




テキストからイメージへ:CLIPの基礎
ニュース速報:ティーンエイジャーがお気に入りの検索エンジンとして](https://www.theverge.com/23365101/tiktok-search-google-replacement)TikTokを利用している。従来の検索エンジンでは必ずしも欲しいものが見つかるとは限らないので、これは驚くべきことではない。特に私のような視覚的な人間であれば、テキストの行を這いずり回るよりも、画像や動画の方がずっと直感的で楽しいと感じるだろう。しかし、機械がどのように与えられたテキストを理解し、返された画像と照合しているのか、不思議に思ったことはないだろうか?
このブログシリーズでは、テキストを基に画像を検索する、つまりテキストから画像へのサービスをご紹介します。テキストから画像への変換は、常に重要なクロスモーダル・アプリケーションであり、業界は、画像をグループ化し、それらの意味的関係を見つけるために、膨大な量のユーザー生成データを必要とする回りくどいソリューションに頼っていた。しかし昨年、OpenAIがCLIPをリリースし、業界に衝撃を与えた。オープンAIは、自然言語入力に基づいて視覚的概念を学習できるように、CLIPを構築するために4億という驚異的な数のテキストと画像のペアを使用した。 ここで、検索アルゴリズム、CLIP、テキストから画像への変換の基本的な構成要素を理解するために、いくつかの基本的な知識について知っておく必要がある。
検索アルゴリズムと意味的類似性
検索アルゴリズムは、それが伝統的なものであれ新しい流派のものであれ、あるいはユニモーダルであれクロスモーダルであれ、意味的類似性の尺度、いやむしろ2つのものの間の意味的距離なしには成り立たない。少し抽象的に聞こえるかもしれないので、いくつかの例を見てみよう。 おそらく小学校の頃からDNAに刻まれているであろう(当時はそのような言い方はしなかっただろうが)整数の一次元空間から始めよう。今、5つの正の整数{1, 5, 6, 8, 10}がある。はい、6です。子供卒業おめでとう。ここでいう距離とは、5と6の間の意味上の距離のことである。
図1 整数の一次元空間](https://assets.zilliz.com/towhee1_figure1_7f3f595b15.png)
さて、機械学習に入ったところで、少し前進して、従来のテキスト検索がどのように行われているかを見てみよう。テキスト検索をやったことがある人と話すと、TF-IDFという言葉をよく耳にするだろう。TFとは用語頻度、つまり単語頻度のことである。辞書の単語の数だけ次元の高い空間があるとする。記事中の各単語の出現回数を数え、この数をこの空間の対応する次元の値とすると、この単語ベクトル空間上の疎なベクトルの分布として、あらゆる記事を記述することができる(記事は通常、辞書中の単語のごく一部しかカバーしていないため、疎なのである)。
図2 単語ベクトル空間のデモ](https://assets.zilliz.com/towhee1_figure2_d11a59c3dc.png)
これは非常にシンプルで実用的な考え方である。上に示したように、2つの記事がその分野や内容において類似している場合、これらの2つの記事に対応するベクトルは、単語ベクトル空間においてそれほど離れていないはずである。テキスト検索では、最初の例の1次元の正の整数空間を高次元の単語ベクトル空間に拡張するが、基本的には同じアプローチである:データのセマンティクスを記述するために使用できる空間を定義し、それらの間の距離を決定する。
もう1つ小さなステップを踏もう(そう、こうなることは予想できたはずだ)。テキストができたのだから、画像の意味論も単語ベクトル空間にマッピングして、テキストと画像のクロスモーダリティを実現してはどうだろう?
しかしもちろん、そう簡単にはいかない。テキストは基本的に、意味論を無償で提供してくれている。彼らは自然な意味単位として「言葉」を持っている。画像にはそれがない。個々のピクセルを使って意味を定義することはできない。
自然な意味単位を持たないベクトル化のパズルは、かつて画像検索や非構造化データ全般の分野を悩ませていた。ほとんどのデータタイプ(画像、ビデオ、オーディオ、点群など)には自然な意味単位がない。データとコンピューティングパワーが十分に安価になり、ニューラルネットワークが普及するまで、この問題を効果的に解決することはできなかった。この問題がニューラルネットワークによってどのように解決されるかを見てみよう。
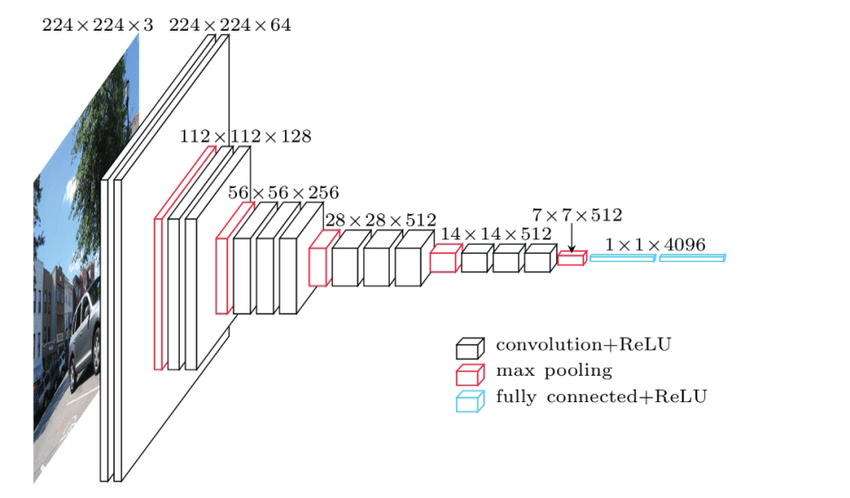
図3 畳み込みニューラルネットワークの層とアーキテクチャ](https://www.researchgate.net/publication/333242381_Convolutional_Neural_Network_Layers_and_Architectures)
ディープ・ニューラル・ネットワークの大きな特徴の1つは、「十分に深い」ことである(You're welcome)。上の図では、左の入力は224 x 224の画像で、右の出力は4096次元のベクトルです。左から右へ、画像は多くのニューラルネットワーク層を通過し、ニューラルネットワークは元の画像のピクセルの空間情報を意味情報に徐々に圧縮していく。この過程で、空間的な次元は狭くなっているが、意味的な次元は長くなっていることがわかる(最も正確な表現ではないが、他に良い表現が見つからない)。基本的に、この処理は画像の意味論を4096次元の実ベクトル空間にマッピングするものである。先に説明したテクニックと比べると、ディープニューラルネットワークを介したベクトル化にはいくつかの明らかな利点がある:
- 元のデータが「単語」のような自然で直接分割可能な意味単位を持っている必要はない。
- データの類似性」の定義は柔軟で、学習データと目的関数によって決定され、アプリケーション固有の特徴に合わせてカスタマイズできる。
- データのベクトル化処理はモデルの推論処理であり、主に行列演算を含み、最新のGPUの高速化機能を利用することができる。
CLIPが行ったのは、テキストと画像をクロスモーダルに接続することだ。データ側では、OpenAIがテキストと画像のペアの大規模データセットWIT(WebImageText)を開発した。このモデルは、画像とテキストがペアになるかどうかを予測するコントラスト学習アプローチを使って学習される。その設計はいたってシンプルだ: 1.1.テキストと画像をそれぞれ特徴エンコードする; 2.2.テキストと画像の特徴をそれぞれのユニモーダル特徴空間からマルチモーダル特徴空間に投影する; 3.3.マルチモーダル空間内では、対になるはずのテキストと画像の特徴ベクトル間の距離(正サンプル)は可能な限り近く、負サンプルはその逆であるべきである。
図4 自然言語スーパービジョンからの伝達可能な視覚モデルの学習。画像出典:https://arxiv.org/pdf/2103.00020.pdf](https://assets.zilliz.com/towhee1_8eba493fc7.png)
ここで重要なのは2番目のステップで、投影層を通してテキストと画像からユニモーダルな特徴をマルチモーダルな特徴空間に投影することである。つまり、画像とテキストの意味論を同じ高次元空間にマッピングすることができる。この意味空間は、CLIPがテキストと画像のクロスモーダル検索のために用意しているブリッジである。これで、説明的なテキストの一部をベクトルとして符号化し、類似した意味論を持つ画像のベクトルを見つけ、これらの画像ベクトルを通して、欲しい元の画像を見つけることができる!
全体としては、ベクトル空間+意味的類似性という古典的な公式と同じである。CLIPの重要性は、テキストと画像の意味論を統一した高次元空間を作ることができる点にあり、テキストと画像の意味論が近ければ近いほど、対応するベクトル間の距離は小さくなる。
テキスト画像変換サービスの基本構成要素
典型的なテキスト画像変換サービスは、リクエスト側(テキスト)、検索アルゴリズム("to")、基礎となるデータベース(画像)の3つの部分を含んでいる。
データベースには、元画像、そのベクトル、元画像を意味ベクトルにエンコードする推論モデルが含まれる。これに対応して、リクエスト側は主にテキストを意味ベクトルにエンコードする推論モデルを含む。
to」の部分は、リクエスト、ベクトルデータベース、画像データベースをつなぐ処理である。リクエスト側からのテキストは、そのベクトル用のモデルに渡され、ベクトルデータベースで最も類似した上位K個の画像ベクトルが比較される。プログラムがベクトルに対応する元画像を見つけると、結果が返される。
図5 テキスト画像変換サービスの基本構成要素](https://assets.zilliz.com/towhee1_figure5_724ad412f0.png)
結論
これで、テキストから画像への検索とCLIPの基本がわかりました!次回は、ここで学んだことを実践するために、わずか5分でテキストから画像へのサービスのプロトタイプを作ります!
この記事が気に入ったら、私たちのprojectを見てみませんか?星やフォーク、あるいはちょっとしたクリックでも結構です。Slack](https://slack.towhee.io/)でもお気軽にご質問ください!
シリーズについて
"テキストから画像へ "は、CLIPを使って大規模なテキストから画像へのサービスを構築する方法を紹介する一連のブログです:
- 検索アルゴリズム、CLIP、テキストから画像への理解を深める;
- 5分でテキストから画像へのデモを構築する;
- アドバンストピック1:大規模ベクトルリコールのためのベクトルデータベースの導入
- 高度なトピック2:1000 QPSを超える推論リクエストを処理できる推論サービスの導入
- トピック3:ベクトルデータの圧縮

{kind=link}
読み続けて

Data Deduplication at Trillion Scale: How to Solve the Biggest Bottleneck of LLM Training
Explore how MinHash LSH and Milvus handle data deduplication at the trillion-scale level, solving key bottlenecks in LLM training for improved AI model performance.

Build for the Boom: Why AI Agent Startups Should Build Scalable Infrastructure Early
Explore strategies for developing AI agents that can handle rapid growth. Don't let inadequate systems undermine your success during critical breakthrough moments.

Introducing DeepSearcher: A Local Open Source Deep Research
In contrast to OpenAI’s Deep Research, this example ran locally, using only open-source models and tools like Milvus and LangChain.