




Хватит создавать инфраструктуру данных для ИИ не на том этапе
Большинство решений по AI-инфраструктуре принимаются на первой неделе, а сожалеть о них начинают, когда оглядываются назад на втором году.
Проблема почти никогда не в модели и редко в логике приложения. Всё возвращается к одному и тому же: инфраструктура данных должна строиться под тот этап, на котором находится команда.
На каждом этапе режим отказа работает в обе стороны. Слишком рано переусложните — и замедлите себя. Недооцените — и будете перестраивать под давлением. И то и другое приводит к одному результату: накладным расходам на итерации, которые накапливаются.
Этап 1: Прототип — просто заставьте его работать
В начале скорость важнее инфраструктуры данных — или, точнее, никакая так называемая «инфраструктура данных» вообще не нужна.
Цель — не масштабируемость. Цель — не управление данными. Цель — не оптимизация.
Цель — просто заставить приложение работать.
Самая распространённая ошибка на этом этапе — принимать сложность за качество. Команды добавляют потоковые пайплайны ingestion до того, как у них появляются документы для ingestion. Они настраивают репликацию production-grade до того, как у них появляется хотя бы один реальный пользователь. Они беспокоятся о согласованности данных между несколькими системами до того, как у них набирается достаточно данных, чтобы согласованность имела значение.
Результат: недели работы над инфраструктурой, которые можно было бы заменить простой сменой идеи.
Что касается горячей темы «vector database», она почти не имеет значения. Milvus, Elasticsearch, pgvector или даже лёгкая библиотека поиска — любой из этих вариантов справится с задачей. Разрыв в качестве retrieval между вариантами ничтожен по сравнению с разрывом между наличием работающего прототипа и его отсутствием.

Что вам на самом деле нужно на этом этапе:
- Ваша локальная файловая система
- Любая лёгкая база данных или библиотека поиска
Этап 2: Product-Market Fit — больше баз данных, хуже проблемы
Как только реальные пользователи начинают взаимодействовать с системой, фокус смещается с создания демо на непрерывное улучшение продукта, но появляется другая ловушка.
Заблуждение звучит разумно: более специализированные типы баз данных приводят к лучшему качеству retrieval.
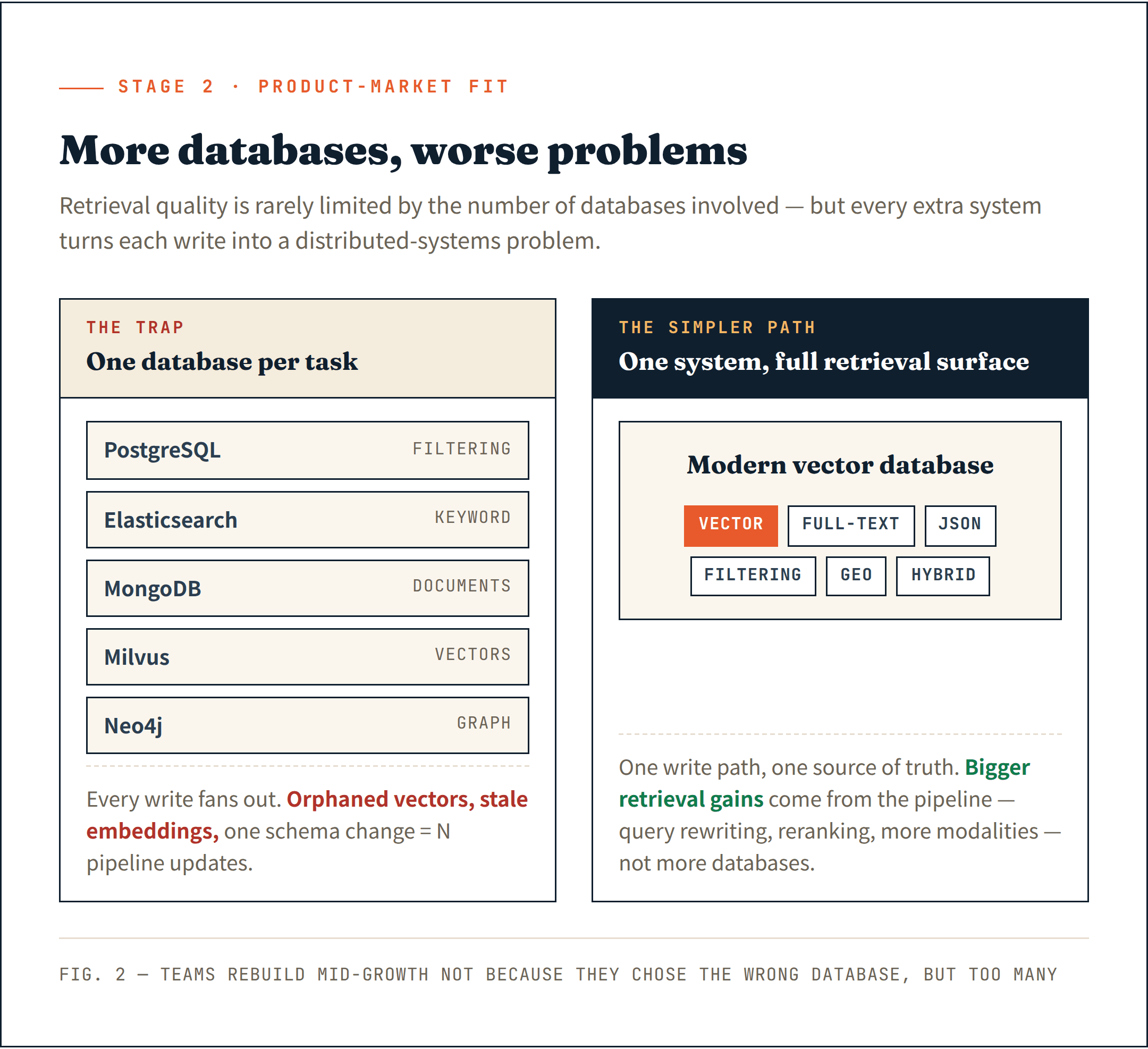
Некоторые команды начинают собирать по одной системе на каждую задачу retrieval — PostgreSQL для фильтрации, Elasticsearch для keyword search, MongoDB для документов, Milvus для vectors и Neo4j для graph relationships. Стек retrieval растёт быстрее, чем сам продукт.
Затем приходит проблема синхронизации.
Документы живут в одной системе. Embeddings — в другой. Metadata — в третьей. Каждая операция записи становится проблемой distributed systems. Неудачное удаление оставляет orphaned vectors. Частичная вставка создаёт stale embeddings. Изменение схемы требует обновлять сразу несколько пайплайнов.
Тяжёлый урок: качество retrieval редко ограничено количеством задействованных баз данных.
Более существенные улучшения приходят из самого пайплайна retrieval — dynamic query rewriting, iterative search, progressive disclosure, лучший reranking. Со стороны данных добавление ещё одного embedding field или ещё одной modality часто улучшает качество retrieval сильнее, чем добавление ещё одной специализированной базы данных.
Современные vector databases незаметно вышли далеко за рамки vectors. Full-text search, JSON filtering, geospatial search и hybrid retrieval — большинство зрелых систем теперь поддерживают это нативно. Предположение «специализированная база данных под каждую задачу» всё больше устаревает.
Единая система, которая покрывает всю поверхность retrieval, проще в эксплуатации и даёт более чистый фундамент для того, что будет дальше.
Я видел слишком много команд, вынужденных перестраивать свою инфраструктуру данных в середине роста — не потому, что они выбрали неправильную базу данных, а потому, что выбрали слишком много.
Что вам на самом деле нужно на этом этапе:
- Управляемый сервис баз данных — позвольте поставщику заниматься надежностью, пока вы фокусируетесь на продукте
- Единая система с широкой семантической поддержкой: векторный поиск, полнотекстовый поиск, JSON, фильтрация, гибридный поиск — а не отдельная база данных для каждой задачи
- Достаточный запас для роста на следующий порядок без перестройки
Этап 3: Рост в масштабе — не каждая рабочая нагрузка должна использовать одни и те же вычислительные ресурсы
Это этап, на котором давление затрат становится неоспоримым. Причина проста: данные всегда растут быстрее, чем ваша выручка.
Самая распространенная ошибка: предполагать, что традиционное решение для баз данных, которое довело вас до этого момента, поведет вас дальше.
В отличие от этапа 2, на этом этапе уже нет простого пространства для перестройки. Масштабная миграция инфраструктуры под давлением роста либо чрезвычайно дорога, либо чрезвычайно рискованна, либо и то и другое.
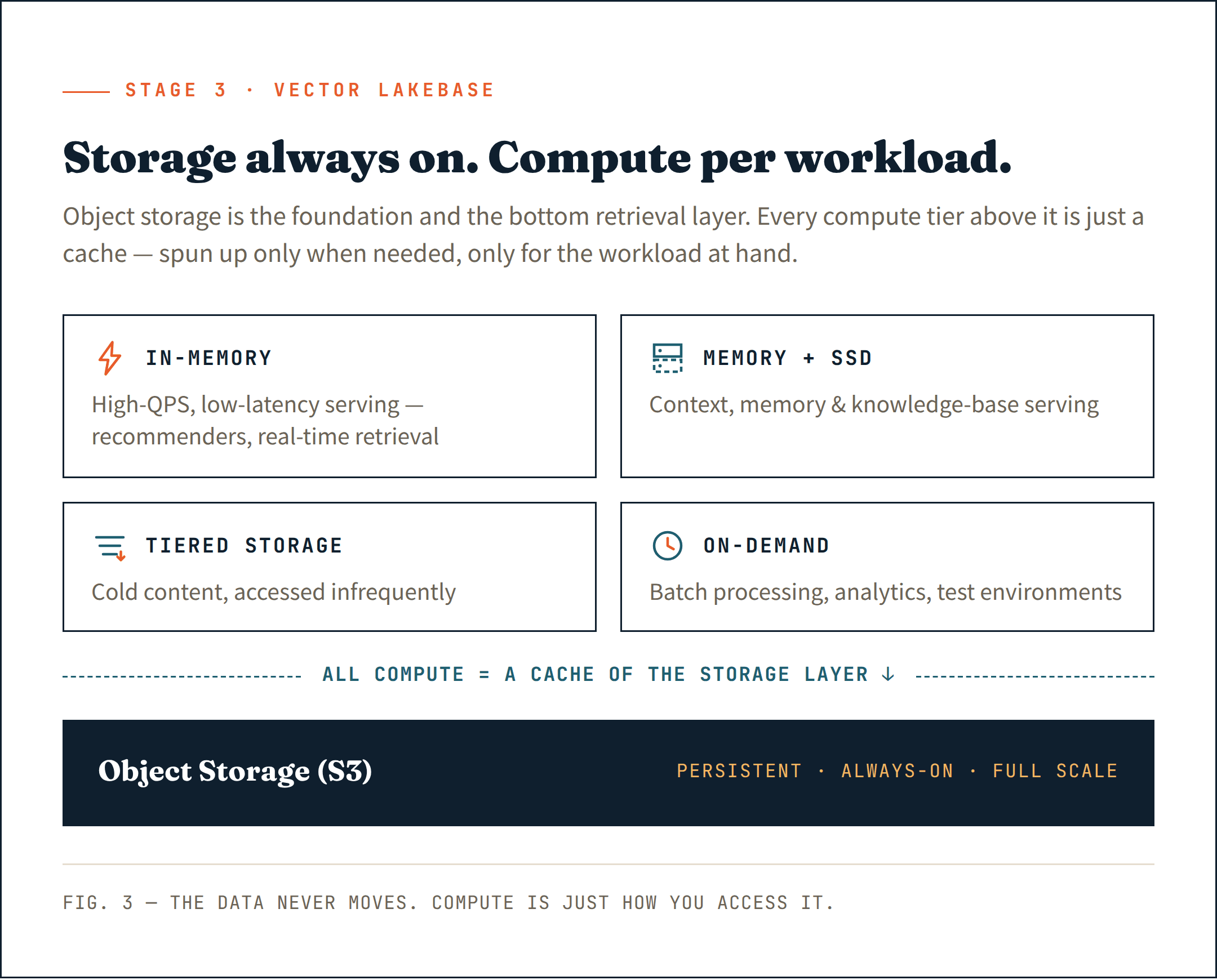
Правильный шаг — перенести всё на объектное хранилище (например, S3) — не просто как постоянное хранилище, а как базовый слой вашей архитектуры поиска. Это самый дешевый, самый надежный и самый масштабируемый вариант из существующих. Относитесь к нему как к фундаменту, а не как к чему-то второстепенному.
Над этим слоем подключайте вычислительные ресурсы только там, где они действительно нужны. Долгоживущие кластеры для обслуживания, чувствительного к задержкам. Эфемерные вычислительные ресурсы для загрузки данных и индексирования. Вычисления по требованию для аналитики и пакетных заданий. Каждая рабочая нагрузка получает нужные ей вычислительные ресурсы — и ничего лишнего.
В этом суть Vector Lakebase: хранилище, которое всегда включено в полном масштабе, и вычислительные ресурсы, которые не являются таковыми — запускаются только при необходимости, только для конкретной рабочей нагрузки.
Что особенно важно, все вычислительные ресурсы — будь то долгоживущие или по требованию — действуют как кэш слоя объектного хранилища. Данные всегда находятся в хранилище. Вычислительные ресурсы — это лишь способ доступа к ним.
Сопоставляйте каждую рабочую нагрузку с правильным уровнем вычислений:
- In-memory для нагрузок с высоким QPS и низкой задержкой — AI-рекомендательные системы, поиск в реальном времени
- Memory + SSD для обслуживания контекста, памяти и баз знаний
- Tiered storage для холодного контента, к которому обращаются редко
- On-demand compute для пакетной обработки, внутренней аналитики и тестовых сред
При правильной реализации этот подход снижает затраты на инфраструктуру на 50% или более по сравнению с унифицированной архитектурой — одновременно обеспечивая гораздо более высокое качество обслуживания для каждой рабочей нагрузки.
Serverless-решения часто начинают давать сбой на этом этапе — не технически, а экономически. Как только объем ваших данных переходит в терабайты, затраты на вставку и хранение начинают доминировать. Причина структурная: serverless-архитектуры включают накладные расходы на пул ресурсов, индексирование и затраты на постоянные данные в наценки на запись и хранение. Вы больше не платите за то, что используете. Вы платите за абстракцию.
Первый принцип инфраструктуры данных на этом этапе прост: ваш фундамент должен масштабироваться вместе с вашими данными, а не против них. Одна архитектура, вынужденная одинаково хорошо обслуживать каждую рабочую нагрузку, в итоге не обслуживает хорошо ни одну из них — и цена этого компромисса накапливается с каждым добавленным гигабайтом.
Что вам действительно нужно на этом этапе:
- Объектное хранилище (S3) как фундамент и нижний слой поиска — постоянное, всегда включенное в полном масштабе, слой, из которого читают все вычислительные ресурсы
- Vector Lakebase: данные, которые никогда не перемещаются, и вычислительные ресурсы, которые запускаются под каждую рабочую нагрузку и ничего сверх этого
- Правильный уровень вычислительных ресурсов для каждого типа рабочей нагрузки
Этап 4: Корпоративный масштаб — доверие становится частью продукта
К этому этапу большинство команд считает, что самое сложное уже позади. Это не так.
Распространенная ошибка: команды всё еще думают, что проблема техническая.
Они оптимизировали инфраструктуру. Они контролируют затраты. Они предполагают, что масштабирование до корпоративного уровня — это вопрос добавления мощности и установки галочки в пункте безопасности.
Это не так.
Вопросы, которые блокируют корпоративные сделки, не имеют ничего общего с производительностью:
Как наши данные изолированы от данных других клиентов?
Кто к чему имеет доступ, и можете ли вы это доказать?
Можете ли вы обслуживать нас в нашем регионе?
Можем ли мы развернуть это внутри нашего собственного cloud account?
Но индивидуальные требования сделок — лишь часть проблемы. На Stage 3 неоднородность была технической — разные workloads, разные compute tiers. На этом этапе она становится структурной: ваша клиентская база требует платформенной data infrastructure, чтобы с этим справляться.
У вас есть бесплатные пользователи, которым нужно экономичное shared serving. У вас есть платные индивидуальные клиенты, которые ожидают лучшей доступности. У вас есть enterprise-клиенты, которым требуются полная изоляция данных, dedicated compute и возможность аудировать всё. Обслуживать все три группы на одной и той же архитектуре означает, что вы либо тратите слишком много на свой free tier, либо недостаточно хорошо обслуживаете enterprise-клиентов, либо и то и другое.
Правильный ответ — tiered infrastructure, соответствующая каждому сегменту клиентов:
- Shared clusters для бесплатных и индивидуальных пользователей — pooled, оптимизированные по стоимости
- Isolated clusters для каждого enterprise-клиента — dedicated compute, dedicated storage, dedicated access controls
- BYOC для клиентов, которым требуется развертывание внутри их собственного cloud account

Пункт BYOC — это место, где большинство команд совершает критическую ошибку. SaaS и BYOC выглядят как два продукта. Если они расходятся на уровне архитектуры, вы поддерживаете две codebase, два deployment pipeline и два operational runbook — бесконечно. Команды, которые сделали это правильно, рассматривали BYOC как deployment model, а не как отдельный продукт. Тот же data plane, тот же control interface, другая deployment target.
Global reliability — другая часть, которую откладывают слишком надолго. В enterprise scale multi-regions — это не premium feature, а базовое ожидание. Enterprise-клиенты из разных географий не будут терпеть single-region deployment, как и не примут ваши SLA commitments. Без unified data infrastructure interface across clouds and regions вы в итоге эксплуатируете разные data layers в разных средах — real-time data sync становится отдельной проблемой distributed systems, а operational complexity растет с каждым новым регионом, который вы добавляете.
Команды, с которыми я общался и которые дошли до серьезных enterprise deals, описывали одно и то же болезненное открытие: ничего из этого не было заложено с самого начала. Это было добавлено позже, под давлением активного sales cycle. Одна команда потратила четыре месяца на retrofitting data-level isolation в архитектуру, которая не была для этого построена. Они это выпустили. Но они точно знали, почему это хрупко.
Enterprise readiness — это не checklist. Это следствие архитектурных решений, принятых гораздо раньше.
Что вам на самом деле нужно на этом этапе:
- Unified data infrastructure interface — consistent across clouds, consistent across regions
- Global clusters, designed for high reliability and multi-region serving
- Tiered serving: shared clusters для бесплатных пользователей, isolated clusters для каждого enterprise-клиента
- SaaS и BYOC на одной и той же архитектуре — one data plane, разные deployment targets
- Open standards и open source в основе — no vendor lock-in at enterprise scale
Что общего у команд, которые хорошо масштабировались
Паттерн устойчив.
Каждый этап вводит совершенно иной класс проблем. Stage 1 — это проблема скорости. Stage 2 — проблема сложности. Stage 3 — проблема стоимости и архитектуры. Stage 4 — проблема доверия и платформы.

Команды, которые прошли каждый этап без болезненной перестройки, поняли это рано. Они перестали спрашивать "какая база данных мне нужна прямо сейчас?" и начали спрашивать "что потребуется на следующем этапе — и не закрывает ли мое текущее решение эту дверь?"
На этапе 1 векторная база данных — ровно тот инструмент, который нужен. Говорю это без оговорок.
На этапе 3 и далее необходимым становится нечто принципиально иного рода — Vector Lakebase. Хранилище всегда включено в полном масштабе. Вычисления соответствуют каждой рабочей нагрузке. Платформа, способная обслуживать бесплатного пользователя, платящего клиента и корпоративный аккаунт на одной и той же архитектуре, без разветвления.
Команды, которые пришли к этому быстрее, не были умнее или лучше профинансированы.
Они просто раньше поняли, что инфраструктурное решение не было временным выбором.
Это был фундамент, на котором будет построено всё остальное.
Zilliz Vector Lakebase доступен в публичной предварительной версии
Мы запустили публичную предварительную версию Zilliz Vector Lakebase — крупную эволюцию Zilliz Cloud: от управляемой векторной базы данных к единой семантической платформе данных, которая объединяет производственную векторную базу данных с общей, lake-native основой данных.
Ключевые возможности Zilliz Vector Lakebase:
- Многоуровневое обслуживание, оптимизированное под разные компромиссы между производительностью в реальном времени и стоимостью
- Поиск по требованию для крупномасштабных или исследовательских рабочих нагрузок без постоянно включенных вычислений
- Поиск по внешнему озеру данных — индексируйте и ищите напрямую по вашим существующим данным в озере
- Полноспектральный поиск по векторам, тексту, JSON и геопространственным данным с гибридным извлечением и reranking
- Единое lake-native хранилище на базе Vortex, открытого формата с более быстрым и дешевым произвольным чтением, чем у Lance или Parquet
Если ваш текущий стек разделяет обслуживание и обнаружение на отдельные системы, на Vector Lakebase, возможно, стоит взглянуть. Попробуйте его в Zilliz Cloud — новые регистрации с рабочей электронной почтой получают $100 бесплатных кредитов — или свяжитесь с нами, чтобы обсудить ваш сценарий использования.
Узнайте больше о Vector Lakebases
- От векторной базы данных к Vector Lakebase
- Мы 8 лет делали векторные базы данных быстрее. Потом мы остановились.
- Почему мы создали Vector Lakebase: переосмысление архитектуры неструктурированных данных для ИИ
- Vector Lakebase: покончить с изолированным хранилищем данных ИИ
- Zilliz Cloud On-Demand Compute: платите только за то, что используете
- Векторный поиск Notion превосходен. Их следующая проблема сложнее.

Читать далее

How to Choose the Best Embedding Model for RAG in 2026: 10 Models Benchmarked
We benchmarked 10 embedding models on cross-modal, cross-lingual, long-document, and dimension compression tasks. See which one fits your RAG pipeline.

Zilliz Cloud Just Landed in Claude Code
The Zilliz Cloud Plugin brings the full power of Zilliz Cloud directly into your Claude Code terminal as natural-language conversations.

What is the K-Nearest Neighbors (KNN) Algorithm in Machine Learning?
KNN is a supervised machine learning technique and algorithm for classification and regression. This post is the ultimate guide to KNN.