




MLOps (Operazioni di apprendimento automatico)
MLOps (Operazioni di apprendimento automatico)
Man mano che i modelli di machine learning (ML) si integrano sempre di più nei processi aziendali quotidiani, le organizzazioni devono affrontare diverse sfide per mantenere i loro modelli accurati e rilevanti negli ambienti reali. Uno dei problemi principali è la deriva dei dati, quando i dati su cui si basano i modelli cambiano nel tempo, facendo perdere loro precisione. Ciò comporta la necessità di un monitoraggio continuo, di una riqualificazione e di una ridistribuzione dei modelli per garantire che le loro previsioni rimangano valide.
La gestione di questi modelli può diventare soggetta a errori, lunga e costosa senza i giusti sistemi. MLOps (Machine Learning Operations) risolve questo problema automatizzando e semplificando l'intero processo.
Vediamo come MLOps semplifica e automatizza il ciclo di vita end-to-end dell'apprendimento automatico, dalla [preparazione dei dati] (https://zilliz.com/blog/streamling-data-processing-with-zilliz-cloud-pipelines-a-deep-dive-into-document-chunking) alla distribuzione dei modelli e al [monitoraggio] (https://zilliz.com/glossary/application-performance-monitoring-).
Che cos'è MLOps?
Machine Learning Operations (MLOps) combina apprendimento automatico, DevOps e ingegneria dei dati per ottimizzare il ciclo di vita dell'apprendimento automatico. L'obiettivo di MLOps è quello di distribuire e mantenere in modo affidabile i modelli di ML in scala negli ambienti di produzione, dalla raccolta dei dati e lo sviluppo dei modelli alla loro distribuzione, al monitoraggio e alla riqualificazione.
Proprio come DevOps ha portato l'automazione e le pratiche di integrazione nello sviluppo del software, MLOps fa lo stesso per l'apprendimento automatico. Applica i principi di Continuous Integration (CI) e Continuous Deployment (CD), consentendo ai team di iterare i modelli più rapidamente e garantendo al contempo un monitoraggio e prestazioni solide negli ambienti di produzione.
Come funziona MLOps
Il processo MLOps comprende diverse fasi che lavorano insieme per ottimizzare l'intero ciclo di vita dell'apprendimento automatico. Queste sono:
Sviluppo del modello
Servizio del modello
Monitoraggio del modello
Manutenzione del modello
Gestione dei dati
Automazione
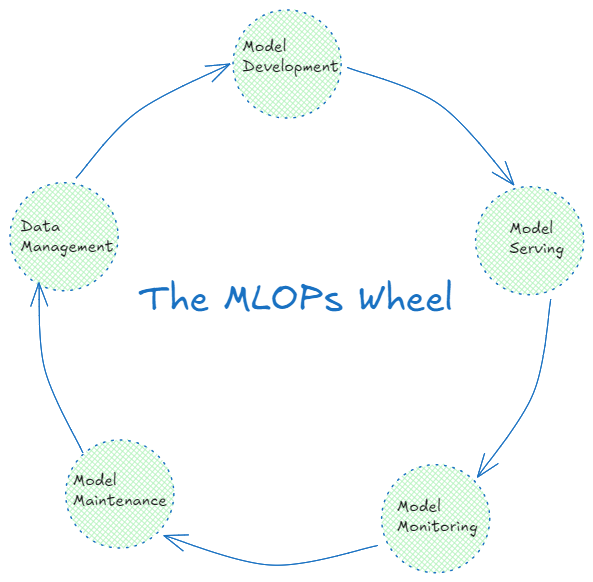 Figura- Fasi multiple del flusso di lavoro MLOps.png
Figura- Fasi multiple del flusso di lavoro MLOps.png
Figura: Fasi multiple del flusso di lavoro MLOps
Sviluppo del modello
La prima fase di MLOps è lo sviluppo del modello, che è alla base di qualsiasi progetto di apprendimento automatico e che comprende diverse importanti sottofasi:
Preparazione dei dati: I dati devono essere puliti e organizzati prima di addestrare un modello. Questo include la rimozione delle informazioni irrilevanti, l'inserimento dei valori mancanti, la normalizzazione dei dati e la loro trasformazione in un formato adatto a un modello di ML.
L'ingegneria delle caratteristiche crea nuove caratteristiche informative o trasforma quelle esistenti per renderle più utili al modello. Ad esempio, i data scientist potrebbero creare nuove caratteristiche come "velocità del vento al quadrato" o "gradienti di temperatura" in un modello di previsione meteorologica per migliorare l'accuratezza della previsione.
Dopo aver preparato i dati, i modelli di ML vengono addestrati. Gli scienziati dei dati addestrano più modelli con algoritmi e iperparametri per trovare quello che funziona meglio.
Test del modello:** Una volta che il modello è stato addestrato, viene testato su un set di dati separato per assicurarsi che sia in grado di fare previsioni accurate su dati nuovi e non visti. Per valutare le prestazioni del modello ML addestrato si utilizzano anche diverse metriche di valutazione.
Modello al servizio
Una volta sviluppato un modello, è necessario distribuirlo in un ambiente di produzione in modo che possa fare previsioni in tempo reale:
Deployment: Questo include la messa a disposizione del modello agli utenti o alle applicazioni. Il modello viene spesso distribuito tramite una API per interagire con altri sistemi. Soluzioni di distribuzione come Kubernetes e Docker aiutano a gestire questo processo garantendo che i modelli siano scalabili e facili da mantenere.
I modelli sono isolati in contenitori (come Docker) per garantire la coerenza. I contenitori includono tutti i componenti necessari - codice, dipendenze e impostazioni - in modo che il modello venga eseguito in modo coerente in ambienti diversi.
Monitoraggio del modello
Dopo la distribuzione, le prestazioni del modello devono essere costantemente monitorate per garantire che rimanga accurato e pertinente:
I sistemi di monitoraggio controllano le prestazioni del modello. Ad esempio, se un modello inizia a fare previsioni imprecise, ciò potrebbe indicare che i dati con cui lavora sono cambiati nel tempo (deriva dei dati).
Tutte le attività del modello vengono registrate per mantenere un registro degli input, degli output e degli errori. Questo aiuta a risolvere i problemi e a identificare gli schemi di utilizzo del modello.
Manutenzione del modello
I modelli di apprendimento automatico devono essere sottoposti a regolare manutenzione per mantenerne le prestazioni:
Aggiornamento e riqualificazione: MLOps facilita l'aggiornamento e la riqualificazione dei modelli quando sono disponibili nuovi dati o quando le prestazioni diminuiscono. La riqualificazione regolare garantisce che i modelli rimangano aggiornati e accurati, adattandosi ai modelli di dati in evoluzione. MLOps automatizza questo processo, rendendolo efficiente e meno soggetto a errori.
Per tenere traccia delle diverse versioni dei modelli, MLOps utilizza sistemi di versioning come [GitHub] (https://github.com/), [MLflow] (https://mlflow.org/) e [DVC] (https://dvc.org/). Questi sistemi registrano ogni versione di un modello, insieme ai dati e al codice utilizzati per crearlo.
Gestione dei dati
I dati sono la spina dorsale di qualsiasi sistema di apprendimento automatico e la loro gestione efficace è una parte fondamentale di MLOps:
Ingestione e archiviazione dei dati: MLOps gestisce il flusso di dati da varie fonti alla pipeline ML e archivia i dati in archivi cloud scalabili come Zilliz Cloud e Milvus.
MLOps garantisce la qualità dei dati, la sicurezza e la conformità alle normative. Inoltre, garantisce che solo le persone autorizzate possano accedere ai dati e che vengano rispettate le leggi sulla privacy.
Automazione
Uno degli obiettivi principali di MLOps è quello di automatizzare le attività ripetitive, rendendo più facile la gestione dei modelli di apprendimento automatico nel tempo:
Gli strumenti di automazione possono gestire molte fasi della pipeline di ML, dall'elaborazione dei dati all'addestramento e alla distribuzione dei modelli. Questo riduce la necessità di interferenze manuali e aiuta a mantenere la coerenza durante la creazione e la distribuzione dei modelli.
Integrazione continua e distribuzione continua (CI/CD):** Le pipeline CI/CD aiutano i team a costruire, testare e distribuire continuamente i modelli con un approccio semplificato e automatizzato. Con CI/CD, i modelli possono essere rapidamente aggiornati, testati e messi in produzione con un ritardo minimo.
Confronto: MLOps vs. DevOps vs. LLMOps
MLOps, DevOps e LLMOps sembrano termini simili; ogni pratica si concentra sul miglioramento dei flussi di lavoro di sviluppo, ma affrontano sfide diverse e offrono soluzioni uniche nell'ambito dello sviluppo software e dell'intelligenza artificiale.
| Aspect | DevOps | MLOps | LLMOps |
| Definizione | Un insieme di pratiche per automatizzare lo sviluppo del software e le operazioni IT. | Estende i principi di DevOps per automatizzare il ciclo di vita dei modelli di ML. | Si concentra sulla gestione del ciclo di vita dei [modelli linguistici di grandi dimensioni] (https://zilliz.com/glossary/large-language-models-(llms)) (LLM). |
| Automatizzare le pipeline di consegna del software (CI/CD), migliorare la collaborazione e abbreviare il ciclo di vita dello sviluppo. | Automatizzazione dei flussi di lavoro ML, dalla preparazione dei dati alla distribuzione e al monitoraggio dei modelli. | Ottimizzare la distribuzione, la messa a punto e la gestione degli LLM in produzione. | |
| Strumenti principali | - GitLab per CI/CD - Grafana per il monitoraggio - Docker e Kubernetes per l'orchestrazione dei container. | - Kubeflow e Apache Airflow sono utilizzati per l'automazione dei flussi di lavoro.- Scikit-learn e TensorFlow per l'addestramento dei modelli. | Strumenti di inferenza su larga scala (Ray Serve, ONNX). |
| Casi d'uso | - Distribuzione rapida di aggiornamenti software - Gestione di sistemi distribuiti. | Monitoraggio continuo delle prestazioni dei modelli in produzione - Automatizzazione del retraining e del redeployment dei modelli di ML. | Distribuzione di modelli linguistici di grandi dimensioni per attività di [NLP] (https://zilliz.com/learn/A-Beginner-Guide-to-Natural-Language-Processing). |
Metriche MLOps
In MLOps, le metriche sono fondamentali per misurare le prestazioni del modello e l'intera pipeline di ML. I KPI in MLOps vanno oltre le tradizionali metriche dei modelli di ML e riguardano l'intero ciclo di vita. L'accuratezza del modello, la precisione, il richiamo e il punteggio F1 sono ancora fondamentali, ma MLOps ne introduce di nuovi. La frequenza di distribuzione misura la frequenza con cui nuovi modelli o aggiornamenti vengono distribuiti in produzione e l'agilità della pipeline di ML. Il tempo medio di ripristino (MTTR) misura la velocità con cui vengono identificati e risolti i problemi nei modelli di produzione. Le metriche di utilizzo delle risorse misurano l'efficienza computazionale, importante per la gestione dei costi nel cloud. Le metriche relative alla deriva dei dati e dei modelli misurano il rendimento dei modelli nel tempo, quando i dati di input cambiano. La latenza e il throughput dell'inferenza sono fondamentali per le applicazioni in tempo reale e misurano il tempo di risposta e la capacità di elaborazione. Le metriche di A/B testing confrontano le prestazioni dei nuovi modelli con quelle dei modelli esistenti in produzione. Il livello di automazione della pipeline misura il livello di intervento umano richiesto; un livello più alto è migliore per gli MLOp più maturi. Infine, le metriche di versionamento e riproducibilità dei modelli assicurano che gli esperimenti e le implementazioni possano essere tracciati e replicati. Queste metriche forniscono una visione completa degli MLOp, in modo da poter migliorare continuamente i processi e i risultati di ML.
Vantaggi e sfide di MLOps
Se da un lato l'MLOps offre numerosi vantaggi che migliorano l'efficienza e l'efficacia delle operazioni di machine learning, dall'altro presenta anche diverse sfide che le organizzazioni devono affrontare. Comprendere i vantaggi e le sfide è fondamentale per implementare con successo le pratiche MLOps e ottenere risultati ottimali.
Vantaggi MLOps
Pipeline automatizzate:** Riduce gli interventi manuali, consentendo a data scientist e ingegneri di concentrarsi sulle attività principali.
Time-to-Market più rapido:** I flussi di lavoro semplificati e l'automazione consentono iterazioni di modelli e cicli di rilascio più rapidi.
Prestazioni migliorate: il monitoraggio continuo e i cicli di riqualificazione creano modelli robusti che si comportano bene in scenari dinamici e reali.
Scalabilità:** I framework MLOps consentono di distribuire e gestire migliaia di modelli in ambienti diversi.
Miglioramento continuo:** I modelli vengono continuamente monitorati e riqualificati. Questa pratica garantisce che si adattino a nuovi dati e a condizioni mutevoli, mantenendo prestazioni elevate.
Sfide MLOps
Complessità:** L'implementazione di MLOps richiede la creazione di un'infrastruttura e di flussi di lavoro complessi, che richiedono molte risorse.
Integrazione degli strumenti: l'integrazione di diversi strumenti per la gestione dei dati, la formazione dei modelli, la distribuzione e il monitoraggio è impegnativa.
Può essere difficile tenere traccia e gestire tutte le diverse versioni dei modelli di apprendimento automatico e le relative dipendenze e impostazioni. Un altro problema che può sorgere è la riproduzione e la convalida dei risultati in vari ambienti.
Sebbene MLOps possa migliorare l'efficienza e la scalabilità nel lungo periodo, il costo iniziale della creazione di un framework MLOps può essere elevato. Le organizzazioni devono investire negli strumenti, nelle infrastrutture e nei talenti giusti per garantire il successo delle loro iniziative MLOps.
Collaborazione:** MLOps introduce processi e strumenti comuni, favorendo una collaborazione efficace tra ingegneri dei dati, scienziati, sviluppatori e ingegneri IT, che rimane una sfida importante.
Strumenti e tecnologie in MLOps
MLOps dipende da diversi strumenti e tecnologie per gestire il ciclo di vita dell'apprendimento automatico. Di seguito sono riportati alcuni degli strumenti MLOps più comunemente utilizzati:
MLflow: Una piattaforma open-source per la gestione dell'intero ciclo di vita dell'apprendimento automatico, compreso il tracciamento degli esperimenti, il versionamento dei modelli e il deployment.
DVC (Data Version Control): Un sistema di controllo delle versioni open-source per la gestione dei dati, l'automazione delle pipeline di ML e la gestione degli esperimenti.
Kubeflow:** Una piattaforma basata su Kubernetes per il deployment, la scalabilità e la gestione dei modelli di apprendimento automatico in ambienti di produzione.
Apache Airflow: Uno strumento di automazione dei flussi di lavoro che aiuta a gestire le pipeline di dati e a pianificare le attività per l'ingestione dei dati e l'addestramento dei modelli.
TensorFlow Extended (TFX): Una piattaforma end-to-end per la distribuzione di pipeline di apprendimento automatico di produzione che utilizzano TensorFlow. TFX fornisce strumenti per la convalida dei dati, la gestione dei modelli e la formazione continua.
Basi di dati vettoriali (Milvus, Zilliz Cloud): In molti scenari MLOps, la gestione di dati non strutturati come immagini, testo o audio è fondamentale. È qui che i database vettoriali possono essere utili. Sono specializzati nell'archiviazione e interrogazione di incorporazioni vettoriali e rappresentazioni numeriche di tali dati. Milvus è un database vettoriale open-source che eccelle nella gestione di insiemi di dati su larga scala e di interrogazioni complesse.
Tendenze MLOps
Il panorama MLOps sta cambiando rapidamente e stanno emergendo alcune tendenze interessanti. L'AutoML (Automated Machine Learning) sta prendendo piede, automatizzando l'ingegneria delle caratteristiche e la regolazione degli iperparametri. L'Edge ML sta diventando sempre più importante; i modelli possono essere eseguiti su dispositivi edge, riducendo la latenza e aumentando la privacy. L'apprendimento federato sta emergendo per addestrare i modelli su dispositivi decentralizzati mantenendo i dati privati. Gli strumenti XAI (Explainable AI) vengono aggiunti alle pipeline MLOps per rispondere alla crescente esigenza di interpretabilità e trasparenza dei modelli. Cresce l'attenzione per gli strumenti di monitoraggio specifici per il ML, in grado di rilevare in tempo reale il degrado del modello e la deriva dei dati. Gli LLM (Large Language Models) vengono aggiunti ai flussi di lavoro MLOps per svolgere attività NLP più avanzate. Poiché la sostenibilità è sempre più importante, stanno emergendo MLOp ecologici per ottimizzare l'uso delle risorse e ridurre l'impronta di carbonio del ML. Queste tendenze indicano un futuro in cui gli MLOps saranno più automatizzati, efficienti, interpretabili ed ecologici.
Domande frequenti sugli MLOp
- **A cosa servono gli MLOP?
Le Machine Learning Operations (MLOps) sono un insieme di pratiche progettate per semplificare e automatizzare i flussi di lavoro e i processi di distribuzione dei modelli di apprendimento automatico (ML). Incorporando l'apprendimento automatico e l'intelligenza artificiale (AI), le aziende possono affrontare sfide complesse del mondo reale e creare soluzioni di valore per i clienti.
- **Che cos'è MLOps vs DevOps?
MLOps è una pratica di scienza dei dati incentrata sul test e sulla distribuzione rapida di modelli di apprendimento automatico. DevOps, invece, integra lo sviluppo e le operazioni IT per migliorare l'efficienza, l'affidabilità e la sicurezza dello sviluppo del software.
- **Qual è la differenza tra MLOps e AIOP?
AIOps consente ai team di IT operations e data science di implementare la gestione predittiva degli alert, migliorare la sicurezza dei dati e supportare i flussi di lavoro DevOps. Le soluzioni MLOps aiutano le aziende a velocizzare l'implementazione dei modelli di machine learning, a migliorare la collaborazione tra i team di data science e operations e a scalare le attività di AI in tutta l'organizzazione.
- **L'MLOps è richiesto?
Con l'adozione da parte delle aziende di soluzioni basate sui dati, la richiesta di professionisti MLOps per implementare e gestire in modo efficiente i modelli di apprendimento automatico è in rapida crescita.
- **Qual è il linguaggio migliore per gli MLOps?
Python è attualmente la scelta migliore per l'apprendimento automatico e gli MLOps. La sua popolarità deriva dalla vasta gamma di strumenti e librerie disponibili per l'apprendimento automatico, come NumPy, TensorFlow, Keras e PyTorch. Queste librerie facilitano la costruzione di modelli di apprendimento automatico e la gestione di attività di ingegneria dei dati, semplificando l'intero processo di MLOps dei progetti di apprendimento automatico.
Risorse correlate
- Che cos'è MLOps?
- Come funziona MLOps
- Confronto: MLOps vs. DevOps vs. LLMOps
- Metriche MLOps
- Vantaggi e sfide di MLOps
- Strumenti e tecnologie in MLOps
- Tendenze MLOps
- Domande frequenti sugli MLOp
- Risorse correlate
Contenuto
Inizia gratis, scala facilmente
Prova il database vettoriale completamente gestito progettato per le tue applicazioni GenAI.
Prova Zilliz Cloud gratuitamente