




Compreender a Inteligência Artificial Multimodal
Compreender a Inteligência Artificial Multimodal
O lançamento do ChatGPT e de muitos outros modelos linguísticos de grande dimensão (LLMs) constituiu um marco crucial no desenvolvimento da IA. Durante este período, os modelos de IA passaram de aplicações de nicho para utilizações quotidianas como a escrita, a codificação, o serviço ao cliente e a criação de conteúdos. No entanto, muitos destes progressos limitaram-se a uma única modalidade: o texto.
A concentração numa única modalidade não é suficiente para alcançar a visão da inteligência artificial geral (AGI). Pela sua própria definição, a AGI exige a capacidade de compreender, raciocinar e agir em múltiplos domínios, desde a linguagem e a visão até à entrada auditiva e sensorial. Assim, nasceu a multimodalidade; este artigo irá guiá-lo através desta técnica.
O que é a IA multimodal?
Os sistemas de inteligência artificial são multimodais se processarem e analisarem informações de várias modalidades, como texto, imagens, áudio e vídeos. Por outro lado, a IA que só pode processar um tipo de modalidade é unimodal.
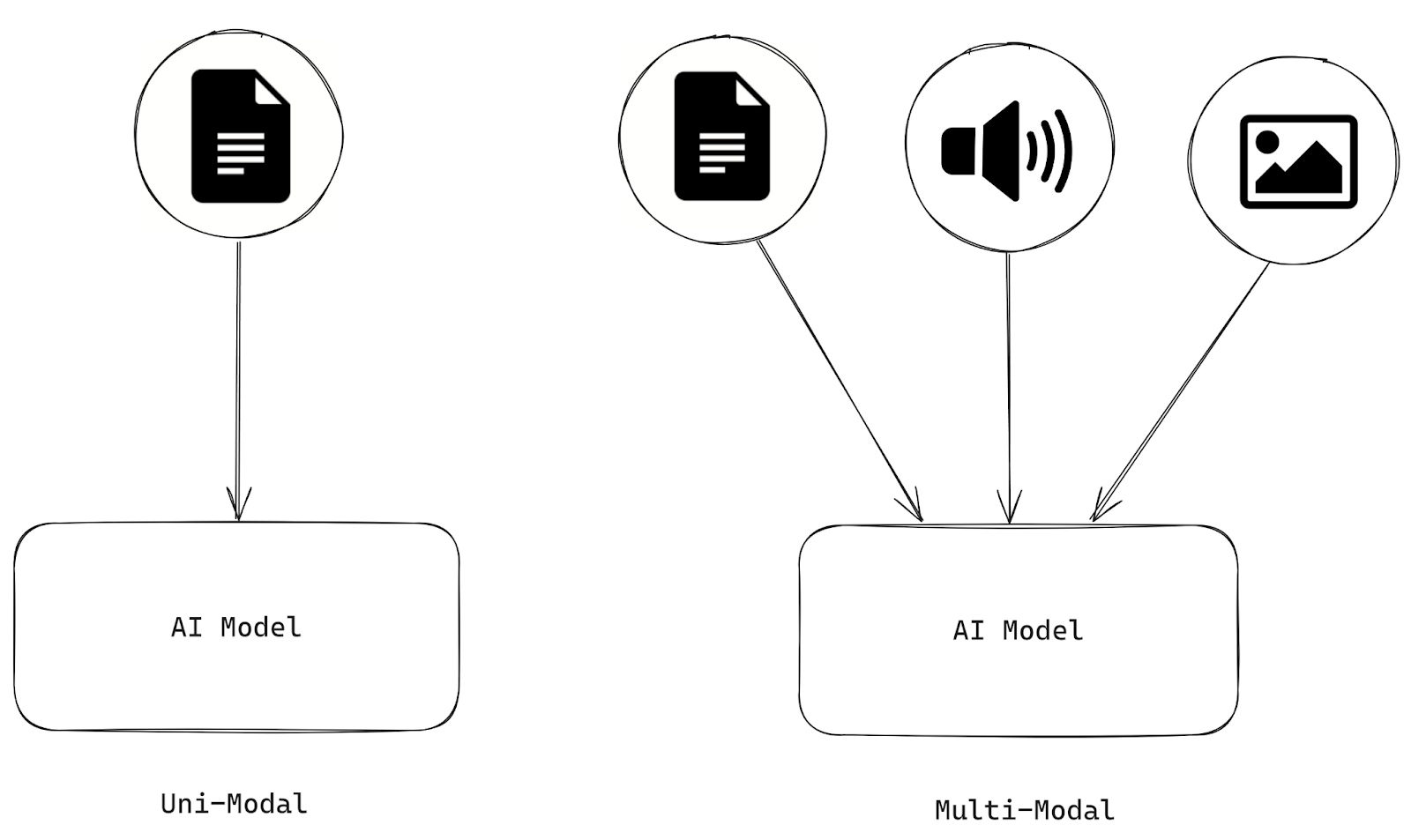 Figura 1- Diferenças entre IA uni e multimodal.png
Figura 1- Diferenças entre IA uni e multimodal.png
Figura 1: Diferenças entre IA uni e multimodal
É importante clarificar a distinção entre dois termos frequentemente confundidos: multimodal e multi-modelo. Multimodal refere-se a sistemas que integram e processam informações de vários tipos de dados. Em contrapartida, multimodelo descreve a utilização de vários modelos independentes que funcionam em paralelo ou em combinação para realizar uma tarefa. Estes modelos podem funcionar com o mesmo tipo de dados ou com tipos de dados diferentes, mas permanecem separados e não integrados.
A IA multimodal pode ter um impacto significativo em muitas aplicações. Por exemplo, um sistema de cuidados de saúde com IA multimodal pode utilizar imagens médicas, gravações de voz de pacientes e notas clínicas para elaborar um diagnóstico mais preciso do que o que poderia ser produzido por um sistema que dependesse apenas de uma fonte de dados. A este respeito, os sistemas de IA multimodal aproximam-se muito mais da cognição humana e são altamente eficazes em tarefas com uma necessidade crítica de compreensão global.
O multimodal pode ser um ou mais dos seguintes:
A entrada e a saída são efectuadas em modalidades diferentes, como texto-imagem ou imagem-texto.
As entradas são multimodais (por exemplo, texto e imagens).
As saídas são multimodais, como um sistema que fornece texto e imagens.
Na secção seguinte, discutiremos o funcionamento dos sistemas multimodais.
Como funciona a IA multimodal?
Vários componentes trabalham juntos em um modelo multimodal. Aqui estão os elementos mais importantes e seu funcionamento:
Tipos de dados: A IA multimodal integra vários tipos de dados, incluindo texto, imagens, áudio e vídeos, permitindo uma compreensão abrangente e a geração de conteúdos em diferentes modalidades.
Representação**: As representações multimodais na aprendizagem automática combinam dados de diferentes modalidades em caraterísticas mais significativas que os modelos podem utilizar. Para o conseguir, são utilizadas duas abordagens diferentes.
Representações conjuntas**: Os dados de diferentes modalidades são transformados num espaço de representação unificado, adequado quando estão disponíveis dados multimodais durante a formação e a inferência. Entre as técnicas normalizadas contam-se as [redes neuronais] (https://zilliz.com/learn/Neural-Networks-and-Embeddings-for-Language-Models) e os modelos gráficos probabilísticos. Embora estes métodos possam melhorar o desempenho, enfrentam desafios com dados em falta.
Representações coordenadas**: Cada modalidade é processada separadamente, com restrições impostas para as alinhar num espaço partilhado.
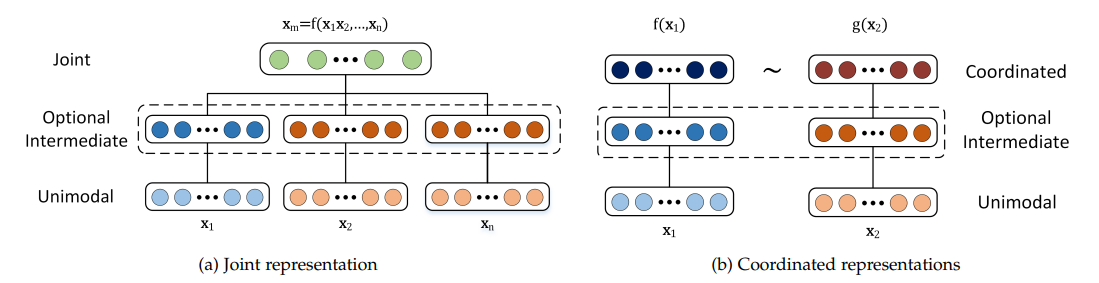 Figura 2- Estrutura das representações conjuntas e coordenadas.png
Figura 2- Estrutura das representações conjuntas e coordenadas.png
Figura 2: Estrutura das representações conjuntas e coordenadas | Fonte
Extração de caraterísticas: São utilizadas técnicas especializadas para extrair caraterísticas de cada tipo de dados, como o processamento de linguagem natural (PLN) para texto, a visão por computador para imagens e o processamento de sinais para áudio.
Fusão de dados**: A fusão combina informações de duas ou mais modalidades para uma tarefa de previsão. As abordagens são as seguintes:
Fusão inicial: Os dados são integrados antes da análise, normalmente num subespaço de baixa dimensão, utilizando métodos como a PCA (Análise de Componentes Principais) ou a ICA (Análise de Componentes Independentes). Esta abordagem requer a sincronização das modalidades, o que pode ser um desafio devido à variação dos formatos de dados e das taxas de amostragem. Embora seja eficiente para a extração de caraterísticas, pode levar à perda de dados e a problemas de sincronização.
Fusão tardia: Os resultados das modalidades individuais são combinados ao nível da decisão utilizando métodos de conjunto como bagging, boosting ou abordagens baseadas em regras (por exemplo, Bayes, max ou fusão média). Este método é excelente quando as modalidades não estão correlacionadas, oferecendo uma flexibilidade semelhante à cognição humana.
Modelação**: As redes neuronais capazes de processar múltiplas modalidades, como os transformadores ou as redes neuronais convolucionais (CNNs), são utilizadas para aprender com diversas entradas. Existem modelos mais sofisticados que apresentam resultados superiores e que são frequentemente designados por LMM (Large Multimodal Models).
Modelos multimodais populares e suas arquitecturas
Existem muitos modelos multimodais disponíveis no mercado. Seguem-se os modelos e arquitecturas mais populares.
Transformador de vídeo, áudio e texto (VATT)
O Video-Audio-Text Transformer (VATT) é uma arquitetura sem convolução projetada para lidar com múltiplas modalidades (vídeo, áudio e texto) usando uma estrutura unificada baseada em Transformer. O VATT começa por alimentar cada modalidade numa camada de tokenização, onde a entrada bruta é projectada num vetor de incorporação que um Transformer processa subsequentemente.
Existem duas configurações principais: uma em que são utilizados transformadores separados com pesos únicos para cada modalidade e outra em que uma única espinha dorsal do transformador com pesos partilhados trata todas as modalidades.
Independentemente da configuração, o Transformer extrai representações específicas de cada modalidade e mapeia-as para um espaço partilhado para tarefas posteriores. A arquitetura segue o pipeline padrão do Transformador, normalmente utilizado em NLP e Vision Transformers (ViT), utilizando tokens de entrada.
Além disso, o VATT incorpora uma tendência relativa aprendível para o texto, tornando-o compatível com modelos como o T5. Esta abordagem permite ao VATT modelar dados multimodais de forma eficaz para tarefas como a classificação.
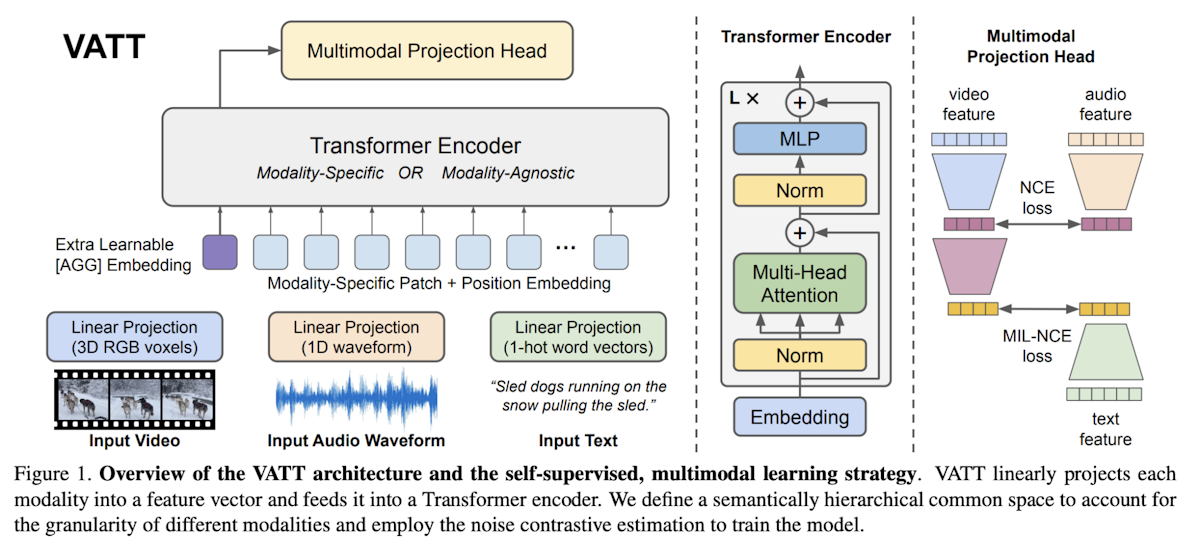 Figura 3- Transformadores de visão para aprendizagem multimodal.png
Figura 3- Transformadores de visão para aprendizagem multimodal.png
Figura 3: Transformadores de visão para aprendizagem multimodal | Fonte
Autoencoder Variacional Multimodal (MVAE)
A arquitetura do Multimodal Variational Autoencoder (MVAE) foi concebida para aprender uma representação unificada de texto e imagens. O MVAE tem três componentes principais: um codificador, um descodificador e um módulo de aplicação (neste caso, um detetor de notícias falsas).
 Figura 4- Arquitetura do Autoencoder Variacional Multimodal.png
Figura 4- Arquitetura do Autoencoder Variacional Multimodal.png
Figura 4: Arquitetura do Autoencoder Variacional Multimodal | Fonte
Encodificador: Este componente processa as entradas de texto e imagem para gerar uma representação latente partilhada. É composto por dois sub-codificadores:
Codificador de texto: Converte uma sequência de palavras de um post em palavras incorporadas utilizando uma rede profunda pré-treinada.
Codificador visual**: Este processo extrai caraterísticas visuais de imagens utilizando CNNs (como a VGG-19) para captar a semântica espacial e de objectos.
Descodificador: O descodificador reconstrói o texto e a imagem originais a partir da representação latente partilhada. Reflecte a estrutura do codificador e divide-se em:
Descodificador textual: Este descodificador reconstrói o texto passando a representação latente através de unidades bidireccionais LSTM e de uma camada totalmente ligada, prevendo a probabilidade de cada palavra.
Descodificador visual**: Inverte a codificação visual, reconstruindo as caraterísticas da imagem VGG-19 através de camadas totalmente conectadas.
Detetor de notícias falsas: Este componente prevê se uma notícia é real ou falsa utilizando a representação latente multimodal partilhada.
CLIP (Pré-treinamento Contrastivo de Linguagem-Imagem)
O modelo CLIP (Contrastive Language-Image Pretraining) foi concebido para aprender representações conjuntas de imagens e texto, treinando num vasto conjunto de dados de pares imagem-texto. O CLIP utiliza duas redes neuronais separadas: uma para imagens (frequentemente uma Vision Transformer ou uma CNN) e outra para texto (normalmente uma Transformer).
Estas redes codificam imagens e texto em vectores de comprimento fixo num espaço de incorporação partilhado. Durante o treino, o CLIP utiliza um objetivo de aprendizagem contrastiva, que junta as incrustações dos pares imagem-texto correspondentes e afasta as dos pares não correspondentes.
Através deste processo, o CLIP aprende a correlacionar informação visual e textual. Esta abordagem permite que o modelo efectue a classificação de imagens sem disparos, permitindo-lhe reconhecer objectos em imagens com base em descrições de linguagem natural sem necessitar de formação específica para a tarefa. Esta poderosa arquitetura pode ser utilizada em tarefas baseadas em imagens de texto para melhorar a capacidade de generalização.
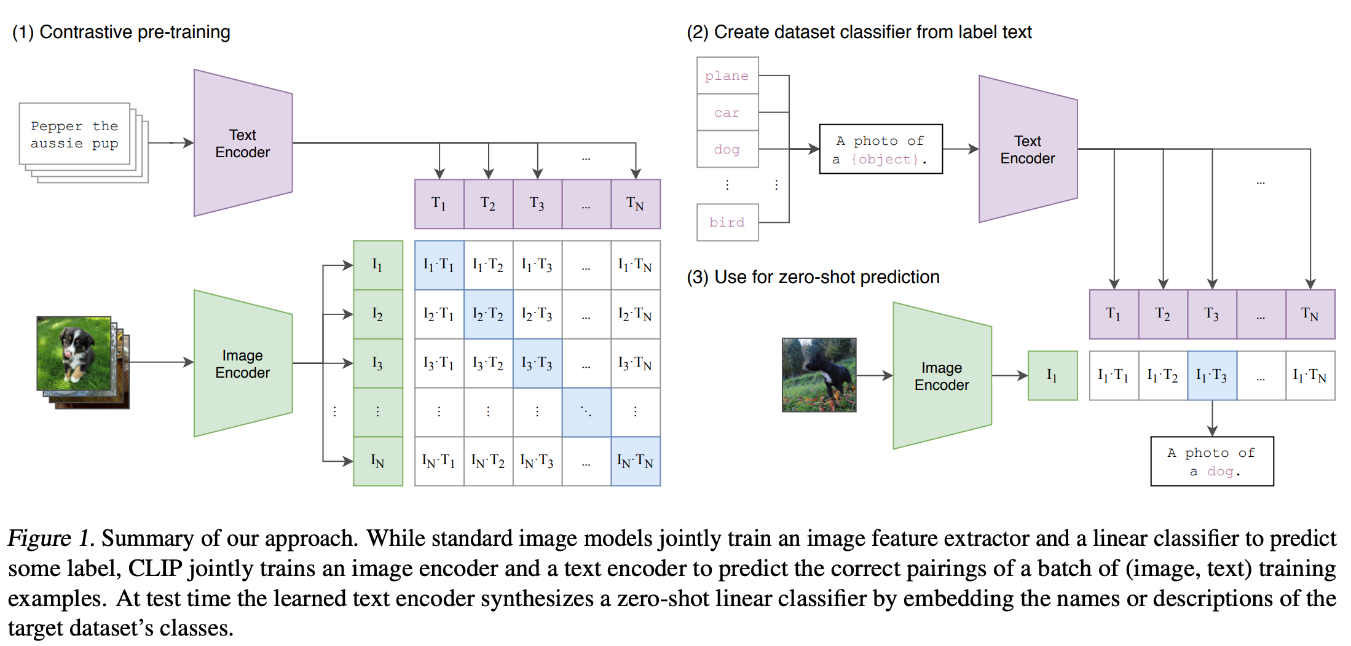 Figura 4- Arquitetura do modelo CLIP.png
Figura 4- Arquitetura do modelo CLIP.png
Figura 4: Arquitetura do modelo CLIP
Alguns modelos de código fechado destas arquitecturas incluem:
Google Gemini: Um LLM multimodal que se destaca em texto, imagens, vídeo e áudio, superando o GPT-4 em vários testes de referência.
ChatGPT (GPT-4V): Suporta texto, voz e imagens, permitindo aos utilizadores interagir com vozes geradas por IA e gerar imagens através do DALL-E 3.
IA do mundo interno**: Cria NPCs inteligentes para mundos digitais, permitindo a comunicação por meio de linguagem natural, voz e emoção.
Meta ImageBind: Processa seis modalidades, combinando dados para tarefas como criar imagens a partir de áudio e permitir que as máquinas percebam os seus ambientes.
Runway Gen-2**: Gera e edita vídeos a partir de texto, imagens ou vídeos existentes, oferecendo capacidades versáteis de criação de conteúdos.
Veja este post para mais [modelos multimodais] (https://zilliz.com/learn/top-10-best-multimodal-ai-models-you-should-know).
RAG multimodal: expandir para além do texto
Retrieval Augmented Generation (RAG))** é um método para recuperar informações contextuais para grandes modelos linguísticos a partir de fontes externas e gerar resultados mais precisos. Também ajuda a atenuar as AI hallucinations e a resolver alguns problemas de segurança dos dados. O RAG tradicional tem sido altamente eficaz na melhoria dos resultados do LLM, mas continua limitado a dados textuais. Em muitas aplicações do mundo real, o conhecimento vai para além do texto, incorporando imagens, gráficos e outras modalidades que fornecem um contexto crítico.
Abaixo está uma visão geral de um fluxo de trabalho típico de RAG baseado em texto:
O utilizador submete uma consulta de texto ao sistema.
A consulta é transformada num vetor embedding, que é depois utilizado para pesquisar uma base de dados vetorial , como o Milvus, onde as passagens de texto são armazenadas como embeddings. A base de dados de vectores recupera passagens que correspondem exatamente à consulta com base na semelhança de vectores.
As passagens de texto relevantes são passadas para o LLM como contexto suplementar, enriquecendo a sua compreensão da consulta.
O LLM processa a consulta juntamente com o contexto fornecido, gerando uma resposta mais informada e precisa.
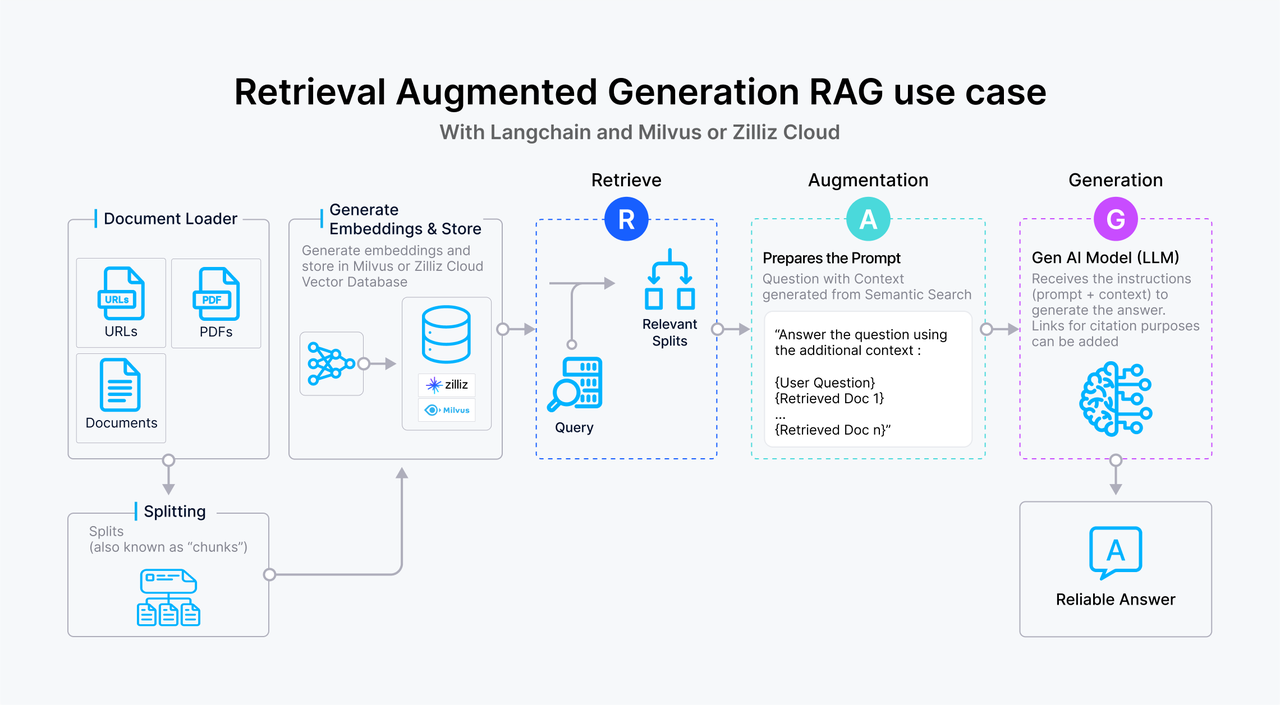 Figura 1- Como funciona o RAG.png
Figura 1- Como funciona o RAG.png
Figura: Como funciona o RAG
O RAG multimodal resolve a limitação acima referida, permitindo a utilização de diferentes tipos de dados, proporcionando um melhor contexto às MMN. Em termos simples, num sistema RAG multimodal, o componente de recuperação procura informações relevantes em diferentes modalidades de dados e o componente de geração gera resultados mais exactos com base nas informações recuperadas.
Para construir um sistema deste tipo, precisamos de utilizar modelos multimodais para gerar embeddings e LLMs com capacidades multimodais, tais como LLAVA, GPT4-V, Gemini 1.5, Claude 3.5 Sonnet, etc., para gerar respostas.
Há duas maneiras de implementar o RAG multimodal:
Utilizar um modelo de incorporação multimodal como o CLIP para transformar textos e imagens em incorporação. Em seguida, recupere o contexto relevante efectuando uma pesquisa de semelhança entre a consulta e as incrustações de texto/imagem. Finalmente, passar o texto bruto e/ou a imagem do contexto mais relevante para o nosso LLM multimodal.
Utilizar um LLM multimodal para produzir resumos de texto de imagens ou tabelas. De seguida, transforme esses resumos de texto em embeddings com um modelo de embedding baseado em texto. Depois, efectue uma pesquisa de semelhança de texto entre a consulta e os embeddings de resumo. Finalmente, passar a imagem bruta do resumo mais relevante para o nosso LLM para a geração de respostas.
Para saber mais detalhes sobre como criar uma aplicação RAG multimodal, consulte os nossos tutoriais utilizando as diferentes abordagens apresentadas abaixo:
[Construir um RAG multimodal com Gemini, BGE-M3, Milvus e LangChain] (https://zilliz.com/learn/build-multimodal-rag-gemini-bge-m3-milvus-langchain)
[Construir melhores pipelines RAG multimodais com FiftyOne, LlamaIndex e Milvus] (https://zilliz.com/blog/build-better-multimodal-rag-pipelines-with-fiftyone-llamaindex-and-milvus)
RAG multimodal: expandindo para além do texto para uma IA mais inteligente ](https://zilliz.com/blog/multimodal-rag-expanding-beyond-text-for-smarter-ai)
Comparação entre Unimodal e Multimodal
Os sistemas multimodais diferem dos sistemas tradicionais (unimodais) na forma como processam e integram simultaneamente dados de vários tipos de modalidades de entrada (por exemplo, texto, imagens e áudio).
Os sistemas multimodais têm uma vantagem na compreensão do contexto porque extraem informações de duas fontes: visão e linguagem. As abordagens tradicionais são mais simples e centram-se em domínios de aplicação específicos. O quadro seguinte ilustra algumas diferenças críticas entre os sistemas unimodais e multimodais.
| Aspeto | AI tradicional | AI multimodal | |
| Tipo de entrada** | Utiliza um único tipo de entrada (por exemplo, apenas texto, apenas imagem) | Processa vários tipos de entrada (por exemplo, texto, imagens, áudio) | |
| Foco de processamento** | Foca-se numa modalidade sensorial ou de dados | Integra e relaciona informação através de múltiplas modalidades | |
| Complexidade** | Mais simples e frequentemente específica de um domínio | É mais complexa devido à necessidade de integrar diversos tipos de dados | |
| Compreensão do contexto** | Limitada à informação disponível numa única modalidade | Pode compreender melhor o contexto utilizando diferentes modalidades | |
| Aplicações** | Classificação de texto, deteção de objectos, reconhecimento da fala, etc. | Interação Homem-Computador, Robótica, Veículos Autónomos, Realidade Aumentada, etc. |
Benefícios e desafios da IA multimodal
Esta secção enumera alguns benefícios críticos e desafios associados à criação e avaliação de sistemas multimodais.
Benefícios
Alguns dos benefícios da utilização da IA multimodal são listados abaixo:
Contexto melhorado: Os sistemas multimodais captam um contexto mais alargado através da integração de informações complementares de diferentes fontes, como a combinação de pistas visuais com linguagem para uma melhor interpretação.
Desempenho melhorado: Ao incorporar dados de várias modalidades, a IA multimodal pode fazer previsões e tomar decisões mais exactas. Por exemplo, um sistema de diagnóstico médico pode ser mais fiável se considerar as imagens e os registos médicos do paciente.
Versatilidade: A IA multimodal pode ser aplicada a várias tarefas complexas, incluindo a legendagem de imagens, a resposta a perguntas visuais, o diagnóstico médico, a condução autónoma, etc., o que a torna altamente adaptável a múltiplos domínios.
Compreensão mais semelhante à humana: A IA multimodal pode imitar melhor a cognição humana e permitir uma melhor interação homem-computador em aplicações em tempo real, processando dados de vários sentidos (modalidades).
Desafios
Alguns desafios associados à utilização da IA multimodal incluem:
Representação: O método ou formato em que as modalidades são representadas extrai a informação complementar ou redundante entre múltiplas modalidades. A representação de dados multimodais é muito importante mas difícil devido à sua natureza heterogénea. Por exemplo, o som é um sinal e a imagem é uma representação 3D com escalas e dimensões variáveis para representar. A forma de os colocar no mesmo espaço de representação comum é um ponto de implementação essencial.
Tradução: O procedimento pode explicar como converter ou transformar dados de uma modalidade para outra, uma vez que são heterogéneos. A relação entre diferentes modalidades é sobretudo subjectiva. Por exemplo, a tradução de um vídeo para a sua descrição textual correspondente.
Fusão: Refere-se à combinação de dados de várias modalidades para melhorar as previsões. Por exemplo, no reconhecimento audiovisual da fala, a descrição visual do movimento dos lábios é integrada com o sinal de fala para prever as palavras faladas. A informação pode provir de diferentes modalidades e tem vários níveis de força de previsão, importância, contribuição e topologia de ruído. Há valores de dados em falta em pelo menos uma das modalidades.
Explicabilidade: Um termo recente, Explainable AI (XAI), tem como objetivo explicar explicações e raciocínios significativos sobre um modelo. No caso de múltiplas modalidades, é mais difícil compreender como é que os modelos chegam a conclusões com diferentes fontes de dados.
FAQs da IA Multimodal
- **O que é a IA multimodal?
A IA multimodal é um tipo de sistema de inteligência artificial que pode processar e analisar informações de várias modalidades, incluindo texto, imagens, áudio e vídeo.
- **Que tipos de dados podem ser utilizados pela IA multimodal?
A IA multimodal utiliza vários tipos de dados, incluindo texto, imagens, áudio, vídeo, sensores e dados gráficos.
- **A IA multimodal está a substituir a IA tradicional?
A IA multimodal não está a substituir a IA tradicional, mas a expandir as suas capacidades através da integração de múltiplas modalidades de dados. Trata-se de uma extensão. Os métodos tradicionais continuam a ser essenciais, enquanto a IA multimodal fornece capacidades adicionais.
- **Quais são algumas das aplicações típicas da IA multimodal?
As aplicações típicas da IA multimodal incluem a legendagem de imagens, a resposta a perguntas visuais, o reconhecimento de emoções e a condução autónoma.
- **Quais são as vantagens da IA multimodal?
A IA multimodal tem várias vantagens, incluindo a robustez, a eficiência, a consciência do contexto, um domínio de aplicação diversificado e uma melhor interação homem-computador.
Recursos relacionados
O que é uma base de dados vetorial e como funciona?](https://zilliz.com/learn/what-is-vetor-database)
Descodificação de modelos de transformadores: Um estudo da sua arquitetura e princípios subjacentes
Construir aplicações de IA com Milvus: tutoriais e cadernos de notas
Modelos de IA com melhor desempenho para as suas aplicações GenAI | Zilliz
- O que é a IA multimodal?
- Como funciona a IA multimodal?
- Modelos multimodais populares e suas arquitecturas
- RAG multimodal: expandir para além do texto
- Comparação entre Unimodal e Multimodal
- Benefícios e desafios da IA multimodal
- FAQs da IA Multimodal
- Recursos relacionados
Conteúdo
Comece grátis, escale facilmente
Experimente o banco de dados totalmente gerenciado, construído para seus aplicativos GenAI.
Experimente o Zilliz Cloud grátis