




Dissecting OpenAI's Built-in Retrieval: Unveiling Storage Constraints, Performance Gaps, and Cost Concerns
After the latest announcements from OpenAI, I started to question whether OpenAI Assistants are suitable for production-level applications, with their limitations, specifically the 20-file limit and the $0.2 per GB price per day. With this in mind, I wrote an article focusing on three topics.
Is $0.2/GB/day for the OpenAI Assistants' knowledge base expensive?
Digging into OpenAI's internal solutions based on their released information.
In what direction should the infrastructure of AI Assistants' knowledge base evolve?
Note: The following content contains some calculations. You are welcome to go through these detailed computations, or you may choose to focus on the highlighted conclusions for a quick overview.
The Cost of OpenAI Assistants' Knowledge Base
Let's do some simple math:
Office 365 charges $6 per TB of data per month. Google Workspace charges $8 per TB of data per month.
For OpenAI Assistants, the cost is 0.2 ($) x 30 (days) x 1024 (GB) = $6,144 per TB per month.
Therefore, adding an AI assistant to my office documents using OpenAI Assistants would cost three orders of magnitude more than a traditional document service ($6 vs. $6,144). Is this expensive? I say, "Yes!" this seems excessively high.
| Services | Pricing |
|---|---|
| Traditional document services | $6 /TB |
| OpenAI Assistants | $6,144/TB |
Let's also briefly calculate the operational cost from OpenAI's side. The following analysis is a bit complex, but the conclusion is simple: Serving 1 GB of documents requires generating 1.5 GB of vectors, and the server cost for serving these vectors is about $0.30 per day. Expensive? It's a bargain compared to the $0.20/GB price tag. Interesting!
| Pricing | |
|---|---|
| OpenAI’s cost | $0.3/GB per day |
| OpenAI’s pricing | $0.2/GB per day |
Here is the estimate:
Consider 1 GB of text using OpenAI's text-embedding-ada-002 model to generate the vectors for retrieval. For every 1 KB of text, this model will create a 1536-dimensional embedding. Each vector dimension corresponds to one float32 (thus 6KB per vector), resulting in the size ratio of input text to output vectors being 1:6, i.e., 1 GB of text corresponds to 6 GB of vectors. Compressing the vectors via quantization can achieve a 4:1 compression ratio, signifying that 1 GB of text corresponds to 1.5 GB of vectors.
Let's consider the server cost for serving 1.5 GB of vectors. Opting for an economical AWS EC2 instance costs approximately $0.30 daily for every 1.5 GB of memory. This scenario is more than fair, as it only assumes the vector storage and search. It does not include other elements like metadata, monitoring, logs, index files, and the cost of high availability with multi-replicas, all needed in production environments.
Costs Analysis Conclusion
OpenAI's new Assistants feature is costing the company more money than it's making due to the high server cost of $0.3/GB/day, compared to the pricing of $0.2/GB/day. However, developers who want to use the Assistants must pay over 1,000 times more than traditional document services. Therefore, they must generate business value that's three orders of magnitude higher than conventional document services to justify the cost.
This pricing model may be justifiable for B2C businesses, as a few GBs of data costing tens of dollars per month is unlikely to be a significant issue for individual users. However, for B2B businesses dealing with large-scale data, this cost could significantly erode business revenue or even surpass the business's value. For example, creating personalized customer service or an intelligent search system for patents and legal documents could become prohibitively expensive.
Digging into OpenAI's solution
Let's pick apart OpenAI Assistants’ current scheme. Here is some publicly available information:
A maximum of 20 files per assistant
A cap of 512MB per file
A hidden limitation of 2 million tokens per file, uncovered during our testing
Only text is supported.
The server traffic experienced a significant increase following OpenAI DevDay. The number of trial users and the corresponding assistants being created has not been disclosed, but it should have been significant.
Dissecting the OpenAI’s retrieval service
Let’s do some math based on the above public information.
- Users are limited to 20 files, each capped at 2 million tokens. Assuming 200 tokens per chunk (corresponding to a vector), there's a limit of 200,000 vectors per user.
| Files Limit Per User | Number of Tokens | Number of Vectors |
|---|---|---|
| / | 200 | 1 |
| 1 file | 2,000,000 (upper limit) | 10,000 |
| 20 files | 40,000,000 (upper limit) | 200,000 |
- Since most users will not reach the 2 million token limit per file, we can estimate that each user’s file will contain an average of 400,000 tokens, which translates to 2,000 vectors. Considering the upper limit of 200,000 vectors per user and the average of 2,000 vectors per user, achieving an overselling ratio of 1000:1 is feasible.
| Files Limit Per User | Number of Tokens | Number of Vectors |
|---|---|---|
| / | 200 | 1 |
| 20 files | 400,000 (on average) | 2,000 |
In addition, OpenAI has a substantial user base, which requires the company to maintain a stable system and effectively manage the impact of any disasters. Therefore, during the initial phases of OpenAI Assistants' development, they are unlikely to opt for a super-large cluster solution. Instead, OpenAI would likely create a system (shown below) where each group of users can share a minor vector database instance for better stability.
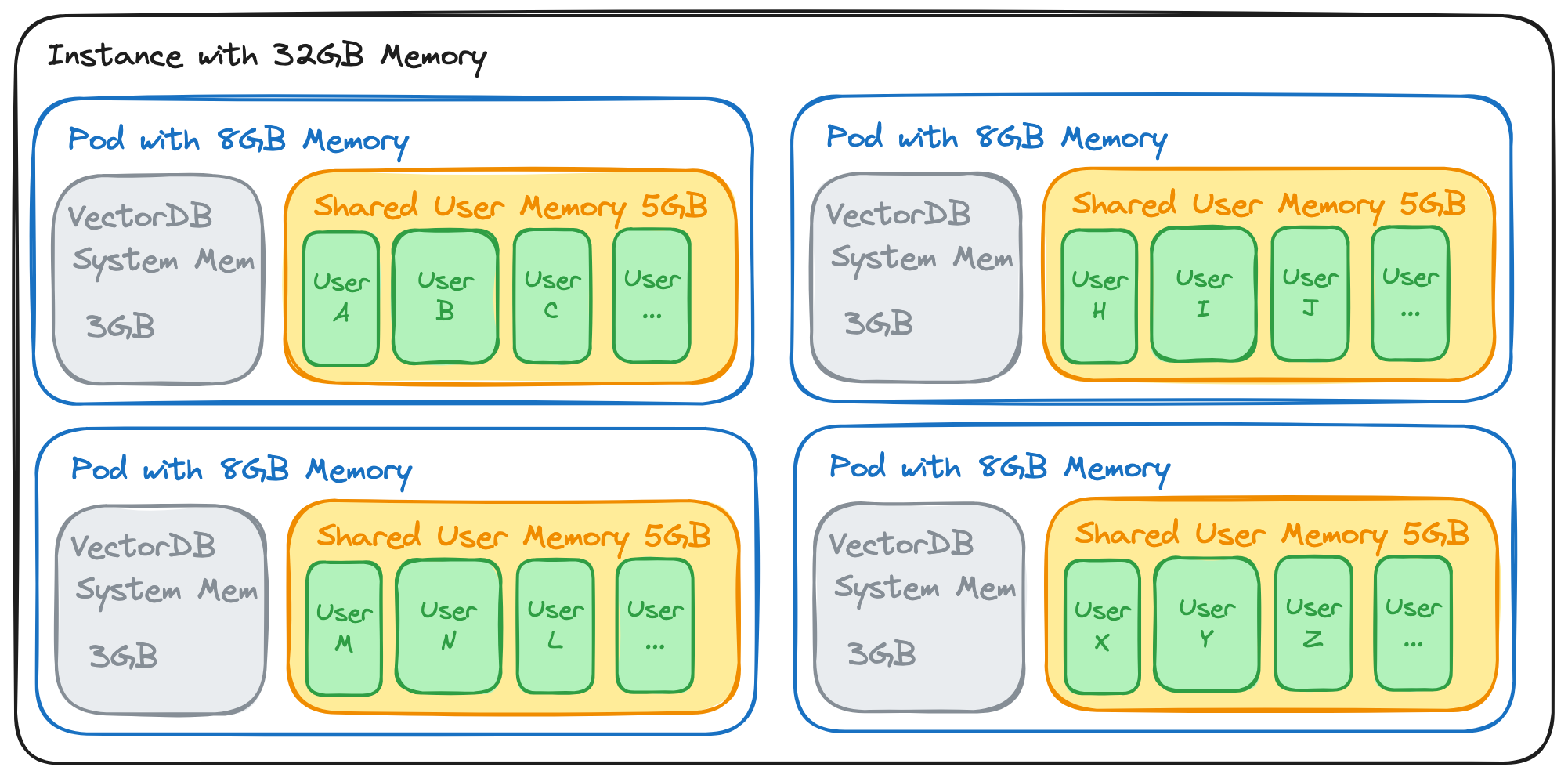 A Simplified Architecture of OpenAI Assistants’ Retrieval Feature
A Simplified Architecture of OpenAI Assistants’ Retrieval Feature
Let's assume that each physical node has 32 GB of memory and is divided into four Pods. Each Pod hosts a separate vector database instance, where a Pod is allocated 8 GB of memory. 3 GB is dedicated to the vector database system, and 5 GB is reserved for serving user vector data.
With a cap of 200,000 vectors per user, quantized vectors and their indices require approximately 500 MB of memory. Therefore, each Pod can accommodate ten users without overselling. However, with an overselling ratio of 1000:1, a single Pod can serve up to 10,000 users (with at least hundreds of active users). As a result, a single server comprising four Pods can accommodate 40,000 users.
This architecture seems adequate for supporting trial users. However, each physical node has the potential to store up to 20 GB of vectors and indices for paying customers, corresponding to roughly 8 GB of original text. Under total capacity, the daily revenue potential is a modest $1.6, which is notably low.
Note: In extreme cases where multiple users with large files share a single Pod, we can mitigate the potential challenges through scheduling. For example, deploying a new Pod can efficiently migrate the load from these larger users.
Quick Summary
OpenAI's retrieval service architecture can work well for trial users but may not scale well enough to support larger businesses with more extensive data requirements.
The current architecture imposes storage limits on user data, reducing potential profits and increasing costs.
Additionally, the architecture is inadequate for application-layer multitenancy, as some customers may require a separate assistant for each client. See more discussions in the OpenAI forum.
Why OpenAI Assistants' knowledge base is not good enough
We previously discussed the limitations of OpenAI Assistants and its architecture. So, how can we address this challenge and reduce costs? The most effective solution would be to optimize the service's architecture.
Before delving into the solution, consider crucial factors that pave the way for an optimized system architecture.
A Refined Vector Database Solution: Hybrid Disk/Memory Vector Storage
Vector databases usually load vectors and indices into memory to expedite query responses. However, Assistant applications are a typical Retrieval Augmented Generation (RAG) use case, so the performance bottleneck lies in the inference of large language models (LLMs) rather than the vector database querying process. In such cases, ultra-fast vector search responses are not required. By intentionally degrading the vector database performance to align with LLMs, we can achieve a balance between cost-effectiveness and expanded storage capabilities. One promising avenue is exploring a disk-based vector database solution, where only hot data is loaded into memory. This approach not only substantially reduces hardware costs but also augments the system's overall storage capacity.
Streamlining Disaster Recovery: Pooling System Data
Presently, OpenAI Assistant employs a somewhat brute-force approach for disaster recovery, assigning each Pod a separate vector database instance and allocating over 1/3 of the memory in each Pod for system use. However, considering only user data requires separation, a more nuanced strategy involves pooling system components together. This approach enhances high availability, allowing these components to function independently, unshackled from individual Pods.
Multi-Tenancy Support for Diverse User Base
The architectural framework should seamlessly cater to both numerous small users and large businesses with large-scale data. Multi-tenancy support at the application layer is a fundamental requirement for Agent applications, especially those with substantial user bases.
Following this line of thought, let's sketch out an architecture diagram.
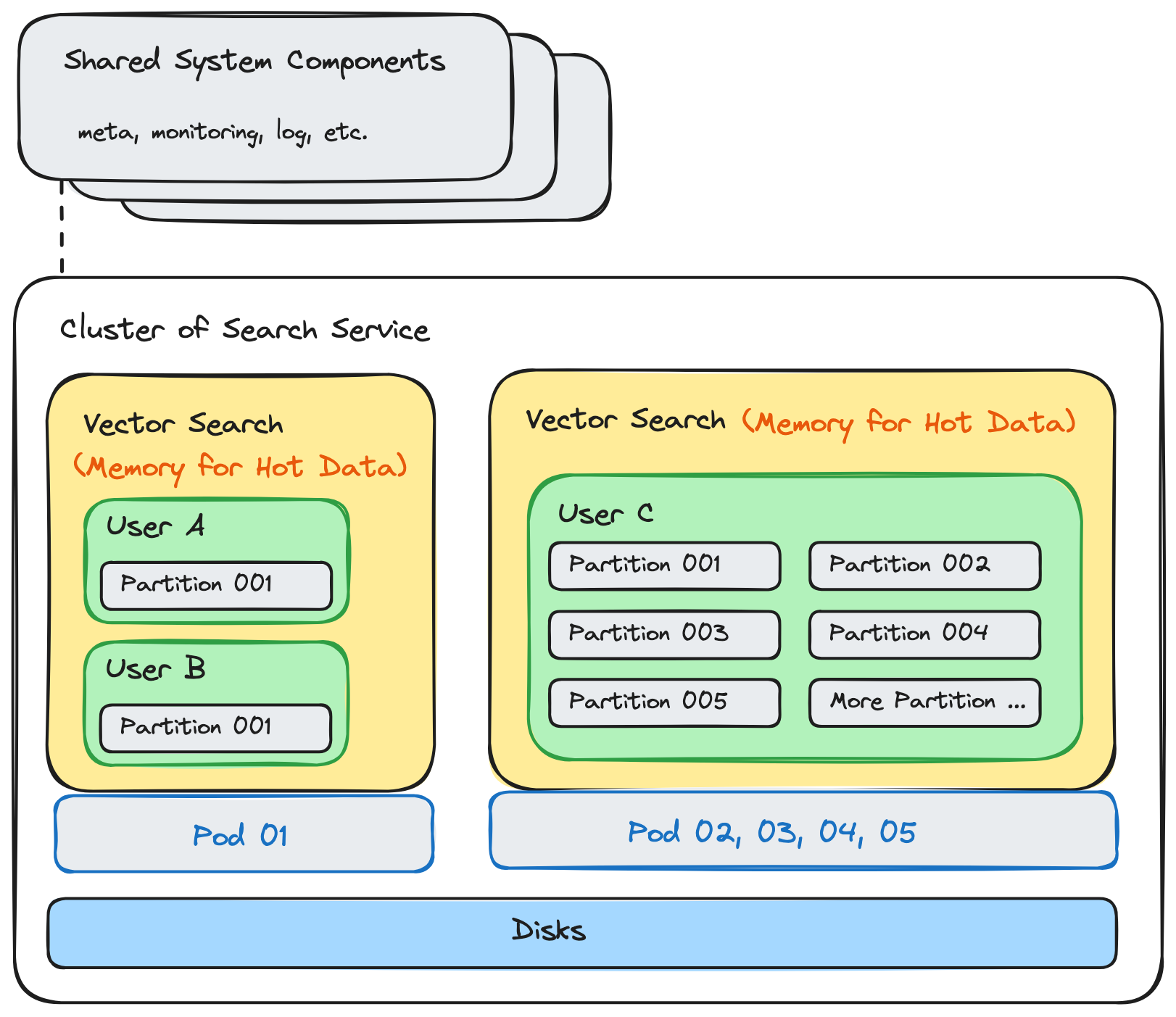 The optimized architecture of OpenAI Assistants’ retrieval feature
The optimized architecture of OpenAI Assistants’ retrieval feature
Let's spotlight some key modifications:
Separation of system and query components. Previously co-located within each Pod, system components are now pooled independently, reducing their resource footprint from 1/3 to less than 1/10 compared to the previous scheme.
Improved Flexibility for Query Components: Query components can now be dynamically allocated based on different Pod numbers, enjoying physical isolation for independent scalability. The control over the blast radius is finely managed at the granularity of query components. Their simplified structure enhances reliability compared to more complex system components.
Hybrid Memory/Disk Architecture: Introducing a hybrid memory/disk architecture, where memory exclusively loads hot data, is another crucial modification. This enhancement allows the same amount of memory to serve 5 to 10 times the original text compared to the previous solution.
Multi-Partition Support for Multi-Tenancy: Adding multi-partition support caters to multi-tenancy at the application layer. Each upper-level user can now be assigned an independent data partition, providing a low-cost solution at the application layer. Physical isolation is achieved by assigning one query component per group of users.
Recalculating the data support with this architecture, a query node with 32 GB of memory, augmented by disk space, can now efficiently support 320 GB of vectors and indices, equivalent to 128 GB of the user's original text. The pooled system component resources allocated to these query nodes amount to 3 GB, physically distinct from the query nodes. In total, 35 GB of memory can accommodate 128 GB of user data, translating to approximately 3.6 GB of user data per GB of memory. In contrast, the previous design allowed 32 GB of memory to support 8 GB of user data, averaging 250 MB of user data per GB of memory. This reflects a remarkable 15-fold increase in efficiency.
An overview of popular vector databases: Milvus, Chroma, and Qdrant
Vector databases play a pivotal role in optimizing the architecture of OpenAI Assistants, making the choice of the most robust option paramount. Here, we delve into three prominent open-source vector databases—Milvus, Chroma, and Qdrant—assessing their strengths and limitations in enhancing the OpenAI Assistants architecture.
Milvus
Pros: Milvus is the most mature open-source vector database, widely embraced in large-scale distributed systems. Notable features include the effective separation of system and query components, isolation of query components through the Resource Group feature, a hybrid memory/disk architecture, and application-level multi-tenancy facilitated by RBAC and Partition features.
Cons: Despite its strengths, Milvus falls short in achieving complete anomaly isolation through the Resource Group-based isolation of query components. Furthermore, it introduces some third-party dependencies, such as Etcd and MinIO, resulting in elevated deployment and operational costs.
Chroma
Pros: Chroma emerges as a new and user-friendly project, celebrated for its simplicity. It caters well to rapid prototyping and quick AI application iteration, gaining popularity among individual developers.
Cons: Chroma excels in smaller-scale scenarios but is not designed for large-scale enterprise applications. It lacks key features such as distributed deployment, component separation, hybrid memory/disk architecture, and application-level multi-tenancy.
Qdrant
Pros: Qdrant, as a newcomer, offers support for small-scale distributed deployment with a streamlined setup process. It also boasts a hybrid memory/disk architecture, aligning it with modern database requirements.
Cons: Currently, Qdrant does not support crucial features like component separation or application-level multi-tenancy, limiting its applicability in certain use cases.
In evaluating these vector databases, it becomes evident that each solution brings its unique strengths and trade-offs to the table, making the choice contingent on specific requirements and priorities within the context of optimizing OpenAI Assistants' architecture.
Summary
In this blog post, we delved into the intricacies of OpenAI Assistants, exploring its pricing, architecture, and potential optimizations for cost-efficiency and enhanced storage capabilities. A key revelation emerged as the cost of vector database infrastructure significantly influences the deployment of knowledge bases and Agent applications.
Upon analyzing OpenAI's costs and profits related to Assistants, we uncovered a notable imbalance, with expenditures exceeding potential revenue. While this may be justifiable during the trial phase, accommodating new customers and community expansion, a more sustainable balance is essential.
The blog post proposes a solution to optimize the architecture, presenting the prospect of achieving a tenfold decrease in costs for these application types compared to existing solutions. The pivotal role of vector databases in this optimization process is underscored, with Milvus emerging as a particularly suitable option among available alternatives.
Nevertheless, acknowledging the inherent limitations of existing vector databases, this post emphasizes that no single vector database solution can comprehensively address all challenges and meet every design requirement for imminent infrastructure development. The choice of vector databases should be tailored to specific requirements to effectively navigate the complexities of optimizing OpenAI Assistants' architecture.

Keep Reading

From Vector Database to Vector Lakebase
Zilliz offers a fully managed Vector Lakebase powered by Milvus, unifying real-time vector search, lake-scale discovery, and Al data operations.

Top 10 Context Engineering Techniques You Should Know for Production RAG
A practical guide to context engineering for production LLM systems, covering RAG, context processing, memory, agents, and multimodal context.

DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding
Explore DeepSeek-VL2, the open-source MoE vision-language model. Discover its architecture, efficient training pipeline, and top-tier performance.