




Vector Lakebase: AIデータサイロに終止符を
すべての AI チームが同じ壁にぶつかる — データ重力
現代のデータチームはどれも、同じようなアーキテクチャの何らかのバージョンを構築してきました。中心にあるのはレイクハウスです — S3 上の Iceberg テーブル、Spark パイプライン、そしてガバナンスのための Delta Lake。これはうまく機能します。そこに AI の要件がやって来ます。
RAG パイプラインは、10 年分のエンタープライズ文書に対する質問に答える必要があるため、すべてをベクトルデータベースにコピーします。AI エージェントには、製品カタログの埋め込みへの低レイテンシアクセスが必要です — また別のパイプライン、また別の同期ジョブ。マルチモーダルモデルのトレーニングでは、10 億件の画像埋め込みに対して日次の重複排除が必要です — インデックスを見ることのできない Spark ジョブです。
6 か月後、2 つだったシステムは 5 つになっています。データエンジニアリングチームは、AI 機能を構築するよりも、同期パイプラインの保守に多くの時間を費やしています。同じデータセットのコピーが 3 つあり、それらが一致している保証はありません。スキーマ変更のたびに、4 つの異なる場所へ影響が波及します。
これは実行の失敗ではありません。アーキテクチャの失敗です — 具体的には、データの根本的な性質である 重力 と戦い続けるアーキテクチャの失敗です。先にデータをコピーすることを要求するすべてのシステムは、あなたに重力税を課しています。追加する AI ワークロードが増えるほど — RAG パイプライン、エージェントメモリ、モデルトレーニング、リアルタイムレコメンデーション — その税は高くなります。
正しい解決策は、より優れたパイプラインではありません。それは新しいアーキテクチャパラダイムであるべきです: Vector Lakebase。
3 世代のアーキテクチャ解決策、2 つの行き止まり
Vector Lakebase の詳細に入る前に、ベクトル検索アーキテクチャがデータ重力の問題に対処するためにどのように進化してきたかを見ておく価値があります。大きく分けて、3 世代の解決策がありました。
第 1 世代: 専用ベクトルデータベース
Milvus のような専用ベクトルデータベースは、本番 AI システムにおける現実の問題を解決しました。汎用データベースでは実現できない再現率と性能を備えた、ミリ秒レイテンシのセマンティック検索です。オープンソースの Milvus ベクトルデータベースの開発者として、Zilliz は長年にわたり、埋め込みの保存、インデックスの構築、そして RAG、エージェント、レコメンデーションシステム、セマンティック検索、マルチモーダルアプリケーション向けの低レイテンシ検索を提供する、信頼性が高く高性能なシステムの構築に注力してきました。その基盤は今でも重要です。本番 AI システムには依然としてデータベース速度の検索が必要であり、ベクトルデータベースは多くのレイテンシに敏感なワークロードにとって適切なサービングレイヤーであり続けています。
しかし、AI ワークロードが成熟するにつれ、課題はオンラインサービングを超えて広がっていきます。組織のソースデータの多くは、すでにオブジェクトストレージ、データレイク、レイクハウス、下流の分析システムに存在しています。そのデータを専用ベクトルデータベースで使用するために、チームは通常、それを別個のサービングシステムにコピーし、取り込みパイプラインを構築し、同期ジョブを維持し、ソースデータとベクトルインデックス間の整合性を管理します。埋め込みモデルが変更されると(そしてそれは必然的に起こります)、チームは埋め込みを再生成し、インデックスを再構築し、複数のシステムを整合させ続ける必要があります。
これはベクトルデータベースの性能の限界ではありません。データ移動によって生じるアーキテクチャ上の境界です。同じデータを本番検索、埋め込み実験、オフライン評価、ガバナンス、リネージ、分析に使いたいと考えるチームが増えるほど、運用上の対象範囲は広がります。専用ベクトルデータベースはオンライン検索の問題を非常にうまく解決しましたが、それ単体ではデータ重力の問題を排除できません。
第 2 世代: Vector Lake
次に自然に生まれた対応は、ベクトル検索をレイクに近づけることでした。つまり、専用のサービングシステムへ先に移動することなく、Iceberg、Delta Lake、または Parquet ファイルから直接ベクトルをクエリするというものです。その動機は正しいものでした。データがすでにオブジェクトストレージやレイクハウスに存在しているなら、検索可能にするためだけに、なぜそれをどこか別の場所へ複製する必要があるのでしょうか?
しかし実際には、ベクターレイク・アーキテクチャは、本番環境のAIワークロードに対して3つの理由で依然として不完全です。
第一に、低レイテンシのサービング向けに設計されていません。 ほとんどのベクターレイクのアプローチは、必要に応じてオブジェクトストレージからデータやインデックスを読み込み、同時実行性が高くレイテンシに敏感なリクエスト処理よりも柔軟性に最適化されています。これはオフラインでの探索には許容できるかもしれませんが、ユーザー向けのRAG、エージェント、レコメンデーション、検索アプリケーションには不十分です。検索パイプラインがLLM呼び出しのクリティカルパス上にある場合、チームには高い同時実行性のもとで予測可能な100ms未満のレイテンシが必要です。p99レイテンシが頻繁に秒単位にまでずれ込むのであれば、そのシステムは分析にはまだ有用かもしれませんが、本番の検索レイヤーとして機能することはできません。
第二に、ベクターレイク・システムは通常、検索段階で止まります。 チームがレイク内のベクターデータをクエリできるようにはしますが、AIデータワークフローのためのより広範な実行環境は提供しません。現代のAIシステムに必要なのは最近傍検索だけではありません。埋め込みの再生成、検索品質の評価、エージェントメモリの圧縮、動画からのフレーム抽出、マルチモーダルデータの処理、メタデータの管理、ファインチューニングや下流パイプライン向けのデータ準備が必要です。レイクファイルの上に検索だけを追加するシステムでは、ベクターおよびマルチモーダルデータのライフサイクル全体には対応できません。
第三に、基盤となるストレージレイヤーがこのワークロード向けに構築されていません。 IcebergとDelta Lakeは構造化された分析データ向けに設計されました — ネイティブのベクター型も、インデックス構造もなく、すべてのクエリはフルスキャンです。AIワークロードには、高速なポイントルックアップ(Parquetの逐次的な行グループスキャンではありません — VortexやLanceのようなフォーマットはこの理由で存在します)、データと共同管理される組み込みインデックス、そして画像、音声、動画をblobとしてインライン化するのではなく参照によってリンクする、参照ベースの非構造化データ管理が必要です。これらはいずれも現在のレイクには存在しません。Iceberg上に構築されたVector Lakeは、あらゆるレベルでストレージレイヤーと格闘しているのです。
第3世代: Vector Lakebase
Vector Lakebaseとは、レイクとベクターデータベースを同期が必要な別々のシステムとして扱うのをやめ、単一の統合レイヤーの2つの動作モードとして構築し始めたときに得られるものです。より具体的には、次のようになります。
ベクターレイクベースは、ベクターデータベースシステムから進化した、新しいAIネイティブかつレイクネイティブなアーキテクチャです。ベクターデータベースの高QPS・低レイテンシのサービング能力と、マルチモーダルデータレイクのオープン性、スケーラビリティ、コスト効率を組み合わせる一方で、データ移行なしにすべてのワークロードを同じ信頼できる唯一の情報源上に維持します。コンピュートをストレージから分離することで、ベクターレイクベースはオープンフォーマットを使用して、マルチモーダルデータ、ベクター、属性、インデックス、メタデータを低コストのオブジェクトストレージに直接保存します。その後、サービング、ディスカバリー、分析のワークロードは、同じデータの上で独立して実行できます。
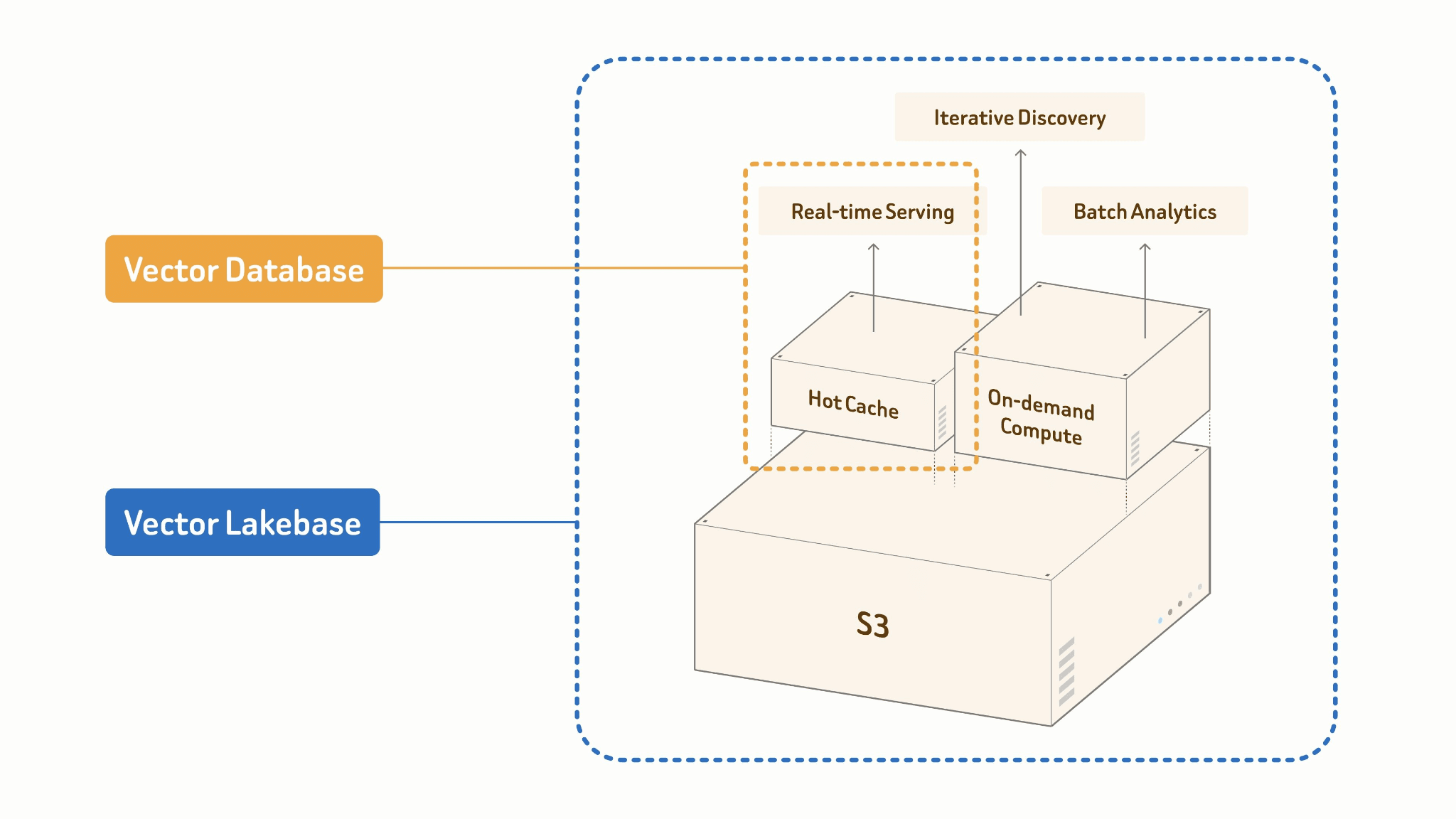
中核となる原則: One Source of Truth。
あなたのレイクテーブルが単一の信頼できる情報源です。オンラインサービングとオフラインバッチ処理は、同じデータ、インデックス、スキーマを共有します。両者の間にパイプラインはありません。なぜなら、両者の間に境界がないからです。
Vector DB: [Lake] ──ETL──▶ [Vector DB] # duplication + staleness
Vector Lake: [Lake + Index] ◀── batch query only # no serving, no processing
Vector Lakebase: [Lake + Index + Compute]
├── Online: Cache + High-performance Index
│ → ANN query, <100ms p99 serving
└── Offline: Batch Processing + Cost-efficient Index Build
→ embed, cluster, dedup, feature engineering
2つのモードは、必然的に異なる設計になっています。オンラインサービングは、ホットキャッシュと高性能なインメモリインデックスに対して実行されます — 同時実行性とテールレイテンシに最適化されています。オフラインバッチジョブは、カラムナスキャン、GPUアクセラレーションによる構築、レイクへの段階的な書き戻しによって、大規模にコスト効率よくインデックスを構築します。同じデータ、同じインデックス形式でありながら、コンピュートプロファイルは根本的に異なります。
実際にはどのように見えるのでしょうか?10億ベクトルの Iceberg テーブルでは次のようになります。
| モード | レイテンシ | コンテキスト |
|---|---|---|
| Spark ブルートフォーススキャン(インデックスなし) | 数時間 | レイクベースのベクトル検索における現在のデフォルト |
| Vector Lakebase — コールド(インデックス構築直後) | 約30秒 | Iceberg からのインデックス構築は約20分 |
| Vector Lakebase — ウォーム(ディスクキャッシュ) | 2桁ミリ秒 | インデックスはローカル SSD にキャッシュ |
| Vector Lakebase — ホット(インメモリ) | 1桁ミリ秒 | 本番環境の RAG とエージェントサービング |
| Vector Lakebase — クラスタリング / 重複排除 | 数時間 | 10億ベクトルの KMeans または近重複検出、完全分散 |
数時間 から 1桁ミリ秒 へ短縮できます — しかも、データをレイクの外へコピーすることはありません。
これは製品選択の問題ではありません。AIデータアーキテクチャが収束しつつある方向性です。データが2か所に存在することを要求するシステムは、ストレージ、エンジニアリング時間、鮮度の面で恒久的な税金を課します。ストレージとAIオペレーションを分離するシステムは、後から振り返れば過渡的なものに見えるでしょう。
Vector Lakebase が実際に可能にすること
以前は別々のシステムを必要としていた少なくとも3種類のワークロードを、今では vector lakebase で扱えるようになります。
外部コレクション:何も移動せずにレイクを検索可能にする
S3 上の Parquet ファイルにペタバイト規模の埋め込みがあります。今日、新しい RAG アプリケーションのためにそれらを検索可能にするには、ベクトルデータベースへロードする必要があります — 数日から数週間単位の移行に加え、継続的な同期義務が伴います。
Vector Lakebase の external collections は、データの重力に逆らうのではなく、それを活かします。バケットを指定し、既存のカラムに対するスキーママッピングを定義し、その場でベクトルインデックスを構築します。データは S3 に留まります。インデックスは S3 に永続化されます。ソースデータが更新されたら、差分更新します — 変更されたファイルだけが再処理されます。
# 1. Register your existing lake data as an external collection
client.create_external_collection(
collection_name="enterprise_docs",
src="s3://my-lake/docs/*.parquet", # point at your existing data
schema={"text": String, "embedding": FloatVector(768)},
)
# 2. Build a vector index — data stays in S3, index persists back to S3
client.create_index("enterprise_docs", field="embedding", index_type="HNSW")
# ~20 min for 1B vectors. Data never moves.
# 3. Search — single-digit ms with in-memory cache
results = client.search(
collection_name="enterprise_docs",
data=[query_embedding],
top_k=10,
output_fields=["text"],
)
移行なし、パイプラインなし、新たなストレージコストなし。あなたの RAG システムは、分析チームがすでに管理している同じデータをクエリします — Spark、Ray、LangChain、PyMilvus、または REST API を通じて。インデックスは、横に取り付けられた外部システムではなく、テーブルの第一級のプロパティになります。
ETL、特徴量エンジニアリング、コンテキストエンジニアリング
これは Vector Database と Vector Lake のどちらも無視しているワークロードです — そして、AIデータスタックの中で最も重要な部分になりつつあります。
AIネイティブなデータ操作は、単にシステム間でデータを移動するだけではありません — その場で、大規模に、意味的な意味でデータを強化します。
- 既存のテーブルに埋め込み列を追加する:1億行に対してバッチ推論を行い、結果を同じテーブルに書き戻す。
- RAG のためにドキュメントコーパスをチャンク化し、生ドキュメントとチャンクを一緒にバージョン管理する。
- text-embedding-3-small から新しいモデルへアップグレードする — 5億ベクトルすべてをその場でバックフィルし、切り替えまで古い埋め込みと新しい埋め込みを共存させる。
- AI エージェントが実行時に取得するコンテキストパッケージを構築し、バージョン管理する — 何が取得されるのか、どのように構造化されるのか、コンテキストウィンドウ向けにどのように圧縮されるのか。
モデルがコモディティ化するにつれて、どのモデルを選ぶかよりも、モデルに何を与えるかの品質がより重要になります。この新たな分野 — コンテキストエンジニアリング — はレイクに属します:データの近くにあり、データと並んでバージョン管理され、エンドツーエンドで再現可能であるべきです。Vector Lakebase はそれを、cron ジョブでつなぎ合わせたアドホックスクリプトではなく、第一級の操作にします。
クラスタリング、重複排除、異常検出
自社モデルのトレーニングやファインチューニングを行うすべてのチームに不可欠でありながら、ベクトルデータベースのパラダイムには完全に欠けているものです:
- 重複排除:LLM ファインチューニングデータセット内の近重複例は、トレーニング損失を膨らませ、モデルの挙動にバイアスをかけます。近重複を特定し、正規セットを出力し、重複排除ラベルを列として書き戻します。
- クラスタリング:トレーニング前に、データセットに実際に何が含まれているのかを理解します。埋め込み空間をクラスタリングすると、「多様な」データセットの40%が、同じ少数のトピックのわずかなバリエーションであることがよくあります。
- 異常検出:自動運転車、ロボティクス、または安全性が重要なあらゆるモデルにおいて — 他とまったく似ていない0.1%のサンプルを見つけます。それらにフラグを立て、ラベリングの優先度を上げ、トレーニングに含めます。インデックスなしでは見つけられず、結果をレイクに書き戻さなければ行動に移せません。
Vector Lakebase はこれらを第一級の分散操作として扱います:インデックスを意識し、データが存在する場所全体で並列化し、オープンフォーマットで結果を書き込みます。重複排除実行の出力は、同じテーブル内の列になります。
すでにこれを基盤に構築している企業
Vector Lakebase の最初期のデザインパートナーは、スケールにおいて最も難しい AI データ問題のうち2つにまたがっています。
大手自動運転および EV 企業は、数十億の運転シーン埋め込みからコーナーケースをマイニングするためにこれを使用しています — 自動運転システムが安全かどうかを左右する、まれな道路シナリオです。トップクラスの基盤モデル企業は、事前学習コーパス全体での近重複検出にこれを使用しています — トレーニングに1 GPU 時間も費やす前に、数十億の例を重複排除してモデル品質を改善します。
すでに Databricks Lakebase があります。もう1つ必要ですか?
それはもっともな質問であり、答えるには Databricks Lakebase が実際に何であるかを理解する必要があります。
Databricks Lakebase — Neon の買収を基に構築 — は、サーバーレス PostgreSQL エンジンを Databricks プラットフォームに統合します。これが解決する問題は、OLTP と OLAP が常に別々のシステムだったことです。Databricks はその境界を崩そうとしています。それは解決する価値のある本物の問題です。しかし、根本的に別の問題です。
| Databricks Lakebase | Vector Lakebase | |
|---|---|---|
| 主なユーザー | バックエンドエンジニア、データエンジニア | ML エンジニア、AI プラットフォームチーム |
| 主なデータ | 行、アカウント、トランザクション | 埋め込み、ドキュメント、マルチモーダル |
| ストレージモデル | Postgres ストレージ + Delta Lake(別々) | 単一のレイクテーブル、統合 |
| バッチ埋め込み / 重複排除 | 対象外 | 第一級の操作 |
| コンテキストエンジニアリング | 対象外 | 中核機能 |
| 既存のレイク上に構築 | 部分的 | はい — 移行ゼロ |
| フォーマット最適化 | Delta Lake, Parquet | Parquet, Vortex, Lance, Apache Iceberg, ネイティブな非構造化データ |
| OLTP(トランザクション) | ✓ | N/A |
Databricks Lakebase は OLTP/OLAP の境界を崩します。Vector Lakebase は、AI データが存在する場所と AI 操作が実行される場所の間の境界を崩します。これらは競合ではなく補完的です。多くのチームは両方を使うことになるでしょう。
アーキテクチャ上の賭け
2013年、Databricksは問いかけました。もしSQL分析がレイクに存在したら? その問いには400億ドルの価値がありました。
次の問いはこうです。もしAIネイティブなデータオペレーション — RAG検索、エージェントメモリ、バッチ埋め込み、モデル学習データのキュレーション、コンテキストエンジニアリング — もレイクに存在したら?
それがVector Lakebaseの背後にある賭けです。移行先となる新しいデータベースではありません。既存のレイクに後付けされたクエリレイヤーでもありません。データが一度だけ存在し、一度だけインデックス化され、あらゆるAIワークロードに対応する統合基盤です — 重複なし、ETLのオーバーヘッドなし、重力に逆らうことなしに。
AI競争ではスピードが報われます。チームが同期パイプラインの構築、古いデータのデバッグ、システム間の移行に費やす毎週は、競合がAI機能を出荷するために使う一週間です。インフラはボトルネックではなく、アクセラレーターであるべきです。勝つチームは最高のモデルを持つチームではありません — データとAIの間の摩擦を取り除いたチームです。
既存のIcebergテーブルまたはデータレイク上に構築。移行なし。重複なし。高速に進める — データはその場に留まり、数分で検索可能、処理可能、AI対応になります。
それがVector Lakebaseです。
Zilliz Vector Lakebaseがパブリックプレビューで利用可能に
私たちはZilliz Vector Lakebaseのパブリックプレビューを開始しました — これはZilliz Cloudを、マネージドベクトルデータベースから統合セマンティックデータプラットフォームへと進化させる大きな一歩であり、低レイテンシのベクトルサービングと、データレイクのオープン性、スケーラビリティ、経済性を組み合わせています。
Zilliz Vector Lakebaseのコア機能:
- さまざまなリアルタイムの性能・コストのトレードオフに最適化された階層型サービング
- 常時稼働のコンピュートなしで、大規模または探索的ワークロードに対応するオンデマンド検索
- 外部データレイク検索 — 既存のレイクデータ上で直接インデックス作成と検索
- ハイブリッド検索とリランキングにより、ベクトル、テキスト、JSON、地理空間データにまたがるフルスペクトラム検索
- Vortex上に構築された統合レイクネイティブストレージ。LanceやParquetよりも高速かつ低コストなランダム読み取りを実現するオープンフォーマット
現在のスタックがサービングとディスカバリーを別々のシステムに分けているなら、Vector Lakebaseは検討する価値があるかもしれません。Zilliz Cloudでお試しください — 新規の仕事用メールでのサインアップには$100分の無料クレジットが付与されます — または、ユースケースについてご相談ください。

読み続けて

Why We Built Vector Lakebase: Rethinking Unstructured Data Architecture for AI
Vector Lakebase: a unified, lake-native data foundation for AI workloads — and an answer to what happens after vector databases succeed.

Announcing VDBBench 1.0: Open-Source VectorDB Benchmarking with Your Real-World Production Workloads
Discover VDBBench 1.0, an open-source tool for benchmarking vector databases with real-world production data, streaming ingestion, and concurrent workloads.

The Great AI Agent Protocol Race: Function Calling vs. MCP vs. A2A
Compare Function Calling, MCP, and A2A protocols for AI agents. Learn which standard best fits your development needs and future-proof your applications.