




Zilliz Cloud On-Demand Compute: платите только за то, что используете
В прошлом квартале мы разбирали кейс с оплатой у клиента из сферы автономного вождения. Их аналитической команде был нужен векторный поиск по коллекции на 1 млрд строк. Мы оценили это на Dedicated cluster: $7,000/месяц. Мы попробовали Serverless: $10,800. Фактическая аналитическая работа занимала несколько часов в месяц.
Оба счета были корректными. Оба продукта делали ровно то, для чего они предназначены. Проблема была в том, что рабочая нагрузка этого клиента — редкая аналитика, использующая один датасет совместно с двумя другими производственными нагрузками, — не соответствовала тому, для чего был разработан каждый из этих продуктов.
Именно для такого случая мы и создали Zilliz Cloud On-Demand Search — одну из новых возможностей, которые мы выпустили вместе с запуском Zilliz Vector Lakebase. Та же нагрузка — менее чем за $500/месяц. Ниже — что не подошло, что мы изменили, где On-Demand — неподходящий инструмент и как в конце всё это вписывается обратно в Vector Lakebase.
Кейс клиента
Коллекция — около 1 миллиарда записей — уже использовалась двумя производственными нагрузками:
- Сервисом онлайн-поиска, обслуживающим трафик в реальном времени.
- Пайплайном обучения моделей, который извлекает данные сценариев для регрессионных задач (им занимается отдельная команда).
Аналитика стала третьей нагрузкой, добавленной поверх тех же данных. Паттерн доступа: аналитики запускали поиски только тогда, когда у них был конкретный вопрос, короткими итеративными сериями, обусловленными текущим расследованием. В остальное время аналитические запросы в кластер не поступали.
Это довольно распространенный сценарий использования Zilliz при довольно типичном масштабе данных. Сложность была в том, что всем трем нагрузкам нужно было читать из одной и той же базовой коллекции, и у каждой был совершенно разный ритм.
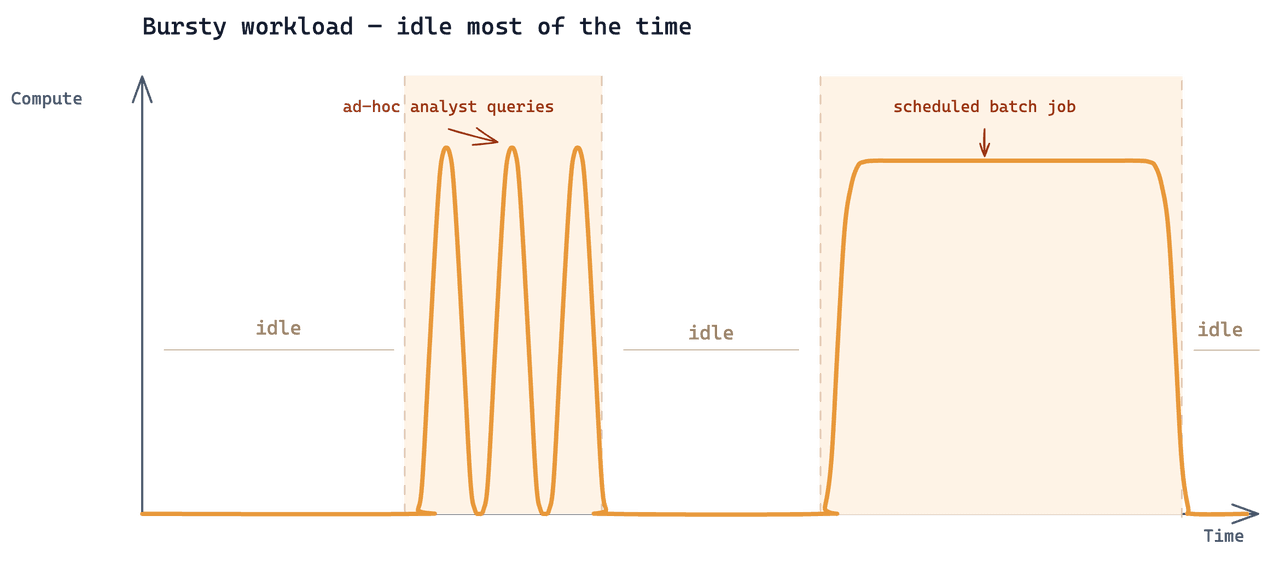
Почему Dedicated Cluster не подошел
Существующая конфигурация представляла собой Tiered-кластер Zilliz Cloud на 24 CU. Добавление аналитической нагрузки к нему оценивалось примерно в $7,000/месяц. Кластер выставляет счет за каждый час своего существования: 24 × 30 = 720 часов/месяц. Реальная аналитическая работа занимала 2–3 часа. Оставшиеся 717 часов оплачивались за простой — 99,6% общих расходов уходило на мощности, которыми никто не пользовался.
Можно останавливать Dedicated-кластер между сессиями, чтобы избежать оплаты часов простоя. Мы рассмотрели этот вариант. Он не работает по двум причинам.
Во-первых, холодный старт на Dedicated занимает 10+ минут для аналитических холодных запросов на датасете такого размера. Ментальная модель Dedicated заключается в том, что все необходимые данные должны находиться в локальной памяти до запуска запросов, поэтому он предварительно загружает весь рабочий набор — обычно в десятки или сотни раз больше данных, чем фактически затрагивает один холодный запрос. Та же загрузка также должна поднять состояние для неквери-работы, которую поддерживает кластер, например DDL и удалений. Эти накладные расходы существуют независимо от того, нужны они следующему запросу или нет.
Во-вторых, тарификация округляется до часа. Поэтому даже если аналитик готов ждать 10+ минут, пока кластер прогреется, счет за один запрос всё равно составит один час плюс загрузка. Когда аналитики работают короткими итеративными сериями, стоимость одного полезного запроса остается высокой, как бы дисциплинированно ни соблюдались запуск и остановка.
Почему Serverless Cluster не подошел
Serverless был следующим вариантом, который мы попробовали. На бумаге он идеально подходит для такого паттерна доступа: без состояния, оплата за запрос, без простаивающих вычислительных мощностей. Для одной только аналитической нагрузки он мог бы сработать.
Загвоздка в том, что Serverless на этом датасете не тарифицирует аналитическую нагрузку изолированно. Он тарифицирует всё, что обращается к коллекции. Как только мы включили существующие нагрузки, три статьи расходов сломали экономику:
- Запросы: ~$6,000/месяц. Большая часть — от двухнедельных регрессионных задач команды обучения моделей: 100 QPS в течение 3 часов каждые две недели. В цены Serverless за единицу включена надбавка за холодный запрос, которая оплачивается за каждый запрос, даже когда запрос горячий. Как только объем запросов перестает быть совсем низким, экономика перестает сходиться.
- Хранилище: $1,700/месяц. Тарифицируется отдельно, потому что в Serverless нет платы за compute-hour, в которую можно было бы включить хранилище.
- Записи: $3,000/месяц. Та же причина — нет compute-hour, в который можно было бы это включить.
Итого: $10,784/месяц, выше, чем у Dedicated-кластера, от которого мы пытались уйти.
У каждой из этих надбавок есть структурная причина.
Запросы несут надбавку за холодный запрос. Со стороны пользователя Serverless выглядит stateless. Со стороны платформы данные все равно должны быть загружены на конкретные машины для выполнения. Запросы делятся на горячие (данные уже на машине) и холодные (сначала загрузка из объектного хранилища). Горячие запросы дешевы; холодные запросы дороги. Платформа не может предсказать, какие запросы будут холодными для конкретного пользователя, поэтому распределяет стоимость холодных запросов по цене единицы каждого запроса. Нагрузки с преимущественно горячими запросами в итоге платят за чужие холодные.
Хранилище оценено выше предельной себестоимости. В Dedicated стоимость хранилища и записей незаметно включена в плату за compute-hour. В Serverless нет платы за compute-hour, за которой можно спрятать эти расходы, поэтому хранилище тарифицируется явно. Эта явная цена должна покрывать данные, которые хранятся, но никогда не запрашиваются, — платформа не может перенести их в глубоко холодное хранилище, потому что данные должны оставаться готовыми к запросу в любой момент. Поддержание такой готовности требует дополнительного состояния, и его стоимость в итоге амортизируется на объем хранилища, который на самом деле не соответствует реальному потреблению.
Записи также оценены выше предельной себестоимости. Записи тарифицируются отдельно, чтобы не позволять пользователям выполнять высокочастотные обновления, создающие большую стоимость записи без роста датасета (иначе платформа была бы вынуждена поглощать эти расходы). Та же динамика, что и у хранилища: стоимость состояния готовности закладывается в цену единицы записи.
Более глубокая проблема в том, что Serverless скрывает от пользователя абстракцию «вычислительного ресурса». Пользователь видит stateless-интерфейс; платформа все равно должна оплачивать непредсказуемые паттерны доступа за ним — горячие/холодные данные, всплески трафика, простаивающее хранилище, которое должно оставаться готовым к запросам. Эти затраты нельзя точно отнести к конкретным пользователям, поэтому они амортизируются в ценах единиц запросов, хранилища и записей. Каждое тарифицируемое действие в итоге оказывается немного выше своей реальной предельной себестоимости.
Это модель «разделенного риска»: каждая строка счета несет надбавку, чтобы покрыть чьи-то холодные запросы, всплески или простаивающее хранилище. Нагрузки, которые в наименьшей степени создают эту вариативность, — стабильные, высокочастотные, предсказуемые горячие запросы — платят наибольшую долю премии. Чем стабильнее ваша нагрузка, тем больше вы в итоге субсидируете.
Что на самом деле было нужно клиенту
Если посмотреть шире, запрос клиента не был чем-то экзотическим. Один датасет, несколько ритмов доступа, при этом счет должен следовать только за тем compute, который каждый ритм фактически использовал.
- Онлайн-поиск: непрерывный, низколатентный, предсказуемый. Dedicated подходит для этого.
- Обучение моделей: всплескообразное, но предсказуемое — 3 часа каждые две недели.
- Аналитика: редкая и непредсказуемая — по несколько минут за раз, с длинными паузами.
Dedicated не мог этого обеспечить. Он выставляет счет за выделенную емкость, а не за потребление. Serverless тоже не мог: его цена за единицу запроса должна субсидировать холодные запросы, простаивающее хранилище и запас под всплески по всем пользователям платформы, поэтому стабильные нагрузки в итоге платят за вариативность, которую сами не создают.
Нам нужна была третья модель вычислений — такая, которая могла бы подключаться к тем же данным, что и Dedicated, запускаться достаточно быстро, чтобы сделать тарификацию по запросам реалистичной, и выставлять счет только за время фактической работы.
Что мы изменили
On-Demand — это отдельная вычислительная модель в Zilliz Cloud, которая существует наряду с Dedicated и Serverless. По сравнению с ними она меняет три вещи:
- Холодный старт. Загружает только те фрагменты, к которым обращается текущий запрос, а не весь рабочий набор. Время сокращается с 10+ минут до секунд.
- Тарификация. Поминутная оплата фактического времени работы вычислений. Записи тоже учитываются. Без минимального часа, без надбавки за холодные/горячие запросы.
- Изоляция. Каждая рабочая нагрузка подключается к коллекции через собственную группу вычислительных ресурсов. Те же данные, без конкуренции.
Следующие три раздела подробно рассматривают каждый из этих пунктов.
Загрузка меньшего объема данных, быстрее
10-минутный холодный старт в Dedicated существует потому, что кластер должен загрузить весь рабочий набор в локальную память, прежде чем обслуживать запросы. Для коллекции на 1 млрд строк это в десятки и сотни раз больше данных, чем фактически нужно любому отдельному запросу. Сократить холодный старт до секунд означает отказаться от этого предположения: загружать только то, к чему обращается текущий запрос.
Звучит как одно предложение; на практике это потребовало переработки трех уровней — что читать, куда это помещать и как это поднимать.
Индексы, которые загружаются частично.
На стороне скалярных данных проталкивание предикатов — стандартная практика. Движок исключает блоки, которые не могут соответствовать предикату, и пропускает их получение. Мы используем это для инвертированных индексов: каждый список позиций загружается как блок, и у каждого списка есть статистика min/max, которую движок может проверить перед получением.
Более сложной задачей было дать векторной стороне сопоставимую возможность «читать подмножество». Графовые индексы — более производительный вариант для стабильного QPS — плохо деградируют при частичной загрузке: чтобы быть полезной, структура должна быть загружена полностью, поэтому стоимость холодной загрузки высока.
On-Demand вместо этого использует семейство IVF. IVF кластеризует векторы по корзинам во время индексации, а во время запроса извлекаются только ближайшие к запросу корзины. Это дает векторной стороне что-то близкое к семантике проталкивания предикатов: холодные запросы подтягивают небольшую часть индекса, а не весь индекс целиком.
Это осознанный компромисс. Мы теряем производительность графовых индексов в стабильном состоянии, и это главная причина, почему On-Demand не подходит для обслуживания с высоким QPS (подробнее об этом ниже). Для разреженных и пиковых рабочих нагрузок этот компромисс того стоит.
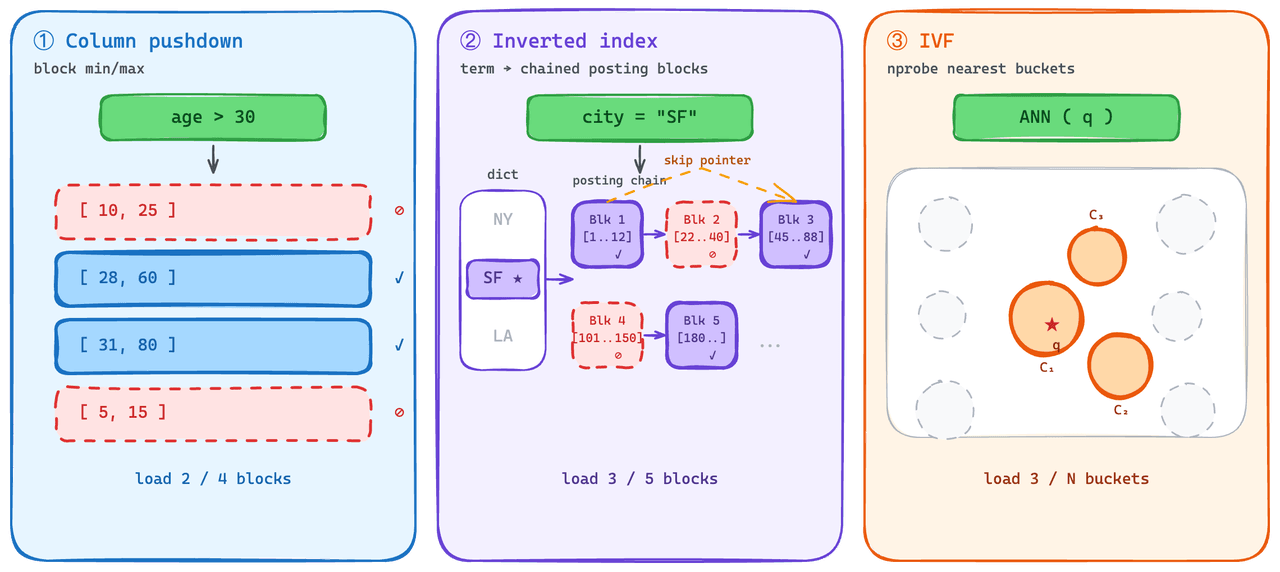
Трехуровневый путь данных.
Когда мы знаем, что читать, следующий вопрос — где это хранить. Фрагменты свободно перемещаются между S3, локальным диском и памятью, а жизненный цикл кэша управляется по фрагментам между запросами: фрагменты, нужные текущему запросу, поднимаются наверх; фрагменты, которые достаточно долго простаивают, вытесняются. Один и тот же набор данных может запрашиваться с очень разной частотой, и ни один из сценариев не платит за загрузку данных, к которым он не обращается.
У каждого уровня свой формат данных и гранулярность, адаптированные к характеристикам ввода-вывода носителя — выравнивание, которое подходит для объектного хранилища, не подходит для локального диска, и ни то ни другое не совпадает с тем, с чем движок работает в памяти.
Асинхронный ввод-вывод от начала до конца.
Цепочка ввода-вывода полностью асинхронна. Вычисления и ввод-вывод конвейеризованы на всем пути, поэтому CPU не простаивает в ожидании получения данных, а пропускная способность ввода-вывода не простаивает в ожидании вычислений.
В совокупности разбиение на фрагменты + уровни + асинхронность сокращают полезную нагрузку холодного запроса до менее 1–2% от полного набора данных и весь путь холодного запроса — до секунд.
Поминутная тарификация
Когда холодный старт занимает секунды, «запускать вычисления при поступлении запроса и освобождать их по завершении» работает как реальный продуктовый механизм — а не просто как проектное устремление. Основную работу выполняют две части плоскости управления.
Пул резервных узлов. Загрузка образов добавляет задержку при поднятии нового узла. Мы держим небольшой пул узлов с заранее загруженными образами наготове, поэтому запуск берет узел из пула, а не стартует с нуля.
Выпуск на основе TTL. У каждой сессии есть настраиваемый тайм-аут простоя. Вычислительные ресурсы освобождаются автоматически, когда срабатывает тайм-аут, завершается нагрузка запросов или закрывается сессия. Весь жизненный цикл планируется платформой — никакого режима «забыл остановить свой кластер», никаких ручных операций.
Поскольку жизненный цикл является мелкогранулярным, гранулярность биллинга снижается соответственно. Вычисления тарифицируются поминутно по фактическому времени работы — без минимального часа, без минимальной платы за запрос. Записи учитываются так же: фактическое использование ресурсов, поминутно.
Точность распределения затрат — это то, что позволяет On-Demand избегать надбавки за хранение, которую приходится взимать Serverless. Serverless оценивает хранение выше предельной себестоимости, потому что у его вычислительного слоя нет способа поглотить неатрибутированные затраты — каждый доллар, который тратит платформа, должен где-то оказаться в счете, поэтому хранение и записи становятся местом, куда сбрасывается то, что нельзя отнести куда-либо еще. Когда On-Demand тарифицирует каждую минуту вычислений на конкретную сессию, неатрибутированного пула нет. Хранение в On-Demand следует ценам Zilliz Cloud по тарифам Dedicated — примерно 1/10 типичного хранения Serverless.
Изоляция рабочих нагрузок на общих данных
Третье изменение — сделать вычислительный слой явным. В Dedicated вычислительный слой — это кластер, невидимый для пользователя, кроме как в виде единственного параметра размера. В Serverless вычислительный слой полностью скрыт. On-Demand делает его видимым.
Каждая рабочая нагрузка подключается к коллекции через группу вычислительных ресурсов. Новые группы запускаются — или существующие используются повторно — через сессии. Разные группы изолированы друг от друга, и счет каждой группы отражает только ее собственное потребление.
В случае автономного вождения именно так аналитическая рабочая нагрузка получает собственное подключение к данным: группа ресурсов On-Demand, которая запускается для ad-hoc запросов и освобождается при простое, работая на той же коллекции Milvus, тех же индексах и тех же метаданных, что и существующие рабочие нагрузки онлайн-поиска и обучения моделей. Разделение хранения и вычислений означает, что никому из них не нужно копировать или синхронизировать данные, чтобы их использовать. Никакого перекрестного субсидирования, никакой конкуренции за расписание, никакой операционной координации между командами по поводу формы кластера.
Это тот же архитектурный паттерн, что и у data lake, примененный к векторному поиску: хранение — это общая основа, а вычисления подключаются в той форме, которая нужна каждой рабочей нагрузке.
Счет после
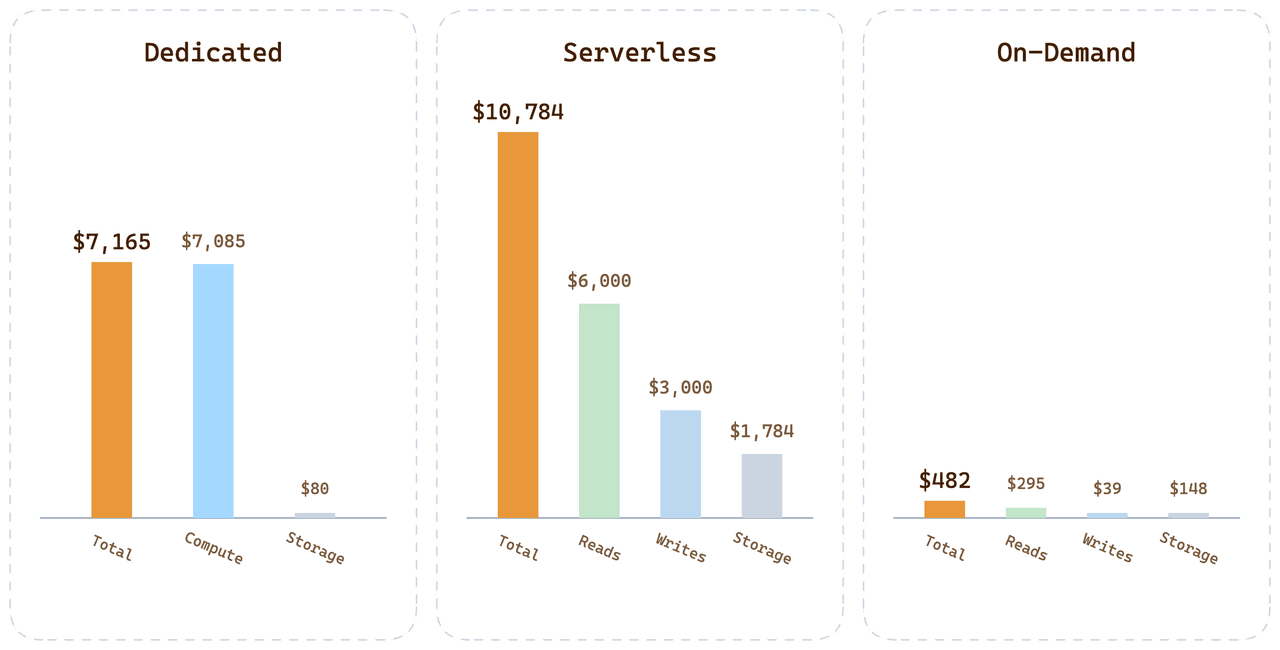
Для той же клиентской рабочей нагрузки по всем трем вариантам:
| Вариант | Ежемесячный счет | Куда уходят деньги |
|---|---|---|
| Dedicated (24 CU Tiered) | $7,165 | 99,6% вычислений оплачено, но простаивает |
| Serverless | $10,784 | Надбавка за запросы + $1,700 хранение + $3,000 записи |
| On-Demand | < $500 | Поминутные вычисления + хранение по тарифам Dedicated |
On-Demand для этой рабочей нагрузки обходится менее чем в 1/20 счета Serverless. Разница — не ценовой трюк; это прямое следствие отнесения затрат к реальному потреблению вместо амортизации вариативности других пользователей в каждой единице цены.
Где On-Demand — неподходящий инструмент
On-Demand не является универсальной заменой Dedicated или Serverless. Те же проектные решения, которые делают его дешевым для разреженных, всплесковых рабочих нагрузок, делают его неподходящим для других. На графике ниже показана месячная стоимость в зависимости от нагрузки запросов для рабочей нагрузки этого клиента по всем трем вариантам.
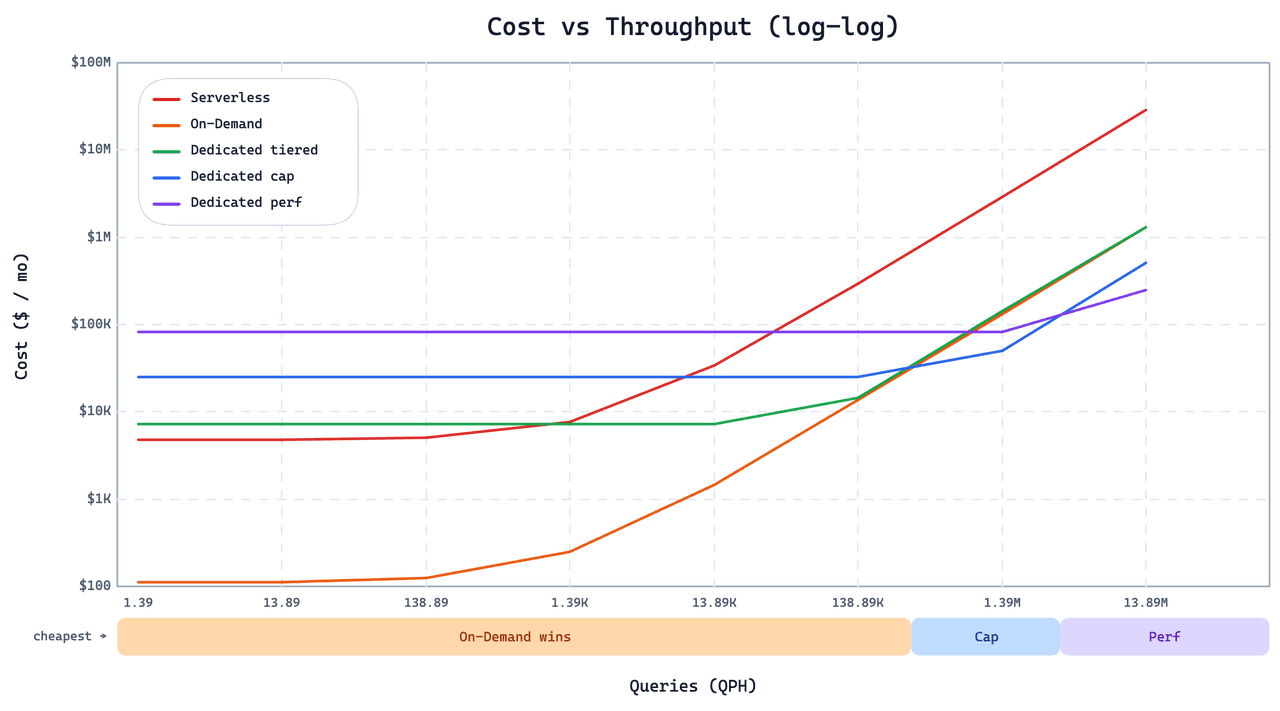
Ниже точки пересечения On-Demand значительно дешевле. Как только QPS достигает десятков, экземпляры Dedicated Cap or Perf instances становятся и дешевле, и быстрее. Два проектных решения объясняют эту точку пересечения:
Без графового индекса. Чтобы удешевить загрузку холодных запросов, On-Demand использует IVF вместо графовых индексов. Графовые индексы обеспечивают более высокий устойчивый QPS в масштабе, но стоимость их холодной загрузки высока. При нагрузке выше нескольких десятков QPS преимущество в устойчивом режиме становится решающим. Для обслуживания с высоким QPS используйте Dedicated.
Более высокая хвостовая задержка на холодных запросах. On-Demand не выполняет предварительную загрузку данных, поэтому холодный запрос платит дополнительным fetch перед выполнением. Тёплые запросы быстрые; холодные заметно медленнее, а распределение хвостовой задержки шире, чем на Dedicated или Serverless. Если ваше приложение не может допускать периодические ответы на уровне секунд (или хуже, минут), On-Demand вам не подходит. Для таких нагрузок Smart Autoscaling on Dedicated сокращает простаивающие мощности без ущерба для задержки в тёплом состоянии.
Где On-Demand действительно является правильным инструментом: разреженный доступ, аналитическая итерация и пакетный майнинг больших наборов данных — рабочие нагрузки, где высокая конкурентность и строгая стабильность задержки не являются основными требованиями.
Как это вписывается в Zilliz Vector Lakebase
Клиентский кейс в этом посте — один из срезов более широкой закономерности: один и тот же набор данных, к которому разные рабочие нагрузки обращаются с разной периодичностью, можно корректно масштабировать только тогда, когда каждая рабочая нагрузка получает ту вычислительную форму, которая ей действительно нужна. On-Demand — одна из таких вычислительных форм. Zilliz Vector Lakebase — это архитектура, которая делает возможным всё остальное.
Vector Lakebase — это lake-native платформа данных для AI-нагрузок. Данные находятся в S3, индексы отделены от вычислений, а разные вычислительные формы подключаются к одной и той же коллекции через zero-copy access. Она поддерживает три режима рабочих нагрузок как возможности первого класса — real-time retrieval, iterative discovery и batch analytics — каждый обслуживается вычислительной формой, соответствующей его паттерну доступа. Vector retrieval всегда был рабочей нагрузкой первого класса в Zilliz Cloud; с запуском Vector Lakebase вычислительные формы для iterative-discovery и batch-analytics присоединяются к нему на той же основе данных.
On-Demand — это вычислительная форма, созданная для аналитических и пиковых рабочих нагрузок. Остальные четыре возможности покрывают оставшиеся режимы:
- Tiered Serving Solutions для real-time retrieval — Performance-Optimized (1000+ QPS, задержка в единицы миллисекунд, всё в памяти), Capacity-Optimized (100–500 QPS при задержке менее 100 мс на памяти + локальном NVMe) и Tiered-Storage (10–50 QPS при задержке ~100 мс на памяти, NVMe и объектном хранилище). Разные точки на кривой производительность/стоимость, один и тот же режим обслуживания.
- External Data Lake Search для индексирования и поиска данных, уже находящихся в Lance, Iceberg или других lake-форматах — без копирования их в отдельное хранилище.
- Full-Spectrum Search для векторов, текста, JSON и геопространственных данных на одной плоскости запросов, с hybrid retrieval, фильтрацией и reranking на wide-table модели данных.
- Unified Lake-Native Storage на базе Vortex, next-generation открытого колоночного формата с более быстрыми случайными чтениями, чем Lance или Parquet, плюс гибкость формата по столбцам.
Zilliz Vector Lakebase теперь доступен в public preview на Zilliz Cloud. Полная архитектура и остальные возможности подробно описаны в каноническом материале Vector Lakebase deep-dive.
Чтобы попробовать On-Demand на своей рабочей нагрузке, зарегистрируйтесь в Zilliz Cloud и запустите On-Demand-кластер из консоли или CLI. Если цифры из этого поста похожи на то, что вы запускаете, команда Zilliz будет рада разобрать вашу рабочую нагрузку до начала разработки.

Читать далее

What Is a Vector Lakebase?
A Vector Lakebase is a unified, lake-native data architecture for AI that combines vector-database-grade serving with open lake storage, reusable lake-level indexes, and a shared semantic layer.

Zilliz Cloud Now Available in AWS Asia Pacific (Seoul)
Zilliz Cloud is now available in AWS Seoul — low-latency vector search, in-country data residency, and one-step migration for Korean AI teams. 31 regions across 5 clouds.

OpenAI o1: What Developers Need to Know
In this article, we will talk about the o1 series from a developer's perspective, exploring how these models can be implemented for sophisticated use cases.