




10 Tips for Running a Vector Database on Kubernetes
Vector databases are designed for similarity search, making them essential for applications like recommendation systems, image retrieval, and AI-driven search. Running a vector database on Kubernetes allows for scalability and automation, but it requires careful configuration to maintain consistent performance. Unlike stateless applications, vector databases rely on persistent storage, efficient resource management, and optimized query execution, making their deployment more complex.
Kubernetes provides tools for managing workloads, but ensuring a vector database runs efficiently involves more than just deployment. Factors like storage performance, autoscaling, security, and monitoring must be properly configured to prevent bottlenecks and maintain stability. Without these optimizations, resource contention, inefficient indexing, and slow query execution can degrade performance.
In this article, we will explore best practices for deploying and managing a vector database on Kubernetes. This includes StatefulSet deployments, storage configurations, autoscaling strategies, security measures, and performance tuning to help ensure a reliable and scalable system.
1. Leverage StatefulSets for Reliable Deployment
Vector databases require stable network identities and persistent storage, making StatefulSets the preferred method for deploying them on Kubernetes. Unlike Deployments, which create interchangeable pods, StatefulSets assign each pod a fixed identity and ensure that data is not lost when a pod is restarted or rescheduled. This stability is essential for distributed databases that rely on consistent pod names and persistent storage.
Since vector databases often involve multiple interconnected services, using a StatefulSet allows each database instance to retain its unique identifier (pod-0, pod-1, etc.) and reconnect to its storage even if it moves to a different node. This consistency helps maintain query performance and prevents data corruption.
Example: Using StatefulSets in Milvus
The following snippet provides a simplified example of how Milvus, the leading open-source vector database with over 35K GitHub stars, uses StatefulSets for its dependencies rather than defining them manually. The Milvus Operator automatically configures StatefulSets where needed, ensuring stable deployments without requiring direct StatefulSet definitions for Milvus itself.
apiVersion: milvus.io/v1beta1
kind: Milvus
metadata:
name: milvus-cluster
spec:
dependencies:
storage:
inCluster:
values:
mode: distributed
replicaCount: 3 # Ensures MinIO runs as a StatefulSet for storage
In this example, the Milvus resource instructs the Milvus Operator to deploy storage using distributed MinIO. The mode: distributed and replicaCount: 3 configuration ensures that MinIO runs with multiple replicas for high availability and persistent storage. The operator automatically handles the underlying deployment configurations for MinIO and other dependencies without requiring manual StatefulSet definitions.
Why StatefulSets Are Essential
StatefulSets provide several benefits that help maintain stability, data integrity, and efficient scaling in a vector database deployment:
Stable Network Identity: This ensures each pod has a predictable DNS name for seamless internal communication.
Persistent Storage: Retains volume claims even if pods restart, preventing data loss.
Controlled Scaling and Upgrades: Ensures new replicas maintain stability and existing data remains intact.
StatefulSets provide a solid foundation for running vector databases, but their effectiveness depends on properly configured storage. Let’s now explore how to optimize persistent storage for performance and reliability.
2. Configure Persistent Storage for Performance
Persistent storage plays a crucial role in vector databases, as they handle large datasets and perform frequent read and write operations. The right storage setup ensures that indexing, query execution, and data retrieval are efficient, minimizing bottlenecks. Since Kubernetes provides multiple storage options, it’s important to select one that balances performance, durability, and scalability based on the database’s workload.
Choosing the Right Storage Backend
Vector databases commonly use a combination of object storage, block storage, and distributed file systems, each suited for different parts of the system. Object storage (e.g., MinIO, AWS S3) is typically used for storing vector embeddings and indexes due to its scalability, while block storage (e.g., SSD-backed PersistentVolumes) is better suited for metadata and logs. Local SSDs provide the lowest latency but are node-specific, making failover complex. Network-attached storage (NAS) allows persistence across nodes but can introduce network latency. Understanding these trade-offs helps in designing a storage strategy that ensures high availability and fast query performance.
Key Considerations for Persistent Storage
When configuring storage for a vector database on Kubernetes, certain factors directly impact performance and reliability:
Storage Class Selection: Choose a storage class optimized for database workloads, such as SSD-backed or provisioned IOPS storage, to ensure low-latency access.
Read/Write Access: Ensure the database storage allows concurrent access if multiple nodes need to read and write to the same dataset.
Snapshot and Backup Support: Use storage backends that support automated snapshots, making recovery from failures or corruption faster.
If you’re setting up object storage for Milvus, there is a dedicated guide that outlines the process in detail: Configuring Object Storage with Milvus Operator.
Storage efficiency plays a major role in how well a vector database performs, but managing compute resources is just as important. The next tip focuses on optimizing resource requests and limits to maintain a stable and responsive system.
3. Optimize Resource Requests and Limits
Effectively managing CPU and memory resources is crucial for maintaining the performance and stability of vector databases running on Kubernetes. Properly setting resource requests and limits ensures that database pods have the necessary resources to handle operations like indexing and querying while also preventing them from consuming excessive resources that could affect other workloads in the cluster.
Balancing CPU and Memory Allocation
Vector databases are computationally intensive, especially when processing large-scale similarity searches. To avoid performance issues, it's important to define appropriate requests (minimum guaranteed resources) and limits (maximum resources a pod can consume).
Key Considerations for Resource Requests and Limits
When configuring resource allocations for your vector database, consider the following:
Set CPU and Memory Requests: Define requests to ensure the database pod always has the minimum resources it needs. For example, a pod running an indexing job might require at least
4 CPUand16Giof memory.Use Limits Cautiously: Limits prevent a pod from consuming too many resources, but setting them too low can cause throttling. For query-heavy workloads, avoid setting strict CPU limits, as it may lead to slow response times.
Monitor and Adjust Based on Load: Resource needs change based on query volume and dataset size. Use Kubernetes monitoring tools to track performance and adjust resource settings as needed.
For instance, if you're deploying a vector database like Milvus, you can utilize the Milvus Sizing Tool to estimate resource requirements based on your specific dataset characteristics.
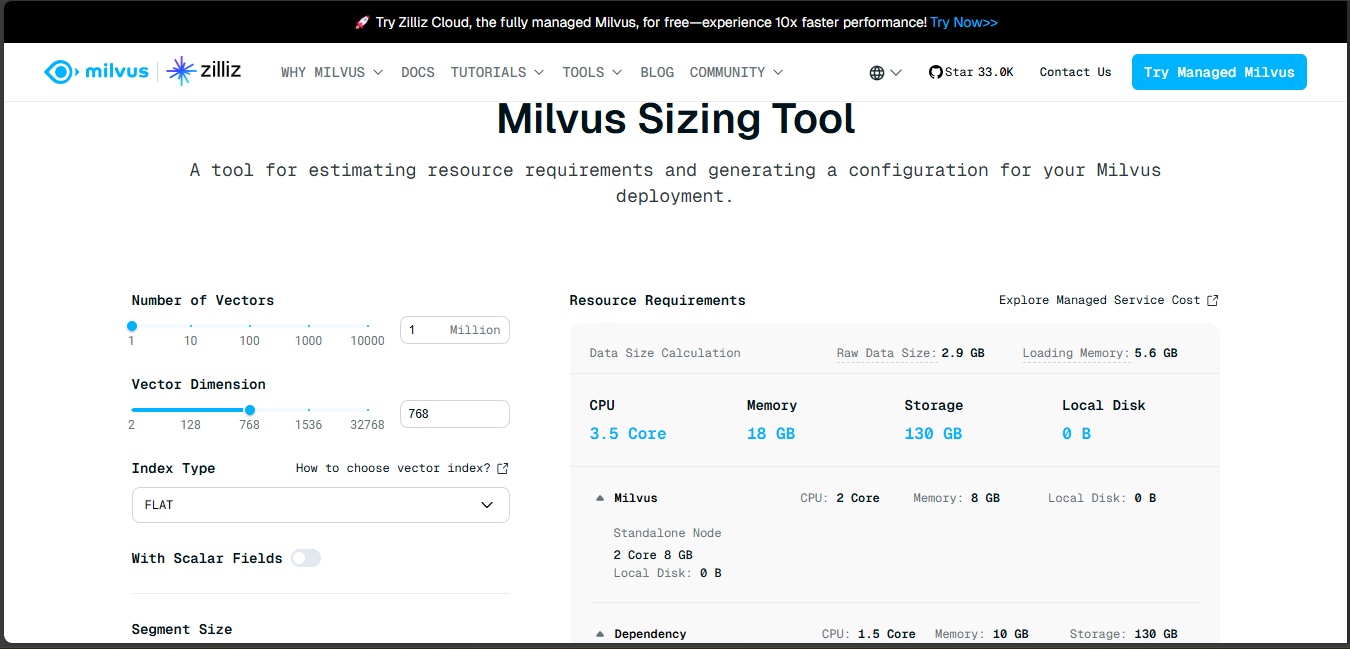 Figure- Milvus sizing tool
Figure- Milvus sizing tool
Figure: Milvus sizing tool
This tool allows you to input parameters such as the number of vectors, vector dimensions, and index types to generate a tailored configuration, ensuring that your deployment is optimized for your workload.
By carefully setting resource requests and limits, you can maintain a stable and efficient environment for your vector database, ensuring it performs optimally under varying workloads.
4. Implement Autoscaling for Efficient Resource Utilization
Workloads in a vector database can fluctuate significantly based on query volume, indexing jobs, and data ingestion rates. Fixed resource allocations may lead to inefficient utilization, either over-provisioning that wastes resources or under-provisioning that degrades performance. Autoscaling helps dynamically adjust resources based on real-time demand, ensuring that the database remains responsive while optimizing costs.
Scaling Approaches for Vector Databases
Autoscaling in Kubernetes can be applied at different levels, depending on how the database is structured. The following are commonly used autoscaling mechanisms:
Horizontal Pod Autoscaler (HPA): Adjusts the number of pods based on CPU, memory, or custom metrics. For example, if query traffic increases, additional read replicas can be provisioned automatically.
Vertical Pod Autoscaler (VPA): Adjusts CPU and memory allocations for individual pods instead of scaling the number of replicas. This is useful for optimizing indexing or query workloads that require more compute power.
Cluster Autoscaler: Ensures that new pods can be scheduled by scaling worker nodes when resource demands exceed the available capacity.
Choosing the right autoscaling approach depends on the database workload. For instance, read-heavy workloads often benefit from HPA, while compute-intensive indexing tasks may require VPA to dynamically allocate more CPU and memory as needed.
Key Considerations for Autoscaling
Autoscaling should be configured carefully to avoid excessive scaling or performance bottlenecks. The following factors help maintain an optimal balance between performance and resource efficiency:
Define Scaling Triggers: Set thresholds for CPU, memory, or custom metrics like query response time to determine when scaling should occur.
Balance Performance and Cost: Autoscaling should prevent excessive scaling that leads to unnecessary costs while ensuring that the database can handle peak loads.
Test Scaling Behavior: Monitor how the database reacts to autoscaling events to prevent disruptions in indexing or query performance.
Dynamic scaling helps a vector database efficiently handle changing workloads, but maintaining visibility into performance is equally important. Monitoring and logging play a key role in tracking database health and diagnosing potential issues.
5. Ensure Robust Monitoring and Logging
Monitoring and logging are essential for maintaining the performance and stability of a vector database running on Kubernetes. Without proper observability, issues like slow queries, resource bottlenecks, or node failures can go unnoticed, leading to degraded performance or downtime. A well-configured monitoring and logging setup allows for proactive troubleshooting and optimization.
Monitoring Key Metrics
To track the health and efficiency of a vector database, you should monitor certain performance indicators:
Query Latency: Measures the time taken to retrieve results. Increasing latency could indicate resource saturation or inefficient indexing.
Resource Utilization (CPU, Memory, I/O): High CPU or memory usage may suggest an undersized deployment, while low utilization could indicate over-provisioning.
Storage Performance: Tracks read/write speeds and available capacity to prevent performance degradation from slow disks or insufficient storage.
Pod and Node Health: Ensures that database pods are running as expected and that there are no frequent restarts or failures.
Tracking these metrics provides insights into potential performance bottlenecks and helps ensure the database remains responsive under varying workloads. However, monitoring alone is not enough, logs provide deeper context for diagnosing issues and understanding database behavior over time.
Implementing Logging and Monitoring Tools
Several Kubernetes-native tools provide visibility into database performance. Prometheus is commonly used to collect performance metrics from database pods, while Grafana enables real-time visualization through dashboards. For logging, solutions like Fluentd, Fluent Bit, or Loki aggregate logs from multiple pods, making it easier to diagnose issues. Additionally, examining Kubernetes events and logs helps troubleshoot crashes, failed queries, or unexpected scaling behavior. Together, these tools create a comprehensive monitoring system that aids in performance optimization and incident resolution.
With proper monitoring in place, database operations become more predictable, but securing the database environment is just as important. Let’s look at the best practices for ensuring security in a Kubernetes deployment.
6. Implement Security Best Practices
Securing a vector database within a Kubernetes environment is crucial to protecting sensitive data and maintaining system integrity. A strong security strategy involves multiple layers, addressing access control, network policies, and secret management. Properly implementing these measures reduces the risk of unauthorized access, data breaches, and operational disruptions.
Access Control
Role-Based Access Control (RBAC) is essential for restricting system access based on user roles. By assigning only the necessary permissions to users and services, RBAC follows the principle of least privilege, reducing the risk of accidental or malicious actions. In multi-tenant environments, additional isolation mechanisms should be implemented to prevent unauthorized access between different user groups.
Network Policies
Controlling network traffic between pods and services is critical for limiting exposure to potential threats. Kubernetes Network Policies allow administrators to define rules that permit or deny traffic between components. For example, restricting access so that only specific application pods can communicate with the database ensures that unauthorized services or external threats cannot connect. Additionally, implementing encryption protocols such as Transport Layer Security (TLS) helps protect data in transit from interception or tampering.
Secret Management
Managing sensitive information such as passwords, API keys, and certificates securely is crucial. Kubernetes Secrets provide a way to store and manage this data without exposing it in configuration files. Secrets should be encrypted, regularly rotated, and tightly controlled to minimize the risk of leaks. Auditing access to secrets helps track unauthorized attempts and ensures compliance with security policies.
By integrating these security best practices, a vector database can remain protected against unauthorized access and vulnerabilities. Security is not a one-time setup but an ongoing process that requires continuous monitoring and improvements.
7. Assigning Pods to Nodes for Optimal Performance
Efficient pod placement in Kubernetes can significantly impact the performance and stability of a vector database. Since vector databases rely on fast disk access, memory-intensive computations, and low-latency network communication, proper scheduling ensures that database instances run on nodes best suited for their workload. Kubernetes provides several mechanisms to control where and how database pods are scheduled within a cluster.
Controlling Pod Placement
Kubernetes allows administrators to influence pod scheduling using node selectors, affinity/anti-affinity rules, and taints/tolerations:
Node Selectors: Assigns pods to specific nodes based on labels. For example, a vector database can be scheduled on nodes with high-performance SSD storage by adding a label like
disktype=ssd.Node Affinity: Offers more flexible constraints than selectors, allowing pods to prefer or require certain node attributes. For instance, a database pod can be scheduled on GPU nodes if vector search acceleration is needed.
Pod Anti-Affinity: Ensures that replicas of a database are spread across different nodes, improving availability and fault tolerance.
Taints and Tolerations: Prevents pods from running on specific nodes unless they have the appropriate toleration, ensuring dedicated resources for performance-critical workloads.
Using these scheduling strategies helps balance performance, availability, and resource efficiency, ensuring that vector database pods are deployed in an optimal environment. However, choosing the right placement strategy also depends on workload requirements and infrastructure constraints.
Key Considerations for Pod Scheduling
When defining pod placement strategies, several factors should be taken into account to ensure the database runs efficiently and remains resilient:
Storage Performance: Assign pods to nodes with local SSDs when possible to reduce query latency and improve indexing speed.
Workload Isolation: Prevent database pods from running on nodes with resource-intensive applications that could lead to contention.
High Availability: Distribute database replicas across multiple nodes to minimize the impact of node failures.
Properly assigning pods to nodes ensures that the vector database has the resources it needs to perform efficiently. While scheduling optimizes resource utilization, securing the container environment further strengthens database reliability. Let’s see how to do this.
8. Secure Container Configuration
Ensuring that the containerized environment is properly secured is essential for protecting a vector database from vulnerabilities and unauthorized access. While Kubernetes provides security controls at the cluster level, the security of individual containers must also be addressed to minimize risks. Poor container security can expose the database to privilege escalation, data breaches, and container escape attacks.
Best Practices for Securing Database Containers
Container security involves restricting privileges, controlling filesystem access, and using secure images. The following measures help reduce the attack surface and improve overall security:
Run as a Non-Root User: By default, many containers run as root, which increases the risk of privilege escalation if the container is compromised. Setting the
runAsNonRootandrunAsUserparameters in the security context ensures that the database process runs with the least privileges necessary.Use Read-Only Filesystems: Enforcing a read-only root filesystem prevents unauthorized modifications to system files and helps contain potential threats.
Drop Unnecessary Linux Capabilities: Kubernetes provides a way to remove unused capabilities from a container’s process, reducing the risk of exploitation. Using
capabilities.drop: ["ALL"]and enabling only required privileges enhances security.Regularly Scan and Update Container Images: Keeping the database container image up to date with the latest security patches prevents known vulnerabilities from being exploited. Additionally, using minimal base images reduces the number of potential attack vectors.
Key Considerations for Container Security
Applying security best practices helps protect the vector database while maintaining performance and stability. However, security settings should be tailored based on workload requirements and compliance needs:
Ensure Compatibility: Some databases require specific system capabilities, so security restrictions should not interfere with essential operations.
Monitor for Security Events: Implement runtime security tools like Falco to detect and respond to suspicious activity within database containers.
Restrict Network Access: Use Kubernetes Network Policies alongside container security settings to further limit exposure to external threats.
By securing container configurations, vector databases remain resilient against potential attacks while operating within a controlled environment. While container security helps reduce risk, having a strong backup and disaster recovery strategy is equally important.
9. Establish Backup and Disaster Recovery Plans
Vector databases store large volumes of valuable data, including indexed embeddings and metadata critical to AI and search applications. Without a robust backup and disaster recovery (DR) strategy, unexpected failures such as hardware crashes, accidental deletions, or misconfigurations can lead to data loss or extended downtime. A well-planned backup and recovery approach ensures data durability and system resilience.
Key Components of a Backup Strategy
A reliable backup plan should include regular snapshots, offsite storage, and automated recovery procedures. The following components help ensure that backups remain effective and accessible:
Automated Snapshots: Use Kubernetes-native backup solutions or database-specific snapshot tools to take periodic backups of persistent volumes. Cloud providers often support VolumeSnapshots, which allow quick restoration of storage.
Offsite and Object Storage Backups: Storing backups in a remote location, such as an object storage service (e.g., MinIO, S3), provides additional protection against local hardware failures or cluster-wide issues.
Point-in-Time Recovery: Some vector databases support Write-Ahead Logging (WAL) or incremental backups, enabling recovery to a specific timestamp. This minimizes data loss in case of corruption or accidental deletions.
Disaster Recovery Considerations
Beyond backups, a disaster recovery plan ensures that the database can be restored efficiently with minimal downtime. The following best practices improve resilience:
Regularly Test Recovery Procedures: A backup is only useful if it can be restored successfully. Periodically testing restore processes helps verify that the system can recover as expected.
Deploy in Multi-Zone or Multi-Region Clusters: Running database replicas across availability zones or regions improves fault tolerance in case of regional outages.
Automate Failover Mechanisms: Configuring automatic failover for database replicas ensures that if a primary node fails, another takes over seamlessly.
A strong backup and disaster recovery strategy ensures that data remains protected and recoverable in various failure scenarios. While data protection is essential, optimizing database configurations further enhances performance and efficiency.
10. Fine-Tune Database Parameters for Optimal Performance
Configuring a vector database correctly ensures that it runs efficiently, especially when handling large-scale queries and indexing operations. While Kubernetes provides flexibility in managing resources, database-specific tuning is necessary to optimize query speed, memory usage, and indexing efficiency. Adjusting parameters based on workload patterns can significantly improve overall performance.
Key Areas to Optimize
Tuning a vector database involves configuring indexing strategies, cache settings, and query performance parameters. The following optimizations help ensure smooth operations:
Indexing Strategy: Choosing the right index type, such as IVF, HNSW, DISKANN or PQ-based methods, affects search accuracy and speed. For example, hierarchical indexes like HNSW provide faster nearest neighbor search but require more memory.
Cache and Memory Management: Increasing the cache size helps keep frequently accessed vectors in memory, reducing disk reads. Databases often provide parameters to fine-tune cache allocation for balancing memory usage and query latency.
Query Parallelism: Many vector databases support parallel query execution to leverage multiple CPU cores. Adjusting thread allocation settings ensures optimal utilization of compute resources.
Batch Processing for Index Building: Index construction can be resource-intensive. Running index creation in batches or during off-peak hours prevents excessive resource consumption while maintaining cluster stability.
Considerations for Performance Tuning
Optimizing database parameters requires continuous monitoring and adjustments based on real-world workloads. The following factors should be considered:
Monitor Query Latency: Track response times to identify slow queries and adjust indexing or caching settings accordingly.
Balance Accuracy and Speed: Higher recall often requires more compute power; adjusting index parameters helps find the right trade-off for the workload.
Adjust Based on Data Growth: As datasets grow, periodic tuning ensures that performance remains consistent over time.
Fine-tuning database settings allows vector databases to handle high-dimensional data search at scale. By combining optimized database configurations with best practices for Kubernetes deployments, organizations can ensure reliable and high-performance vector search applications.
Conclusion
Running a vector database on Kubernetes requires thoughtful configuration to maximize performance, scalability, and security. Ensuring stable deployments with StatefulSets, configuring persistent storage for performance, and managing resource allocation effectively helps maintain efficiency. Autoscaling, monitoring, and security measures ensure the system's reliability, while backups and disaster recovery plans safeguard against data loss.
Since workloads evolve over time, continuous monitoring and adjustments are essential. By applying these best practices, you can maintain a high-performance, scalable vector database that remains cost-efficient and secure in a Kubernetes environment.
Further Resources
Keep Reading

Migrating from S3 Vectors to Zilliz Cloud: Unlocking the Power of Tiered Storage
Learn how Zilliz Cloud bridges cost and performance with tiered storage and enterprise-grade features, and how to migrate data from AWS S3 Vectors to Zilliz Cloud.

Announcing the General Availability of Single Sign-On (SSO) on Zilliz Cloud
SSO is GA on Zilliz Cloud, delivering the enterprise-grade identity management capabilities your teams need to deploy vectorDB with confidence.

8 Latest RAG Advancements Every Developer Should Know
Explore eight advanced RAG variants that can solve real problems you might be facing: slow retrieval, poor context understanding, multimodal data handling, and resource optimization.
The Definitive Guide to Choosing a Vector Database
Overwhelmed by all the options? Learn key features to look for & how to evaluate with your own data. Choose with confidence.