




Условные вариационные автоэнкодеры (CVAEs): генеративные модели с условными входными данными

Условные вариационные автоэнкодеры (CVAEs): генеративные модели с условными входными данными
Вы когда-нибудь задумывались, как ИИ может генерировать конкретные, реалистичные изображения или данные на основе условия, например создавать изображение кошки в определенном стиле?
Вариационные автоэнкодеры (VAEs) — это мощные генеративные модели, но им не хватает контроля над атрибутами данных. Условные вариационные автоэнкодеры (CVAEs) преодолевают это ограничение, включая условия, такие как метки или атрибуты, как в энкодер, так и в декодер. Это позволяет CVAEs генерировать данные, адаптированные к конкретным требованиям, что делает их идеальными для таких задач, как целевое создание изображений или генерация персонализированного контента, расширяя их потенциал в различных областях.
Давайте рассмотрим, как работают условные вариационные автоэнкодеры (CVAEs), их преимущества и как они меняют способы генерации данных в различных доменах.
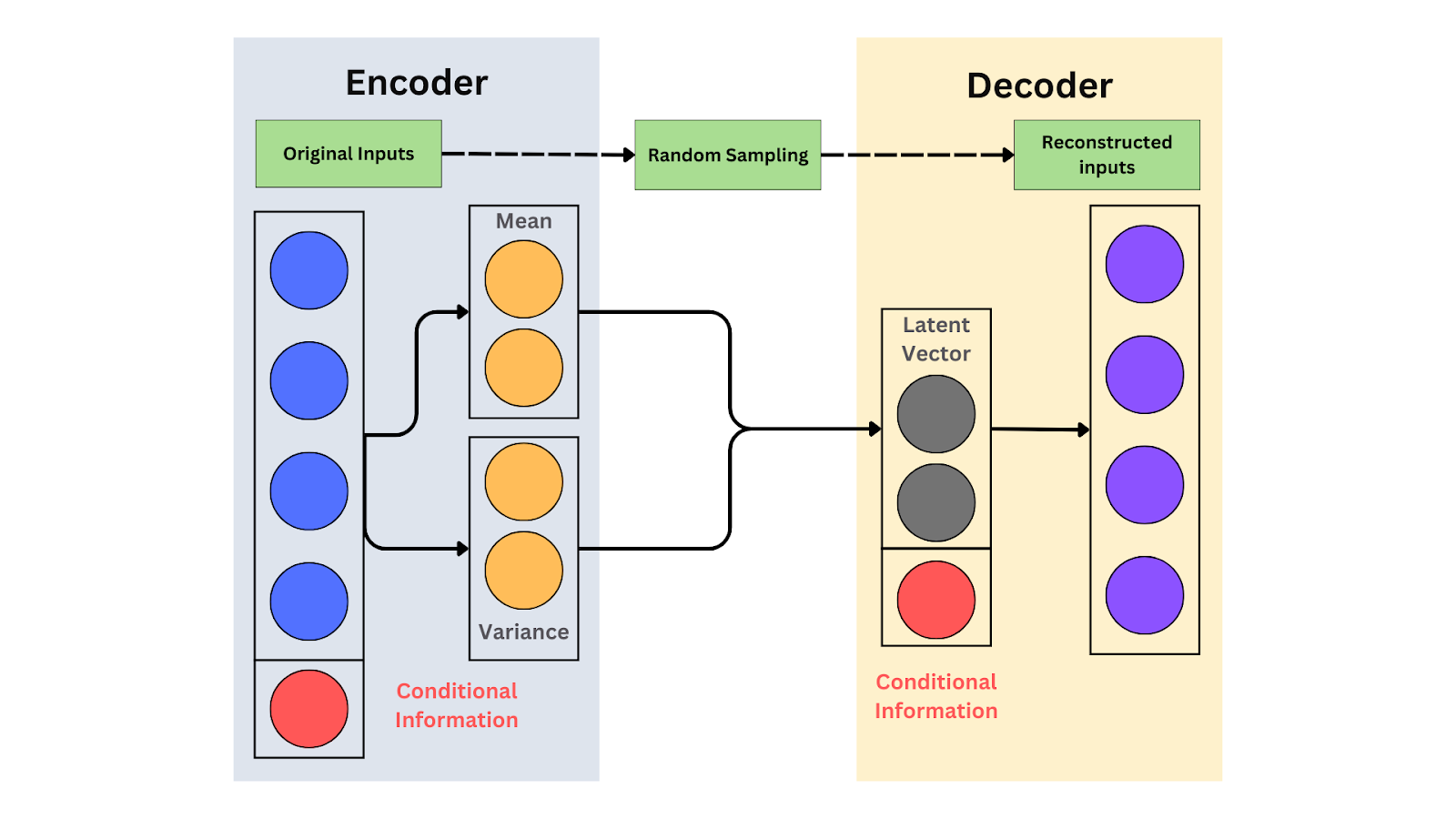 Схема CVAE.png
Схема CVAE.png
Схема CVAE
Что такое условные вариационные автоэнкодеры (CVAE) ?
Условный вариационный автоэнкодер (CVAE) — это расширение вариационного автоэнкодера (VAE), которое включает условные входные данные, такие как метки или атрибуты, для управления процессом генерации данных. Сгенерированные данные соответствуют конкретным требованиям за счет обусловливания модели. Например, если вы хотите создавать изображения кошек или собак, вы можете предоставить метку "cat" или "dog", чтобы направить генерацию. Это позволяет модели создавать желаемый результат на основе условия.
CVAEs важны, потому что они обеспечивают контроль над генерацией данных. Условные входные данные гарантируют, что выходные данные соответствуют заранее определенным признакам. Это делает их полезными для таких задач, как генерация изображений для модного дизайна, где модели могут создавать предметы одежды разных цветов или стилей, а также в целевых симуляциях, где необходимо генерировать конкретные сценарии на основе определенных условий.
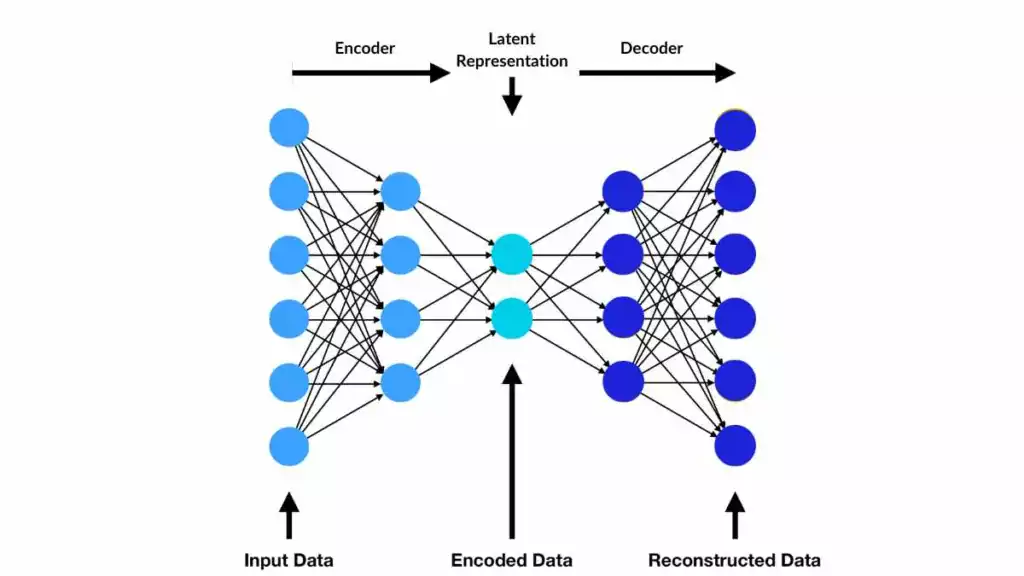 Структура автоэнкодера лежит в основе VAEs и CVAEs.png
Структура автоэнкодера лежит в основе VAEs и CVAEs.png
Структура автоэнкодера лежит в основе VAEs и CVAEs | Источник
Понимание вариационных автоэнкодеров (VAEs)
Прежде чем мы подробно рассмотрим CVAEs, давайте обсудим концепцию вариационных автоэнкодеров (VAEs). VAEs — это генеративные модели, которые учатся представлять сложные распределения данных в непрерывном латентном пространстве для генерации новых образцов данных.
VAEs содержат два основных компонента: энкодер и декодер. Энкодер сжимает входные данные в латентное пространство, фиксируя их ключевые признаки. Декодер реконструирует входные данные или генерирует новые образцы из этого латентного представления. Функция потерь играет ключевую роль в обучении, балансируя точность реконструкции и регулярность латентного пространства. Регуляризация обеспечивает гладкость и структурированность латентного пространства, позволяя генерировать согласованные данные.
Функция потерь
Функция потерь в вариационных автоэнкодерах (VAEs) состоит из двух основных компонентов: потерь реконструкции и KL-дивергенции.
- Потери реконструкции измеряют, насколько хорошо модель воспроизводит входные данные. Обычно они рассчитываются с использованием среднеквадратичной ошибки (MSE) или бинарной кросс-энтропии. Уравнение для потерь реконструкции:
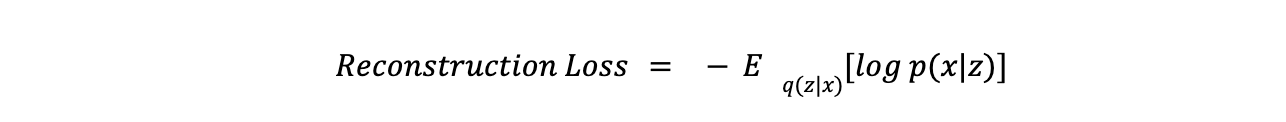
- KL-дивергенция, сокращение от дивергенции Кульбака-Лейблера, — это статистическая мера того, насколько различаются два вероятностных распределения. В контексте VAEs она гарантирует, что латентное распределение 𝒒(𝔃∣𝔁) (изученное энкодером) остается близким к априорному 𝒑(𝔃), которое обычно является стандартным гауссовым распределением. Уравнение для KL-дивергенции:
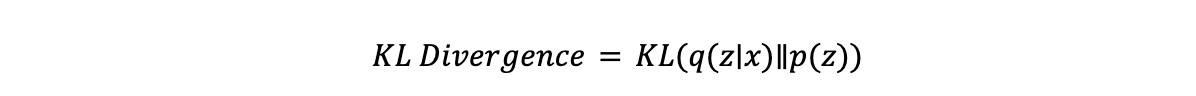
Общая функция потерь представляет собой взвешенную сумму этих двух членов:
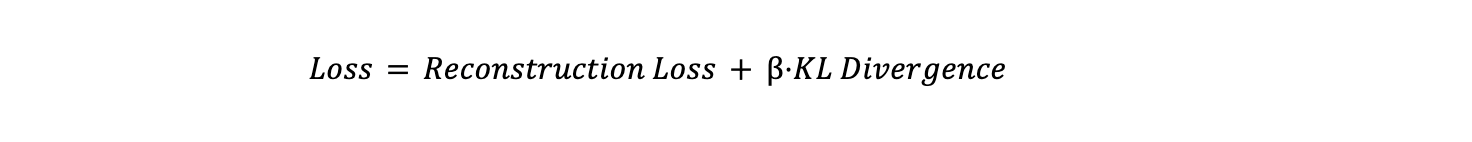
Где β — это гиперпараметр, который управляет компромиссом между потерей реконструкции и KL-дивергенцией. Более высокое значение β придает большее значение регуляризации латентного пространства, тогда как более низкое значение позволяет модели больше сосредоточиться на точной реконструкции. Этот баланс крайне важен для того, чтобы модель одновременно генерировала точные данные и обучалась осмысленному, хорошо организованному латентному пространству.
Регуляризация
Регуляризация использует дивергенцию Кульбака — Лейблера, чтобы согласовать латентное пространство с априорным распределением, гарантируя, что латентные переменные следуют гауссовскому распределению. Это сглаживает латентное пространство, обеспечивая интерполяцию и осмысленную выборку. Точки, расположенные близко друг к другу в латентном пространстве, генерируют похожие выходные данные. Регуляризация также улучшает обобщающую способность, предотвращая переобучение модели на обучающих данных. Например, в дизайне одежды регуляризация обеспечивает генерацию разнообразных моделей одежды при сохранении реалистичных узоров и стилей. Она помогает создавать вариации типов одежды, цветов и текстур, не производя нереалистичных результатов. Поддерживая структурированность латентного пространства, она генерирует дизайны, которые соответствуют текущим трендам, но при этом отличаются по-своему.
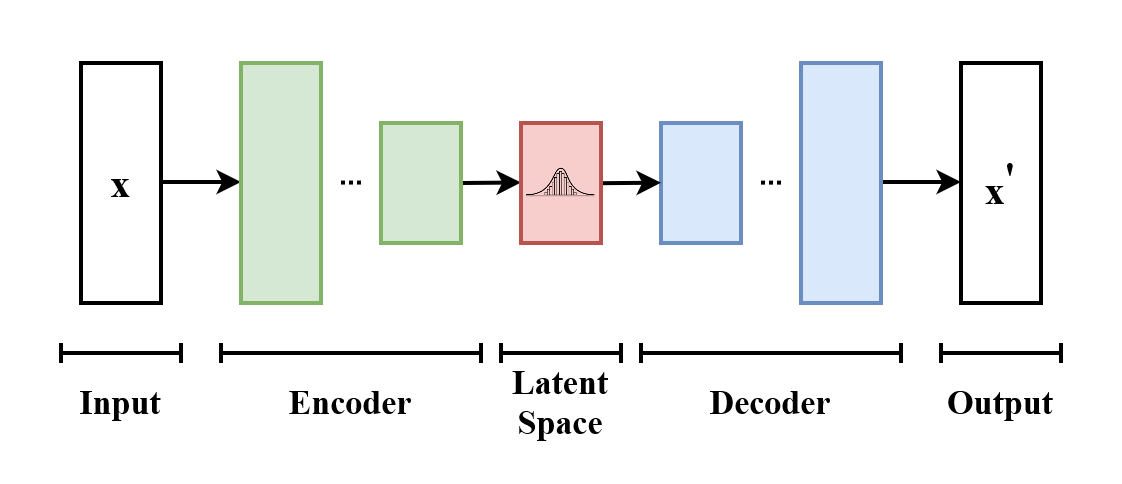 Структура вариационного автоэнкодера (VAE) |.png
Структура вариационного автоэнкодера (VAE) |.png
Структура вариационного автоэнкодера (VAE) | Источник
{kind=link}
Как CVAE улучшает VAE с помощью условных входных данных?
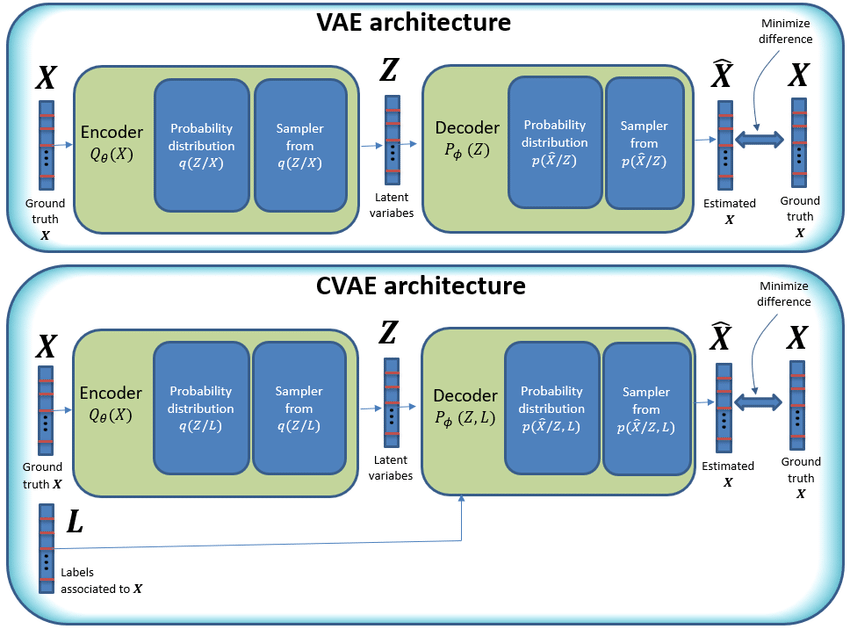
CVAEs расширяют VAEs, добавляя условные входные данные, такие как метки классов, для управления генерацией данных. Энкодер обрабатывает как входные данные, так и условие. Он отображает их в совместное латентное пространство, захватывая данные и условие в объединенном виде. Затем декодер использует это латентное представление, сжатую версию данных, вместе с условием для генерации новых образцов.
Например, если условие — "красные кроссовки," декодер генерирует изображение красных кроссовок. Условие гарантирует, что выходной результат соответствует конкретным требованиям. Как и VAEs, CVAEs используют KL-дивергенцию для регуляризации латентного пространства и создания гладкого распределения.
VAEs полагаются только на вариации входных данных, что ограничивает контроль над выходным результатом. CVAEs используют метки или атрибуты для управления процессом генерации. Это позволяет получать целевые и конкретные выходные данные. Например, в CVAE, обученном на MNIST, условием может быть метка цифры, такая как "5." Получив метку и входные данные, модель генерирует конкретную "5." VAE, напротив, может сгенерировать любую случайную цифру в зависимости от латентного пространства.
CVAEs идеально подходят для задач вроде генерации изображений с определенными признаками или персонализации контента. Например, CVAE может сгенерировать дизайн кроссовок на основе предпочтений пользователя по цвету, размеру и стилю, улучшая кастомизацию и пользовательский опыт.
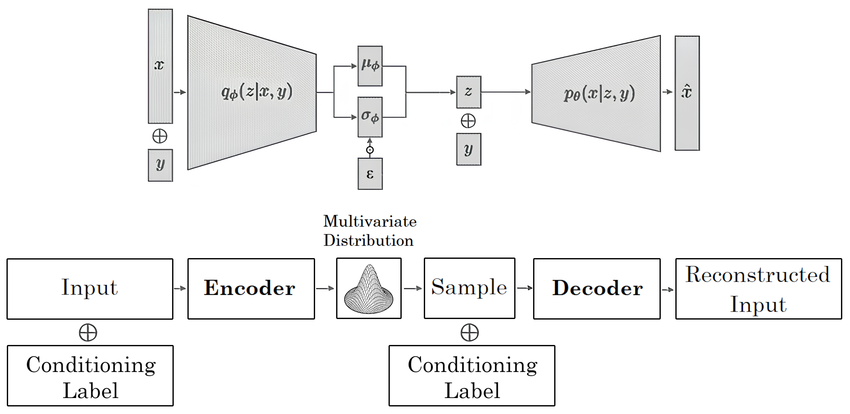 Архитектура условного вариационного автоэнкодера (CVAE).png
Архитектура условного вариационного автоэнкодера (CVAE).png
Архитектура условного вариационного автоэнкодера (CVAE) | Источник
Ключевые термины:
Латентное пространство: латентное пространство — это высокоразмерное сжатое представление данных. Оно фиксирует ключевые признаки входных данных, такие как поза или цвет, в компактной форме. Например, изображение лица может быть сжато в вектор, представляющий возраст или выражение лица. Пространство обычно следует известному распределению (например, гауссовскому), что позволяет генерировать новые, похожие точки данных путем выборки из этого распределения. Это представление позволяет модели эффективно манипулировать точками данных или интерполировать между ними.
Кодировщик: кодировщик преобразует входные данные в вероятностное латентное представление. Он отображает вход 𝔁 (например, изображение) в распределение (среднее 𝜇, дисперсия 𝝈2) в латентном пространстве. Например, для изображения кошки кодировщик выдает распределение признаков, таких как цвет и порода. Из этого распределения выбирается латентный вектор. Кодировщик обучается эффективно сжимать данные, сохраняя при этом существенные признаки.
Декодировщик: декодировщик принимает латентную переменную 𝔃 и реконструирует или генерирует данные. Он отображает латентный вектор, сжатую версию данных, обратно в исходное пространство данных. Например, декодировщик генерирует изображение кошки из латентного вектора, представляющего признаки кошки. Функция обозначается как 𝒑(𝔁∣𝔃), где 𝔁 — сгенерированные данные. Декодировщик может создавать разнообразные выходные данные, обучаясь на латентных переменных, даже для ранее не встречавшихся данных.
Условные входные данные: условные входные данные предоставляют дополнительную информацию (например, метки), которая направляет генерацию данных. В CVAE метки вроде "cat" помогают генерировать конкретные выходные данные, например изображения кошек. Кодировщик и декодировщик используют эти входные данные для создания контролируемых выходных данных. Например, кодировщик становится 𝒒(𝔃∣𝔁,𝔂), а декодировщик — 𝒑(𝔁∣𝔃,𝔂). Эти входные данные обеспечивают генерацию моделью данных, адаптированных к заданным условиям, повышая гибкость.
- KL-дивергенция: KL-дивергенция измеряет, насколько изученное кодировщиком распределение отличается от априорного распределения (обычно гауссова). Она побуждает кодировщик генерировать латентные переменные, близкие к априорному распределению, обеспечивая структурированное латентное пространство. Формула:
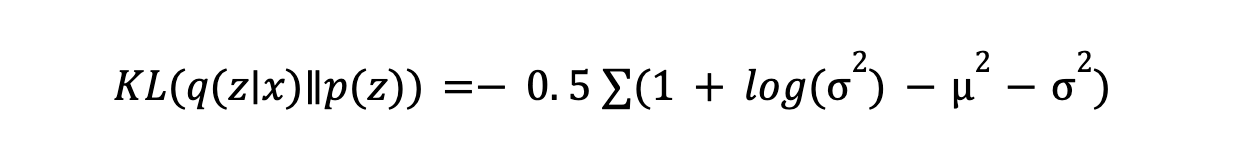
Минимизация KL-дивергенции помогает поддерживать хорошо организованное латентное пространство для генерации данных. Этот метод регуляризации обеспечивает распределение латентных переменных таким образом, чтобы выборка и генерация новых точек данных были надежными.
CVAE vs. VAE vs. GAN
В этом разделе сравниваются вариационные автоэнкодеры (VAEs) с условными вариационными автоэнкодерами (CVAEs) и генеративно-состязательными сетями (GANs). Все они являются генеративными моделями, но имеют несколько ключевых различий.
Следующая таблица показывает различия в их механизмах, гибкости и вариантах использования.
| Аспект | VAE (вариационный автоэнкодер) | CVAE (условный вариационный автоэнкодер) | GANs (генеративно-состязательные сети) |
| Основной механизм | Кодирует входные данные в сжатое латентное пространство и генерирует новые данные. | Подобно VAE, включает условные входные данные (например, метки) для управления генерацией. | Состоит из двух сетей: генератор создает данные, а дискриминатор оценивает их. |
| Входные данные | В энкодер подаются только сами данные. | Условные данные (например, метки классов и атрибуты) также используются в энкодере. | Использует случайный шум в качестве входа для генератора, тогда как дискриминатор оценивает сгенерированные данные. |
| Латентное представление | Представляет все распределение данных, обеспечивая гладкое, непрерывное латентное пространство. | Латентное пространство обусловлено входными данными, что обеспечивает больший контроль над сгенерированным выходом. | Латентное пространство изучается в процессе обучения, без явного контроля над конкретными признаками. |
| Управление генерацией | Генерация основана исключительно на латентном пространстве, без внешних средств управления. | Условные данные позволяют генерировать данные на основе конкретных атрибутов (например, генерировать изображения определенных категорий, таких как «кошка» или «собака»). | Генератор «соревнуется» с дискриминатором, улучшая сгенерированные данные, «обманывая» дискриминатор. |
| Гибкость | Подходит для генерации данных общего назначения и обнаружения аномалий. | Идеален для сценариев, где требуется управляемая генерация на основе конкретных атрибутов. | Очень гибок в генерации реалистичных образцов, но обеспечивает меньший контроль над конкретными выходными данными. |
| Обучающие данные | Может обучаться на широком наборе данных без явных условий. | Требуются дополнительные размеченные или условные данные для управления процессом генерации. | Требует состязательного обучения, в котором генератор и дискриминатор конкурируют друг с другом. |
| Сценарии использования | Генерация данных (например, генерация лиц), обнаружение аномалий и интерполяция точек данных. | Управляемая генерация изображений (например, генерация конкретных объектов или условий, таких как цвет или стиль), полуобучение. | Генерация высококачественных изображений, преобразование изображений, перенос стиля и аугментация данных. |
| Ключевые преимущества | Проще обучать, без необходимости во внешних условиях. | Позволяет генерировать весьма специфичные выходные данные, обеспечивая лучший контроль над сгенерированными данными. | Генерирует высокореалистичные изображения и разнообразные данные без необходимости в явных метках. |
| Пример применения | Генерация случайных изображений лиц. | Генерация изображений лиц с конкретными атрибутами, такими как возраст, пол или выражение лица. | Генерация реалистичных изображений человеческих лиц, создание искусства или преобразование изображений из одного стиля в другой. |
 Сравнение CVAE с типичной архитектурой VAE.png
Сравнение CVAE с типичной архитектурой VAE.png
Сравнение CVAE с типичной архитектурой VAE | Источник
 Сравнение архитектур (A) VAE и (B) GAN.png
Сравнение архитектур (A) VAE и (B) GAN.png
Сравнение архитектур (A) VAE и (B) GAN | Источник
Преимущества и проблемы вариационных автоэнкодеров (VAE)
Вариационные автоэнкодеры (VAE) предлагают значительные преимущества в генеративном моделировании, но также создают проблемы, которые необходимо решать. Сначала обсудим преимущества использования VAE.
Условная генерация: CVAE могут генерировать новые образцы на основе заданных условий, что делает их полезными для таких задач, как генерация изображений с определенными признаками или создание персонализированного контента. Это добавляет гибкость и универсальность различным приложениям.
Осмысленные представления: Условные VAE (CVAE) обучаются осмысленным латентным представлениям из входных данных, обеспечивая лучшее понимание и управление структурами данных. Это особенно полезно для таких задач, как извлечение и анализ признаков.
Кастомизация: CVAE могут создавать данные, адаптированные под конкретные потребности, обеспечивая индивидуальные рекомендации и таргетированный контент. Это делает их чрезвычайно ценными в таких областях, как реклама и персонализированные пользовательские приложения.
Аугментация данных: CVAE можно использовать для расширения наборов данных путем генерации разнообразных и реалистичных синтетических данных. Эта возможность помогает улучшить производительность моделей машинного обучения, особенно в сценариях с ограниченными или несбалансированными наборами данных.
Теперь обсудим проблемы, возникающие при использовании VAE.
Коллапс мод: Он возникает, когда модель генерирует только несколько типов образцов, что приводит к повторяющимся результатам вместо разнообразных. Переобучение может усугубить эту проблему, заставляя модель запоминать конкретные шаблоны, а не обучаться осмысленным латентным представлениям. Это часто происходит из-за плохого исследования латентного пространства или недостаточных и нерепрезентативных обучающих данных. Для решения этой проблемы можно использовать методы регуляризации, такие как dropout и batch normalization, а также продвинутые алгоритмы обучения, например Importance-Weighted Autoencoders (IWAE).
Генерация изображений высокого разрешения: CVAE испытывают трудности с эффективной генерацией изображений высокого разрешения. Латентное пространство модели может не захватывать достаточное количество мелких деталей, что приводит к размытым или искаженным результатам. Это ограничение возникает из-за ограниченной емкости латентного пространства и потери качества в результатах высокого разрешения. Смягчение этой проблемы включает использование более сложных латентных пространств или иерархических VAE, объединение CVAE с такими моделями, как GAN, или применение техник прогрессивного обучения, которые постепенно увеличивают разрешение во время обучения.
Сценарии использования условных вариационных автоэнкодеров (CVAE)
Условные вариационные автоэнкодеры (CVAE) являются универсальными инструментами в глубоком обучении и применяются в различных областях. Вот несколько ключевых сценариев использования:
Генерация изображений: CVAE генерируют изображения, обусловленные такими атрибутами, как стиль, поза или освещение. В дизайне и моде они используются для визуализации одежды в разных стилях или цветах. Разработчики игр используют их для создания разнообразных внешностей персонажей, а производители автомобилей применяют их для визуализации транспортных средств с различными настройками для клиентов.
Системы рекомендаций контента: CVAE улучшают персонализацию, обучаясь предпочтениям пользователей, чтобы предлагать релевантные рекомендации. Они также динамически адаптируются к взаимодействиям пользователей, со временем повышая вовлеченность.
Разработка лекарств: CVAE ускоряют медицинские инновации, генерируя новые молекулярные структуры на основе желаемых свойств. Они также оптимизируют существующие соединения для улучшения терапевтических результатов.
Обнаружение аномалий: CVAE выявляют необычные закономерности в критически важных системах. Они помечают отклонения от нормальных рабочих параметров и повышают кибербезопасность, обнаруживая необычную сетевую активность.
Обработка естественного языка (NLP): CVAE способствуют выполнению таких задач, как генерация связного текста, обусловленного контекстом, стилем или тоном. Они также облегчают тонкие языковые переводы, адаптированные к стилистическим требованиям.
Искусство и творчество: CVAE помогают художникам и создателям, обеспечивая перенос стиля для переосмысления произведений искусства в разных эстетиках. Они также помогают генерировать новые художественные произведения на основе конкретных тем или мотивов.
Этика и подотчетность ИИ: CVAE поддерживают ответственную разработку ИИ, улучшая интерпретируемость моделей за счет контролируемой генерации данных. Они обеспечивают соответствие ИИ-систем этическим стандартам, позволяя получать контролируемые результаты.
Инструменты
Теперь мы рассмотрим некоторые популярные инструменты и фреймворки, которые облегчают реализацию и обучение условных вариационных автоэнкодеров (CVAEs).
TensorFlow: Это мощный фреймворк для проектирования CVAE. Он упрощает реализацию архитектур энкодер-декодер и поддерживает вычисление члена KL-дивергенции через TensorFlow Probability. Его поддержка GPU/TPU обеспечивает эффективное обучение на больших наборах данных.
PyTorch: Он широко используется благодаря своей гибкости и динамическому графу вычислений, что делает его идеальным для пользовательских реализаций CVAE. Он позволяет точно контролировать компоненты модели, а библиотеки, такие как Pyro, добавляют расширенные возможности вероятностного моделирования для функций потерь CVAE.
JAX и Flax: JAX в сочетании со своей библиотекой нейронных сетей Flax предлагает эффективные вычисления для CVAE. Он обеспечивает гибкость для настройки вычислений градиентов и поддерживает масштабируемые архитектуры для сложных задач CVAE.
FAQS
Что отличает CVAE от стандартных VAE? CVAE используют условные входные данные для управления характеристиками выходных данных. Стандартные VAE генерируют данные только на основе входного распределения.
Как обусловливание влияет на генеративный процесс в CVAE? Обусловливание направляет модель при генерации данных, соответствующих конкретным атрибутам. Оно добавляет контроль и точность выходным данным.
Каковы распространенные применения CVAE? CVAE создают настраиваемые изображения, персонализированный текст и расширенные наборы данных. Они хорошо подходят для задач, требующих генерации конкретных характеристик.
С какими проблемами можно столкнуться при обучении CVAE? Для обучения требуются размеченные данные и тщательная настройка. Также могут возникать проблемы со стабильностью и сложностью.
Каковы ограничения CVAE по сравнению с GAN? CVAE могут создавать менее реалистичные результаты. GAN часто достигают более четких и детализированных результатов, но не обладают таким же уровнем контроля.
- Что такое условные вариационные автоэнкодеры (CVAE) ?
- Понимание вариационных автоэнкодеров (VAEs)
- Как CVAE улучшает VAE с помощью условных входных данных?
- CVAE vs. VAE vs. GAN
- Преимущества и проблемы вариационных автоэнкодеров (VAE)
- Сценарии использования условных вариационных автоэнкодеров (CVAE)
- Инструменты
- FAQS
Контент
Начните бесплатно, масштабируйтесь легко
Попробуйте полностью управляемую векторную базу данных, созданную для ваших GenAI приложений.
Попробуйте Zilliz Cloud бесплатно