




Estrazione dei dati: Dai dati grezzi alle intuizioni di valore

Estrazione dei dati: Dai dati grezzi alle intuizioni di valore
Che cos'è il Data Mining?
Il data mining è una tecnica per scoprire modelli, tendenze e intuizioni preziose da grandi quantità di dati. Aiuta le aziende e i ricercatori a prendere decisioni migliori scoprendo connessioni nascoste che non sono ovvie a prima vista. Utilizzando tecniche come la classificazione, il clustering e l'estrazione di regole di associazione, il data mining trasforma i dati grezzi in preziose intuizioni. Che si tratti di prevedere il comportamento dei clienti, di individuare frodi o di migliorare i risultati delle ricerche, il data mining svolge un ruolo fondamentale nel plasmare la tecnologia moderna.
Come funziona il data mining?
Il data mining analizza grandi insiemi di dati per trovare modelli, relazioni e tendenze nascoste che possono essere utilizzate per il processo decisionale. Utilizza metodi statistici, algoritmi di apprendimento automatico e tecniche di gestione dei database per elaborare i dati grezzi e trasformarli in informazioni utili. Il processo segue una serie di fasi per pulire, organizzare ed estrarre informazioni utili dai dati. Per capire meglio, si consideri una piattaforma di e-commerce che vuole prevedere quali clienti acquisteranno probabilmente in base al loro comportamento di navigazione.
Fasi del processo di estrazione dei dati
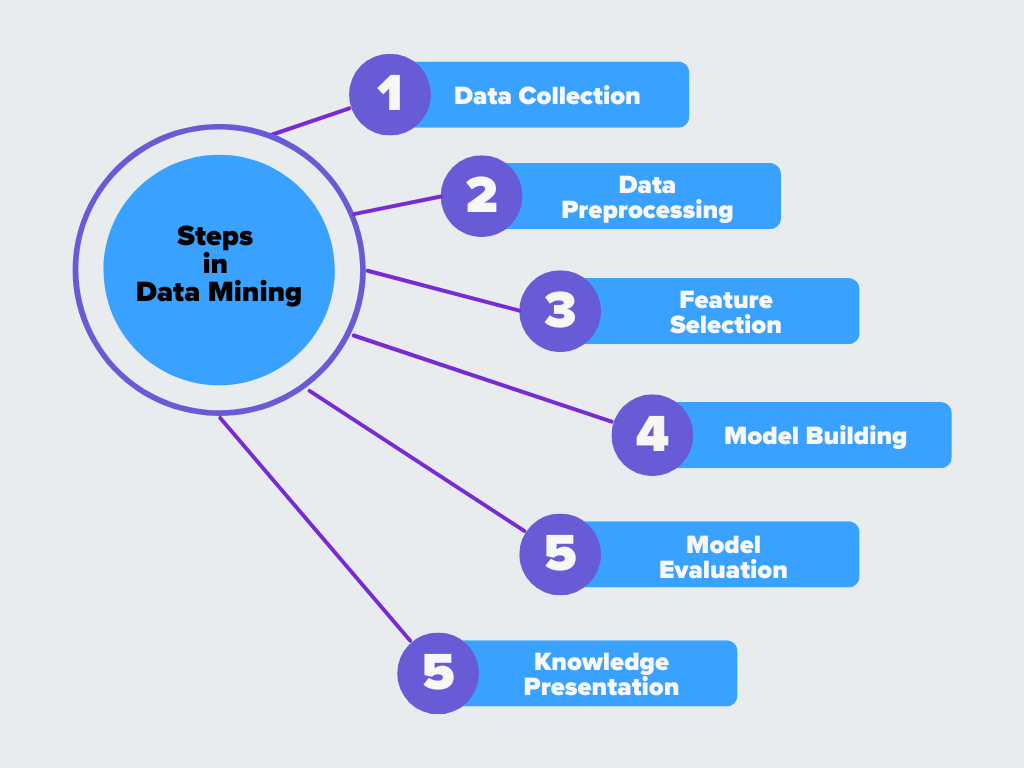 Figura - Fasi dell'estrazione dei dati
Figura - Fasi dell'estrazione dei dati
Figura: Fasi dell'estrazione dei dati
1. Raccolta dei dati
Il primo passo consiste nel raccogliere i dati da diverse fonti, come database, fogli di calcolo, dispositivi IoT o cloud storage. Poiché i dati sono spesso disponibili in diversi formati e strutture, devono essere integrati in un unico sistema. Questa fase gestisce anche i record duplicati e unisce i set di dati per creare una visione unificata. **Una piattaforma di e-commerce raccoglie dati dai log del sito web, dagli account degli utenti e dalla cronologia degli acquisti per creare una visione completa del comportamento dei clienti.
2. Preelaborazione dei dati
I dati grezzi raramente sono perfetti. Possono contenere valori mancanti, incongruenze o errori che possono influire sull'accuratezza dei risultati. La pre-elaborazione dei dati comporta la pulizia dei dati eliminando i duplicati, inserendo i valori mancanti e correggendo gli errori. Le tecniche di pre-elaborazione, come la normalizzazione e la trasformazione, aiutano a strutturare i dati in modo che siano pronti per l'analisi. **Ad esempio, alcuni clienti possono avere profili incompleti, cronologia degli acquisti mancante o record duplicati che devono essere puliti prima dell'analisi.
3. Selezione delle caratteristiche
Non tutti i dati sono utili per l'estrazione. Nella [selezione delle caratteristiche] (https://zilliz.com/ai-faq/what-is-feature-extraction), i dati vengono trasformati in un formato più adatto e le caratteristiche essenziali vengono selezionate, mentre quelle irrilevanti vengono rimosse. L'ingegnerizzazione delle caratteristiche crea nuove variabili basate sui dati esistenti, che fanno parte di questa fase per migliorare le prestazioni del modello. Ad esempio, possono essere selezionate caratteristiche come il tempo trascorso sulle pagine dei prodotti, gli acquisti passati e il tasso di abbandono del carrello, mentre possono essere rimossi dati meno utili come gli indirizzi IP.
4. Costruzione del modello
Una volta puliti e preparati i dati, si applicano gli algoritmi per trovare modelli e relazioni. Tecniche come il clustering, la classificazione e l'estrazione di regole di associazione aiutano a identificare intuizioni significative. I modelli di apprendimento automatico possono essere addestrati in questa fase per riconoscere le tendenze, classificare i dati o fare previsioni basate su modelli storici. **Ad esempio, la piattaforma potrebbe utilizzare un modello di classificazione per prevedere se un utente effettuerà probabilmente un acquisto in base al suo comportamento di navigazione e agli acquisti precedenti.
5. Valutazione del modello
Non tutti i modelli scoperti durante l'estrazione sono utili. Questa fase convalida i risultati per garantire che siano accurati e significativi. Gli analisti confrontano i risultati con i dati noti, utilizzano metriche di performance come l'accuratezza e il richiamo e, se necessario, perfezionano i modelli. L'obiettivo è confermare che i modelli trovati siano affidabili e applicabili agli scenari del mondo reale. **La piattaforma testa il modello di previsione confrontando i risultati con gli acquisti effettivi per verificarne l'accuratezza.
6. Presentazione della conoscenza
La fase finale consiste nel presentare le conoscenze in modo chiaro e comprensibile. Ciò potrebbe includere report visivi, dashboard o sintesi che i responsabili delle decisioni possano utilizzare. Le conoscenze estratte vengono poi applicate per migliorare i processi, prendere decisioni aziendali o potenziare i sistemi guidati dall'intelligenza artificiale.
**Ad esempio, la piattaforma di e-commerce utilizza queste conoscenze per creare consigli personalizzati sui prodotti, annunci mirati e offerte promozionali per aumentare le vendite.
Tecniche e algoritmi di estrazione dei dati
Le tecniche di data mining si dividono in categorie in base al modo in cui analizzano i dati ed estraggono modelli significativi. Queste tecniche includono apprendimento supervisionato, apprendimento non supervisionato, apprendimento semi-supervisionato e rilevazione di anomalie. Ogni approccio è adatto a diversi tipi di problemi, che vanno dalla classificazione e dalla previsione alla scoperta di strutture nascoste nei dati.
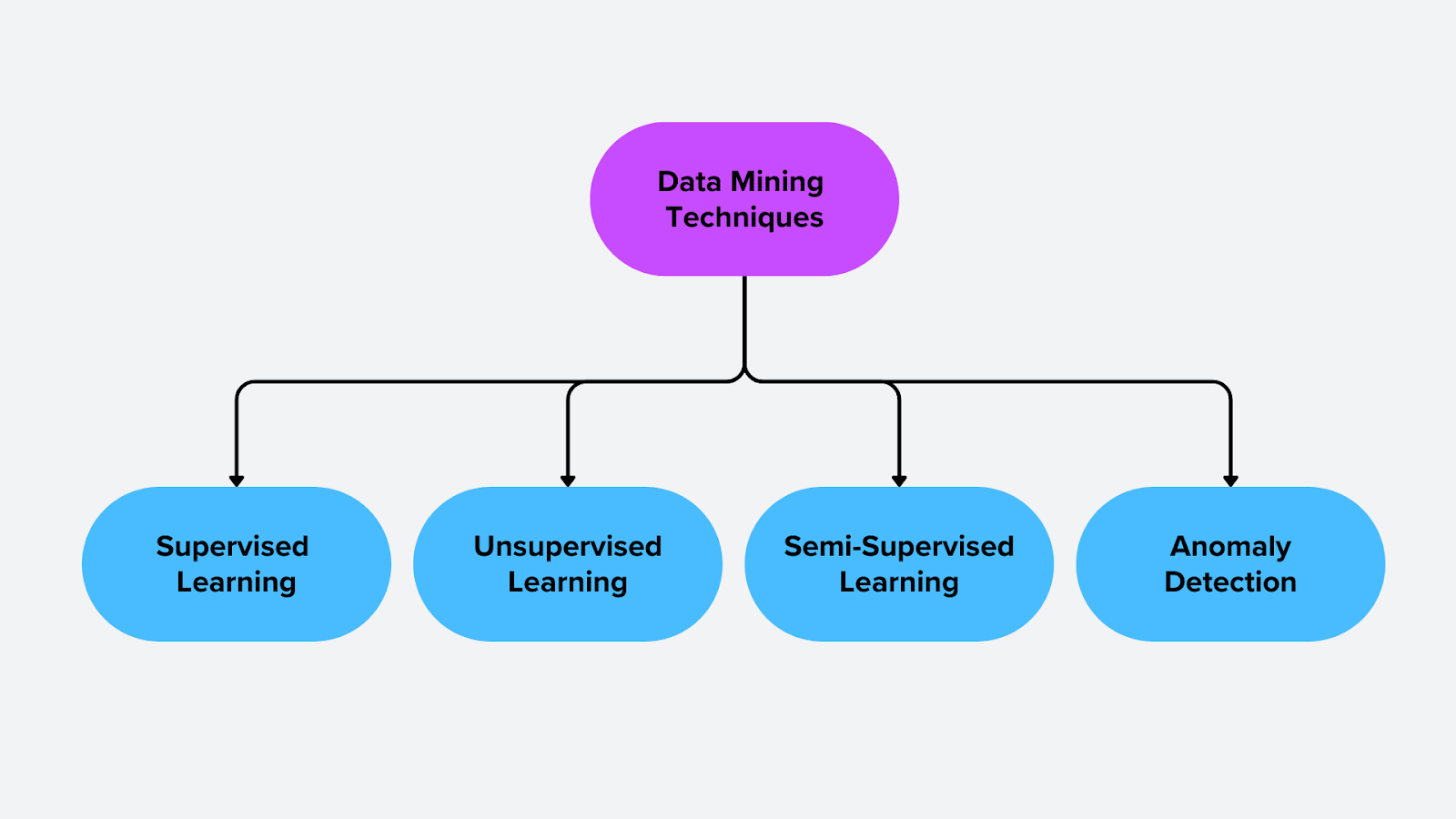 Figura - Tecniche di estrazione dei dati
Figura - Tecniche di estrazione dei dati
Figura: Tecniche di estrazione dei dati
1. Apprendimento supervisionato
L'apprendimento supervisionato addestra un modello su dati etichettati, in cui ogni ingresso ha una corrispondente uscita nota. Il modello impara da questi esempi per prevedere i risultati di nuovi dati non visti. Questo approccio è comunemente utilizzato nelle attività di classificazione, regressione e previsione delle serie temporali.
 Figura - Tecniche di apprendimento automatico supervisionato
Figura - Tecniche di apprendimento automatico supervisionato
Figura: Tecniche di apprendimento automatico supervisionato
Un modello basato su regole che divide i dati in sottoinsiemi più piccoli in base ai valori delle caratteristiche, formando una struttura ad albero per il processo decisionale.
Un ensemble di alberi decisionali multipli che migliora l'accuratezza e riduce l'overfitting mediando le previsioni di più modelli.
Un approccio sequenziale agli alberi decisionali che corregge gli errori precedenti in ogni iterazione, ottenendo prestazioni predittive più elevate.
Un algoritmo di classificazione che trova il confine ottimale (iperpiano) per separare diverse categorie di dati.
K-Nearest Neighbors (K-NN): Un algoritmo basato sulla distanza che classifica i nuovi punti di dati in base alla classe maggioritaria dei loro vicini più prossimi.
Reti neurali: Modelli multistrato ispirati al cervello umano che apprendono relazioni complesse tra i dati in ingresso e in uscita.
Regressione del vettore di supporto (SVR):** Una variante di SVM utilizzata per prevedere valori continui anziché etichette categoriali.
2. Apprendimento non supervisionato
L'apprendimento non supervisionato analizza i dati senza etichette, identificando strutture e relazioni nascoste all'interno di un insieme di dati. È comunemente usato per il clustering, il rilevamento delle anomalie e la riduzione della dimensionalità.
 Figura - Tecniche di apprendimento automatico non supervisionato
Figura - Tecniche di apprendimento automatico non supervisionato
Figura: Tecniche di apprendimento automatico non supervisionato
Un algoritmo di suddivisione che divide i dati in K cluster assegnando ogni punto al centro del cluster più vicino.
Clustering gerarchico:** Costruisce una gerarchia di cluster attraverso metodi bottom-up (agglomerativi) o top-down (divisivi).
DBSCAN (Density-Based Spatial Clustering): Raggruppa i punti di dati più densi trattando gli outlier come rumore, il che lo rende utile per le distribuzioni irregolari dei dati.
Principal Component Analysis (PCA): Tecnica di riduzione della dimensionalità che trasforma i dati in uno spazio di dimensioni inferiori preservando la varianza.
Autoencoder: Un tipo di rete neurale che apprende rappresentazioni compresse dei dati per il rilevamento di anomalie e l'estrazione di caratteristiche.
Identifica le relazioni tra gli elementi di un set di dati, comunemente usato nell'analisi dei panieri di mercato.
Algoritmo di Apriori:** Tecnica di estrazione di modelli frequenti che trova relazioni tra gli elementi identificando iterativamente gli insiemi di elementi frequenti.
Algoritmo FP-Growth:** Un'alternativa più efficiente ad Apriori, che utilizza una struttura ad albero (FP-tree) per estrarre pattern frequenti con calcoli ridotti.
3. Apprendimento semi-supervisionato
L'apprendimento semi-supervisionato è un approccio ibrido che combina una piccola quantità di dati etichettati con una grande quantità di dati non etichettati per migliorare la precisione dell'apprendimento. Questa tecnica è utile quando l'etichettatura dei dati è costosa o richiede molto tempo.
 Figura- Apprendimento semi-supervisionato.png
Figura- Apprendimento semi-supervisionato.png
Figura: Apprendimento semi-supervisionato
Un modello viene inizialmente addestrato su dati etichettati, quindi fa previsioni su dati non etichettati, aggiungendo le previsioni ad alta affidabilità al set di dati etichettati per un ulteriore addestramento.
Apprendimento semi-supervisionato basato su grafi:** Utilizza strutture a grafo per propagare le etichette attraverso una rete di punti dati correlati, comunemente utilizzato nei sistemi di raccomandazione.
Reti avversarie generative (GAN)](https://zilliz.com/glossary/generative-adversarial-networks):** Le GAN generano nuovi campioni etichettati per migliorare l'apprendimento in scenari a bassa etichettatura, rendendole utili nel riconoscimento delle immagini e del parlato.
Regolarizzazione della coerenza:** Assicura che le previsioni di un modello rimangano coerenti anche quando vengono introdotte leggere variazioni all'input, migliorando la robustezza nell'apprendimento semi-supervisionato.
4. Rilevamento delle anomalie e analisi dei valori anomali
Il rilevamento delle anomalie identifica i punti di dati che si discostano in modo significativo dai modelli normali. Questi algoritmi sono comunemente utilizzati nel [rilevamento delle frodi] (https://zilliz.com/ai-faq/can-anomaly-detection-be-used-for-fraud-detection), nella sicurezza informatica e nel rilevamento dei guasti industriali.
Figura - Rilevamento delle anomalie](https://assets.zilliz.com/Figure_Anomaly_detection_b7353e3dd5.png)
Figura: Rilevamento delle anomalie
Metodo Z-Score:** Rileva gli outlier misurando il numero di deviazioni standard di un punto rispetto alla media.
Intervallo interquartile (IQR):** Identifica gli outlier analizzando l'intervallo tra il primo e il terzo quartile, segnalando i valori estremi.
Isolation Forest: Un modello ad albero che isola più velocemente le anomalie suddividendo i punti di dati in modo casuale.
Fattore outlier locale (LOF):** Misura la densità relativa dei punti di dati per identificare le anomalie in un set di dati.
Una variante di SVM progettata per rilevare le deviazioni dalla classe maggioritaria, comunemente utilizzata per il rilevamento delle frodi.
Rilevamento di anomalie basato su autoencoder:** Utilizza il deep learning per ricostruire i dati di input, segnalando le anomalie quando l'errore di ricostruzione è elevato.
Applicazioni dell'estrazione dei dati nei vari settori industriali
Il data mining viene utilizzato in diversi settori per analizzare grandi insiemi di dati, scoprire modelli e migliorare il processo decisionale. Di seguito sono riportati alcuni casi d'uso specifici del settore:
1. Finanza
Le banche utilizzano il data mining per analizzare i modelli di transazione e rilevare attività sospette, come comportamenti di spesa insoliti o tentativi di accesso multipli falliti.
Valutazione del credito e del rischio:** Le istituzioni finanziarie valutano il livello di rischio di un mutuatario analizzando la storia creditizia, i modelli di reddito e i precedenti rimborsi dei prestiti.
Trading algoritmico:** Le società di investimento utilizzano l'analisi predittiva per analizzare le tendenze del mercato e automatizzare le strategie di trading ad alta frequenza.
2. Assistenza sanitaria
Gli ospedali analizzano le cartelle cliniche e i sintomi dei pazienti per prevedere precocemente le malattie, migliorando i piani di trattamento e riducendo i ricoveri.
Scoperta e sviluppo di farmaci:** Le aziende farmaceutiche utilizzano il data mining per identificare potenziali candidati ai farmaci analizzando i dati genetici e di sperimentazione clinica.
Previsione della riammissione dei pazienti:** Gli operatori sanitari analizzano la storia dei pazienti per prevedere la probabilità di riammissione e adottare misure preventive.
3. Commercio elettronico e vendita al dettaglio
Raccomandazioni personalizzate:** I rivenditori online analizzano la cronologia di navigazione e di acquisto dei clienti per offrire raccomandazioni personalizzate sui prodotti.
Strategie di prezzo dinamiche: le piattaforme di e-commerce regolano i prezzi in base alla domanda, ai prezzi della concorrenza e al comportamento dei clienti.
Previsione del tasso di abbandono:** I rivenditori utilizzano il data mining per identificare i clienti a rischio di abbandono e per indirizzarli con offerte speciali per migliorare la fidelizzazione.
4. Sicurezza informatica
Le organizzazioni utilizzano il data mining per rilevare attività di rete insolite, come tentativi di accesso non autorizzato o infezioni da malware.
Threat Intelligence & Risk Assessment: I team di sicurezza analizzano i dati storici degli attacchi per prevedere e prevenire le minacce informatiche future.
Rilevamento di phishing e frodi: i modelli di apprendimento automatico identificano i tentativi di phishing analizzando i modelli di e-mail, gli URL e i comportamenti dei mittenti.
5. Produzione e IoT industriale
Manutenzione predittiva:** Le fabbriche analizzano i dati dei sensori delle macchine per prevedere i guasti prima che si verifichino, riducendo i tempi di fermo e i costi di riparazione.
Ottimizzazione della catena di fornitura:** I produttori utilizzano il data mining per prevedere le fluttuazioni della domanda, ottimizzare le scorte e ridurre gli sprechi.
Controllo della qualità e rilevamento dei difetti: l'analisi dei dati aiuta a identificare precocemente i difetti di produzione, rilevando le anomalie nei processi di produzione.
6. Telecomunicazioni
Ottimizzazione della rete:** Le società di telecomunicazioni analizzano i modelli di utilizzo per ottimizzare l'allocazione della larghezza di banda e ridurre la congestione.
Gli operatori classificano i clienti in base al comportamento di utilizzo e offrono piani personalizzati per migliorare la fidelizzazione.
Rilevamento di spam e robocall:** Le tecniche di data mining aiutano a filtrare le chiamate e i messaggi di spam in base ai modelli di chiamata e alle segnalazioni degli utenti.
7. Energia e servizi di pubblica utilità
Le aziende energetiche analizzano i modelli di consumo passati per prevedere la domanda futura e ottimizzare le prestazioni della rete.
Rilevamento dei guasti nelle reti elettriche: i sensori monitorano le linee elettriche e rilevano le anomalie per prevenire le interruzioni e migliorare la manutenzione.
Analisi dei contatori intelligenti: i fornitori di servizi pubblici utilizzano il data mining per rilevare modelli di utilizzo insolito dell'energia e identificare potenziali furti di energia.
8. Istruzione
Le scuole analizzano i dati degli studenti per identificare quelli a rischio e fornire un supporto personalizzato all'apprendimento.
Sistemi di apprendimento adattivo:** Le piattaforme educative utilizzano il data mining per personalizzare i materiali didattici in base ai punti di forza e di debolezza degli studenti.
Sistemi di raccomandazione dei corsi:** Le università analizzano le prestazioni degli studenti per consigliare i corsi più adatti in base agli interessi e agli obiettivi di carriera.
Vantaggi del Data Mining
Scopre modelli nascosti: aiuta le aziende e i ricercatori a scoprire intuizioni non immediatamente evidenti nei dati grezzi.
Migliora il processo decisionale: fornisce approfondimenti basati sui dati che migliorano la pianificazione strategica e l'accuratezza delle previsioni.
Questo strumento identifica le tendenze e i cambiamenti nel comportamento dei consumatori, nelle condizioni di mercato e nei modelli finanziari senza alcun intervento manuale.
Aumenta la personalizzazione dei clienti:** Consente un marketing altamente mirato analizzando le preferenze dei clienti e le interazioni passate.
Ottimizza le operazioni aziendali:** Migliora l'efficienza della supply chain, riduce gli sprechi e aumenta la produttività prevedendo la domanda e le esigenze di risorse.
Migliora la diagnostica sanitaria:** Contribuisce alla diagnosi precoce delle malattie e a piani di trattamento personalizzati analizzando i dati dei pazienti.
Accelera la ricerca scientifica: accelera la scoperta di farmaci, l'analisi genetica e la modellazione climatica analizzando rapidamente vasti insiemi di dati.
Come Milvus aiuta nel Data Mining?
Il data mining spesso richiede l'analisi di grandi quantità di dati strutturati e non strutturati (https://zilliz.com/learn/introduction-to-unstructured-data) per scoprire modelli significativi. I database relazionali tradizionali hanno difficoltà a gestire dati non strutturati e ad alta dimensionalità, il che li rende inefficienti per le applicazioni moderne come i sistemi di raccomandazione, il rilevamento di anomalie e la ricerca semantica. Milvus, un database vettoriale open-source sviluppato dagli ingegneri di Zilliz ****, è stato progettato specificamente per gestire dati su larga scala e ad alta dimensionalità, rendendolo uno strumento potente per le attività di data mining.
1. Gestione dei dati ad alta dimensione
Le moderne applicazioni di data mining si basano su dati ad alta dimensione, come le [incorporazioni] di immagini (https://zilliz.com/glossary/vector-embeddings), le rappresentazioni testuali e le [serie temporali] (https://zilliz.com/learn/time-series-embedding-data-analysis), per estrarre informazioni significative. I database relazionali tradizionali sono inefficienti nel gestire questi tipi di dati, poiché sono stati progettati per tabelle strutturate piuttosto che per rappresentazioni vettoriali multidimensionali.
Milvus fornisce un database vettoriale dedicato per memorizzare e gestire le incorporazioni ad alta dimensione, il che lo rende un componente infrastrutturale fondamentale per il data mining guidato dall'intelligenza artificiale.
Supporta diversi formati di dati, tra cui vettori densi e radi, per garantire la flessibilità dei diversi modelli di apprendimento automatico e deep learning.
Le strutture ottimizzate di indicizzazione vettoriale (come IVF, HNSW e PQ) aumentano l'efficienza di archiviazione, riducendo la ridondanza e migliorando le prestazioni delle query in grandi insiemi di dati.
Le funzionalità di Batch processing e di parallelizzazione consentono di inserire e recuperare rapidamente milioni di vettori per le applicazioni di intelligenza artificiale che richiedono aggiornamenti continui.
**Un'azienda di analisi video memorizza in Milvus le incorporazioni fotogramma per fotogramma, consentendo una ricerca e un recupero efficienti basati sui contenuti per la classificazione e l'etichettatura automatica dei video.
2. Scalabilità per le applicazioni di Big Data Mining
Il big data mining richiede database in grado di scalare con volumi crescenti di informazioni. Milvus fornisce:
architettura cloud-native per implementazioni su larga scala in ambienti distribuiti.
Utilizzo efficiente delle risorse per ottenere prestazioni di interrogazione efficienti dal punto di vista dei costi anche su enormi insiemi di dati.
È facile da integrare con pipeline di data mining basate sull'intelligenza artificiale perché è integrato con framework di apprendimento automatico come TensorFlow, PyTorch e Hugging Face.
**In genomica, ad esempio, Milvus memorizza e ricerca le incorporazioni di sequenze di DNA per aiutare i ricercatori a trovare rapidamente le somiglianze genetiche tra milioni di record.
3. Ricerca semantica e di similarità efficiente
Le ricerche semantiche e di similarità sono essenziali per le moderne applicazioni di data mining che coinvolgono dati non strutturati, come immagini, testo e multimedia. A differenza delle ricerche tradizionali basate su parole chiave, la ricerca per similarità si basa su incorporazioni vettoriali per recuperare i risultati più rilevanti in base al significato piuttosto che alle corrispondenze esatte.
Milvus consente una ricerca per similarità ad alte prestazioni sfruttando le incorporazioni vettoriali. Permette agli utenti di trovare risultati basati sul contesto piuttosto che sulle parole esatte.
Supporta gli algoritmi di ricerca Approximate Nearest Neighbor (ANN), come HNSW, IVF e PQ, per accelerare il reperimento di risultati in set di dati di grandi dimensioni.
Le funzionalità di ricerca multimodale consentono di effettuare ricerche trasversali su testo, immagini e video, rendendolo ideale per i sistemi di raccomandazione, il reperimento di contenuti e le applicazioni NLP.
**Ad esempio, un sistema di ricerca di documenti legali può utilizzare Milvus per recuperare le leggi basate sul significato semantico piuttosto che su parole chiave, migliorando l'accuratezza della ricerca legale.
Conclusione
Il data mining è un processo trasformativo che trasforma vasti insiemi di dati in approfondimenti praticabili, promuovendo l'innovazione nei settori della finanza e della sanità. Le organizzazioni possono scoprire modelli nascosti, ottimizzare le operazioni e prendere decisioni basate sui dati sfruttando tecniche avanzate come l'apprendimento supervisionato e non supervisionato, il rilevamento di anomalie e l'estrazione di modelli frequenti. Milvus potenzia queste capacità fornendo una solida piattaforma per l'archiviazione e il recupero di dati ad alta dimensionalità, che consente di effettuare efficienti ricerche semantiche e di similarità. La sua capacità di scalare senza problemi con le applicazioni di big data lo rende uno strumento prezioso per le moderne esigenze di data mining.
Domande frequenti sull'estrazione dei dati
**1. Quali sono le principali tecniche utilizzate nel data mining?
Il data mining utilizza diverse tecniche, tra cui l'apprendimento supervisionato (alberi decisionali, SVM, reti neurali), l'apprendimento non supervisionato (clustering, association rule mining), il rilevamento delle anomalie e l'estrazione di pattern frequenti (Apriori, FP-Growth). Ogni tecnica aiuta a estrarre informazioni significative da grandi insiemi di dati.
**2. In che modo il data mining è diverso dall'analisi tradizionale dei dati?
L'analisi tradizionale dei dati si basa su query predefinite e sull'interpretazione umana, mentre il data mining utilizza algoritmi automatizzati per scoprire modelli, tendenze e relazioni nascoste nei dati. Il data mining è anche più scalabile, il che lo rende adatto alla gestione dei big data e delle applicazioni di intelligenza artificiale.
**3. Quali sono le maggiori sfide del data mining?
Tra le sfide principali del data mining vi sono la gestione di dati rumorosi e incompleti, i problemi di privacy e sicurezza dei dati, la gestione della complessità computazionale e la scalabilità di insiemi di dati enormi. Una preelaborazione efficace e l'uso di modelli avanzati di intelligenza artificiale aiutano a mitigare questi problemi.
**4. Come viene utilizzato il data mining nelle applicazioni reali?
Il data mining è ampiamente utilizzato per il rilevamento delle frodi nel settore bancario, per i sistemi di raccomandazione nell'e-commerce, per la manutenzione predittiva nel settore manifatturiero, per la diagnosi delle malattie nel settore sanitario e per il rilevamento delle minacce alla sicurezza informatica. Aiuta le organizzazioni a ottimizzare il processo decisionale e ad automatizzare i processi.
**5. Che ruolo hanno i database vettoriali nel data mining?
I database vettoriali, come Milvus, aiutano a memorizzare e recuperare dati ad alta dimensionalità in modo efficiente, rendendo più veloce la ricerca di similarità, il clustering e il rilevamento di anomalie. Questi database sono utili per le applicazioni basate sull'intelligenza artificiale, come il riconoscimento delle immagini, l'elaborazione del linguaggio naturale e i sistemi di raccomandazione.
Risorse correlate
- Che cos'è il Data Mining?
- Come funziona il data mining?
- Tecniche e algoritmi di estrazione dei dati
- Applicazioni dell'estrazione dei dati nei vari settori industriali
- Vantaggi del Data Mining
- Come Milvus aiuta nel Data Mining?
- Conclusione
- Domande frequenti sull'estrazione dei dati
- Risorse correlate
Contenuto
Inizia gratis, scala facilmente
Prova il database vettoriale completamente gestito progettato per le tue applicazioni GenAI.
Prova Zilliz Cloud gratuitamente