




ベクトル・インデックスによるビッグデータの類似性検索の高速化
コンピュータ・ビジョンから新薬の発見に至るまで、ベクトル類似性検索エンジンは、多くの一般的な人工知能(AI)アプリケーションに力を与えている。類似性検索エンジンが依存する100万、10億、あるいは1兆のベクトルデータセットへの効率的なクエリを可能にする大きな要素は、ビッグデータ検索を劇的に加速するデータ整理プロセスであるインデックス作成です。この記事では、ベクトル類似検索の効率化においてインデックス作成が果たす役割、さまざまなベクトル転置ファイル(IVF)インデックスタイプ、さまざまなシナリオでどのインデックスを使用すべきかについてのアドバイスを取り上げます。
へのジャンプ:*。
- ベクトルインデックスは類似性検索と機械学習をどのように加速させるのか](#how-does-vector-indexing-accelerate-similarity-search-and-machine-learning)
- IVFインデックスにはどのような種類があり、どのようなシナリオに最適か](#What-are-different-types-of-IVF-indexes-and-which-scenarios-are-they-best-suited-for)
- フラット:比較的小規模な(100万人規模の)データセットを検索するのに適しており、100%の再現率が要求される場合](#flat-good-for-searching-relatively-small-million-scale-datasets-when-100-recall-is-required)
- IVF_FLAT:精度を犠牲にする代わりに速度を向上させる](#ivf_flat-improves-speed-at-the-expense-of-accuracy-and-vice-versa)
- IVF_SQ8:IVF_FLATよりも高速でリソースを消費しないが、精度も劣る](#ivf_sq8-faster-and-less-resource-hungry-than-ivf_flat-but-also-less-accurate)
- IVF_SQ8H:IVF_SQ8よりもさらに高速な新しいGPU/CPUハイブリッドアプローチ](#ivf_sq8h-new-hybrid-gpucpu-approach-that-is-even-faster than-ivf_sq8)
- 大規模ベクトルデータ管理プラットフォームMilvusの詳細](#learn-more-about-milvus-a-massive-scale-vector-data-management-platform)
ベクターインデックスは類似検索や機械学習をどのように加速させるのか?
類似性検索エンジンは、入力とデータベースを比較して、入力に最も類似しているオブジェクトを見つけることで機能する。インデクシングはデータを効率的に整理するプロセスであり、大規模なデータセットに対する時間のかかるクエリを劇的に高速化することで、類似性検索を有用なものにする上で大きな役割を果たす。膨大なベクトルデータセットがインデックス化された後、クエリは入力クエリと類似したベクトルを含む可能性が最も高いクラスタ、つまりデータのサブセットにルーティングすることができる。実際には、これは本当に大きなベクトルデータに対するクエリを高速化するために、ある程度の精度が犠牲になることを意味する。
単語がアルファベット順に並べられた辞書に例えることができる。単語を調べるとき、同じ頭文字の単語だけを含むセクションに素早く移動することができ、入力単語の定義の検索を劇的に高速化することができる。
IVFインデックスにはどのような種類があり、どのようなシナリオに最適ですか?
高次元のベクトル類似検索のために設計されたインデックスは数多くあり、それぞれ性能、精度、ストレージ要件においてトレードオフの関係にあります。この記事では、いくつかの一般的なIVFインデックスタイプ、その長所と短所、そして各インデックスタイプのパフォーマンステスト結果について説明します。性能テストでは、オープンソースのベクトルデータ管理プラットフォームであるMilvusにおいて、各インデックスタイプのクエリー時間とリコール率を定量化しています。テスト環境に関する追加情報については、本記事下部の方法論セクションを参照のこと。
FLAT:100%の想起率が必要な場合に、比較的小さな(100万規模の)データセットを検索するのに適している。
完璧な精度が要求され、比較的小さな(百万スケールの)データセットに依存するベクトル類似検索アプリケーションには、FLATインデックスが良い選択です。FLATはベクトルを圧縮せず、正確な検索結果を保証できる唯一のインデックスである。FLATの結果は、再現率が100%に満たない他のインデックスが生成した結果の比較対象としても使用できる。
FLATが正確なのは、検索に網羅的なアプローチをとるからである。つまり、クエリごとに、ターゲット入力がデータセット内のすべてのベクトルと比較される。このため、FLATは我々のリストの中で最も遅いインデックスであり、膨大なベクトルデータのクエリには適していない。MilvusにはFLATインデックス用のパラメータはなく、FLATインデックスを使用するためにデータトレーニングや追加ストレージを必要としない。
FLATパフォーマンステスト結果
Milvusにおいて、200万個の128次元ベクトルからなるデータセットを使用し、FLATクエリ時間の性能テストを実施した。
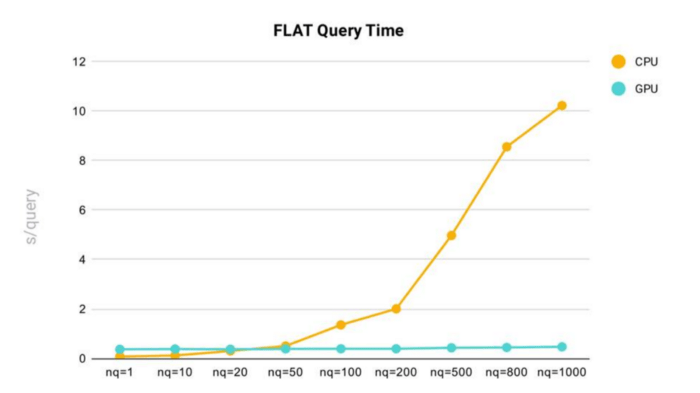 MilvusにおけるFLATインデックスのクエリ時間テスト結果
MilvusにおけるFLATインデックスのクエリ時間テスト結果
主な要点
- nq(クエリのターゲットベクトルの数)が増加すると、クエリ時間は増加します。
- MilvusのFLATインデックスを使用すると、nqが200を超えるとクエリー時間が急激に増加することがわかります。
- 一般的に、GPUでMilvusを実行した場合とCPUで実行した場合では、FLATインデックスの方が高速で一貫性があります。しかし、nqが20以下の場合、CPUでのFLATクエリの方が高速です。
IVF_FLAT:IVF_FLAT:精度を犠牲にして速度を向上させる(逆も同様)。
精度を犠牲にして類似検索処理を高速化する一般的な方法は、近似最近傍(ANN)検索を行うことである。ANN アルゴリズムは、類似したベクトルをクラスタリングすることで、ストレージ要件と計算負荷を削減し、ベクトル検索を高速化します。IVF_FLATは最も基本的な転置ファイルインデックスタイプで、ANN検索の一形態に依存しています。
IVF_FLATはベクトルデータをいくつかのクラスタ単位(nlist)に分割し、対象となる入力ベクトルと各クラスタの中心との距離を比較します。システムがクエリに設定したクラスタ数(nprobe)に応じて、ターゲット入力と最も類似したクラスタ(複数可)内のベクトルとの比較に基づく類似性検索結果が返され、クエリ時間が大幅に短縮されます。
nprobeを調整することで、シナリオに応じた精度と速度の理想的なバランスを見つけることができます。IVF_FLATの性能テストの結果は、ターゲット入力ベクトルの数(nq)と検索するクラスタの数(nprobe)の両方が増加すると、クエリ時間が急激に増加することを示しています。IVF_FLATはベクトルデータを圧縮しませんが、インデックスファイルにはメタデータが含まれるため、インデックスを持たない生のベクトルデータセットと比較すると、ストレージ要件はわずかに増加します。
IVF_FLAT の性能テスト結果:
IVF_FLATのクエリ時間性能テストは、10億個の128次元ベクトルを含む公開1B SIFTデータセットを用いてMilvusで実施された。
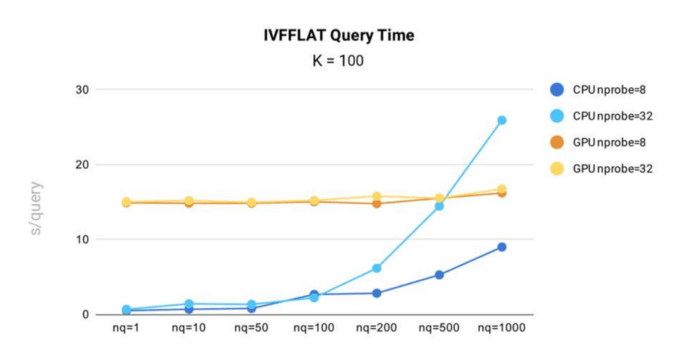 MilvusにおけるIVF_FLATインデックスのクエリタイムテスト結果
MilvusにおけるIVF_FLATインデックスのクエリタイムテスト結果
主な要点:
- CPU上で実行する場合、MilvusのIVF_FLATインデックスのクエリー時間はnprobeとnqの両方で増加します。これは、クエリに含まれる入力ベクトルが多いほど、あるいはクエリが検索するクラスタ数が多いほど、クエリ時間が長くなることを意味します。
- GPUの場合、nqとnprobeの変化に対するインデックスの時間変動は少ない。これは、インデックスデータが大きく、CPUメモリからGPUメモリへのデータコピーがクエリ時間全体の大半を占めるためです。
- nq = 1,000、nprobe = 32を除くすべてのシナリオで、IVF_FLATインデックスはCPU上で実行する方が効率的です。
100万個の128次元ベクトルを含む公開1M SIFTデータセットと、100万個以上の200次元ベクトルを含むglove-200-angularデータセットの両方をインデックス構築に使用し、IVF_FLATの想起性能テストをMilvusで実施した(nlist = 16,384)。
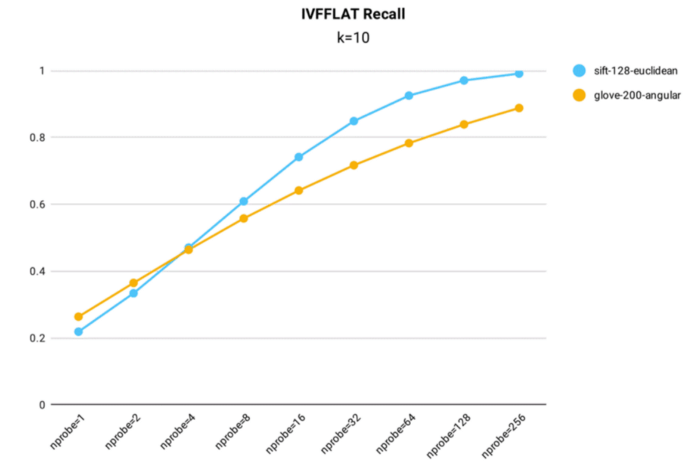 MilvusにおけるIVF_FLATインデックスの再現率テスト結果
MilvusにおけるIVF_FLATインデックスの再現率テスト結果
キーポイント
- IVF_FLATインデックスは精度を最適化することができ、nprobe = 256の場合、1M SIFTデータセットで0.99を超える再現率を達成。
IVF_SQ8:IVF_FLATよりも高速でリソースを消費しないが、精度も劣る。
IVF_FLATは圧縮を行わないため、生成されるインデックスファイルは、インデックスを付けない生のベクトルデータとほぼ同じサイズになります。例えば、元の 1B SIFT データセットが 476 GB の場合、IVF_FLAT のインデックスファイルは若干大きくなります(~470 GB)。すべてのインデックスファイルをメモリにロードすると、470GBのストレージを消費します。
ディスク、CPU、GPU のメモリリソースが限られている場合は、IVF_FLAT よりも IVF_SQ8 の方が適しています。このインデックスタイプは、スカラー量子化を行うことで、各FLOAT(4バイト)をUINT8(1バイト)に変換することができます。これにより、ディスク、CPU、GPUのメモリ消費量が70~75%削減される。1B SIFTデータセットの場合、IVF_SQ8インデックスファイルは140GBのストレージしか必要としない。
IVF_SQ8 のパフォーマンステスト結果:
10億個の128次元ベクトルを含む1B SIFTデータセットをインデックス構築に使用し、IVF_SQ8のクエリ時間テストをMilvusで実施しました。
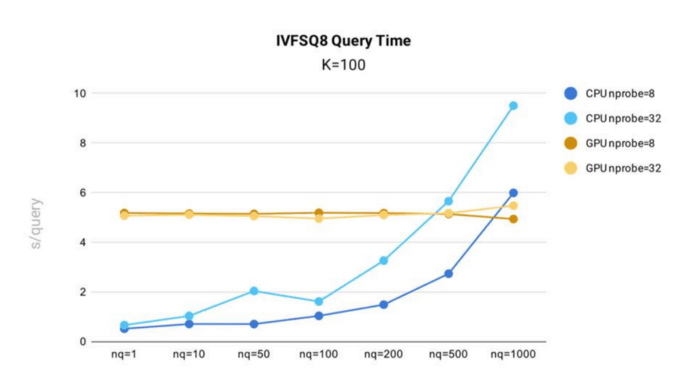 MilvusにおけるIVF_SQ8インデックスのクエリタイムテスト結果
MilvusにおけるIVF_SQ8インデックスのクエリタイムテスト結果
キーポイント
- インデックスファイルのサイズを小さくすることで、IVF_SQ8はIVF_FLATと比較して顕著な性能向上を実現しています。IVF_SQ8 は IVF_FLAT と同様のパフォーマンスカーブを描いており、nq と nprobe に応じてクエリ時間が長くなっています。
- IVF_FLATと同様に、IVF_SQ8はCPU上で実行され、nqとnprobeが小さいほど高速になります。
100万個の128次元ベクトルを含む1M SIFTデータセットと、100万個以上の200次元ベクトルを含むglove-200-angularデータセットの両方を用いて、IVF_SQ8の想起性能テストをMilvusで実施した(nlist = 16,384)。
MilvusにおけるIVF_SQ8インデックスの再現率テスト結果](https://assets.zilliz.com/Blog_Accelerating_Similarity_Search_on_Really_Big_Data_with_Vector_Indexing_6_b1e0e5b6a5.png)
キーポイント
- 元データの圧縮にもかかわらず、IVF_SQ8はクエリ精度の大幅な低下は見られない。様々なnprobe設定において、IVF_SQ8はIVF_FLATよりも最大でも1%低い再現率。
IVF_SQ8H:IVF_SQ8よりもさらに高速な新しいGPU/CPUハイブリッドアプローチ。
IVF_SQ8Hは、IVF_SQ8よりもクエリ性能を向上させる新しいインデックスタイプです。CPU上で動作するIVF_SQ8インデックスをクエリする場合、クエリ時間の大半はターゲット入力ベクトルに最も近いnprobeクラスタを見つけることに費やされます。クエリ時間を短縮するために、IVF_SQ8は、インデックスファイルよりも小さい粗量子化器演算用のデータをGPUメモリにコピーし、粗量子化器演算を大幅に高速化します。次にgpu_search_thresholdが、どのデバイスがクエリを実行するかを決定します。nq >= gpu_search_thresholdの場合、GPUがクエリーを実行し、そうでない場合はCPUがクエリーを実行します。
IVF_SQ8Hはハイブリッド・インデックス・タイプで、CPUとGPUが一緒に動作する必要があります。GPU対応Milvusでのみ使用可能です。
IVF_SQ8H パフォーマンステスト結果:
10億個の128次元ベクトルを含む公開1B SIFTデータセットをインデックス構築に使用し、IVF_SQ8Hのクエリ時間性能テストをMilvusで実施した。
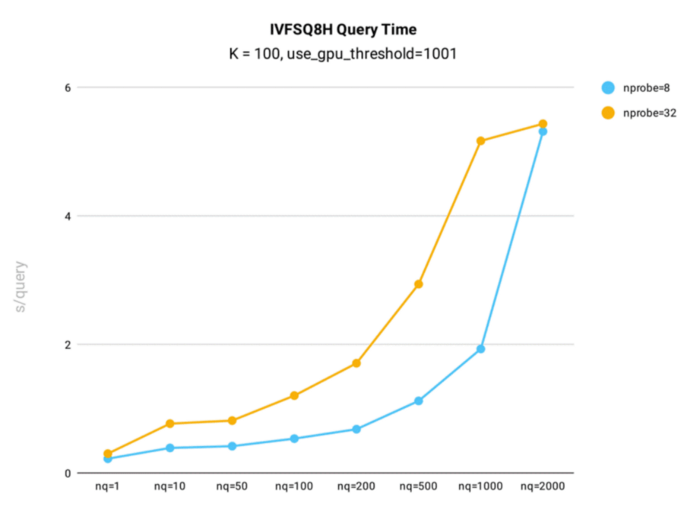 MilvusにおけるIVF_SQ8Hインデックスのクエリタイムテスト結果
MilvusにおけるIVF_SQ8Hインデックスのクエリタイムテスト結果
キーポイント
- nqが1,000以下の場合、IVF_SQ8Hのクエリ時間はIVFSQ8の約2倍。
- nq = 2000 の場合、IVFSQ8H と IVF_SQ8 のクエリ時間は同じです。しかし、gpu_search_threshold パラメータが 2000 より低い場合、IVF_SQ8H は IVF_SQ8 を上回ります。
- IVF_SQ8Hのクエリ回収率はIVF_SQ8と同じであり、検索精度を落とすことなく、より少ないクエリ時間を達成することを意味する。
大規模ベクトルデータ管理プラットフォームMilvusの詳細はこちら。
Milvusは、人工知能、ディープラーニング、伝統的なベクトル計算などの分野における類似検索アプリケーションを強力にサポートするベクトルデータ管理プラットフォームです。Milvusに関する追加情報については、以下のリソースをご覧ください:
- MilvusはGitHubのオープンソースライセンスで利用可能です。
- Milvusでは、グラフおよびツリーベースのインデックスを含む、その他のインデックスタイプもサポートされています。サポートされているインデックスタイプの包括的なリストについては、MilvusのDocumentation for vector indexesを参照してください。
- Milvusを立ち上げた会社については、Zilliz.comをご覧ください。
- Slack](https://join.slack.com/t/milvusio/shared_invite/zt-e0u4qu3k-bI2GDNys3ZqX1YCJ9OM~GQ)でMilvusコミュニティとチャットしたり、問題のヘルプを得ることができます。
方法論
パフォーマンステスト環境
本記事で参照した性能テストに使用したサーバー構成は以下の通りである:
- Intel (R) Xeon (R) Platinum 8163 @ 2.50GHz、24コア
- GeForce GTX 2080Ti x 4
- 768 GBメモリ
関連技術コンセプト
この記事を理解するのに必要ではありませんが、インデックス・パフォーマンス・テストの結果を解釈するのに役立つ技術的概念をいくつか紹介します:
 ブログ_ベクターインデクシングによるビッグデータでの類似検索の高速化_8.png
ブログ_ベクターインデクシングによるビッグデータでの類似検索の高速化_8.png
リソース
本記事では以下のソースを使用した:
- データベースシステム百科事典](https://books.google.com/books/about/Encyclopedia_of_Database_Systems.html?id=YdT3wQEACAAJ)," Ling Liu and M. Tamer Özsu.
次の記事
引き続き、Accelerating Similarity Search on Really Big Data with Vector Indexing:パートIIを読む。
読み続けて

Why Teams Are Migrating from Weaviate to Zilliz Cloud — and How to Do It Seamlessly
Explore how Milvus scales for large datasets and complex queries with advanced features, and discover how to migrate from Weaviate to Zilliz Cloud.

Vector Databases vs. Hierarchical Databases
Use a vector database for AI-powered similarity search; use a hierarchical database for organizing data in parent-child relationships with efficient top-down access patterns.

Top 5 AI Search Engines to Know in 2025
Discover the top AI-powered search engines of 2025, including OpenAI, Google AI, Bing, Perplexity, and Arc Search. Compare features, strengths, and limitations.