




ColPali: Улучшенный поиск документов с помощью языковых моделей зрения и стратегии встраивания ColBERT
Retrieval Augmented Generation (RAG) - это техника, которая объединяет возможности больших языковых моделей (LLMs) с внешними источниками знаний для повышения точности и релевантности ответов. Частым применением RAG является извлечение контента из таких источников, как PDF-файлы, поскольку эти файлы часто содержат ценные данные, но сложны для поиска и индексации. Сложность заключается в том, что важная информация может быть упущена в зависимости от инструмента, используемого для извлечения. Например, текст, встроенный в изображения, может быть не обнаружен при извлечении, что делает его невозможным для последующего извлечения.
Модель поиска документов ColPali, решает эту проблему с помощью новой архитектуры, основанной на визуальных языковых моделях (VLM). Она индексирует документы по их визуальным признакам, захватывая текстовые и визуальные элементы. Генерируя многовекторные представления текста и изображений в стиле ColBERT, ColPali кодирует изображения документов непосредственно в единое пространство встраивания, устраняя необходимость в традиционном извлечении и сегментации текста.
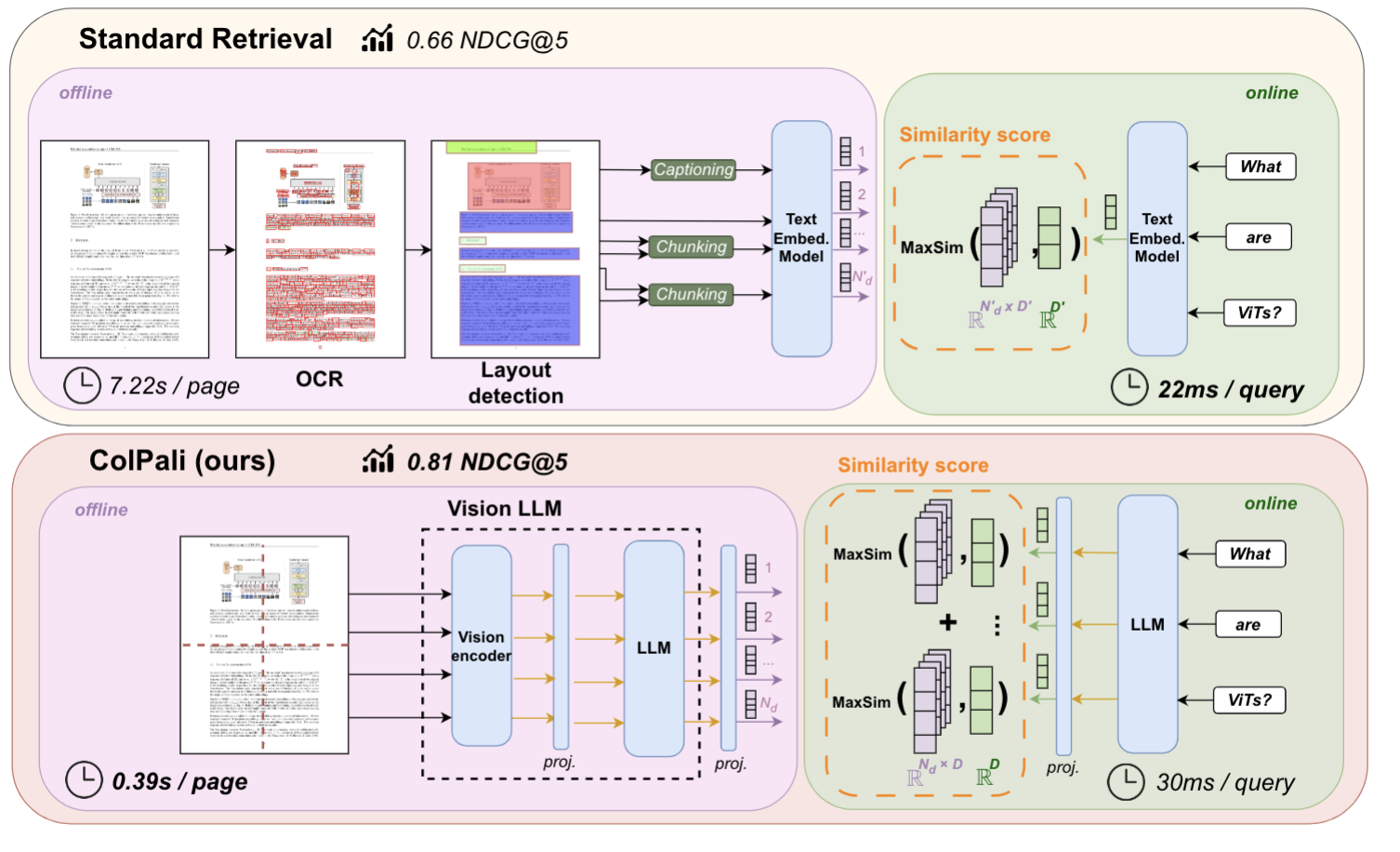 Рисунок: Стандартный конвейер поиска и конвейер ColPali для поиска PDF
Рисунок: Стандартный конвейер поиска и конвейер ColPali для поиска PDF
Изображение выше взято из статьи ColPali, где авторы утверждают, что обычный конвейер поиска PDF-файлов обычно включает в себя несколько этапов: извлечение текста с помощью OCR, определение расположения, разбиение на части и создание вставки. ColPali упрощает этот процесс, используя одну модель языка зрения (VLM), которая принимает на вход скриншот страницы.
ColPali объединяет инструменты, выходящие за рамки традиционных RAG-систем, поэтому важно понять некоторые из этих концепций. Прежде чем обсуждать детали ColPali, давайте познакомимся с моделями языка зрения и моделями позднего взаимодействия.
Что такое модели языка зрения (VLM)?
Модели языка зрения (VLM) - это мультимодальные модели, которые обучаются на основе изображений и текста одновременно. Они принимают изображения и текст на вход и генерируют текст на выходе и являются частью более широкой категории генеративных моделей.
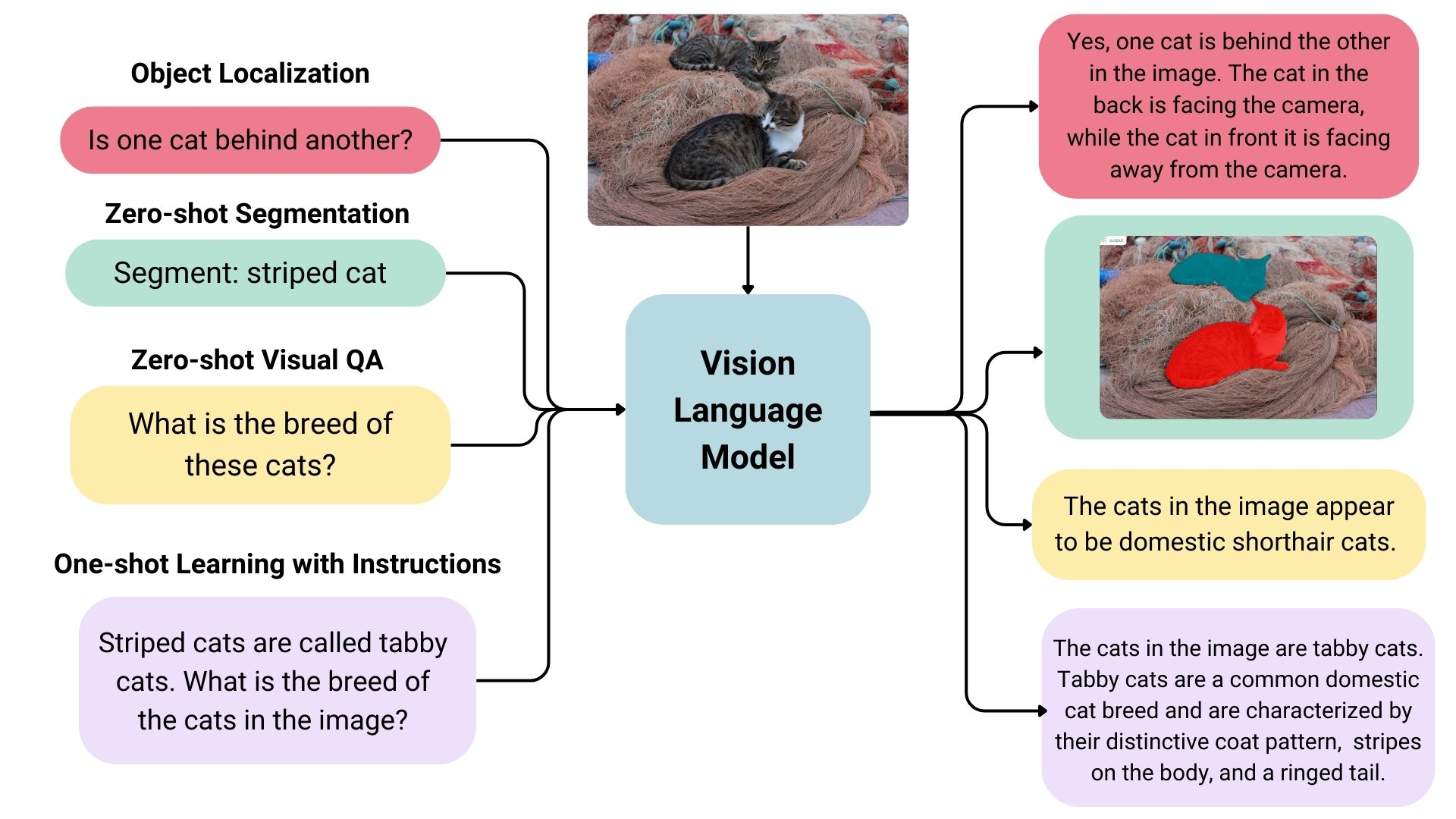 Пример VLM
Пример VLM
ColPali использует VLM для выравнивания вкраплений лексем текста и изображений, полученных в ходе мультимодальной тонкой настройки. В частности, используется расширенная версия модели PaliGemma-3B для создания ColBERT-стиля многовекторных представлений. Авторы выбрали эту модель, поскольку она имеет множество контрольных точек, точно настроенных для различных разрешений изображений и задач, включая OCR для чтения текста с изображений.
ColPali построена на основе модели Google PaliGemma-3B, которая была выпущена с открытым весом. Эта модель была обучена на разнообразном наборе данных - 63 % академических и 37 % синтетических данных, полученных из просмотренных PDF-страниц, дополненных псевдовопросами, сгенерированными VLM.
Что такое модели позднего взаимодействия?
Модели Late Interaction предназначены для задач поиска. Они фокусируются на сходстве между документами на уровне лексем, а не на использовании единого векторного представления. Представляя текст в виде серии вкраплений лексем, эти модели обеспечивают детализацию и точность кросс-кодирования, но при этом пользуются преимуществами эффективности автономного хранения документов.
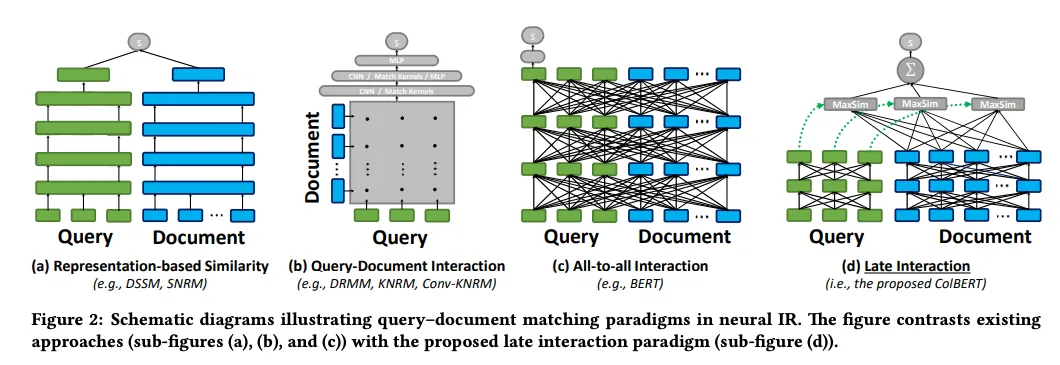 Рисунок 2: Схематические диаграммы, иллюстрирующие парадигмы сопоставления запроса и документа в нейронном IR
Рисунок 2: Схематические диаграммы, иллюстрирующие парадигмы сопоставления запроса и документа в нейронном IR
Рисунок 2: Схематические диаграммы, иллюстрирующие парадигмы согласования запросов и документов в нейронном ИР. | Источник_
Имея такое представление о моделях позднего взаимодействия и моделях языка видения, мы можем теперь изучить, как ColPali сочетает эти элементы для улучшения поиска документов.
Что такое ColPali и как он работает?
ColPali - это усовершенствованная модель поиска документов, предназначенная для индексирования и извлечения информации непосредственно из визуальных особенностей документов, в частности PDF-файлов. В отличие от традиционных методов, основанных на оптическом распознавании символов (OCR) и сегментации текста, ColPali делает скриншоты каждой страницы и встраивает все страницы документа в единое векторное пространство с помощью VLM. Такой подход позволяет ColPali обойти сложные процессы извлечения, повышая точность и эффективность поиска.
Ниже приведены основные этапы рабочего процесса:
Обработка документов
- Создание изображений из PDF: Вместо того чтобы извлекать текст, создавать фрагменты, а затем вставлять их, ColPali напрямую вставляет скриншот страницы PDF в векторное представление. Этот шаг похож на фотографирование каждой страницы, а не на попытку извлечь ее содержимое.
- Разделение изображений на сетки: Затем каждая страница делится на сетку из однородных фрагментов, называемых патчами. По умолчанию она делится на сетку 32x32, в результате чего на одно изображение приходится 1024 патча. Каждый патч представлен в виде 128-мерного вектора. Вы можете представить это как одно изображение с 1024 "словами", описывающими эти патчи.
Генерация встраивания
- Обработка патчей изображений: ColPali преобразует эти визуальные патчи в эмбеддинги с помощью Vision Transformer (ViT), который обрабатывает каждый патч для создания детального векторного представления.
- Согласование визуальных и текстовых вкраплений: Чтобы сопоставить визуальную информацию с поисковым запросом, ColPali преобразует текст запроса во вкрапления в том же векторном пространстве, что и пятна изображений. Такое выравнивание позволяет модели напрямую сравнивать и сопоставлять визуальный и текстовый контент.
- Обработка запроса: Модель токенизирует запрос, присваивая каждой лексеме 128-мерный вектор. Она использует подсказки типа "Опишите это изображение
", чтобы модель сосредоточилась на визуальных элементах, обеспечивая беспрепятственную интеграцию текстовых и визуальных данных.
Механизм извлечения
ColPali использует механизм позднего сходства взаимодействия для сравнения вложений запроса и документа во время запроса. Этот подход позволяет детально взаимодействовать между всеми векторами ячеек сетки изображений и векторами маркеров текста запроса, обеспечивая всестороннее сравнение.
Сходство вычисляется с использованием подхода "сумма максимальных сходств":
- Вычисление баллов сходства между каждой лексемой запроса и каждой лексемой патча на изображении.
- Суммируйте эти оценки, чтобы получить оценку релевантности для каждого документа.
- Сортировка документов по баллу в порядке убывания с использованием балла в качестве меры релевантности.
Этот метод позволяет ColPali эффективно сопоставлять запросы пользователей с соответствующими документами, фокусируясь на фрагментах изображений, которые лучше всего соответствуют тексту запроса. При этом выделяются наиболее значимые фрагменты документа, объединяя текстовый и визуальный контент для точного поиска.
Процесс обучения модели
ColPali построен на основе модели PaliGemma-3B - языковой модели зрения, разработанной Google. В своей реализации ColPali сохраняет веса модели замороженными во время обучения, чтобы сохранить предварительно обученные знания VLM и сосредоточиться на оптимизации для задач поиска документов.
Ключ к адаптации этой VLM общего назначения для поиска документов лежит в небольшом, но очень важном компоненте: адаптер для поиска документов. Этот адаптер накладывается поверх модели PaliGemma-3B и обучается для изучения представлений, адаптированных для задач поиска.
В процессе обучения этого адаптера используется подход триплетного обучения:
- Текстовый запрос
- Изображение страницы, соответствующей запросу
- Изображение страницы, не имеющей отношения к запросу
Этот метод позволяет модели научиться тонко различать релевантный и нерелевантный контент, что повышает точность поиска.
Преимущества ColPali
- Отказ от сложной предварительной обработки: ColPali заменяет традиционную процедуру извлечения текста, OCR, определения макета и разбивки на части одним VLM, который берет на вход скриншот страницы.
- Получение визуальной и текстовой информации: Работая непосредственно с изображениями страниц, ColPali может учитывать как текстовый контент, так и визуальную компоновку при изучении документов.
- Эффективное извлечение информации из визуально насыщенных документов: Механизм позднего взаимодействия обеспечивает тонкое соответствие между запросами и содержанием документа, позволяя эффективно извлекать необходимую информацию из сложных, визуально насыщенных документов.
- Сохранение контекста: Оперируя изображениями целых страниц, ColPali сохраняет полный контекст документа, который может быть утерян при традиционных подходах к разбивке текста.
Вызовы ColPali
Как и любая крупномасштабная поисковая система, ColPali сталкивается с серьезными проблемами в плане вычислительной сложности и требований к хранению данных.
Вычислительная сложность: Вычислительные требования ColPali растут квадратично с количеством лексем запроса и векторов патчей. Это означает, что при увеличении сложности запросов или разрешения изображений документов вычислительные требования быстро растут.
Требования к хранению: Затраты на хранение данных при ColBERT-подобных подходах составляют от 10 до 100 раз больше, чем при плотном векторном встраивании, поскольку для каждого маркера требуется свой вектор. Потребности системы в хранении данных линейно зависят от трех факторов:
Количество документов
Количество патчей на документ
Размерность векторных представлений.
Такое масштабирование может привести к значительным требованиям к хранению больших коллекций документов.
Стратегия оптимизации - снижение точности
Для решения этих проблем масштабирования мы предлагаем использовать стратегию уменьшения точности.
- Снижение точности: Переход от представлений с высокой точностью (например, 32-битных плавающих чисел) к форматам с более низкой точностью (например, 8-битным целым числам) может значительно снизить требования к хранению данных, при этом качество поиска часто оказывается минимальным.
Резюме
ColPali обладает значительным потенциалом для преобразования способов получения визуально насыщенного контента с текстовым контекстом в системах RAG. Используя языковые модели зрения, он позволяет осуществлять поиск документов не только по тексту, но и по визуальным элементам.
Однако, несмотря на впечатляющие результаты, ColPali сталкивается с проблемами, связанными с высокими требованиями к хранению данных и вычислительной сложностью, что может препятствовать широкому распространению. Будущая оптимизация может устранить эти ограничения и сделать его более практичным. По мере развития методов RAG методы поиска, подобные ColPali, объединяющие визуальное и текстовое понимание, вероятно, будут играть все более важную роль в информационном поиске по различным типам документов.
Мы будем рады услышать ваше мнение!
Если вам понравилась эта статья в блоге, мы будем очень признательны, если вы поставите нам звезду на GitHub! Вы также можете присоединиться к нашему сообществу Milvus на Discord, чтобы поделиться своим опытом. Если вам интересно узнать больше, загляните в наш репозиторий Bootcamp на GitHub или в наши блокноты. Мы также будем рады услышать, если вы планируете попробовать ColPali в будущем!
Дальнейшее чтение
- Бумага ColPali: [2407.01449] ColPali: Efficient Document Retrieval with Vision Language Models
- ColPali GitHub: https://github.com/illuin-tech/colpali
- ColBERT: A Token-Level Embedding and Ranking Model
- ColPali: Document Retrieval with Vision Language Models
- Что такое RAG?
- Что такое векторные базы данных и как они работают?

Читать далее

A Developer's Guide to Exploring Milvus 2.6 Features on Zilliz Cloud
Milvus 2.6 marks a shift from “vector search + glue code” to a more advanced retrieval engine, and it is now Generally Available (GA) on Zilliz Cloud (a managed Milvus service).

How to Build RAG with Milvus, QwQ-32B and Ollama
Hands-on tutorial on how to create a streamlined, powerful RAG pipeline that balances efficiency, accuracy, and scalability using the QwQ-32B and Milvus.

Cosmos World Foundation Model Platform for Physical AI
NVIDIA's Cosmos platform enables safe, digital twin training of GenAI models for physical applications, overcoming data scarcity and safety challenges.