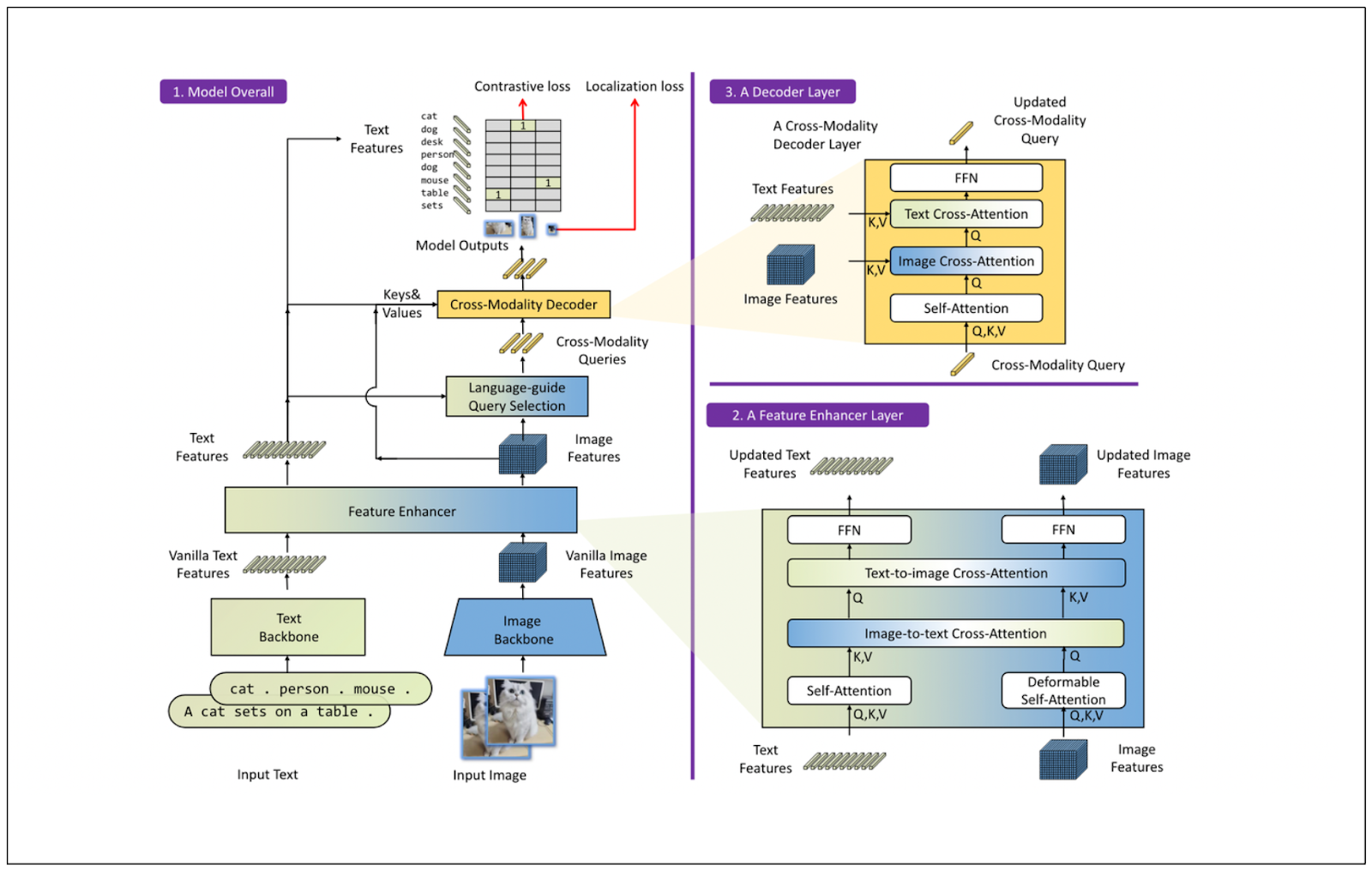 The high-level architecture of the feature enhancer and cross-modality decoder .png
The high-level architecture of the feature enhancer and cross-modality decoder .png
You can easily implement Grounding DINO using HuggingFace. If you’d like to follow along, the code demonstrated in this article can be found in this notebook.
Let’s say we want to detect a cupcake from the image shown below. The following code snippet can obtain the cake's bounding box with Grounding DINO.
!pip install diffusers
import requests
import torch
import os
from PIL import Image
from transformers import AutoProcessor, AutoModelForZeroShotObjectDetection
import numpy as np
from diffusers import AutoPipelineForInpainting
from diffusers.utils import make_image_grid
model_id = "IDEA-Research/grounding-dino-tiny"
processor = AutoProcessor.from_pretrained(model_id)
model = AutoModelForZeroShotObjectDetection.from_pretrained(model_id).to('cpu')
image_url = "<https://farm4.staticflickr.com/3688/9612791241_1484851c78_z.jpg>"
image = Image.open(requests.get(image_url, stream=True).raw)
# Check for a cake
text = "a cake."
inputs = processor(images=image, text=text, return_tensors="pt").to('cpu')
with torch.no_grad():
outputs = model(**inputs)
results = processor.post_process_grounded_object_detection(
outputs,
inputs.input_ids,
box_threshold=0.4,
text_threshold=0.3,
target_sizes=[image.size[::-1]]
)
print(results)
"""
Output:
[{'scores': tensor([0.8716]), 'labels': ['a cake'], 'boxes': tensor([[244.4494, 233.1335, 360.1640, 333.2773]])}]
"""
 Using Grounding DINO to detect a cupcake from the image.png
Using Grounding DINO to detect a cupcake from the image.png
We can detect the cake object in the image provided!
Next, we can remove the object detected by Grounding DINO using the masking method. After applying the masking method, we should obtain an image output with contrasting pixel values for the area between the outside and inside of the detected bounding box.
left, top, right, bottom = results[0]["boxes"][0].tolist()
left = int(left)
top = int(top)
right = int(right)
bottom = int(bottom)
# Create an empty black image
image_url = "<https://farm4.staticflickr.com/3688/9612791241_1484851c78_z.jpg>"
image = Image.open(requests.get(image_url, stream=True).raw)
width, height = image.width, image.height # You can set the desired dimensions of the image
mask = np.zeros((height, width), dtype=np.uint8)
# Set the area inside the bounding box to white (255)
mask[top:bottom, left:right] = 255
mask_image = Image.fromarray(mask)
 Mask the content detected by Grounding DINO.png
Mask the content detected by Grounding DINO.png
Now that we have the masked version of the image, let's implement the image inpainting step.
Since DALL-E is not an open-source model and consuming its API is not free, we will replace this model with an open-source image generation model in the following example. Specifically, we will implement the Stable Diffusion model for image inpainting with the help of HuggingFace.
Let’s say we want to replace a cupcake in the image with a cup of coffee. We can do so with the following code:
pipeline = AutoPipelineForInpainting.from_pretrained(
"runwayml/stable-diffusion-inpainting", torch_dtype=torch.float16, variant="fp16"
)
pipeline = pipeline.to("cuda")
generator = torch.Generator("cuda").manual_seed(92)
prompt = "a coffee, 8k"
inpaint_image = pipeline(prompt=prompt, image=image, mask_image=mask_image, generator=generator).images[0]
newsize = (image.width, image.height)
inpaint_image = inpaint_image.resize(newsize)
make_image_grid([image, inpaint_image], rows=1, cols=2)
 Replace the cupcake in the image with a cup of coffee using Stable Diffusion.png
Replace the cupcake in the image with a cup of coffee using Stable Diffusion.png
That's all we need to do to recreate the image inpainting method implemented by Delivery Hero!
The quality of AI-generated images implemented by Delivery Hero is very good. With this approach, they can recommend a catalog of high-quality food images of a product that vendors can choose from.
However, they encounter one significant problem during the food image generation process: the safety aspect. We will discuss this issue in the next step.
Building a Safety System
The sophisticated image generation approach discussed in the previous section relies on a text prompt. This means that sometimes, the image generation model may misunderstand our intention.
For example, let's say we want to generate a food image of a chicken on a plate. Without any safety control, the model might generate images as follows:
 The image we want vs. the image generated by AI without any safety control .png
The image we want vs. the image generated by AI without any safety control .png
Therefore, we need a component to control the image quality generated by the model. This is where the safety system comes into play.
Delivery Hero implements the safety system based on four components: image tagging, image centering, text detection, and image sharpness. In the meetup presentation, the Delivery Hero team focused on two components: image tagging and image centering.
Image Tagging
The first approach implemented by Delivery Hero as a safety system is tagging the image generated by the image generation model. Image tagging refers to the process of predicting an image's tags with the help of a machine-learning model. For this purpose, Delivery Hero utilized a model called the Recognize-Anything Plus Model (RAM++).
RAM++ is a powerful image tagging model with exceptional zero-shot generalization. Thanks to its LLM integration, it can recognize 4,585 unique tags.
RAM++ receives three different inputs during the training process: image, text, and tag. The combination of text and tag enriches the scope of visual concepts that can be inferred from an image. To improve the model's generalization even more, RAM++ utilizes ChatGPT to create different varieties of descriptions of each tag based on five different prompts:
Describe concisely what a(n) {tag} looks like.
How can you identify a(n) {tag} concisely?
What does a(n) {tag} look like concisely?
What are the identified characteristics of a(n) {tag}?
Please provide a concise description of the visual characteristics of {tag}.
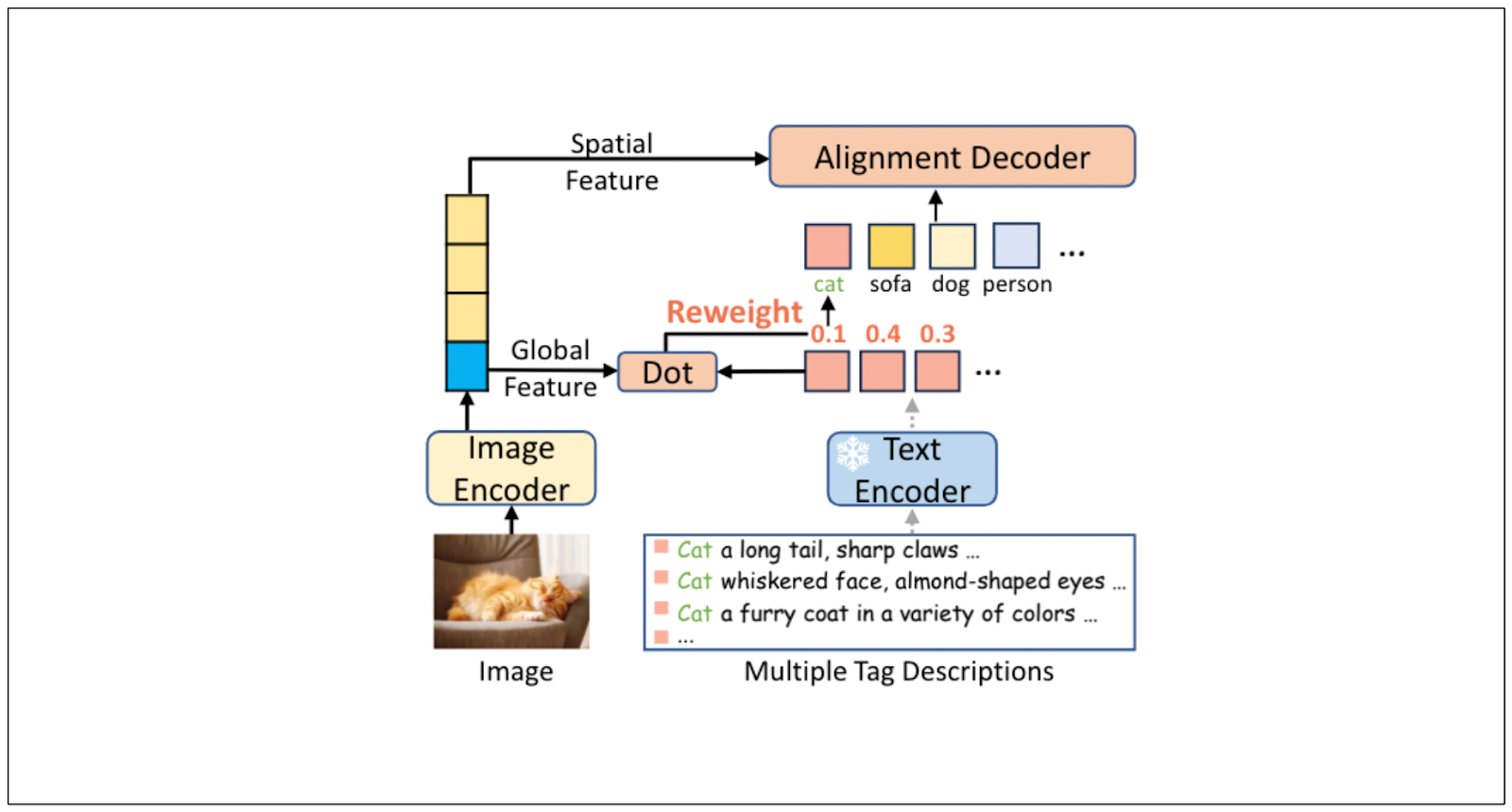 Image tagging- tag-to-text:RAM:RAM++ architecture .png
Image tagging- tag-to-text:RAM:RAM++ architecture .png
These tag descriptions generated by GPT 3.5 Turbo expand the semantic meaning of each tag, therefore improving the scope of an image's visual concepts.
The text and tag descriptions are then passed into a text encoder, while the image is passed into an image encoder. The results from these encoders are then fused inside a so-called alignment decoder block that consists of cross-attention and feed-forward layers to generate the final tags of the image.
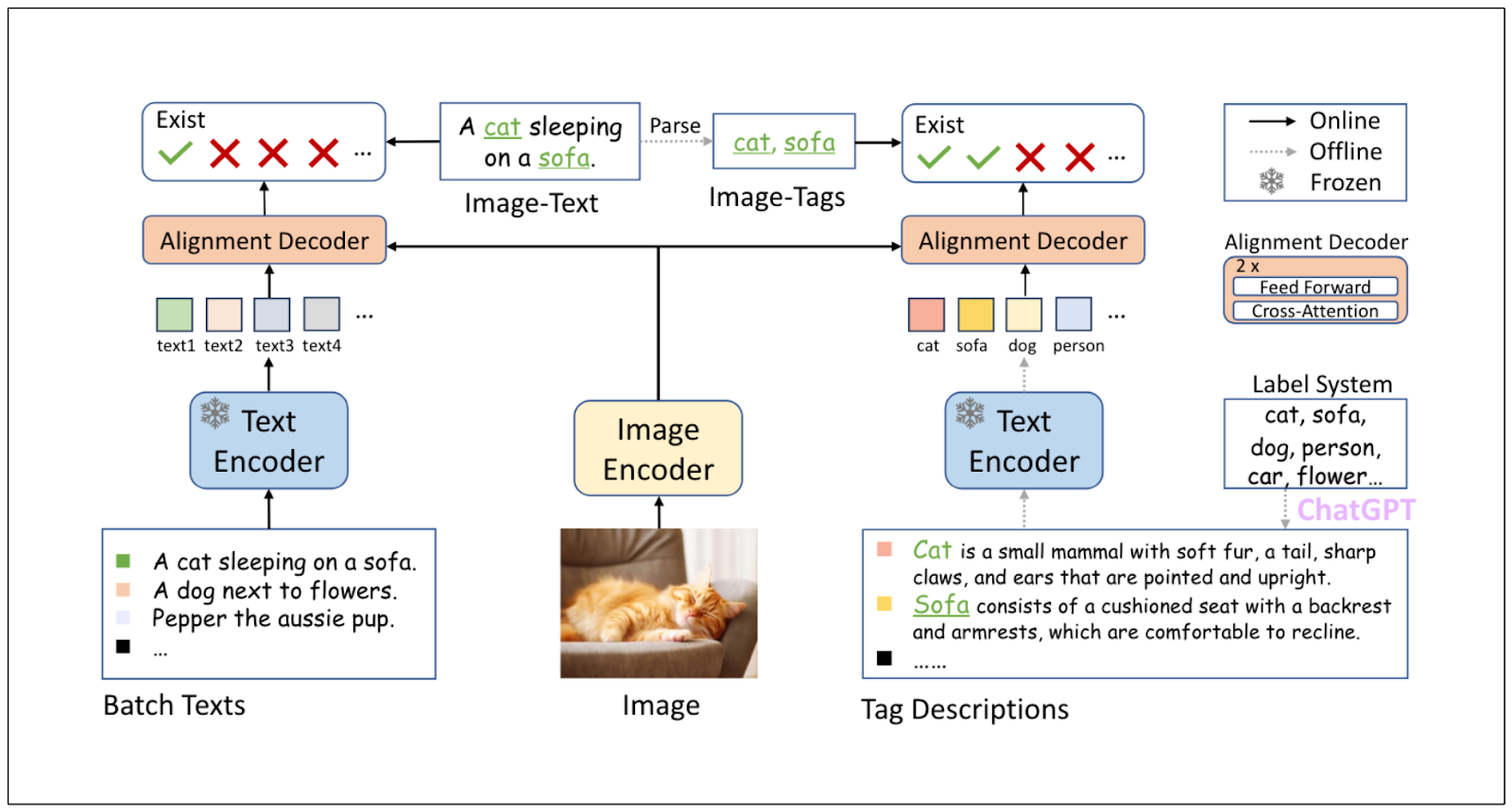
To implement RAM++ to generate an image tag, we must first install the recognize-anything library and then use the command line to generate the image tag. In the following example, we’ll predict the image tag we used in the previous section.
!git clone <https://github.com/xinyu1205/recognize-anything.git>
%cd recognize-anything
!pip install -e .
if not os.path.exists('pretrained'):
os.makedirs('pretrained')
if not os.path.exists('images'):
os.makedirs('images')
# Download swin transformers checkpoint
!wget <https://huggingface.co/xinyu1205/recognize-anything-plus-model/resolve/main/ram_plus_swin_large_14m.pth> -O pretrained/ram_plus_swin_large_14m.pth
# Download input image
!wget <https://farm4.staticflickr.com/3688/9612791241_1484851c78_z.jpg> -O images/cupcake_and_coffee.jpg
%cd recognize-anything
# Image tagging inference
!python inference_ram_plus.py --image images/cupcake_and_coffee.jpg \\
--pretrained pretrained/ram_plus_swin_large_14m.pth
In the example command above, we use the Swin-Transformer model as the image encoder, and below is the output that we should get:
 The tags generated by the Swin-Transformer model .png
The tags generated by the Swin-Transformer model .png
As you can see, we get tags such as “beverage,” “cloth,” “coffee,” “coffee cup,” “cup,” “cupcake,” “table,” “dining table,” “plate,” etc. for our images.
Among all 4585 tag categories, data scientists at Delivery Hero identified 10 "food" tags and 50 "negative" tags. The "negative" tags include several tags associated with animals, such as “bug”, “beetle”, “ant”, “hornet”, etc.
 Image tagging with the Swin-Transformer model.png
Image tagging with the Swin-Transformer model.png
Then, they assigned a score for each AI-generated food image based on the tags predicted by the RAM++ model.
The score is 1 if the image contains at least one "food" tag and no "negative" tags.
The score is 0 if the image contains a "negative" tag.
Image Centering
Another component implemented by data scientists at Delivery Hero to enhance the safety of AI-generated images is image centering. In this component, the proportionality of the generated image is assessed. As you might already know, food in the center of an image is more appealing than one at the edge or cut from the image.
To assess the image proportionality, Delivery Hero utilizes Grounding DINO, described in the previous section, to detect the food object in an image. Then, the bounding box produced by the model will be assessed to determine the quality of the image.
The scoring system is as follows:
0 if no food or plate object is detected
0.5 if the bounding box touches the image edge
1 if the bounding box is in the center of the image
The final step is combining each component's score with a weighted function. At the end, each image has a weighted score from the four components. By applying a threshold value, an image with a weighted score below that threshold would be filtered out and not recommended to the vendors.
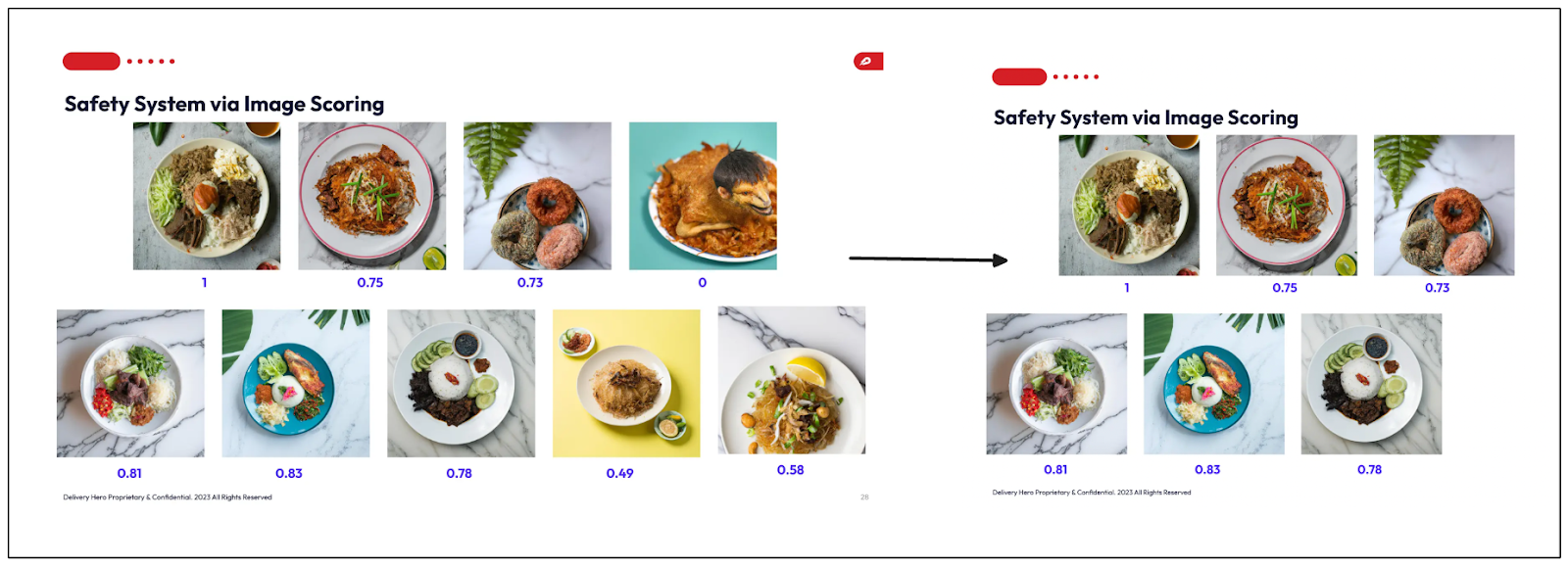 Image scoring.png
Image scoring.png
Conclusion
In this article, we've discussed how two data scientists at Delivery Hero use AI models to generate high-quality food images to improve user experience and conversion rate. Their approach consists of two stages: food image generation and building a safety system.
They used DALL-E from OpenAI to generate the image and implemented an image inpainting method with the help of Grounding DINO and DALL-E. The team adopted four components to generate a final score to determine the safety of a generated image: image tagging, image centering, text detection, and image sharpness. The scores obtained from these four components are then combined with a weighted function to give each image one final score value. By applying a threshold, an image with a final score below the threshold will be filtered out and not recommended to vendors.
You can access the code demonstrated in this article via this notebook.
You can watch the replay of the Delivery Hero team’s talk on YouTube.
Keep Reading

Zilliz Cloud Now Available in AWS Europe (Ireland)
Zilliz Cloud launches in AWS eu-west-1 (Ireland) — bringing low-latency vector search, EU data residency, and full GDPR-ready infrastructure to European AI teams. Now live across 30 regions on five cloud providers.

Context Engineering Strategies for AI Agents: A Developer’s Guide
Learn practical context engineering strategies for AI agents. Explore frameworks, tools, and techniques to improve reliability, efficiency, and cost.

Introducing DeepSearcher: A Local Open Source Deep Research
In contrast to OpenAI’s Deep Research, this example ran locally, using only open-source models and tools like Milvus and LangChain.