




デリバリー・ヒーローはいかにしてAI生成画像の安全システムを導入したか
多国籍オンラインフードデリバリー企業であるDelivery Heroは、顧客と各地域のレストランをつないでいる。したがって、デリバリーヒーローのサービスに対する総合的な満足度を維持するためには、両者のニーズを理解することが極めて重要である。
ベルリンで開催されたZilliz Unstructured Data Meetupでのプレゼンテーションで、Delivery Heroの2人のデータサイエンティストであるIaroslav AmerkhanovとNikolay Ulyanovは、レストランのベンダーと顧客のニーズを合理化するための研究プロジェクトについて議論した。
<< Watch the replay of the meetup talk >>
社内の統計に基づき、デリバリーヒーローは興味深い事実を発見した:アプリ上で画像が添付された商品は、画像のない商品よりもはるかに頻繁に注文されている。具体的には、アプリ上で注文された商品の86%に画像が添付されている。また、A/Bテストを実施した結果、商品に画像を追加するだけで、コンバージョン率が6~8%上昇することも判明した。**この発見は、顧客がデリバリーヒーローのアプリで業者に食品を注文する前に、商品の画像が重要な要素の一つであることを意味する。
しかし、各レストランや業者に商品の画像を提供するよう求めるのは面倒なことで、すべての業者が魅力的な画像を提供できるわけではない。そこで、Delivery Heroのデータサイエンティストは、AIの進歩を活用することで、高品質の商品画像を生成する洗練されたアプローチを提案した。彼らのアプローチは、食品画像の生成と安全システムの2つの段階から構成されている。
まず食品画像生成の段階について説明しよう。
食のイメージ生成
1つは、利用可能な生成AIプラットフォームのAPIを呼び出すことであり、もう1つは画像インペインティング法を使用することである。
人気の画像生成モデルによる食品画像生成
DALL-E、Midjourney、stable diffusionなど、高品質で写実的な画像を生成するためのAIモデルがいくつか利用可能です。このため、デリバリーヒーローでは、DALL-Eを用いて料理画像を生成しています。
GPT-3 モデルと同様に、DALL-E は Transformer-decoder ブロックをバックボーンとしています。これは、Transformer アーキテクチャが非常に汎用性が高く、テキストや画像など異なるモダリティのデータ を生成することができるためです。要するに、DALL-E はテキスト記述から画像を生成するように訓練されているのだ。
テキスト記述から DALL-E が生成した画像例](https://assets.zilliz.com/Example_images_generated_by_DALL_E_from_text_descriptions_e14ec5164a.png)
DALL-E を使って画像を生成するのは簡単です。ただ一つ必要なことは、生成させたい画像を説明するテキストプロンプトを用意することです。デリバリーヒーローが食品画像を生成する際に使用するプロンプトは以下の通りです:
素敵なお皿の上に{dish}と{dish_attributes}のプロフェッショナルな写真、{background}背景
このプロンプトで、デリバリーヒーローは特定の属性と背景を持つ料理の高品質な画像を生成します。
 特定の属性と背景を持つ料理の高画質画像生成 by DALL-E.png
特定の属性と背景を持つ料理の高画質画像生成 by DALL-E.png
画像補間による料理画像生成
デリバリーヒーローの料理画像生成の2つ目のアプローチは、インペインティング技術です。画像インペインティングとは、画像の特定の領域を置き換えるプロセスを指します。
全体として、デリバリー・ヒーローがこのアプローチを使って食品画像を生成するために実装したステップは4つある:
画像選択:** データハブから料理の画像を選択する。
オブジェクト検出:** オブジェクト検出モデルを使用して、画像内の料理オブジェクトを検出する。出力として、検出された料理のバウンディングボックスが得られる。
画像マスキングピクセル値を黒または白に置き換えることで、バウンディングボックス内の領域を削除する。
画像インペインティング(Image inpainting):**画像生成モデルを使用して、画像の削除された領域を好みの料理で塗りつぶす。
インペインティング技法による画像生成](https://assets.zilliz.com/Image_generation_with_the_inpainting_technique_30b8344986.png)
デリバリーヒーローでは、この手法に2つのモデルを使用しています:DINOは物体検出に、DALL-Eは画像生成に使用します。
では、上記の画像インペインティングアプローチの各ポイントを分解してみよう。画像選択のステップは簡単なので省略できる。より興味深いのは、Grounding DINOを用いた物体検出ステップである。
一言で言えば、Grounding DINOはテキストと画像のペアを入力とする物体検出モデルである。これは3つの異なる入力融合アプローチを用いる。特徴エンハンサー、言語ガイド付きクエリー選択、クロスモダリティデコーダーの3つで、テキストと画像の入力を効果的に組み合わせ、強力な物体検出モデルを生成する。
特徴エンハンサーとクロスモダリティデコーダーの高レベルアーキテクチャは、注意層とフィードフォワードニューラルネットワークを含むTransformer-blockアーキテクチャとよく似ている。しかし両コンポーネントとも、テキストと画像の入力を融合するために、洗練された画像-テキスト間およびテキスト-画像間のクロスアテンションレイヤーを備えている。
特徴エンハンサーとクロスモダリティデコーダーの高レベルアーキテクチャ.png](https://assets.zilliz.com/The_high_level_architecture_of_the_feature_enhancer_and_cross_modality_decoder_96f517aa4d.png)
HuggingFaceを使えば簡単にGrounding DINOを実装できる。この記事のコードは このノートブックにあります。
下の画像からカップケーキを検出したいとしよう。以下のコードでは、Grounding DINOを使ってケーキのバウンディングボックスを取得することができる。
pip install diffusers
インポートリクエスト
インポートトーチ
import os
from PIL import Image
from transformers import AutoProcessor, AutoModelForZeroShotObjectDetection
import numpy as np
from diffusers import AutoPipelineForInpainting
from diffusers.utils import make_image_grid
model_id = "IDEA-Research/grounding-dino-tiny"
processor = AutoProcessor.from_pretrained(model_id)
model = AutoModelForZeroShotObjectDetection.from_pretrained(model_id).to('cpu')
image_url = "<https://farm4.staticflickr.com/3688/9612791241_1484851c78_z.jpg>"
image = Image.open(requests.get(image_url, stream=True).raw)
# ケーキがあるかチェック
text = "ケーキ"
inputs = processor(images=image, text=text, return_tensors="pt").to('cpu')
with torch.no_grad():
出力 = model(**inputs)
results = processor.post_process_grounded_object_detection(
outputs、
input.input_ids、
box_threshold=0.4、
text_threshold=0.3、
target_sizes=[image.size[::-1]].
)
print(results)
"""
出力
{'scores': tensor([0.8716]), 'labels':['a cake'], 'boxes': tensor([[244.4494, 233.1335, 360.1640, 333.2773]])}]。
"""
 接地DINOを使って画像からカップケーキを検出する.png
接地DINOを使って画像からカップケーキを検出する.png
提供された画像からケーキを検出する!
次に、Grounding DINOで検出したオブジェクトをマスキング法で除去する。マスキング法を適用すると、検出されたバウンディングボックスの外側と内側のピクセル値が対比された画像が出力されるはずだ。
left, top, right, bottom = results[0]["boxes"][0].tolist()
left = int(left)
top = int(top)
right = int(right)
bottom = int(bottom)
# 空の黒い画像を作成する
image_url = "<https://farm4.staticflickr.com/3688/9612791241_1484851c78_z.jpg>"
image = Image.open(requests.get(image_url, stream=True).raw)
width, height = image.width, image.height # 画像の寸法は自由に設定できます。
mask = np.zeros((height, width), dtype=np.uint8)
# バウンディングボックス内の領域を白(255)に設定します.
mask[top:bottom, left:right] = 255
mask_image = Image.fromarray(マスク)
 接地DINO.pngで検出された内容をマスクする
接地DINO.pngで検出された内容をマスクする
マスキングされた画像が手に入ったので、次に画像をインペイントするステップを実行しよう。
DALL-Eはオープンソースのモデルではなく、そのAPIを消費することは無料ではないので、以下の例では、このモデルをオープンソースの画像生成モデルに置き換えます。具体的には、HuggingFaceの助けを借りて、画像インペインティングのためのStable Diffusionモデルを実装します。
画像中のカップケーキをコーヒーカップに置き換えたいとします。以下のコードで実現できる:
pipeline = AutoPipelineForInpainting.from_pretrained(
"runwayml/stable-diffusion-inpainting", torch_dtype=torch.float16, variant="fp16"
)
pipeline = pipeline.to("cuda")
generator = torch.Generator("cuda").manual_seed(92)
prompt = "コーヒー、8k"
inpaint_image = pipeline(prompt=prompt, image=image, mask_image=mask_image, generator=generator).images[0].
newsize = (image.width, image.height)
inpaint_image = inpaint_image.resize(newsize)
make_image_grid([image, inpaint_image], rows=1, cols=2)
 安定拡散.pngを使って画像のカップケーキをコーヒーカップに置き換える
安定拡散.pngを使って画像のカップケーキをコーヒーカップに置き換える
以上で、デリバリー・ヒーローが実装している画像のインペインティング・メソッドを再現することができた!
デリバリーヒーローが実装したAI生成画像のクオリティは非常に高い。この方法を使えば、業者が選択できる商品の高品質な食品画像のカタログを推薦することができる。
しかし、食品画像を生成する過程で、1つの重大な問題に遭遇する。この問題については次のステップで説明する。
安全システムの構築
前のセクションで説明した洗練された画像生成アプローチは、テキストプロンプトに依存しています。これは、画像生成モデルがこちらの意図を誤解することがあることを意味する。
例えば、皿に盛られた鶏肉の料理画像を生成したいとします。安全制御がなければ、モデルは次のように画像を生成するかもしれない:
私たちが欲しい画像とAIが安全制御なしで生成した画像の比較.png](https://assets.zilliz.com/The_image_we_want_vs_the_image_generated_by_AI_without_any_safety_control_58495105f5.png)
したがって、モデルによって生成される画像の品質を制御するコンポーネントが必要です。そこで、安全システムの出番となる。
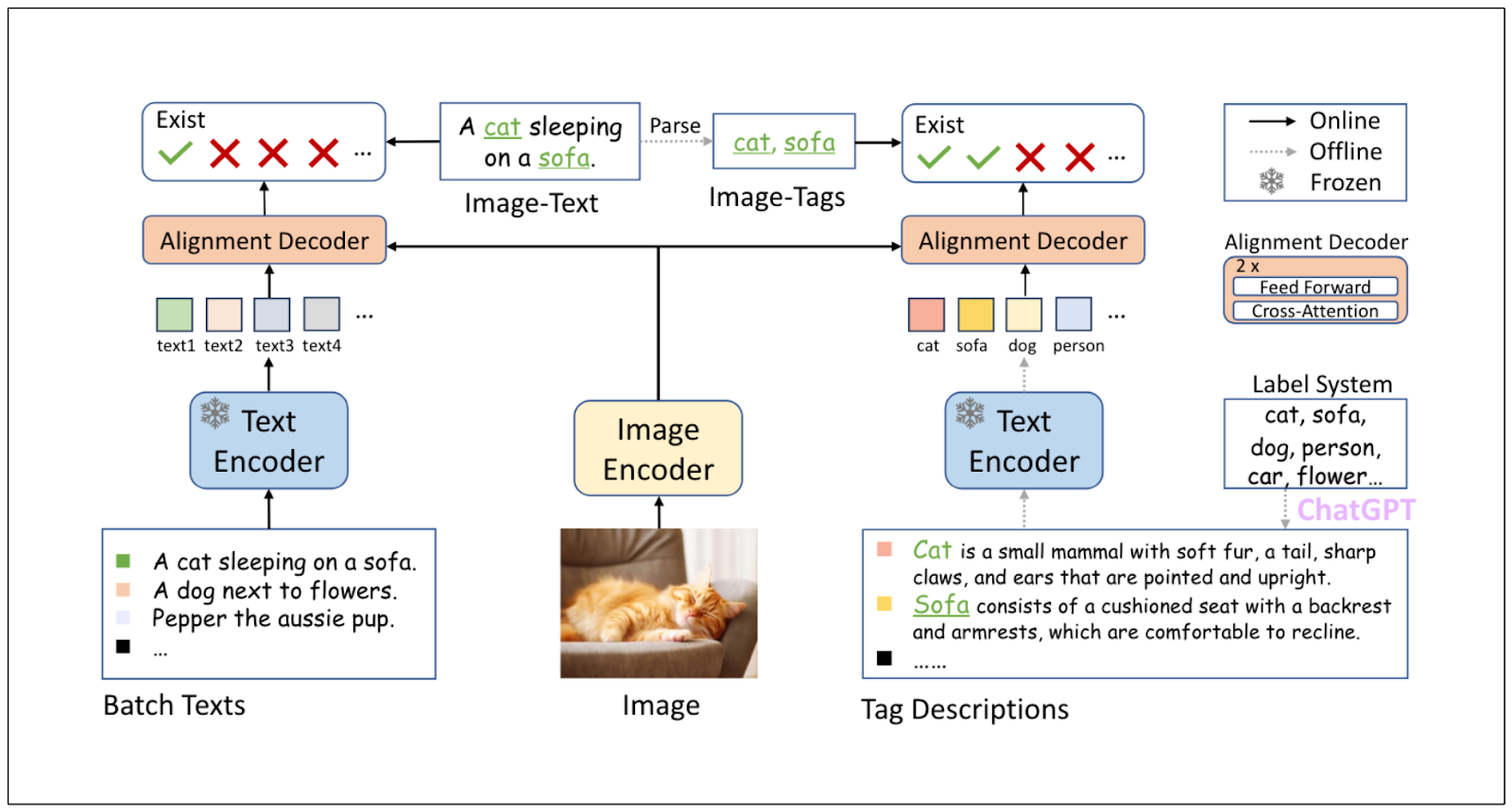
デリバリーヒーローは、4つのコンポーネントに基づいて安全システムを実装しています:画像タグ付け、画像センタリング、テキスト検出、画像シャープネスです。ミートアップのプレゼンテーションでは、デリバリーヒーローのチームは2つのコンポーネントに焦点を当てました:**画像タグ付けと画像センタリングです。
画像タグ付け
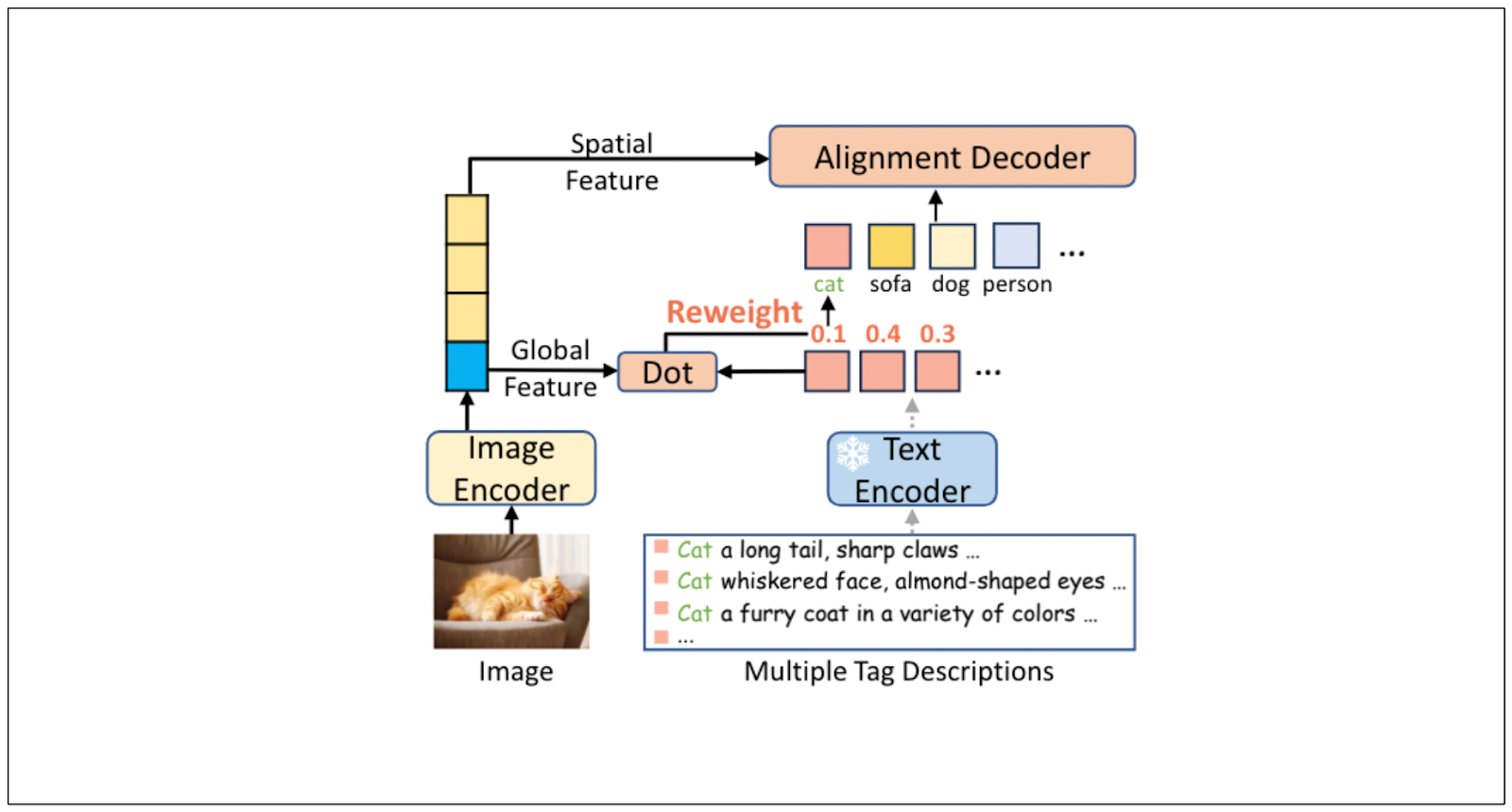
デリバリーヒーローが安全システムとして実装した最初のアプローチは、画像生成モデルによって生成された画像へのタグ付けである。画像タグ付けとは、機械学習モデルの助けを借りて画像のタグを予測するプロセスを指す。この目的のために、デリバリーヒーローはRecognize-Anything Plus Model(RAM++)と呼ばれるモデルを利用しました。
RAM++は、卓越したゼロショット汎化機能を備えた強力な画像タグ付けモデルです。LLMの統合により、4,585のユニークなタグを認識することができます。
RAM++は、学習プロセスにおいて、画像、テキスト、タグの3つの異なる入力を受け取ります。テキストとタグを組み合わせることで、画像から推測できる視覚的概念の範囲が広がります。モデルの汎化性をさらに向上させるために、RAM++はChatGPTを利用して、5つの異なるプロンプトに基づいて各タグのさまざまな種類の説明を作成します:
タグ}がどのように見えるかを簡潔に説明してください。
a(n) {タグ}がどのようなものか簡潔に説明してください。
a(n) {tag}はどのように見えますか?
a(n) {tag}の識別された特徴は何ですか?
タグ}の視覚的特徴を簡潔に説明してください。
 画像タグ付け-タグからテキストへ:RAM:RAM++アーキテクチャ .png
画像タグ付け-タグからテキストへ:RAM:RAM++アーキテクチャ .png
GPT3.5ターボによって生成されたこれらのタグ記述は、各タグの意味的な意味を拡大し、したがって、画像の視覚的な概念の範囲を向上させます。
次に、テキストとタグ記述はテキストエンコーダに渡され、画像は画像エンコーダに渡されます。これらのエンコーダーの結果は、クロスアテンションレイヤーとフィードフォワードレイヤーから構成される、いわゆるアライメントデコーダーブロック内で融合され、画像の最終タグが生成される。
RAM++を実装して画像タグを生成するには、まずrecognize-anythingライブラリをインストー ルしてから、コマンドラインを使って画像タグを生成する必要があります。次の例では、前のセクションで使用した画像タグを予測します。
git clone <https://github.com/xinyu1205/recognize-anything.git>
cd recognize-anything
!pip install -e .
if not os.path.exists('pretrained'):
os.makedirs('pretrained')
if not os.path.exists('images'):
os.makedirs('images')
# swin 変換チェックポイントをダウンロードする
!wget <https://huggingface.co/xinyu1205/recognize-anything-plus-model/resolve/main/ram_plus_swin_large_14m.pth> -O pretrained/ram_plus_swin_large_14m.pth
# 入力画像のダウンロード
!wget <https://farm4.staticflickr.com/3688/9612791241_1484851c78_z.jpg> -O images/cupcake_and_coffee.jpg
cd recognize-anything
# 画像タグの推論
!python inference_ram_plus.py --image images/cupcake_and_coffee.jpg ˶-̀ㅂ-́)و ̑̑ !
--pretrained pretrained/ram_plus_swin_large_14m.pth
上のコマンド例では、画像エンコーダとしてSwin-Transformerモデルを使用しています:
Swin-Transformerモデルによって生成されたタグ.png](https://assets.zilliz.com/The_tags_generated_by_the_Swin_Transformer_model_70a8744a51.png)
ご覧のように、画像には "飲料"、"布"、"コーヒー"、"コーヒーカップ"、"カップ"、"カップケーキ"、"テーブル"、"ダイニングテーブル"、"皿 "などのタグが生成されます。
全4585のタグカテゴリの中から、Delivery Heroのデータサイエンティストは10の「食べ物」タグと50の「ネガティブ」タグを特定した。ネガティブ "タグには、"バグ"、"カブトムシ"、"アリ"、"スズメバチ "など、動物に関連するタグがいくつか含まれている。
 スウィン・トランスフォーマーモデルによる画像タグ付け.png
スウィン・トランスフォーマーモデルによる画像タグ付け.png
次に、RAM++モデルによって予測されたタグに基づいて、AIが生成した各食品画像にスコアを割り当てた。
画像に少なくとも1つの「食べ物」タグが含まれ、「ネガティブ」タグが含まれない場合、スコアは1となる。
画像に「否定的」タグが含まれている場合、スコアは0となる。
画像のセンタリング
AIが生成した画像の安全性を高めるために、デリバリーヒーローのデータサイエンティストによって実装されたもう1つのコンポーネントが、画像のセンタリングである。このコンポーネントでは、生成された画像の比率が評価される。すでにご存知かもしれないが、画像の中心にある食べ物は、端にあるものや画像から切り取られたものよりも魅力的である。
画像のプロポーショナリティを評価するために、Delivery Heroは前節で説明したグラウンディングDINOを利用して画像内の料理オブジェクトを検出する。そして、モデルによって生成されたバウンディングボックスを評価し、画像の品質を決定する。
スコアリングシステムは以下の通りである:
食べ物や皿のオブジェクトが検出されなければ0
バウンディングボックスが画像エッジに接している場合は0.5
バウンディングボックスが画像の中央にある場合は1
最後のステップは、各コンポーネントのスコアを重み関数で結合することです。最後に、各画像は4つの成分から加重されたスコアを持つ。しきい値を適用することで、重み付けスコアがそのしきい値以下の画像はフィルタリングされ、ベンダーに推奨されなくなる。
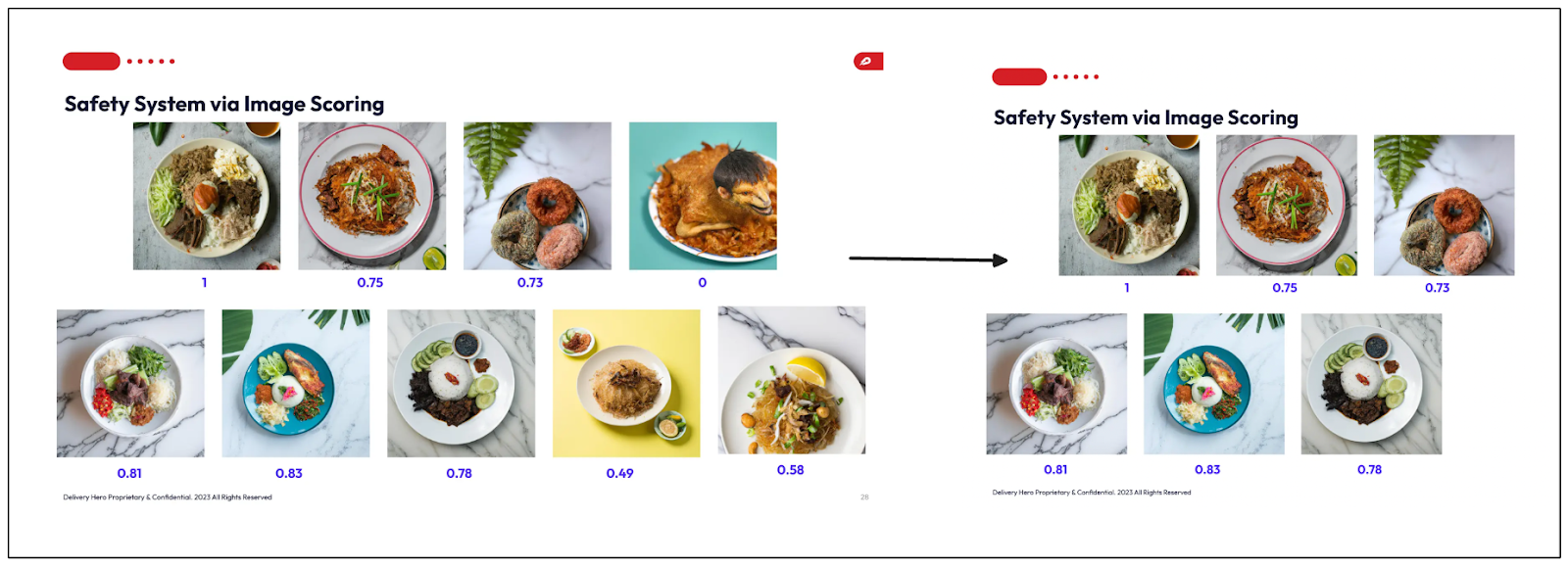 画像スコアリング.png
画像スコアリング.png
結論
この記事では、Delivery Heroの2人のデータサイエンティストが、AIモデルを使用して高品質の料理画像を生成し、ユーザー体験とコンバージョン率を向上させる方法について説明した。彼らのアプローチは、食品画像の生成と安全システムの構築という2つの段階から構成されている。
彼らは画像を生成するためにOpenAIのDALL-Eを使用し、Grounding DINOとDALL-Eの助けを借りて画像インペインティング手法を実装した。生成された画像の安全性を判断する最終的なスコアを生成するために、画像タグ付け、画像センタリング、テキスト検出、画像シャープネスの4つの要素を採用した。これら4つの要素から得られたスコアを重み付け関数で組み合わせ、各画像に最終的なスコア値を1つ与える。閾値を適用することで、最終スコアが閾値を下回る画像はフィルタリングされ、ベンダーに推奨されなくなります。
この記事で示したコードには、 このノートブック からアクセスできます。
YouTube](https://www.youtube.com/watch?v=7T-y_KaQbuY&t=2323s)で、Delivery Heroチームのトークのリプレイを見ることができる。

読み続けて

The Real Bottlenecks in Autonomous Driving — And How AI Infrastructure Can Solve Them
Autonomous driving faces a data bottleneck. Learn how AI-native vector databases like Zilliz solve scale, cost, and insight challenges across AV pipelines.

Democratizing AI: Making Vector Search Powerful and Affordable
Zilliz democratizes AI vector search with Milvus 2.6 and Zilliz Cloud for powerful, affordable scalability, cutting costs in infrastructure, operations, and development.

The Great AI Agent Protocol Race: Function Calling vs. MCP vs. A2A
Compare Function Calling, MCP, and A2A protocols for AI agents. Learn which standard best fits your development needs and future-proof your applications.