




音楽推薦システムのための項目ベースの協調フィルタリング
Wanyin AppはAIベースの音楽共有コミュニティで、音楽愛好家の音楽共有を促進し、作曲を容易にすることを意図している。
Wanyinのライブラリには、ユーザーによってアップロードされた大量の音楽が含まれている。主なタスクは、ユーザーの過去の行動に基づいて興味のある音楽を選別することである。我々は2つの古典的なモデルを評価した:ユーザーベースの協調フィルタリング(User-based CF)とアイテムベースの協調フィルタリング(Item-based CF)。
- ユーザベース協調フィルタリングは、類似度統計量を用いて、類似した嗜好や興味を持つ近隣ユーザを検索する。取得された近傍ユーザーの集合により、システムはターゲットユーザーの興味を予測し、レコメンデーションを生成することができる。
- Amazonによって導入されたアイテムベースCF(I2I)は、推薦システムのための協調フィルタリングモデルとしてよく知られている。興味のあるアイテムは、スコアの高いアイテムと類似していなければならないという仮定に基づき、ユーザーの代わりにアイテム間の類似度を計算する。
ユーザベースのCFは、ユーザ数が一定以上になると、計算時間が法外に長くなる可能性がある。このような製品の特性を考慮し、I2I CFを採用することにしました。楽曲に関するメタデータをあまり持っていないため、楽曲そのものを扱い、楽曲から特徴ベクトル(エンベッディング)を抽出する必要があります。私たちのアプローチは、これらの楽曲をMFC(mel-frequency cepstrum)に変換し、楽曲の特徴埋め込みを抽出するために畳み込みニューラルネットワーク(CNN)を設計し、埋め込み類似度検索によって音楽推薦を行うことである。
埋め込み類似度検索エンジンの選択
特徴ベクトルが得られたところで、残る課題は、大量のベクトルの中から、目的のベクトルと類似したベクトルをどのように取り出すかである。埋め込み類似度検索エンジンは、FaissとMilvusで迷いました。Milvusに気づいたのは、2019年11月にGitHubのトレンドリポジトリを見ていたときです。プロジェクトを見てみると、その抽象的なAPIに魅力を感じました。(当時はv0.5.x、現在はv0.10.2)。
私たちはFaissよりもMilvusを気に入っています。一方では、Faissを使ったことがあるので、新しいものを試したいと思っています。一方、Milvusと比べると、Faissはより基礎的なライブラリであるため、使い勝手があまりよくない。Milvusについて学ぶにつれ、私たちは最終的にMilvusを採用することを決めた:
- Milvusは非常に使いやすい。Milvusは非常に使いやすい。Dockerイメージを引っ張ってきて、自分のシナリオに基づいてパラメータを更新するだけでいい。
- より多くのインデックスをサポートし、詳細なサポートドキュメントがある。
一言で言えば、Milvusはユーザーにとって非常に使いやすく、ドキュメントも非常に詳しい。もし何か問題に出くわしたとしても、大抵はドキュメントで解決策を見つけることができる。
Milvus クラスタサービス ☸️
機能ベクトル検索エンジンとしてMilvusを使用することを決定した後、開発(DEV)環境にスタンドアロンノードを設定しました。このノードは数日間順調に稼動していたので、工場受入テスト(FAT)環境でテストを実行することを計画した。本番環境でスタンドアロン・ノードがクラッシュすると、サービス全体が利用できなくなる。したがって、可用性の高い検索サービスをデプロイする必要がある。
Milvusはクラスタ・シャーディング・ミドルウェアであるMishardsと、コンフィギュレーション用のMilvus-Helmの両方を提供している。Milvusクラスタサービスをデプロイするプロセスは簡単だ。いくつかのパラメータを更新し、Kubernetesにデプロイするためにパックするだけだ。Milvusのドキュメントにある以下の図は、Mishardsがどのように動作するかを示している:
Mishardsの仕組み図](https://assets.zilliz.com/1_how_mishards_works_in_milvus_documentation_43a73076bf.png)
Mishardsはアップストリームからのリクエストを分割したサブモジュールにカスケードし、サブサービスの結果を収集し、アップストリームに返します。Mishardsベースのクラスタソリューションの全体的なアーキテクチャを以下に示す:
Mishardsの全体アーキテクチャ](https://assets.zilliz.com/2_mishards_based_cluster_solution_architecture_3ad89cf269.jpg)
公式ドキュメントではMishardsについてわかりやすく紹介しています。興味のある方はMishardsを参照してください。
私たちの音楽レコメンダーシステムでは、Milvus-Helmを使って、書き込み可能なノード1台、読み取り専用ノード2台、Mishardsミドルウェアインスタンス1台をKubernetesにデプロイした。しばらくFAT環境でサービスが安定稼働した後、本番環境にデプロイした。今のところ安定している。
🎧 I2I音楽レコメンデーション🎶(英語)
前述したように、抽出した既存楽曲のエンベッディングを用いて、WanyinのI2I音楽推薦システムを構築しました。まず、ユーザがアップロードした新曲のボーカルとBGMを分離(トラック分離)し、BGMの埋め込みデータを曲の特徴表現として抽出しました。これは、オリジナル曲のカバーバージョンの選別にも役立つ。次に、これらのエンベッディングをMilvusに格納し、ユーザが聴いた曲を元に類似曲を検索し、検索された曲を並べ替えたりしてレコメンデーションを生成する。以下に実装プロセスを示す:
WanyinのI2I音楽推薦システムの実装](https://assets.zilliz.com/3_music_recommender_system_implementation_c52a333eb8.png)
🚫 重複曲フィルター
Milvusを使うもう一つのシナリオは、重複曲フィルタリングです。ユーザの中には同じ曲やクリップを何度もアップロードする人がおり、重複した曲が推薦リストに表示されることがある。つまり、前処理なしで推薦を生成することは、ユーザーエクスペリエンスに影響を与えることになる。そのため、前処理によって重複する曲を見つけ出し、同じリストに表示されないようにする必要がある。
Milvusを使用するもう一つのシナリオは、重複曲のフィルタリングである。同じ曲やクリップを何度もアップロードするユーザーがおり、重複した曲が推薦リストに表示される可能性がある。つまり、前処理なしで推薦を生成することは、ユーザーエクスペリエンスに影響を与えることになる。そのため、前処理によって重複する曲を見つけ出し、同じリストに表示されないようにする必要がある。
前述のシナリオと同様に、類似した特徴ベクトルを検索することによって、重複曲フィルタリングを実装した。まず、ボーカルとBGMを分離し、Milvusを用いて類似曲を検索した。重複曲のフィルタリングを正確に行うため、対象曲と類似曲の音声指紋を抽出し(Echoprint、Chromaprint等の技術を使用)、対象曲の音声指紋と類似曲の各指紋の類似度を算出した。類似度が閾値を超えた場合、その曲をターゲット曲の複製と定義する。オーディオフィンガープリントマッチングのプロセスは重複曲のフィルタリングをより正確にしますが、時間もかかります。そのため、膨大な音楽ライブラリの曲をフィルタリングする場合、その前段階としてMilvusを使って重複曲候補をフィルタリングする。
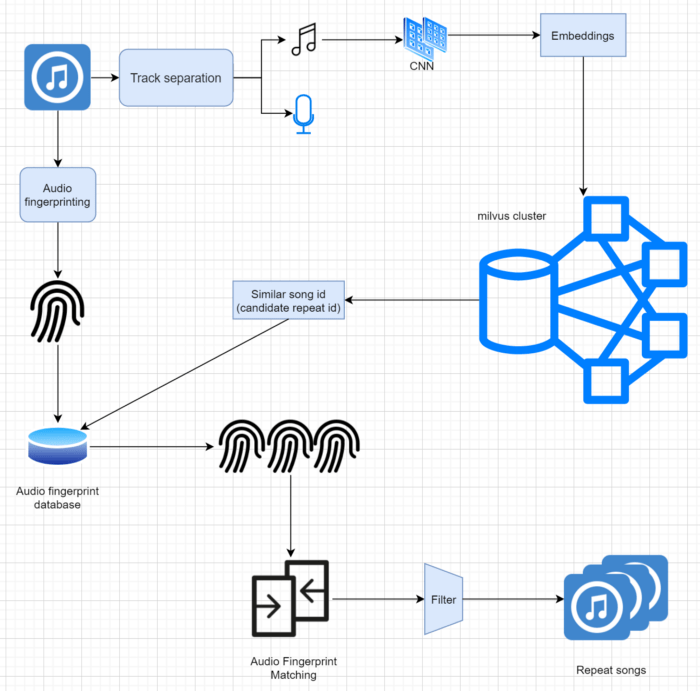 Milvusを使って重複曲フィルタリングを実現する
Milvusを使って重複曲フィルタリングを実現する
Wanyinの膨大な音楽ライブラリにI2I推薦システムを実装するために、私たちのアプローチは、曲の埋め込みを特徴として抽出し、ターゲット曲の埋め込みと類似した埋め込みを呼び出し、その結果をソートして並べ替え、ユーザへの推薦リストを生成します。リアルタイム推薦を実現するため、特徴ベクトル類似検索エンジンとしてFaissよりもMilvusを選択しました。同じ意味で、重複曲フィルターにもMilvusを適用し、ユーザーエクスペリエンスと効率を向上させています。
Wanyin App](https://enjoymusic.ai/wanyin)をダウンロードしてお試しください。(注:すべてのアプリストアで利用できるとは限りません。)
📝 著者:
ジェイソン、ステップビーツのアルゴリズム・エンジニア Shiyu Chen、Zillizのデータエンジニア
📚参考文献
Mishards Docs: https://milvus.io/docs/v0.10.2/mishards.md ミシャード: https://github.com/milvus-io/milvus/tree/master/shards ミルバス・ヘルム:https://github.com/milvus-io/milvus-helm/tree/master/charts/milvus
読み続けて

Why and How to Migrate from Self-Hosted Milvus to Zilliz Cloud
A simple, step-by-step guide to migrating from Milvus to Zilliz Cloud. Learn both endpoint and backup methods for a smooth, scalable vector database migration.

How to Build RAG with Milvus, QwQ-32B and Ollama
Hands-on tutorial on how to create a streamlined, powerful RAG pipeline that balances efficiency, accuracy, and scalability using the QwQ-32B and Milvus.

Vector Databases vs. NoSQL Databases
Use a vector database for AI-powered similarity search; use NoSQL databases for flexibility, scalability, and diverse non-relational data storage needs.