




LLM幻覚の解読:言語モデルのエラーを深く掘り下げる
#はじめに
企業や大手ハイテク企業が大規模な言語モデル(LLMを使ってより良い製品を作るとき、信頼できるソリューションを提供する責任を理解することが重要である。重大な問題は、これらのモデルが時として確信に満ちた誤った情報を出力し、ユーザーにその出力が正確であると誤解させることである。この問題は幻覚として知られている。
データ・サイエンティストのMorenaは、Zillizが最近主催したUnstructured Data Meetupで、LLMの幻覚について洞察に満ちたプレゼンテーションを行った。幻覚の概念、幻覚の種類、幻覚がどのように有害であるか、なぜ幻覚が起こるのか、そして最も重要なことは、どのようにして幻覚を検出できるかについて詳しく説明した。
幻覚とは何か?
幻覚とは、あらゆる形式の言語モデルによって生成される、誤った、あるいは矛盾した出力のことである。簡単に言えば、事実に反していたり、無意味であったり、入力された「文脈」に対して不誠実であったりする「内容」である。
例えば、Llama3に複雑な質問をしてみよう:**State Software社の共同設立者は、JSONについて他にどんな名前を議論していたのでしょうか?
Llama3の答えは以下の通りだ:
例の質問に対するLlama3の答え](https://assets.zilliz.com/Llama3_s_answer_to_the_example_question_00c6723577.png)
一方、実際の議論はやや異なっている:
JSONに関するWikipediaのページの答え](https://assets.zilliz.com/The_answer_on_the_Wikipedia_page_about_JSON_5bc0464797.png)
ラマ3-8Bは幻覚の典型的な例を示している。言語モデルが与える幻覚の種類を調べてみましょう。
幻覚の種類
幻覚には大きく分けて、内発的幻覚と外発的幻覚の2種類がある。
内発的幻覚
内発的な幻覚は、与えられた情報源と対比する傾向がある。複雑で膨大な理解力テストの問題を急いで解こうとしている自分を想像してみよう。あなたは情報を間違えて、いくつかの問題を不正解にするかもしれない。同様に、LLMは、膨大なテキストコーパスのように、データが非常に非構造的である場合に、頻繁に幻覚を見る傾向がある。
外在的幻覚
外在的な幻覚は、LLMが提供されたソース・データと照合して検証できない情報を 生成するときに発生します。外在的な幻覚を効果的に管理するには、LLMに与えられた情報をタスクの完了にのみ使用するよう促す。このアプローチは、検索支援型生成(RAG)パイプラインにおいて特に有益である。Laurie VossはZilliz Unstructured Data Meetupでこの実践を強調し、精度を維持する上での重要性を強調した。
以下は、外在的な幻覚に対処するためのプロンプトの例である。
prompt = f"""外部の知識ではなく、あなたに提供されたコンテキストのみを使用して、ユーザークエリに答えてください。
コンテキスト{ウィキペディア_ページ_コンテンツ}。
クエリ このページを要約してください"""
# むしろ
prompt = f"""このページを要約してください。
{Wikipedia_Page_Content}"""
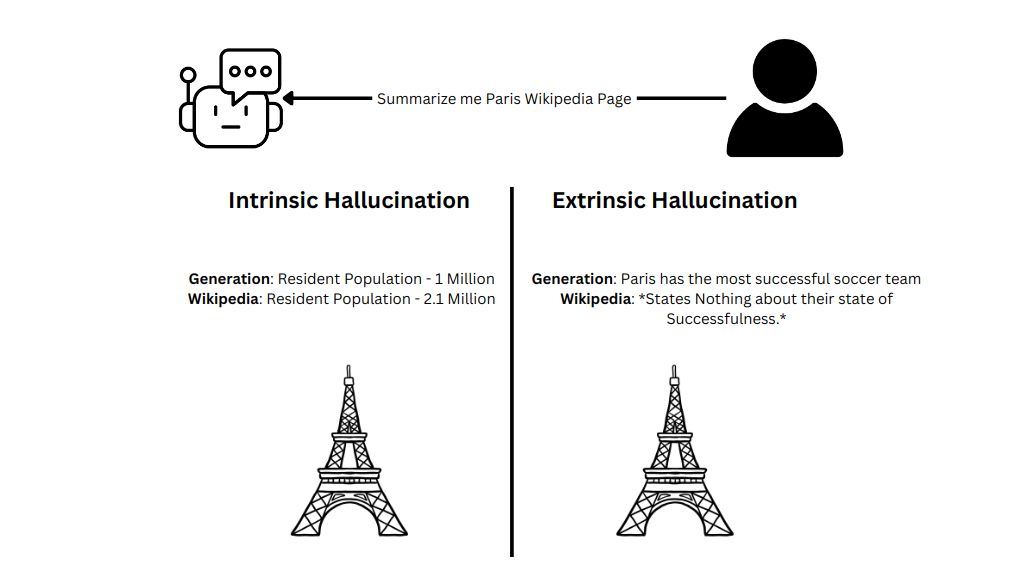 本質的幻覚と外在的幻覚の例
本質的幻覚と外在的幻覚の例
LLM 幻覚の問題点
当初は無害、あるいはユーモラスにさえ見える幻覚も、法律や医療などの業界でLLMを導入する際には重大な問題を引き起こす。これらの分野では、生成AIモデルによって生成される情報の正確性が、肯定的な結果を保証するために重要である。これらのモデルが不正確なアウトプットを生成すると、誤った法的判断や患者ケアの低下といった深刻な結果を招き、生命を危険にさらす可能性がある。
さらに、LLMによって生成される幻覚は、特定の産業への影響にとどまらず、社会的に広範な影響を及ぼす可能性がある。LLMは信頼できる情報源に対する信頼を損ない、一般市民の間に混乱と不信を蔓延させる。このような信頼の低下は、選挙のような重要なイベント時には特に大きなダメージを与える。
例えば選挙期間中、LLMによって候補者、投票手続き、選挙結果について誤った情報が流布されると、民主主義のプロセスに大きな影響を与える可能性がある。誤った情報は、投票場所や投票時間について有権者に誤解を与え、投票率を抑制し、選挙結果に影響を与える可能性がある。さらに、不正選挙という根拠のない主張が抗議行動や対立を引き起こした状況に見られるように、誤った情報は緊張をエスカレートさせ、社会不安や暴力につながる可能性さえある。
なぜLLMは幻覚を見るのか?
LLMの出力は、行列の乗算やソフトマックス関数のような複雑な数学的演算によって決定され、先行するトークンに基づいてシーケンスの各トークンの確率を計算する。これらの確率がLLMによって生成されるシーケンスを決定するが、何がこれらの確率に影響を与えるのだろうか?
与えられた文字列に対するトークンの確率](https://assets.zilliz.com/Token_probabilities_for_a_given_string_d1dc2ced0b.png)
学習データにおける矛盾または偽情報
Foundationモデルは、Wikipediaページ、subreddits、ツイート、Stack OverflowやMathOverflowのスレッド、GitHubリポジトリ、その他多数のインターネットソースを含む、膨大な量の非構造化データでトレーニングされる。このトレーニングは、モデルが最初から意味のある出力を生成することを目的としているのではなく、テンソルとして保存された基礎知識を構築し、首尾一貫した出力を生成する。
しかし、インターネット上にあるすべてのデータが正確なわけではない。特定のサブレディットやツイートのような誤った情報や誤解を招くようなコンテンツは、トレーニング中にモデルに影響を与える可能性がある。この問題は、モデルの重みに矛盾をもたらし、歪んだ確率分布をもたらし、最終的に出力に幻覚を引き起こす。
タスクの複雑さ
タスクの性質も、LLMが誤った出力や無意味な出力を出しやすいかどうかに影響する。簡単な質問に答えるような単純なタスクは、幻覚を見 る可能性は低い。しかし、広範なテキストを要約したり、マークダウン形式で提供される表データを分析したりするような、より複雑なタスクに直面すると、LLMは苦戦し、非常に無意味な出力を生成する可能性がある。
単純なタスクと複雑なタスク](https://assets.zilliz.com/Simple_vs_Complex_Task_133e01b717.png)
幻覚の検出
LLM幻覚の検出には、自己評価、参照に基づく検出、不確実性に基づく検出、一貫性に基づく検出など、いくつかの方法論が用いられている。これらの方法論のいくつかを詳しく調べてみよう。
幻覚検出法](https://assets.zilliz.com/Hallucination_detection_methods_d1f02a40c3.png)
自己評価
自己評価はLLMがその出力を評価するプロセスであり、幻覚はしばしばモデル内部で発生することを考えると、最初は直感に反するように思えるかもしれない。しかし、応答の質を評価することは、応答そのものを生成するよりも本質的に簡単であるため、この方法は依然として価値がある。回答評価のような単純なタスクは、複雑なクエリに対する回答生成のような複雑なタスクよりも幻覚を起こしにくい。これは、LLMが応答の正しさと一貫性を評価する能力は、まったく新しい情報を正確に生成する能力よりも難易度が低いからである。
さらに、自己評価を参照ベースや一貫性ベースのアプローチなどの他の検出手法と統合することで、LLMの出力を総合的に評価する能力が高まる。このようなアプローチを組み合わせることで、潜在的な幻覚を効果的に識別・軽減するモデルの能力が強化され、生成されるコンテンツの全体的な信頼性と信憑性が向上する。
LLMの自己評価のための基本的なワークフロー](https://assets.zilliz.com/A_basic_Workflow_for_LLM_s_Evaluating_themselves_1002a23f3a.png)
参照ベースの方法
参照ベースの方法論は、提供された参照に対して生成された出力の一貫性を評価し、検索拡張生成(RAG)や要約のようなタスクを利用する生産環境において特に有用である。
ソース知識を参照として提供することで、LLMは与えられた参照と密接に一致する出力を生成することができる。パリに関するウィキペディアのページを要約するタスクを考えてみよう。参照ベースの手法を使うことで、LLMは元のコンテンツと比較して評価された要約を生成し、正確さと一貫性を確保することができる。
BERTScoreやROUGEScoreのようなパフォーマンスメトリクスは、特定のタスクにおけるLLMのパフォーマンスを評価するために一般的に使用される。これらの指標は、生成された出力がどの程度参考文献と一致しているかを定量的に評価するものである。さらに、自己評価レイヤーを組み込むことで、参照ベースの評価手法の信頼性と有効性がさらに高まる。
コンテキストに基づく検索のための体系的ワークフロー](https://assets.zilliz.com/A_Systematic_Workflow_for_Context_Based_Retrieval_ea68d4f032.png)
不確実性に基づく方法
以前、LLMが自信満々に誤った出力をするのを観察したことを覚えているだろうか?さて、幻覚に関しては、水面下では必ずしもそうとは限らない。幻覚は、トークンが「最良」のグランドトゥルーストークンよりもわずかに上位にランクされる不確実な確率分布のために発生する可能性があり、出力の誤った生成につながります。
トークンの確率を分析するには、Hugging Face class methodsを活用することができます。これらのメソッドにより、トークン生成に関連する確率を調べることができ、モデルがどのように決定を下すかについての洞察を提供し、幻覚が発生するインスタンスを特定できる可能性があります。
from transformers import GPT2Tokenizer, AutoModelForCausalLM
np として numpy をインポートする。
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
model = AutoModelForCausalLM.from_pretrained("gpt2")
tokenizer.pad_token_id = tokenizer.eos_token_id
入力 = tokenizer(["Today is"], return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=5, return_dict_in_generate=True, output_scores=True)
transition_scores = model.compute_transition_scores(
outputs.sequences, outputs.scores, normalize_logits=True
)
input_length = inputs.input_ids.shape[1]
Generated_tokens = outputs.sequences[:, input_length:] (生成されたトークン)
for tok, score in zip(generated_tokens[0], transition_scores[0]):
# トークン|トークン文字列|ロジット|確率
print(f"| {tok:5d}.| {tokenizer.decode(tok):8s}.| {score.numpy():.4f}.| {np.exp(score.numpy()):.2%}")
# 期待される出力
#| 262 | その | -1.4136 | 24.33
#| 1110|日|-2.6089|7.36パーセント
#| 618 | いつ | -2.0096 | 13.40
#|356|we|-1.8593|15.58
#|460| カン|-2.5083|8.14% #|460| カン|-2.5083|8.14
logprobs](https://platform.openai.com/docs/api-reference/chat/create?lang=python)を使って、gpt-4のようなクローズドソースのモデルでこの方法を試すことができる。
from openai import OpenAI
クライアント = OpenAI()
完了 = client.chat.completions.create(
model="gpt-4o"、
メッセージ=[
{"role":"user", "content":"こんにちは!}
],
logprobs=True、
top_logprobs=2
)
print(completion.choices[0].logprobs)
logprobsの出力は以下のJSONのようになる。
{
"id":"chatcmpl-123"、
"object":"chat.completion"、
"created":1702685778,
"model":"gpt-4o"、
"選択肢":[
{
"index":0,
"message":{
"role":"assistant": "アシスタント"、
"content":"こんにちは!"
},
"logprobs":{
"content":[
{
"token":"Hello": "こんにちは"、
"logprob":-0.31725305,
「bytes":[72, 101, 108, 108, 111],
「top_logprobs":[
{
"token":Hello": "こんにちは"、
"logprob":-0.31725305,
「bytes":[72, 101, 108, 108, 111]
},
{
"token":"Hi"、
"logprob":-1.3190403,
「bytes":[72, 105]
}
]
},
{
"token":"!",
"logprob":-0.02380986,
「bytes":[
33
],
「top_logprobs":[
{
"token":"!",
"logprob":-0.02380986,
「bytes":[33]
}]
}, "finish_reason":"停止"
}
],
"usage":{
"prompt_tokens":2,
「completion_tokens": 2:2,
"total_tokens":4
},
"system_fingerprint": null
}
一貫性に基づく検出
一貫性に基づく検出は、LLMの幻覚を識別するための簡単かつ効果的な方法である。この方法では、LLMに同じ質問を複数回問い合わせ、その応答を比較する。繰り返されるクエリで一貫性のある出力が得られれば、幻覚の可能性は低くなり、一貫性のない応答が得られれば、潜在的な問題があることが示唆される。
以下は、モレーナが講演で話した例で、彼はLLMに3つの質問を繰り返した。
ronaldo_prompt = "クリスティアーノ・ロナウドについて3つの事実を教えてください"
toaster_prompt = "トースターに関する不条理な事実を教えてください"
seinfeld_prompt = "『となりのサインフェルド』でクレイマーが巨大な帽子を買ったエピソードは?"
プロンプトの設定
ronaldo_passages = [].
for i in range(3):
prompt = ronaldo_prompt
result = chat_gpt_prompt(prompt).choices[0]-message.content
ronaldo_passages.append(結果)
トースター_パッセージ = [].
for i in range(3):
prompt = toaster_prompt
result = chat_gpt_prompt(prompt).choices[0].message.content
toaster_passages.append(result)
seinfeld_passages = [].
for i in range(3):
prompt = seinfeld_prompt
result = chat_gpt_prompt(prompt).choices[0].message.content
seinfeld_passages.append(result)
この例では、クリスティアーノ・ロナウドに関するクエリは、その情報がLLMトレーニングデータに組み込まれているため、幻覚のリスクを最小限に抑えながら、一貫した出力が得られる傾向があります。この一貫性は、確立されたトピックに対する正確な応答を生成するモデルの信頼性を示している。
クリスティアーノ・ロナウドについてLLMが生成した回答](https://assets.zilliz.com/The_answer_generated_by_the_LLM_about_Cristiano_Ronaldo_81a76a5b7e.png)
しかし、『となりのサインフェルド』の場合、クレイマーは "ジャイアント・ハット "を買っていないので、ケースは異なる。
ジャイアントハットについてLLMが生成した答え](https://assets.zilliz.com/The_answer_generated_by_the_LLM_about_Giant_Hat_19707c3a3f.png)
結論
より多くの企業が大規模言語モデル(LLM)をプロダクション・アプリケーションに使用するにつれ、その課題に一貫して取り組むことが不可欠になっている。幻覚は放っておくと、どんどん有害になっていきます。幻覚の起源、トリガー、検出戦略を理解することで、その影響を最小限に抑えることができる。
この記事では、幻覚の概念とその潜在的な引き金について探ってきた。さらに、幻覚を検出するための4つの実用的な方法、すなわち自己評価、参照に基づく方法、不確実性に基づく方法、一貫性に基づく検出を紹介した。これらの方法は異なるユースケースに対応し、組み合わせることで幻覚検出の精度を高めることができる。
異なる幻覚検出法を比較する](https://assets.zilliz.com/Comparing_different_hallucination_detection_methods_57c3afba82.png)
これらのアプローチを導入することで、LLMやその他の生成AI技術の責任ある展開が保証され、社会への肯定的な影響を最大化することができる。

読み続けて

Smarter Autoscaling in Zilliz Cloud: Always Optimized for Every Workload
With the latest upgrade, Zilliz Cloud introduces smarter autoscaling—a fully automated, more streamlined, elastic resource management system.

Democratizing AI: Making Vector Search Powerful and Affordable
Zilliz democratizes AI vector search with Milvus 2.6 and Zilliz Cloud for powerful, affordable scalability, cutting costs in infrastructure, operations, and development.

Vector Databases vs. Object-Relational Databases
Use a vector database for AI-powered similarity search; use an object-relational database for complex data modeling with both relational integrity and object-oriented features.