




GenAIエコシステムの風景:LLMとベクトルデータベースを超えて
20ヶ月前のChatGPTの画期的なローンチ以来、GenAIスペースは大きな発展と革新を経験してきました。当初は、大規模言語モデル(LLMs)とベクトルデータベースが最も注目を集めました。しかし、GenAIのエコシステムは、これら2つの要素よりもはるかに広範で複雑である。GenAIアプリケーションを強化する重要なインフラであるベクターデータベースの構築者として、私は急速な技術の進歩と業界への影響を観察することに興奮している。この記事では、これまでの経緯を振り返り、GenAIエコシステムの展望についての洞察を共有したい。
ジェネレーティブAIのアプリケーションは、大きく2つのタイプに分類することができる:Retrieval-Augmented Generation (RAG)とマルチメディア生成である。RAGは、情報検索技術と生成言語モデルを組み合わせて、関連性のある首尾一貫した出力を生成する。一方、マルチメディア生成は、生成モデルを活用して、クリエイティブな広告やデジタル・ツインなどの複雑な視覚コンテンツを作成する。
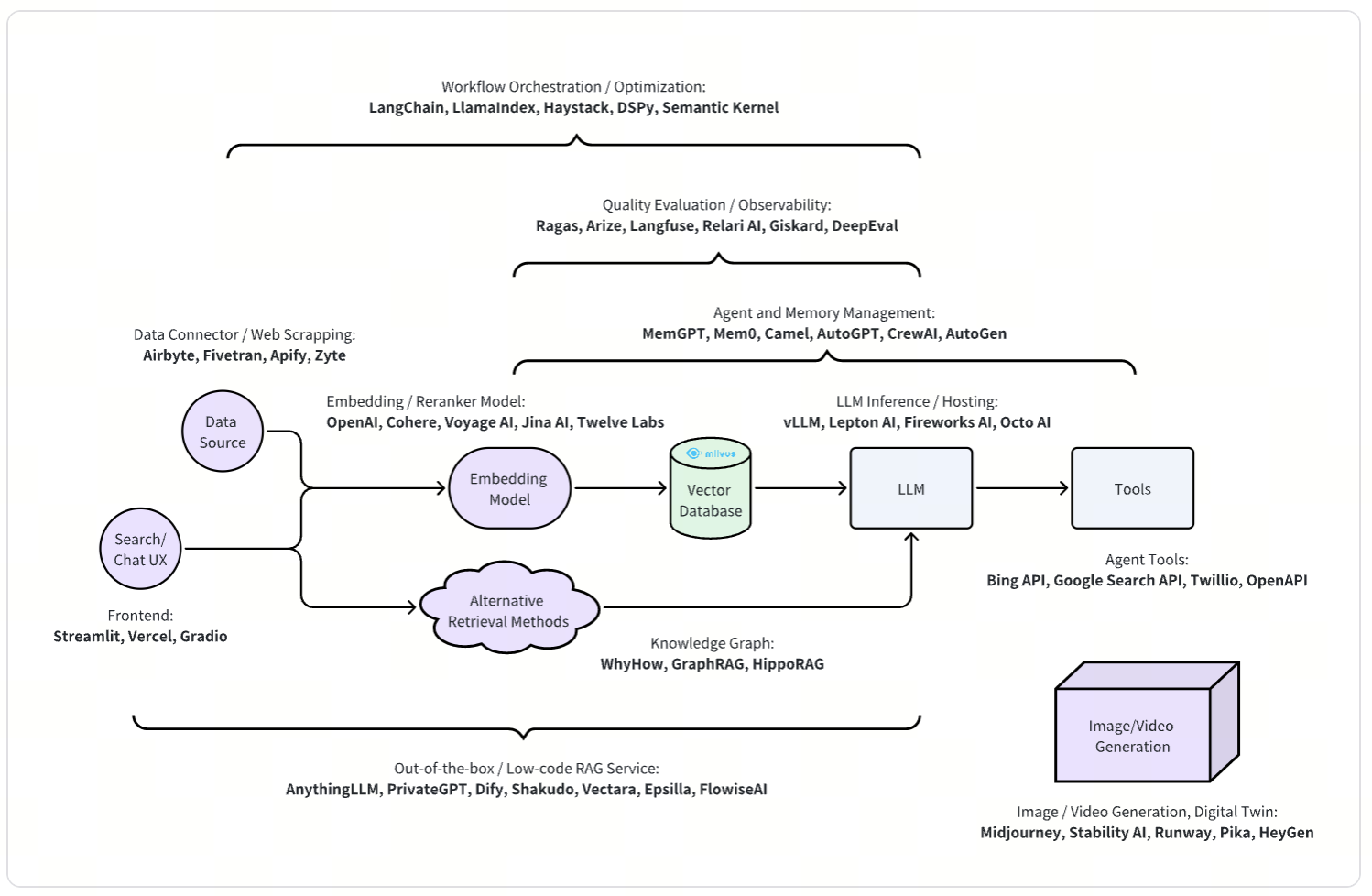
検索拡張型ジェネレーション
検索補強型生成(RAG)は現在、生成AIの最も一般的なユースケースの1つである。単純なRAGシステムは、基本的なデータクリーニング、埋め込みモデル、ベクトルデータベース、LLMなどの様々なコンポーネントから構成される。より高度な、プロダクションレベルのRAGシステムは、一般的に、品質とユーザーエクスペリエンスを向上させるための追加コンポーネントを含む。RAGシステムは従来の検索システムのアーキテクチャに似ているため、検索システムの多くのコンポーネントは今日でもRAGに適用可能である。
典型的な検索システムは、オフラインのインデックス作成部分とオンラインのクエリ提供部分の2つの主要部分に分けられる。同様に、RAGはインデックス作成フェーズとオンラインクエリーサービスフェーズから構成される:
インデックス作成フェーズ:** インデックス作成フェーズでは、データベース、API、ファイルシステムを含む様々なソースからデータを取得する。インデックス作成フェーズでは、データベース、API、ファイルシステムなど、さまざまなソースからデータを取得する。処理後、データは適切なフォーマットに組み込まれ、効率的な検索のためにベクトルデータベースにロードされる。RAGシステムの中には、ラベル抽出、ナレッジグラフ構築、要約などの高度なデータマイニング技術を組み込んで、データを充実させ、検索プロセスを改善するものもある。
オンラインクエリ提供フェーズでは、ユーザのクエリ意図を理解することに重点を置き、ベクトル類似性検索を含む様々な検索方法を用いて、最も関連性の高い情報を検索する。検索結果は、生成のために大規模言語モデル(LLM)に送られる。この段階でLLMは、検索されたデータに基づいて、首尾一貫した文脈に関連した出力を生成する。さらに、LLMはエージェントとして機能し、外部ツールを活用してその能力を高め、より包括的で正確な応答を提供することができる。
その結果、多くのオーケストレーション・プロジェクトは、様々なコンポーネントやコンフィギュレーション・ノブの実装を提供している。また、アーキテクチャが複雑であるため、システムをホワイトボックスとしてもブラックボックスとしても評価する必要があり、評価フレームワークの開発につながる。
また、各コンポーネントは、各データソースのコネクタや、特定のユースケースに合わせたモデルの組み込みなど、より優れたリッチな機能の構築を目指す開発者を惹きつける。LLM推論フレームワークは、APIサービスだけでなく、LLMのより柔軟な展開オプションを提供する。さらに、エージェントフレームワークは、LLMの推論能力とツール使用能力をよりよく活用するのに役立つ。
さらに、プロジェクトによっては、ナレッジグラフのような代替検索メソッドを探求したり、UIエクスペリエンスを向上させるウェブフロントエンドフレームワークを開発したり、チャットボットUIを含むRAGワークフロー全体を提供するアウトオブボックスソリューションを作成するなど、さまざまな観点からRAGにアプローチしている。
ワークフローのオーケストレーションと最適化
RAGアプリケーションの複雑なワークフローを管理するために、LangChain、LlamaIndex、Haystack、DSPy、*Semantic KernelなどのSDKが広く利用されています。これらのオーケストレーションフレームワークは、開発者がRAGパイプラインを構築、カスタマイズ、テストすることを可能にし、パイプラインが特定のユースケースに最適な生成回答品質を達成するように構成されていることを保証する。
例**ラマインデックス
LlamaIndexは、LLMを使用してコンテキスト拡張アプリケーションを構築するためのフレームワークです。データの取り込み、解析、索引付け、問い合わせのためのツールを提供することで、開発者はLLMをプライベートデータと統合することができる。このアプローチにより、API、SQLデータベース、ドキュメントなどのユーザー固有のデータソースからコンテキストを取り込むことで、質問応答、チャットボット、ドキュメント理解などの特定のアプリケーションにLLMを使用することが容易になります。LlamaIndexは、様々なチャンキング戦略やハイブリッド検索メソッドなど、一般的に使用されるコンポーネントの便利なプログラム抽象化を提供します。
品質評価と観測可能性
RAGは複雑なシステムであるため、特定のシナリオで最適な結果を達成することは困難な場合があります。このような課題に対処するためには、科学的な評価手法が不可欠である。Ragas](https://zilliz.com/product/integrations/ragas)、Arize、Langfuse、Relari AI、Giskard、DeepEval**などのプロジェクトは、評価と観測可能性のために必要なメトリクスとツールを提供しています。これらのツールにより、開発者はRAGシステムを定量的に測定、監視、トラブルシューティングすることができます。
例Ragas
RagasはRAGパイプラインを評価するための包括的なフレームワークです。Ragasは、忠実性、関連性、文脈の正確さなどの回答品質を評価するためのツールを提供します。Ragasは、合成テストデータセットの生成、本番環境でのRAGアプリケーションのモニタリング、LangChainやLlamaIndexのようなAIツールやプラットフォームとの統合をサポートします。主要なパフォーマンス側面をカプセル化した調和されたRagasスコアを提供することで、このフレームワークは評価プロセスを簡素化・定量化し、最終的にRAGパイプラインの有効性と信頼性を向上させます。
データコネクタとウェブスクレイピング
複数のソースからのデータをシームレスに統合して処理する能力は極めて重要である。Airbyte](https://zilliz.com/product/integrations/Airbyte)やFivetranのようなプラットフォームは、ウェブスクレイピングのためのApifyやZyte**と同様に、堅牢なデータコネクタを提供することでリードしている。これらは、企業がデータを効率的に収集、変換、RAGワークフローに統合することを可能にし、重要なミッションにAIの力を活用することを容易にします。データ収集と接続性は、従来の検索システムにとって重要であり、今日のRAGにおいても同様に重要である。
例**エアバイト
Airbyteは、抽出とロード(EL)データパイプラインを構築するために設計されたオープンソースのデータ移動プラットフォームである。多くのデータパイプラインプラットフォームが主に主要なサービスにフォーカスしているのとは異なり、Airbyteは小規模で見過ごされがちなサービスの統合もサポートしています。膨大な数のコネクタを維持し、カスタムコネクタを共有するためのコミュニティを育成することで、Airbyteは企業が特定のニーズに合わせたソリューションを作成することを可能にします。その堅牢なデータコネクタは、非構造化データをエンベッディングに処理し、Milvusのようなベクターデータベースにロードして意味的類似性検索を行うことができる。この機能は、企業がデータを効率的に収集、変換、RAGワークフローに統合し、AI主導の意思決定や検索アプリケーションを強化するのに役立ちます。
エンベッディングとリランカーモデル
エンベッディング・モデルなどのディープ・ニューラル・ネットワークは、非構造化データがどのように処理され理解されるかを変革している。OpenAI、Cohere、Voyage AI、Jina AI、Twelve Labs**のような企業は、テキストデータやマルチモーダルデータを数値ベクトルに変換する高度なモデルの開発の最前線にいる。これらの埋め込みにより、近似最近傍(ANN)ベクトル検索が可能になり、アプリケーションは関連性の高い結果と洞察を提供できるようになります。
汎用のエンベッディング・モデルだけでなく、Voyage AIのような企業は、法律や金融のような特定の分野で品質を向上させる特殊なモデルを作成しており、Twelve Labsは動画検索のエンベッディング・モデルに注力している。リランカーは、クエリと少数の候補文書セットとの意味的関連性を比較するために意図的に訓練されたモデルであり、最初のベクトルベースの検索段階からの結果の精度をさらに高めることができる。Cohere、Voyage AI、Jina AIなどの企業は、検索精度を向上させるリランカーを提供している。
例**ボヤージュAI
Voyage AIは、埋め込みモデルやリランカーを含む検索モデルを専門とするスタンフォード大学とMITのAI研究者チームである。彼らの代表的なモデルであるvoyage-2は、テキストに対する対照学習によって学習され、OpenAIのテキスト埋め込みモデルのような業界標準と比較して、より高い検索精度、拡張されたコンテキストウィンドウ、効率的な推論を提供する。Voyage AIは、金融、多言語文脈、法律業務、コード検索などの分野に最適化された、汎用モデルとドメイン固有モデルの両方を提供する。Voyage AIは、検索結果を向上させるリランカーも提供している。
LLM 推論とホスティング
LLMアプリケーションの需要が高まる中、効率的なホスティングと推論ソリューションは不可欠です。vLLM](https://zilliz.com/blog/building-rag-milvus-vllm-llama-3-1)、Lepton AI、Fireworks AI、Octo AI**などのプロジェクトは、LLMのデプロイとスケーリングのための堅牢なインフラを提供しています。LLMには様々な推論最適化が組み込まれており、モデルの処理時間中に効率的に動作するようになっている。
例vLLM
vLLMは、最適化されたLLM推論とサービングのためのオープンソースライブラリである。PagedAttentionメカニズムを使用して効率的にメモリを管理し、着信リクエストの継続的なバッチ処理をサポートします。vLLMは、一般的なHuggingFaceモデルとシームレスに統合され、並列サンプリングやビームサーチのようなデコーディングアルゴリズムによる高スループットのサービングを提供します。分散推論、ストリーミング出力のためのテンソル並列とパイプライン並列をサポートし、OpenAI互換のAPIサーバーを含む。さらに、プレフィックスキャッシングやマルチローラのサポートなどの実験的な機能を提供し、NVIDIAとAMDの両方のGPUに最適化されています。
エージェントとメモリ管理
GenAIエコシステムは、MemGPT、Mem0、Camel、AutoGPT、CrewAIのようなソリューションにより、メモリ管理とエージェントベースのAIシステムにおいて進歩しています。これらのイノベーションにより、AIアプリケーションは会話履歴を記憶し、ツールを活用し、相互に作用することが可能になり、ユーザー体験を大幅に向上させる、よりパーソナライズされたコンテキストを認識したインタラクションを提供します。
例MemGPT
MemGPTは、ステートフルLLMエージェントの開発と展開を簡素化することを目的としたオープンソースプロジェクトです。従来のオペレーティングシステムと同様のメモリ階層と制御フローを利用することで、MemGPT は異なるストレージ階層を自動的かつインテリジェントに管理し、LLM の限られたコンテキストウィンドウ内で拡張コンテキストを提供します。MemGPTは、RAGを介した外部データソースへの接続を容易にし、カスタムツールや関数の定義と呼び出しをサポートすることで、高度なステートフルLLMエージェントの開発を容易にします。
エージェントの外部ツールとAPI
様々な外部ツールやAPIとAIモデルを統合することは、エージェントの機能を拡張する上で極めて重要である。Bing API、Google Search API、Twilioのようなサービスや、OpenAPI**のようなフレームワークは、エージェントとツールの相互作用を促進し、アプリケーションが外部のデータ、サービス、機能にアクセスし、活用することを可能にする。
例Bing API
ウェブ検索や画像検索のようなサービスを含むBing Search APIスイートは、安全で広告がなく、位置情報を考慮した検索結果を提供する。これにより、エージェントは1回のAPIコールで、何十億ものウェブドキュメント、画像、ビデオ、ニュースソースから情報にアクセスすることができます。
フロントエンドと検索/チャットUIの経験
AIアプリケーションと対話するための直感的なインターフェイスを作成することは、ユーザーの採用に不可欠です。Streamlit、Vercel、Gradio**のようなフレームワークは、ユーザーフレンドリーなUIエクスペリエンスを提供することで、AIアプリケーションの開発を簡素化します。開発者はこれらのフレームワークを活用することで、RAGアプリケーションのチャットボックスや、ビジュアル検索のための画像選択、トリミング、ブラウジングのような機能など、AIインタラクションの特定のニーズに合わせてインターフェースをカスタマイズすることができます。
例**ストリームリット
StreamlitはオープンソースのPythonフレームワークで、データサイエンティストやAI/MLエンジニアが最小限のコーディング作業でダイナミックでインタラクティブなデータアプリケーションを作成できるように設計されています。直感的な構文に重点を置き、CSS、HTML、JavaScriptの必要性を排除することで、Streamlitは洗練されたアプリケーションの迅速な構築とデプロイを可能にします。PandasやNumPyのような一般的なデータライブラリと統合され、AI駆動型アプリケーション開発のためのバックエンドコンポーネントをサポートしています。
ナレッジグラフ(KG)
ナレッジグラフは、情報検索の精度と関連性を向上させる構造化データを提供することで、検索-拡張生成を強化し、より正確でコンテキストを意識したAI生成応答をもたらします。WhyHow、GraphRAG、HippoRAG**のような主要なプロジェクトは、検索結果と生成された回答の品質を向上させるために、ナレッジグラフ構造とRAG技術を組み合わせています。
例WhyHow
WhyHowは、ナレッジグラフを使用した複雑なRAG(Retrieval-Augmented Generation)システムの強化に重点を置き、開発者がより効果的に非構造化データを整理し、検索できるように設計されたプラットフォームです。柔軟なデータ取り込みのためのツールを提供し、開発者と非技術的なドメインエキスパートとのコラボレーションのための多人数でのグラフ作成をサポートし、特定のユースケースに合わせてグラフを調整するためのきめ細かいスキーマ操作を可能にします。小さくモジュール化されたグラフとベクトルチャンクを重視することで、WhyHowは情報検索の精度を向上させます。このプラットフォームはベクターデータベースと互換性があり、様々なフォーマットへのエクスポート機能を備えています。さらに、WhyHowは、高度なフィルタリング技術により、より正確な検索ワークフローの作成を支援するオープンソースのルールベース検索パッケージを提供しています。
すぐに使えるローコードRAGサービス
RAGのためのすぐに使えるローコードソリューションに対する需要も大きい。AnythingLLM、PrivateGPT、Dify、Shakudo、Vectara、Epsilla、FlowiseAI**などのプロジェクトは、データパイプラインや検索インフラにおける大規模な開発や専門知識を必要とすることなく、企業がAI機能を迅速に展開できるように、使いやすいソリューションとカスタマイズの度合いを提供しています。
例AnythingLLM(エニシングエルエルエム
AnythingLLMは、インタラクティブなRAGチャットボットとAIエージェントをコーディング不要で提供するオールインワンのAIアプリケーションです。プライベート、ゼロセットアップソリューション、または幅広いコーディング専門知識を必要としないカスタマイズ可能なAIアプリケーションを求める企業向けに設計されています。AnythingLLMは、商用およびオープンソースの大規模言語モデル(LLM)とベクトルデータベースの両方をサポートしています。このアプリケーションは、ローカルおよびリモートのホスティングを通じてフルスタックの経験を促進します。主な機能には、組織化されたドキュメント管理のためのワークスペース、権限設定によるマルチユーザーサポート、ウェブブラウジングとコード実行のためのエージェント、カスタム埋め込み可能なチャットウィジェット、複数のドキュメントタイプのサポートが含まれます。AnythingLLMは、カスタム統合のための開発者APIも提供しています。
画像およびビデオ生成
GenAIエコシステムはテキストベースのアプリケーションに限定されません:
クリエイティブ生成とデジタルツイン
Midjourney、Stability AI、Runway、Pika、HeyGen**などのツールは、高品質の画像や動画を生成するためのAIを搭載したソリューションを提供することで、クリエイティブ業界に革命をもたらしています。これらのプラットフォームは、アーティスト、マーケティング担当者、開発者に魅力的なビジュアルコンテンツを作成する力を与え、創造性と革新性の限界を押し広げます。
例**ミッドジャーニー
Midjourneyは、サンフランシスコの独立系研究所であるMidjourney, Inc.によって開発された生成AIプログラムおよびサービスである。OpenAIのDALL-EやStability AIのStable Diffusionと同様に、自然言語の説明やプロンプトから高品質の画像を作成する。ユーザーはDiscordボットを介してMidjourneyと対話し、/imagineコマンドでプロンプトを入力することで画像を生成し、アップスケーリング用のオプションが付いた4つの画像を得ることができる。このツールは、GenAIエコシステムの進歩を強調し、デジタルコンテンツ制作の可能性を広げることでクリエイティブ産業に影響を与える。
おわりに
GenAIのエコシステムは、ダイナミックで急速に進化するランドスケープであり、多様なコンポーネントと複雑性が特徴です。LLMやベクトルデータベースのような基盤技術から、データ取り込み、オーケストレーション、画像生成の革新まで、GenAIは人工知能の境界を再定義しています。探求と革新が続けば、業界全体に変革をもたらす可能性は計り知れません。Zillizでは、Milvusベクトルデータベースの開発者として、GenAIの分野で多くのパートナーと協力してきました。私たちは、GenAIの継続的な進化を目撃し、貢献することを熱望し、それがもたらす可能性を楽しみにしています。

読み続けて

Zilliz Cloud Now Available in AWS Asia Pacific (Seoul)
Zilliz Cloud is now available in AWS Seoul — low-latency vector search, in-country data residency, and one-step migration for Korean AI teams. 31 regions across 5 clouds.

Why Teams Are Migrating from Weaviate to Zilliz Cloud — and How to Do It Seamlessly
Explore how Milvus scales for large datasets and complex queries with advanced features, and discover how to migrate from Weaviate to Zilliz Cloud.

How to Use Anthropic MCP Server with Milvus
MCP + Milvus: Streamline AI agent development with standardized data access, eliminating integration hassles while enhancing context and flexibility.