




IVFインデックスのパラメーター選択方法
Milvus設定のベストプラクティス](https://medium.com/@milvusio/best-practices-for-milvus-configuration-f38f1e922418)では、Milvus 0.6.0設定のベストプラクティスを紹介しました。今回は、テーブルの作成、インデックスの作成、検索などの操作において、Milvusクライアントで主要なパラメータを設定する際のベストプラクティスも紹介します。これらのパラメータは検索パフォーマンスに影響を与えます。
1.index_file_size.
テーブルを作成する際に、index_file_sizeパラメータを使用して、データ格納用の単一ファイルのサイズをMB単位で指定します。デフォルトは1024です。ベクトルデータをインポートする場合、Milvusはデータをインクリメンタルにファイルに結合します。ファイルサイズがindex_file_sizeに達すると、このファイルは新しいデータを受け付けず、Milvusは新しいデータを別のファイルに保存します。これらはすべて生データファイルである。インデックスが作成されると、Milvusは各rawデータファイルに対してインデックスファイルを生成します。IVFLATインデックスタイプの場合、インデックスファイルのサイズは対応する生データファイルのサイズにほぼ等しくなります。SQ8インデックスでは、インデックスファイルのサイズは対応する生データファイルの約30%である。
検索中、Milvusは各インデックスファイルを1つずつ検索します。我々の経験では、index_file_sizeを1024から2048に変更すると、検索性能は30%から50%向上する。しかし、この値が大きすぎると、大きなファイルをGPUメモリ(あるいはCPUメモリ)にロードできないことがあります。たとえば、GPU メモリが 2 GB で index_file_size が 3 GB の場合、インデックス・ファイルは GPU メモリにロードできません。通常、index_file_size を 1024 MB または 2048 MB に設定します。
次の表は、index_file_size に sift50m を使用したテストです。インデックス・タイプは SQ8 です。
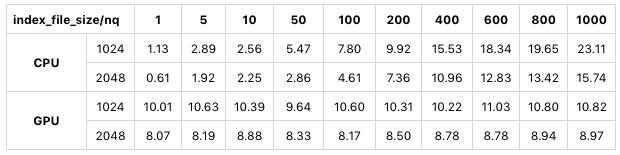 1-sift50m-test-results-milvus.
1-sift50m-test-results-milvus.
CPUモードでもGPUモードでも、index_file_sizeが1024 MBの代わりに2048 MBになると、検索パフォーマンスが大幅に向上することがわかります。
2.nlist ** and** nprobe
nlistパラメータはインデックス作成に使用され、nprobeパラメータは検索に使用されます。IVFLATとSQ8はどちらもクラスタリングアルゴリズムを使用して、多数のベクトルをクラスタ(バケット)に分割します。nlistはクラスタリング中のバケットの数です。
インデックスを使って検索する場合、最初のステップはターゲットベクトルに最も近いバケットを一定数見つけることであり、2番目のステップはバケットからベクトル距離によって最も類似したk個のベクトルを見つけることです。nprobe<//code>はステップ1でのバケット数です。
一般に、nlistを増加させると、バケット数が多くなり、クラスタリング中のバケット内のベクトル数が少なくなる。その結果、計算負荷が減少し、検索性能が向上する。しかし、類似度比較のためのベクトルが少なくなると、正しい結果が見落とされる可能性があります。
nprobeを増やすと、検索するバケットが増えます。その結果、計算負荷は増加し、検索性能は悪化するが、検索精度は向上する。この状況は、分布の異なるデータセットごとに異なるかもしれません。nlistとnprobeを設定する際には、データセットのサイズも考慮すべきである。一般に、nlistは4 * sqrt(n) とすることが推奨される。nprobeについては、精度と効率のトレードオフをしなければならず、試行錯誤しながら値を決めるのが最良の方法である。
以下の表は、nlistとnprobeに対してsift50mを使用したテストである。インデックス・タイプはSQ8である。
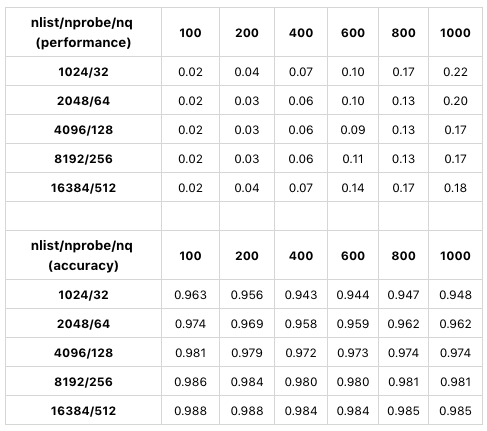 sq8-index-test-sift50m.
sq8-index-test-sift50m.
この表は、nlist/nprobeの異なる値を使用して検索パフォーマンスと精度を比較したものです。CPUとGPUのテストは同じような結果になるため、GPUの結果のみを表示しています。このテストでは、nlist/nprobe<//code>の値が同じ割合で増加すると、検索精度も増加します。nlist = 4096、nprobeが128のとき、Milvusは最高の検索性能を持つ。結論として、nlistとnprobeの値を決定する場合、異なるデータセットと要求を考慮して性能と精度のトレードオフを行う必要がある。
まとめ
index_file_size:データサイズがindex_file_sizeより大きい場合、index_file_sizeの値が大きいほど検索性能は向上する。
nlistとnprobe:性能と精度はトレードオフの関係にある。
読み続けて

A Developer's Guide to Exploring Milvus 2.6 Features on Zilliz Cloud
Milvus 2.6 marks a shift from “vector search + glue code” to a more advanced retrieval engine, and it is now Generally Available (GA) on Zilliz Cloud (a managed Milvus service).

Milvus 2.6.x Now Generally Available on Zilliz Cloud, Making Vector Search Faster, Smarter, and More Cost-Efficient for Production AI
Milvus 2.6.x is now GA on Zilliz Cloud, delivering faster vector search, smarter hybrid queries, and lower costs for production RAG and AI applications.

Announcing the General Availability of Zilliz Cloud BYOC on Google Cloud Platform
Zilliz Cloud BYOC on GCP offers enterprise vector search with full data sovereignty and seamless integration.