




オートGPTの説明:あなたのユニークなユースケースのための包括的なオートGPTガイド
この記事はThe Sequenceに掲載されたもので、許可を得てここに再掲載している。
2022年12月、GPTを搭載したチャットボット・インターフェイスChatGPTが、大規模言語モデル(LLM)を主流メディアに紹介した。それ以来、数多くのGPTアプリが登場している。最も人気のあるものの1つは?Auto-GPT。オープンソースのGPTベースのアプリで、GPTを完全に自律化することを目指している。わずか数週間で、PyTorch、Scikit-Learn、HuggingFace Transformers、その他あらゆるオープンソースのAI/MLライブラリを凌駕し、GitHubで120k以上のスターを獲得した。
Auto-GPTがこれほど人気のあるプロジェクトである理由は何だろうか?第一に、自律型GPTという自称ビジョンの実現が期待できるからだ。Auto-GPTには、ウェブを検索したり、話したり、会話を記録したりする「エージェント」が組み込まれている。人々はそれを使ってピザを注文したり、アプリをコーディングしたり、商品を販売したりしている。今度はあなたがAuto-GPTを活用してワークフローを強化し、ありふれたタスクを自動化する方法を学ぶ番だ。
このAuto GPTチュートリアルでは、次のことを学びます:
- Auto-GPTとは?
- 数分でAuto GPTをセットアップする方法
- Auto-GPT用に
.envを設定する
- Auto-GPT用に
- Auto-GPTで最初のタスクを実行する
- Auto-GPTにメモリを追加する
- Milvus Standaloneを使う(Docker Compose)
- Milvus Liteを使う(Pipインストール)
- "Auto-GPTの説明 "のまとめ
Auto-GPT とは?
最近AIが熱い。ChatGPTは、2023年2月の時点で月間訪問者数が10億人を超え、史上最も急成長しているアプリと報告されています。LLMは、人工知能(AGI)の到来、ソフトウェアの未来、人類を啓蒙か破滅に導くテクノロジーのブレークスルーと謳われてきた。しかし、LLMには重大な欠点がある。LLMは自分で行動できないのだ。LLMは、誰かがタスクからタスクへと繰り返し促す必要があるのだ。
Auto-GPTはこの問題の解決に乗り出した。Auto-GPTは、GPT-4が自律的に機能することを目的としたオープンソースのソフトウェアである。どのようにして自律性を提供するのか?エージェントを使うのだ。Auto-GPTは、インターネット閲覧、音声合成ツールによる会話、コードの記述、入出力の追跡などのタスクを実行するエージェントをユーザーがスピンアップすることを可能にする。
この拡張機能は、誇大広告とメディアの悲観的なシナリオを助長する。しかし、AIを恐れる必要はない。AIを活用する方法を理解している限り、AIのストーリーは前向きで生産的なものになる。それでは、ほんの数分でローカル・マシンでAuto GPTを立ち上げて実行する方法を見てみよう。
数分でAuto-GPTをセットアップする方法
自動GPTの設定方法](https://assets.zilliz.com/Auto_gpt_blog_1_8516fed6f9.png)
Auto-GPTの設定は驚くほど簡単です。まず、Auto-GPT GitHubページにアクセスし、cloneリンクをコピーしてください。それから、ターミナルかVSCodeインスタンスを開き、作業ディレクトリに移動する。私の場合は、~/Documents/workspaceです。git clone git@github.com:Significant-Gravitas/Auto-GPT.git` を使ってローカルにリポジトリをクローンします。次に、新しく作成したフォルダに移動します。
新しく作成したフォルダで、新しいPython仮想環境を作成します。仮想環境に入ったら、pip install -r requirements.txt を実行して依存関係をすべてインストールします。これで Auto-GPT がインストールされました。インスタンスを立ち上げて実行するために必要な最後のことは、OpenAI API キーを環境変数に入れることです。
自動GPTのための.envの設定
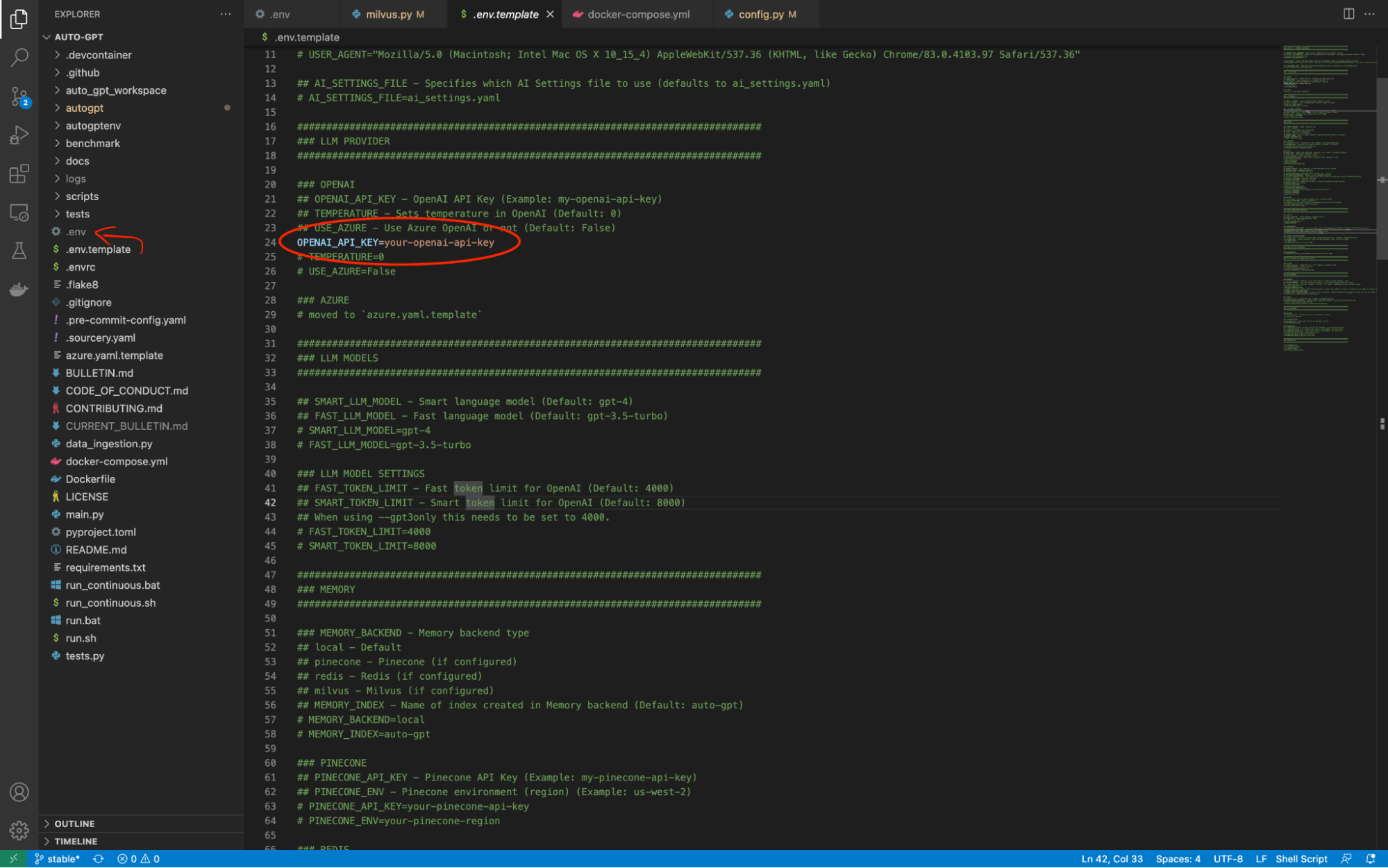 configure-env.png
configure-env.png
Auto-GPTのルートディレクトリには.env.templateというファイルがある。このファイル名を.envだけに変更する必要がある。そして、このファイルを使って、Auto-GPTに自律的な機能を与える外部ツールとの接続に必要な情報をすべて保存することができる。Auto-GPTを起動する前に、1つ変更しなければならないことがある。OPENAI_API_KEY`の値をOpenAI APIキーに変更する必要があります。
Auto-GPT で最初のタスクを実行する
 run-task-auto-gpt.png
run-task-auto-gpt.png
OpenAI API Keyが更新されたら、Auto-GPTを使っていくつかの作業を自動化することができます。この例では、AIにおける先月の最もインパクトのある開発についてのニュースレターの作成を自動化します。ターミナルで python -m autogpt を実行して起動します。Auto-GPTを起動すると、名前をつけ、役割を定義し、目標を与えるように促される。
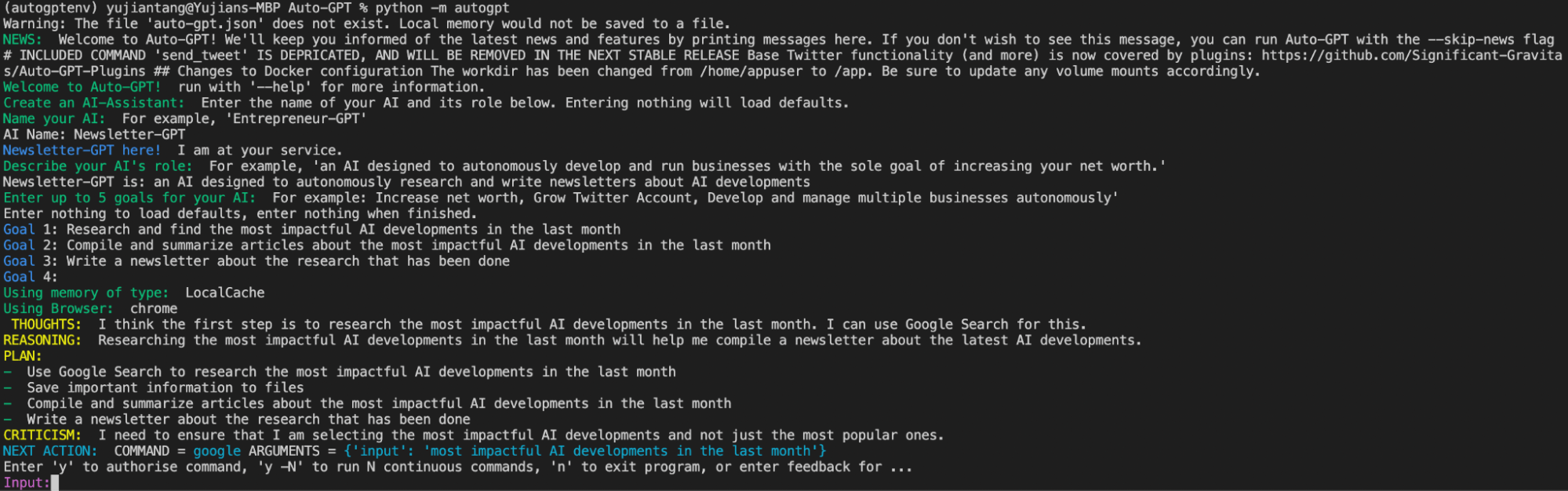 run-first-task-auto-gpt.png
run-first-task-auto-gpt.png
この例では、AIに「ニュースレター・ジェネレーター」という名前をつけます。次のプロンプトでは、Newsletter-GeneratorがAIの開発について自律的に調査し、ニュースレターを書くように設計されたAIであることをAIに伝えます。次に、Auto-GPTはAIに最大5つの目標を与えるように促します。
私はNewsletter-Generatorに3つの目標を与えた。第一に、この一ヶ月で最もインパクトのあったAIの開発を調査して見つけること。第二に、先月の最もインパクトのあったAI開発に関する記事をまとめ、要約すること。3つ目は、調査結果についてのニュースレターを書くこと。セットアップが完了すると、Auto-GPTはこの設定を保存するためにai_settings.yamlというファイルを生成し、タスクを開始する。
各タスクに対して、思考、理由、計画、その計画に対する批判、次のステップを提供する。タスクを実行する前に、その計画に対する承認やフィードバックを求めるプロンプトが表示される。私たちが望むなら、私たちに承認を求めることなく、次のN個のタスクを自律的に実行させることができる。
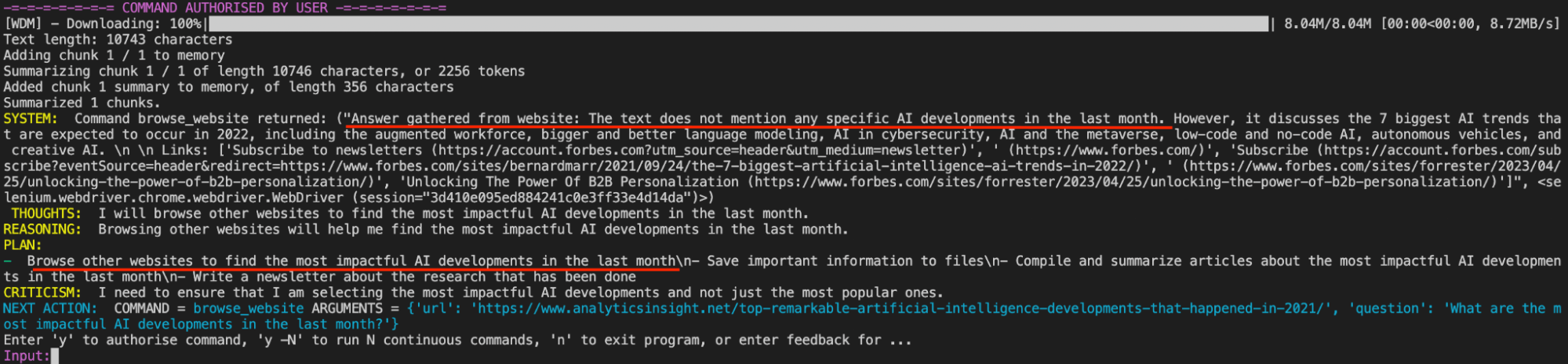 auto-gpt-ability.png
auto-gpt-ability.png
上の画像では、Auto-GPTがGoogleで見つけた最初の記事にはタスクを完了するのに必要な情報が含まれていないことを見分ける能力を見ている。Auto-GPTはこれを私たちに返し、先月の衝撃的なAIの開発を得るための次のステップを呼び起こす。
自動GPTにメモリを追加する
 メモリを追加する-自動GPT.png
メモリを追加する-自動GPT.png
Auto-GPTのデフォルトの "local "ストレージオプションを使うと、Auto-GPTは上の画像のようなauto-gpt.jsonというドキュメントを生成する。このドキュメントには、テキストブロックとそれに続く数字の束が含まれています。テキストブロックはAuto-GPTとの現在の会話を記録し、数字はその会話を表すベクトル埋め込みです。
メモリーに JSON ファイルを使用することは、スケーラブルなソリューションではありません。Auto-GPTで作業すればするほど、より多くのデータが生成されます。これまでの会話の記憶という形だけでなく、書き込むファイルや追加の「エージェント」も生成されます。JSONはこれらの情報を記録しておくことができますが、もしあなたが作成したものを検索したり、取り出したり、編集したりしたいのであれば、永続的なストレージバックエンドが必要になります。
幸運なことに、Auto-GPTは様々なメモリバックエンドを使用することができます。ベクターデータを保存するのですから、Milvusのようなベクターデータベースが理想的なソリューションです。Milvusはオープンソースのベクトルデータベースで、KubernetesやDocker上で実行する分散ソリューションやローカルインスタンスを実行する方法など、複数のソリューションがあります。この例では、バックエンドとしてMilvusを使用する2つの方法を取り上げます。
まず、Docker Composeを使った分散ソリューションであるMilvus Standaloneをローカルで実行する方法。2つ目は、Pythonコードでベクターデータベースをインスタンス化して使用するMilvus Liteの使用方法です。最初のソリューションは、Auto-GPTのコードを少し変更するだけですが、Docker Compose経由でMilvusをダウンロードする必要があります。2つ目の解決策では、既存のパッケージをもう少し変更する必要がありますが、pip installだけでMilvusを使用することができます。
スタンドアロンでMilvusを使用する(Docker Compose)
メモリソリューションとしてMilvus Standaloneを使用する場合、Auto-GPTコードの変更は少なくて済みますが、Dockerが必要になります。Milvus Standalone](https://milvus.io/docs/install_standalone-docker.md)の説明に従い、ローカルのDockerコンテナ上でインスタンスを立ち上げて実行してください。
Milvusインスタンスを立ち上げたら、Auto-GPTが長期保存用にMilvusインスタンスを使用するように、いくつかの変更を加えるだけでよい。.envファイルでMEMORY_BACKENDを見つけ、localからmilvusに変更する。次にMILVUSを見つける。MILVUS の下に MILVUS_ADDR と MILVUS_COLLECTION という2つの環境変数がある。これらをアンコメントする。デフォルトのままで構わない。
pip install pymilvusを実行してMilvus SDKを入手する。その後、python -m autogptを使用してAuto-GPTを再度起動する。この時、変化に気づくはずである。ターミナルにUsing memory of type:MilvusMemory`のメッセージが表示されるはずだ。Auto-GPTにMilvusを追加する方法は以上である。
 add-milvus-auto-gpt.png
add-milvus-auto-gpt.png
Milvus Liteを使う (Pipインストール)
注意: これらの変更をAuto-GPTに取り込むためのプルリクエスト がオープンされています。
Milvus Lite](https://github.com/milvus-io/milvus-lite)はMilvus Standaloneと異なり、余分な依存関係はありません。pip install milvus pymilvusを実行して、Milvus LiteとMilvus Python SDKをpip` でインストールする。Auto-GPTを起動する前に外部からMilvusを起動するつもりはないので、Auto-GPTのセットアップ中に起動させる必要がある。
そのために3つのファイルを変更する:.env、autogpt/memory/milvus.py、autogpt/config/config.pyです。まず、Milvusスタンドアロンインスタンスと同じ変更を行います。MEMORY_BACKEND 変数を milvus に変更し、MILVUS_ADDR と MILVUS_COLLECTION 変数のコメントを外します。.envファイルの Milvus セクションにMILVUS_TYPEという新しい環境変数を追加し、lite` と等しい値に設定する。
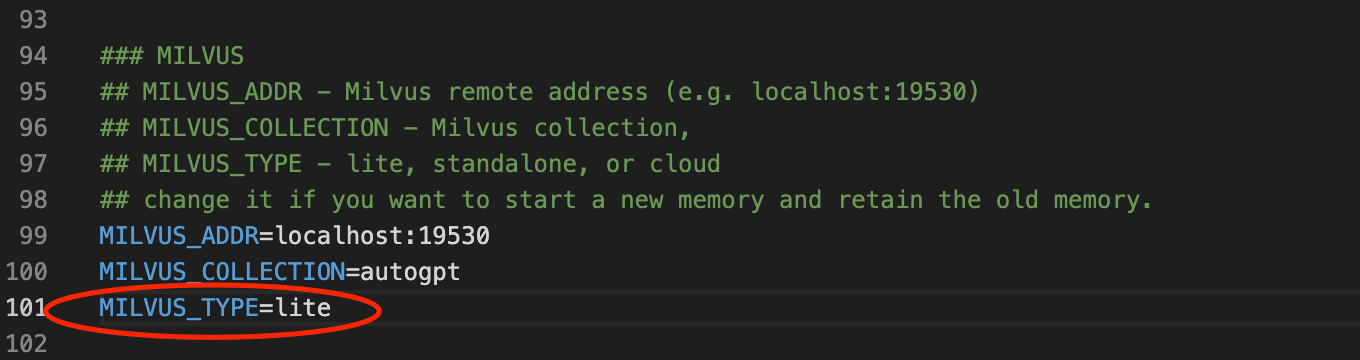 milvus-type.png
milvus-type.png
autogptフォルダの下の2つのファイルを変更します。config フォルダ下の config.py ファイルで、環境変数から MILVUS_TYPE を取得するために milvus_type の値を設定する。
python
milvus のタイプはスタンドアロン、ライト、クラウドのいずれかである。
self.milvus_type = os.getenv("MILVUS_TYPE")
memory` フォルダ下の `milvus.py` ファイルに `if` ステートメントを追加して、コンフィグ内の `milvus_type` の値をチェックする。もし値が `lite` なら、Milvus をインポートしてサーバを立ち上げ、デフォルトの Milvus Lite サーバに接続する。元のコードの行を `else` 文に移す。
パイソン
if cfg.milvus_type == "lite":
from milvus import default_server
print("Milvus Liteの起動")
default_server.start()
connections.connect(host='127.0.0.1', port=default_server.listen_port)
さもなければ
connections.connect(address=cfg.milvus_addr)
これらの変更を行うと、通常のようにAuto-GPTを実行できるようになる。python -m autogpt` を実行すると、Auto-GPT のインスタンスが起動し、起動時の出力が少し変わる。ターミナルには "Starting Milvus Lite "という行とMilvus Liteの出力テキストが表示されるはずだ。また、"Using memory of type:と表示されるはずである。
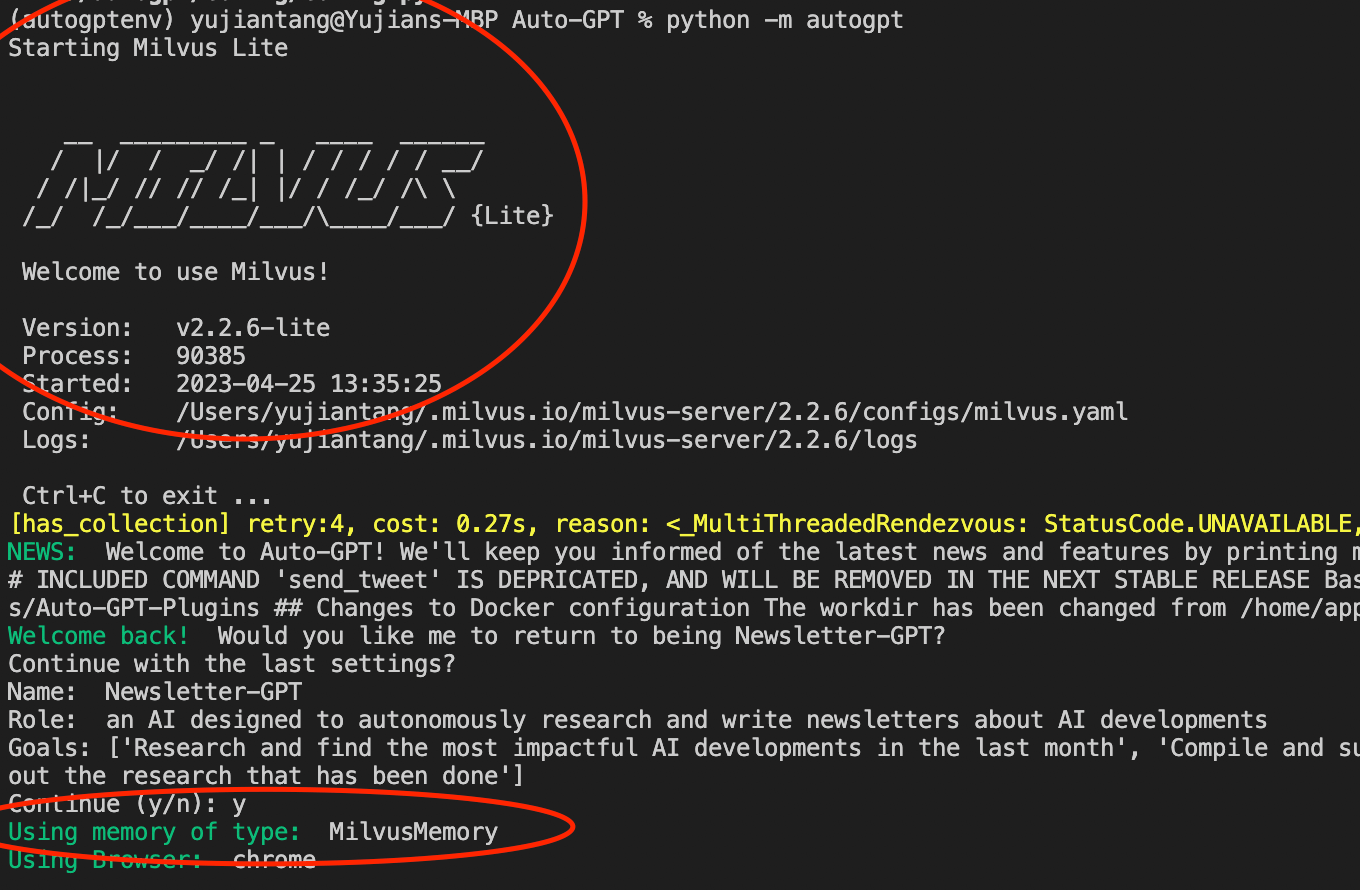 milvus-memory.png
milvus-memory.png
自動GPTの説明 "のまとめ
この記事ではAuto-GPTの基本的な使い方を説明した。まずGitHubからAuto-GPTをダウンロードし、インスタンスを走らせた。走らせた後、Auto-GPTが生成するファイルを見てみた。Auto-GPTのファイルを見ると、ベクターでいっぱいのJSONファイルを使ってローカルにメモリを追跡していることがわかった。
JSONファイルはスケーラブルではない。より堅牢なメモリバックエンドとして、Auto-GPTに統合されている他のメモリオプションの1つであるMilvus vector databaseを使います。Milvusバックエンドを2つの方法で追加する方法を紹介します:スタンドアロンDockerコンテナのセットとして、またはAuto-GPTによってスピンアップされたインスタンスとして。LLMを使ったベクターデータベースに関する他の投稿もお楽しみに。

読み続けて

From Vector Database to Vector Lakebase
Zilliz offers a fully managed Vector Lakebase powered by Milvus, unifying real-time vector search, lake-scale discovery, and Al data operations.

How Zilliz Saw the Future of Vector Databases—and Built for Production
An inside look at how Zilliz built vector databases for real-world use, focusing on scalability, stability, and running them reliably at scale.

How to Build an Enterprise-Ready RAG Pipeline on AWS with Bedrock, Zilliz Cloud, and LangChain
Build production-ready enterprise RAG with AWS Bedrock, Nova models, Zilliz Cloud, and LangChain. Complete tutorial with deployable code.