




Выбор правильной модели встраивания для ваших данных
Что такое модели встраивания?
Модели встраивания - это модели машинного обучения, которые преобразуют неструктурированные данные (текст, изображения, аудио и т. д.) в векторы фиксированного размера, также известные как векторные встраивания (разреженное, плотное, бинарное встраивание и т. д.). Эти векторы передают семантический смысл неструктурированных данных, облегчая выполнение различных задач, таких как поиск по сходству, обработка естественного языка (NLP), компьютерное зрение, кластеризация, классификация и другие.
Существуют различные типы моделей встраивания, включая встраивания слов, встраивания предложений, встраивания изображений, мультимодальные встраивания и многие другие.
Встраивание слов: Представляют слова в виде плотных векторов. Примеры включают Word2Vec, GloVe и FastText.
Вкрапления предложений: Представляют целые предложения или абзацы. Примеры: Universal Sentence Encoder (USE) и Sentence-BERT.
Вкрапления изображений: Представляют изображения в виде векторов. Примеры включают такие модели, как ResNet и CLIP.
Мультимодальные вкрапления: Объединяют различные типы данных (например, текст и изображения) в единое пространство встраивания. CLIP от OpenAI является ярким примером.
Модели встраивания и дополненная генерация поиска (RAG)
Retrieval Augmented Generation (RAG) - это паттерн в генеративном ИИ, в котором вы можете использовать свои данные для расширения знаний модели-генератора LLM (например, ChatGPT). Этот подход - идеальное решение для устранения раздражающих галлюцинаций в LLM. Он также может помочь вам использовать ваши специфические или частные данные для создания приложений GenAI, не беспокоясь о безопасности данных.
RAG состоит из двух различных моделей, embedding models и large language models (LLMs), которые используются в режиме вывода. В этом блоге рассказывается о том, как выбрать лучшую модель встраивания и где ее найти в зависимости от типа данных и, возможно, языка или области специализации, например, юриспруденции.
Как выбрать лучшую модель встраивания для ваших данных
Выбор правильной модели встраивания для ваших данных требует понимания конкретного случая использования, типа данных и требований к производительности вашего приложения.
Текстовые данные: MTEB Leaderboard
Доска лидеров HuggingFace MTEB - это универсальный магазин для поиска моделей встраивания в текст! Для каждой модели встраивания вы можете увидеть ее среднюю производительность в целом по задачам.
Хороший способ начать - отсортировать по убыванию по столбцу "Retrieval Average ", поскольку эта задача наиболее связана с векторным поиском. Затем найдите модель с наименьшим объемом памяти (ГБ).
Размер вложения - это длина вектора, т.е. y-часть в f(x)=y, которую выводит модель.
Макс токенов - длина фрагмента входного текста, т. е. x-части в f(x)=y, который вы можете ввести в модель.
В дополнение к задаче "Извлечение" можно также фильтровать по:
Язык: французский, английский, китайский или польский. Например, task=retrieval и Language=chinese.
Юридический. Например, task=retrieval and Language=law, для моделей, точно настроенных на юридические тексты.
К сожалению, поскольку обучающие данные только недавно стали общедоступными, некоторые позиции MTEB представляют собой overfitted models, занимающие обманчиво более высокие позиции, чем они реально могут показать на ваших данных. В этом блоге от HuggingFace есть советы, как решить, доверять ли рейтингу модели. Щелкните ссылку на модель (так называемую "карточку модели").
Поищите блоги и статьи, которые объясняют, как модель обучалась и оценивалась. Внимательно изучите языки, данные и задачи, на которых обучалась модель. Также ищите модели, созданные авторитетными компаниями. Например, на карточке модели voyage-lite-02-instruct вы увидите другие модели производства VoyageAI, но не эту. Это подсказка! Эта модель - тщеславная модель для переоборудования. Не используйте ее!
На скриншоте ниже я бы попробовал новую запись от Snowflake, "snowflake-arctic-embed-1", потому что она имеет высокий рейтинг, достаточно мала, чтобы работать на моем ноутбуке, а в карточке модели есть ссылки на блог и статью.
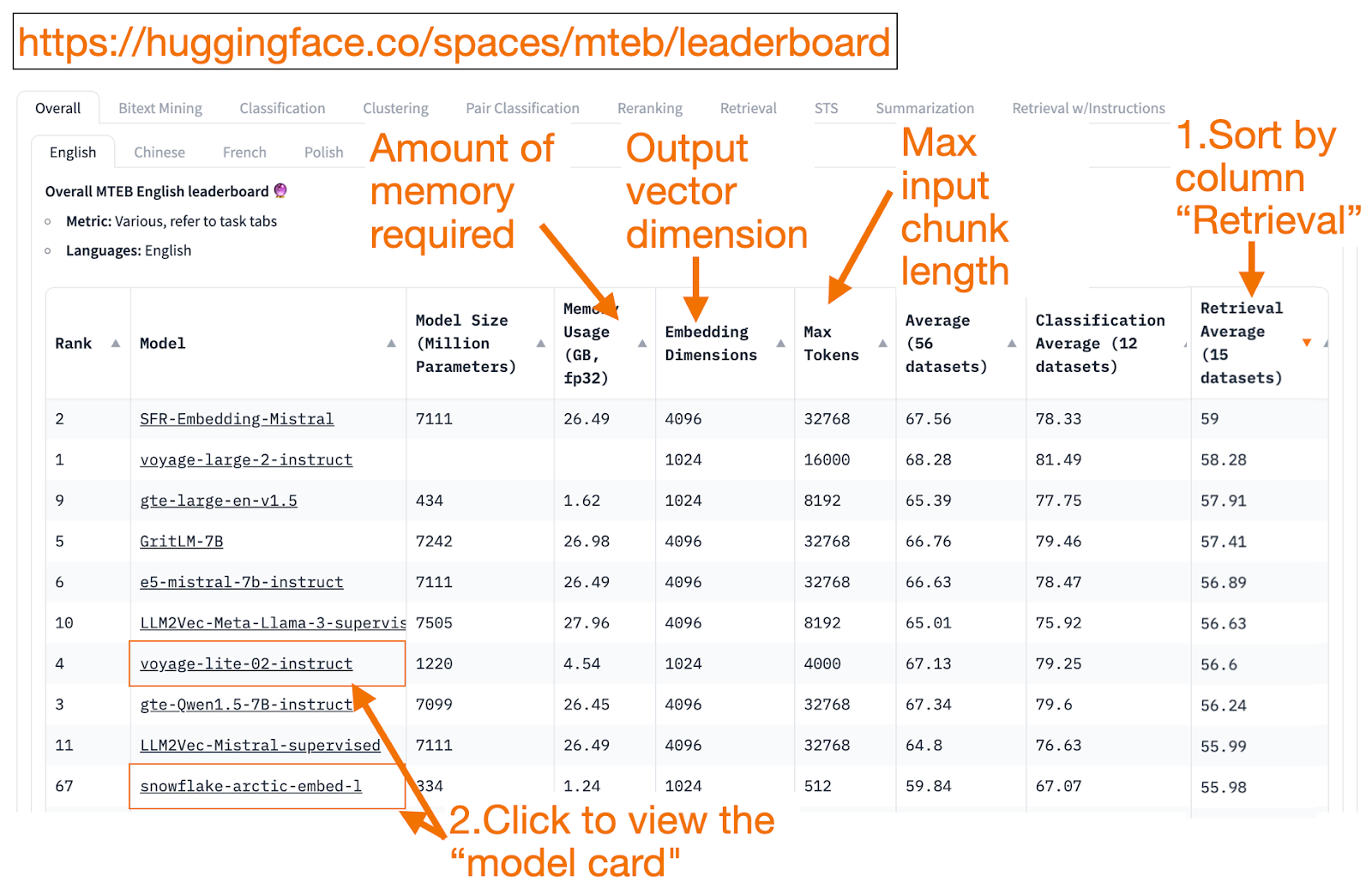 Sceenshot of Snowflake on MTEB Leaderboard
Sceenshot of Snowflake on MTEB Leaderboard
После того как вы выберете модель встраивания, приятным моментом в использовании моделей HuggingFace является то, что вы можете изменить модель, изменив **model_name** в коде!
import torch
from sentence_transformers import SentenceTransformer
# Инициализация настроек torch
torch.backends.cudnn.deterministic = True
DEVICE = torch.device('cuda:3' if torch.cuda.is_available() else 'cpu')
# Загружаем модель из huggingface.
model_name = "WhereIsAI/UAE-Large-V1" # Просто измените model_name, чтобы использовать другую модель!
encoder = SentenceTransformer(model_name, device=DEVICE)
# Получите параметры модели и сохраните их на потом.
EMBEDDING_DIM = encoder.get_sentence_embedding_dimension()
MAX_SEQ_LENGTH_IN_TOKENS = encoder.get_max_seq_length()
# Выведите параметры модели.
print(f "имя_модели: {имя_модели}")
print(f "EMBEDDING_DIM: {EMBEDDING_DIM}")
print(f "MAX_SEQ_LENGTH: {MAX_SEQ_LENGTH_IN_TOKENS}")

Данные изображения: ResNet50
Иногда требуется найти изображения, похожие на входное изображение. Может быть, вы ищете больше изображений кошек породы скоттиш-фолд? В этом случае вы загрузите свое любимое изображение кошки породы скоттиш-фолд и попросите поисковую систему найти похожие изображения!
ResNet50 - популярная модель Convolutional Neural Network (CNN), первоначально обученная в 2015 году компанией Microsoft на данных ImageNet.
Аналогично, для обратного поиска видео ResNet50 может встраивать видео. Затем в базе данных видеозаписей выполняется обратный поиск сходства изображений. Ближайшее видео (за исключением входного) возвращается пользователю как наиболее похожее.
Звуковые данные: PANNs
Аналогично тому, как вы можете использовать обратный поиск изображений по входному изображению, вы также можете использовать обратный поиск аудиоклипов по входному звуковому фрагменту.
PANNs (Pretrained Audio Neural Networks) - популярные модели встраивания для этой задачи, поскольку они предварительно обучены на больших наборах аудиоданных и хорошо справляются с такими задачами, как классификация и тегирование аудио.
Мультимодальные изображения и текстовые данные: SigLIP или Unum
За последние несколько лет появились модели встраивания, которые обучаются на смеси [неструктурированных данных] (https://zilliz.com/glossary/unstructured-data): Текст, Изображение, Аудио или Видео. Такие модели встраивания отражают семантику сразу нескольких типов неструктурированных данных в одном векторном пространстве.
Модели мультимодального встраивания позволяют использовать текст для поиска изображений, генерировать текстовые описания изображений или осуществлять обратный поиск по входному изображению.
CLIP (Contrastive Language-Image Pretraining) от OpenAI в 2021 году была стандартной моделью встраивания. Однако практикам было сложно ее использовать, поскольку она требовала тонкой настройки. В 2024 году SigLIP, или сигмоидальный CLIP от Google, представляется улучшенным CLIP, и есть сообщения о хороших результатах использования подсказок zero-shot.
Варианты малых моделей LLM становятся все более популярными. Вместо того чтобы требовать большого кластера облачных вычислений, они могут работать на ноутбуках (как мой M2 Apple с 16 ГБ ОЗУ). Маленькие модели используют меньше памяти, а значит, имеют меньшую задержку и потенциально могут работать быстрее, чем большие модели. Unum предлагает мультимодальные модели для встраивания небольшого размера.
Мультимодальные текстовые и/или звуковые и/или видеоданные
Большинство мультимодальных систем преобразования текста в звук RAG используют мультимодальный генеративный LLM для преобразования звука в текст. После создания пар звук-текст текст встраивается в векторы, и вы можете использовать RAG для извлечения текста обычным способом. На последнем этапе текст снова преобразуется в звук, чтобы завершить цикл "текст-звук" или наоборот.
Whisper от OpenAI может транскрибировать речь в текст.
Text-to-speech (TTS) от OpenAI также может преобразовывать текст в разговорный звук.
Мультимодальные системы Text-to-Video RAG используют аналогичный подход: сначала переводят видео в текст, встраивают текст, ищут по тексту и возвращают видео в качестве результатов поиска.
Sora от OpenAI может преобразовывать текст в видео. Как и в Dall-e, вы задаете текст, а LLM генерирует видео. Sora также может генерировать видео из неподвижных изображений или других видео.
Резюме
В этом блоге мы рассмотрели некоторые популярные модели встраивания, используемые в [RAG-приложениях] (https://zilliz.com/learn/Retrieval-Augmented-Generation).
Дополнительные ресурсы
Ссылки
Таблица лидеров МТЭБ, статья, Github: https://huggingface.co/spaces/mteb/leaderboard
Лучшие практики MTEB, чтобы избежать выбора модели с избыточной приспособленностью: https://huggingface.co/blog/lyon-nlp-group/mteb-leaderboard-best-practices
Поиск похожих изображений: https://milvus.io/docs/image_similarity_search.md
Поиск изображений к видео: https://milvus.io/docs/video_similarity_search.md
Звукоподражательный поиск: https://milvus.io/docs/audio_similarity_search.md
Поиск от текста к изображению: https://milvus.io/docs/text_image_search.md
2024 Статья SigLIP (sigmoid loss CLIP): https://arxiv.org/pdf/2401.06167v1
Карманные модели мультимодального встраивания от Unum: https://github.com/unum-cloud/uform

Читать далее

Why AI Databases Don't Need SQL
Whether you like it or not, here's the truth: SQL is destined for decline in the era of AI.

OpenAI o1: What Developers Need to Know
In this article, we will talk about the o1 series from a developer's perspective, exploring how these models can be implemented for sophisticated use cases.

Building RAG Pipelines for Real-Time Data with Cloudera and Milvus
explore how Cloudera can be integrated with Milvus to effectively implement some of the key functionalities of RAG pipelines.