




Come Inkeep e Milvus hanno costruito un assistente AI guidato da RAG per un'interazione più intelligente
Come sviluppatori, la ricerca della documentazione tecnica di varie piattaforme o servizi può essere noiosa. La documentazione tecnica tipica contiene numerose sezioni e gerarchie che possono essere confuse o difficili da navigare. Di conseguenza, spesso ci troviamo a spendere una quantità significativa di tempo per cercare le risposte di cui abbiamo bisogno. L'aggiunta di un assistente AI alla documentazione tecnica può essere un risparmio di tempo per molti sviluppatori, in quanto possiamo semplicemente chiedere all'AI le nostre domande e questa ci fornirà le risposte o ci reindirizzerà alle pagine e agli articoli pertinenti.
In un recente Unstructured Data Meetup ospitato da Zilliz, Robert Tran, cofondatore e CTO di Inkeep, ha parlato di come Inkeep e Zilliz abbiano costruito un assistente AI per il loro sito di documentazione. Ora possiamo vedere questo assistente AI in azione su entrambi i siti di documentazione di Zilliz e Milvus.
In questo articolo esploreremo i dettagli tecnici presentati da Robert Tran. Quindi, senza ulteriori indugi, iniziamo con la motivazione dell'integrazione di un assistente AI nelle pagine di documentazione tecnica.
La motivazione dell'assistente AI nella documentazione tecnica
La documentazione tecnica è una fonte essenziale di informazioni che tutte le piattaforme devono fornire per assistere i loro utenti o sviluppatori. Deve essere intuitiva, completa e utile per guidare gli sviluppatori di tutti i livelli di esperienza nell'uso delle caratteristiche e delle funzionalità disponibili sulle piattaforme.
Tuttavia, quando le piattaforme introducono numerose nuove funzionalità, la loro documentazione tecnica può diventare eccessivamente complessa. Questa complessità può confondere molti sviluppatori quando navigano nella documentazione tecnica di una piattaforma. Gli sviluppatori sono spesso sotto pressione per ottenere risultati in tempi brevi e il tempo trascorso a cercare informazioni nella documentazione tecnica può distrarli dall'effettivo lavoro di codifica e sviluppo.
Molte piattaforme offrono funzionalità di ricerca di base nella loro documentazione tecnica per aiutare gli sviluppatori a trovare rapidamente i contenuti di cui hanno bisogno, in modo simile a come noi cerchiamo su Google. Gli utenti possono digitare parole chiave e la piattaforma fornisce un elenco di pagine potenzialmente rilevanti per rispondere alle loro domande. Tuttavia, queste funzioni di ricerca di base spesso non riescono a comprendere il contesto della richiesta dell'utente, portando a risultati di ricerca irrilevanti o incompleti.
 Figura - Domande tipiche poste dagli sviluppatori su Milvus .png
Figura - Domande tipiche poste dagli sviluppatori su Milvus .png
Figura: Domande tipiche poste dagli sviluppatori a proposito di Milvus_
Come sviluppatori, sappiamo che le nostre domande sono spesso più sfumate e talvolta troppo complesse per le funzionalità di ricerca di base. Ad esempio, quando navigano nella documentazione tecnica di Zilliz, gli sviluppatori pongono domande altamente tecniche come "Come includere vettori radi insieme a vettori densi durante il processo di recupero?" o "Come scalare il cluster in modo dinamico?". Le funzionalità di ricerca di base spesso non riescono a rispondere in modo soddisfacente a domande così complesse e ricche di sfumature.
L'aggiunta di un assistente AI risolve questi problemi. Un assistente AI è in grado di comprendere l'intento degli sviluppatori e il significato semantico delle loro query, consentendo loro di ottenere le informazioni di cui hanno bisogno in pochi secondi. Gli sviluppatori possono semplicemente digitare la loro domanda e l'assistente AI fornirà loro una risposta o li reindirizzerà alla pagina esattamente pertinente, invece di passare al setaccio molti contenuti, il che è noioso e richiede tempo.
Inoltre, gli assistenti AI si avvalgono dei più recenti progressi nell'elaborazione del linguaggio naturale (NLP), come i Large Language Models (LLMs), la ricerca vettoriale e la Retrieval Augmented Generation (RAG). L'approccio RAG è infatti il cuore di questo assistente AI, che gli consente di comprendere le sfumature delle domande degli utenti e di fornire risposte accurate e pertinenti in pochi secondi.
Nella prossima sezione discuteremo i metodi alla base di un assistente AI.
Il concetto di Generazione Aumentata di Recupero (RAG)
La Retrieval Augmented Generation (RAG) è un metodo che combina tecniche avanzate di NLP, come la ricerca vettoriale e gli LLM, per generare risposte accurate alle domande degli utenti.
 Figura- Flusso di lavoro RAG.png
Figura- Flusso di lavoro RAG.png
Figura: Flusso di lavoro RAG._
In poche parole, il flusso di lavoro di un metodo RAG è piuttosto semplice. Per prima cosa, noi utenti poniamo una domanda. Successivamente, il metodo RAG recupera i documenti pertinenti che potrebbero contenere la risposta alla nostra domanda. Quindi, la nostra domanda e i documenti rilevanti vengono combinati in un'unica richiesta coerente prima di essere inviati a un LLM. Infine, il LLM genera la risposta alla nostra domanda utilizzando i documenti pertinenti forniti.
Come si può notare, il concetto principale di RAG consiste nel fornire a un LLM un contesto pertinente per rispondere alla nostra domanda. Questo approccio presenta almeno due vantaggi: in primo luogo, riduce il rischio di LLM allucinazione, cioè di generare risposte imprecise e non veritiere. In secondo luogo, la risposta generata dal LLM sarà più contestualizzata e adatta alla nostra domanda. Ciò è particolarmente utile quando poniamo al LLM domande sul contenuto di documenti interni.
Le fasi di implementazione della RAG sono quattro: ingestione, indicizzazione, recupero e generazione.
Ingestione: comporta la raccolta e la pre-elaborazione dei dati. Si possono raccogliere anche le informazioni rilevanti e i metadati di ciascun record.
Indicizzazione: comporta il processo di archiviazione dei dati con un metodo di indicizzazione ottimizzato per un rapido recupero. In questa fase, i dati pre-elaborati vengono trasformati in embeddings vettoriali utilizzando un modello di embedding e quindi memorizzati all'interno di un database vettoriale come Milvus con algoritmi di indicizzazione avanzati come FLAT, FAISS o HNSW.
Recupero: comporta operazioni di ricerca vettoriale per abbinare la domanda dell'utente ai dati memorizzati. In questo processo, l'interrogazione dell'utente viene prima trasformata in un vettore incorporato utilizzando lo stesso modello di incorporazione usato per trasformare i dati memorizzati. Successivamente, viene eseguita una ricerca di similarità tra la query dell'utente e i dati memorizzati per trovare le informazioni più rilevanti nel database vettoriale.
Generazione: comporta l'utilizzo di un LLM per produrre la risposta finale. In primo luogo, la domanda dell'utente e il contesto più rilevante della fase di recupero vengono combinati in un prompt. Successivamente, l'LLM genera una risposta alla domanda dell'utente in base al contesto fornito nel prompt.
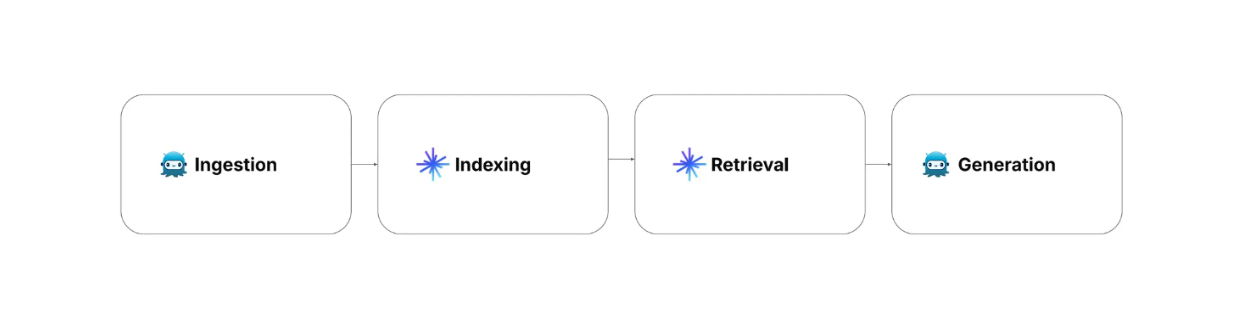 Figura- Fasi di RAG..png
Figura- Fasi di RAG..png
Figura: Fasi del RAG._
Ci sono diversi fattori da considerare nell'implementazione di ciascuna delle fasi sopra menzionate. Ad esempio, durante la fase di ingestione, dobbiamo pensare alla fonte dei dati, all'approccio di pulizia dei dati e al metodo di chunking. Nel frattempo, durante la fase di indicizzazione, dobbiamo considerare il modello di incorporazione e il database vettoriale che vogliamo utilizzare, nonché gli algoritmi di indicizzazione adatti al nostro caso d'uso.
Nella prossima sezione, discuteremo le implementazioni dettagliate di RAG adottate da Inkeep e Zilliz per costruire un assistente AI per le pagine di documentazione di Zilliz e Milvus.
Metodi usati da Inkeep e Zilliz per costruire un assistente AI
Per costruire un assistente AI, Inkeep e Zilliz utilizzano una combinazione di tecniche diverse per l'implementazione di RAG. Inkeep gestisce le parti di ingestione e generazione, mentre Zilliz fornisce supporto a Inkeep nelle fasi di indicizzazione e recupero.
Come accennato nella sezione precedente, il primo passo dell'implementazione di RAG è la fase di ingestione. In questa fase, Inkeep raccoglie i dati testuali relativi a Zilliz e Milvus da varie fonti, come la [documentazione] tecnica (https://milvus.io/docs), il supporto e le FAQ e i [repository GitHub] (https://github.com/milvus-io/milvus). Questi dati testuali vengono poi puliti e suddivisi in gruppi per garantire che ogni informazione non sia né troppo ampia né troppo granulare.
Prima di passare alla fase successiva, vengono raccolti anche i metadati di ogni record raggruppato. Questi metadati includono:
Tipo di fonte: se i dati provengono da un repo GitHub, da una documentazione tecnica, da una pagina di supporto e di FAQ, ecc.
Tipo di record: come la versione dei dati, se si tratta di testo o di codice. Se si tratta di codice, viene indicato anche il linguaggio di programmazione.
Riferimenti gerarchici: includono i figli, i genitori e i fratelli di ciascun punto di dati. Questo è importante perché i dati sono raccolti dai siti web di Zilliz.
URL, tag, percorsi: come gli URL da cui sono stati presi i dati. Questi metadati sono molto utili per fornire collegamenti a citazioni o fonti nella risposta generata dal LLM.
Date: come la data di pubblicazione di ciascun dato.
Una volta che Inkeep ha raccolto i dati e i loro metadati, il passo successivo è il metodo di indicizzazione.
Nel metodo di indicizzazione, i dati pre-elaborati devono essere trasformati in incorporazioni vettoriali per consentire la ricerca di similarità nella fase di recupero. Per trasformare ogni punto di dati in un embedding vettoriale, Inkeep e Zilliz utilizzano tre diversi metodi di embedding: un modello di embedding sparse tradizionale, un modello di embedding sparse basato sul deep learning e un modello di embedding denso.
 Figura - Incorporamenti sparsi e densi..png
Figura - Incorporamenti sparsi e densi..png
Figura: Incorporamenti sparsi e densi.
Le Sparse embedding sono particolarmente utili per processi di matching semplici, basati su parole chiave e booleani. Pertanto, i documenti rilevanti recuperati da un embedding sparse contengono normalmente le parole chiave dell'interrogazione. Nel frattempo, dense embedding è più utile per catturare le sfumature o il significato semantico della query. I documenti recuperati dal dense embedding possono contenere o meno le parole chiave della query, ma il contenuto sarà altamente rilevante.
Esistono due diversi tipi di modelli che possono essere utilizzati per trasformare i dati in sparse embedding: modelli tradizionali/statistici e modelli basati sul deep learning. Per l'assistente AI, Inkeep e Zilliz utilizzano BM25 come modello tradizionale e SPLADE/BGE-M3 come modello basato sul deep learning.
Per trasformare i dati in embedding densi, si possono scegliere molti modelli di deep learning, come quelli di OpenAI, Sentence-Transformers, VoyageAI, ecc. Per l'assistente AI, Inkeep e Zilliz utilizzano tre diversi modelli di embedding: MS-MARCO, MPNET e BGE-M3.
Una volta trasformati tutti i dati nelle loro rappresentazioni rade e dense, le incorporazioni vengono memorizzate in un database vettoriale per consentire un rapido recupero. Per costruire l'assistente AI, Inkeep e Zilliz utilizzano Milvus come database vettoriale. Ora la domanda è: perché dobbiamo usare una combinazione di embedding sparse e dense quando la scelta di una di esse potrebbe essere sufficiente?
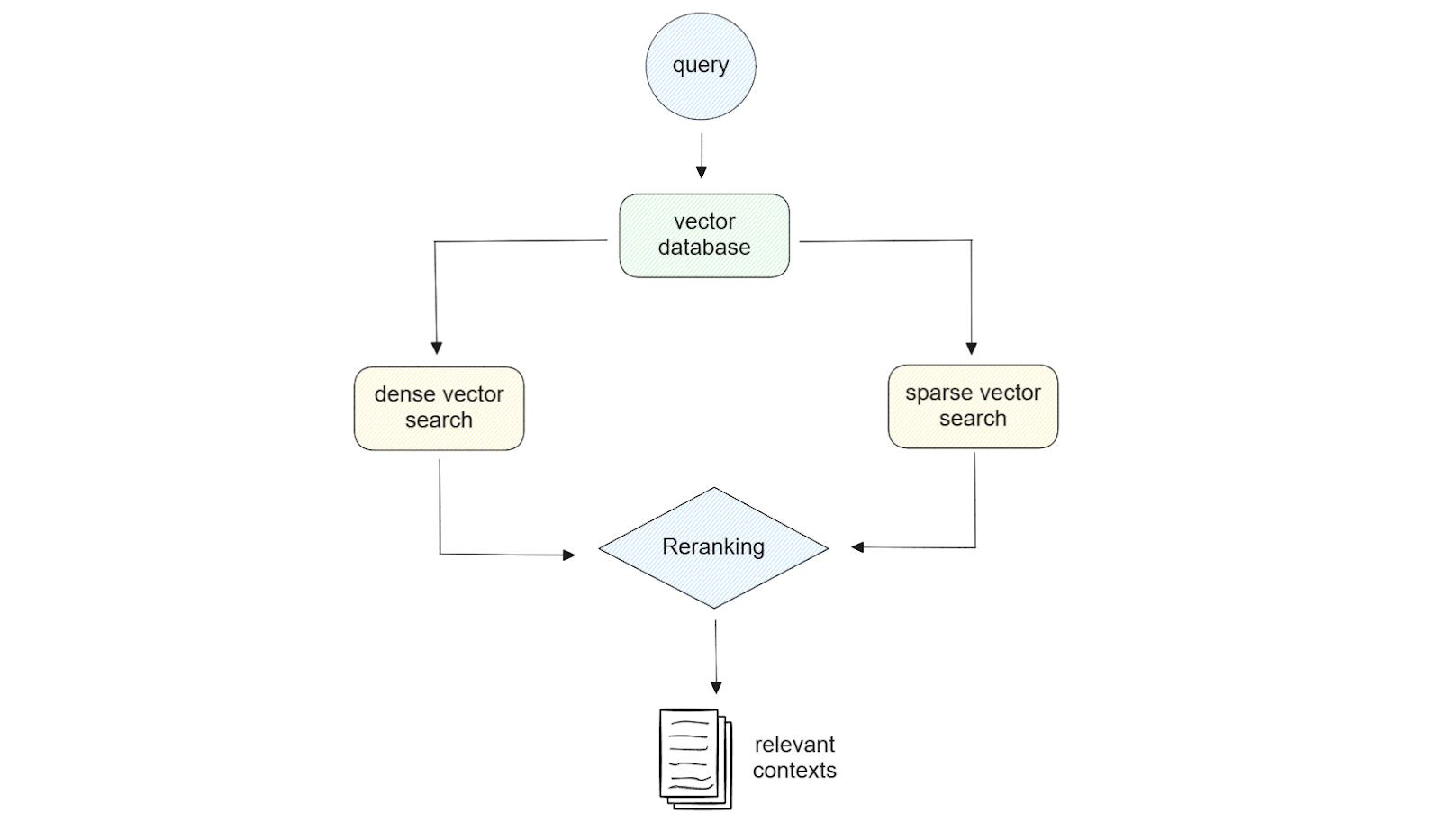 Figura - Illustrazione della ricerca ibrida..png
Figura - Illustrazione della ricerca ibrida..png
Figura: Illustrazione della ricerca ibrida._
L'utilizzo di embedding sia sparse che dense offre flessibilità nella fase di recupero. Ad esempio, se la nostra query è breve (meno di 5 parole), l'uso dell'embedding sparse potrebbe essere sufficiente. Se invece l'interrogazione è lunga, nella maggior parte dei casi l'utilizzo di un embedding denso consente di ottenere risultati di qualità migliore. Inoltre, se utilizziamo Milvus come database vettoriale, possiamo sfruttare la potenza di hybrid search, cioè la ricerca di similarità utilizzando una combinazione di embedding sparse e dense. Se lo si desidera, si può anche eseguire una ricerca di similarità con incorporazione densa o rada con metadata filtering.
Quando si implementa una ricerca ibrida per trovare i contenuti più rilevanti per la nostra query, è necessario considerare anche il metodo di reranking. Questo perché otterremo risultati simili da due metodi diversi e abbiamo bisogno di un approccio per combinare questi risultati. Per fare ciò, Inkeep e Zilliz hanno implementato due diversi metodi di reranking: il weighted scoring e la reciprocal rank fusion (RRF).
Il concetto di punteggio ponderato è semplice: assegniamo un peso a ciascun metodo. Ad esempio, possiamo assegnare un peso del 60% al risultato di somiglianza ottenuto con l'incorporazione densa e del 40% con l'incorporazione rada. Nel RRF, invece, i punteggi dei contesti sono calcolati sommando i loro ranghi reciproci tra due metodi diversi, spesso con una piccola costante aggiuntiva k per evitare la divisione per zero.
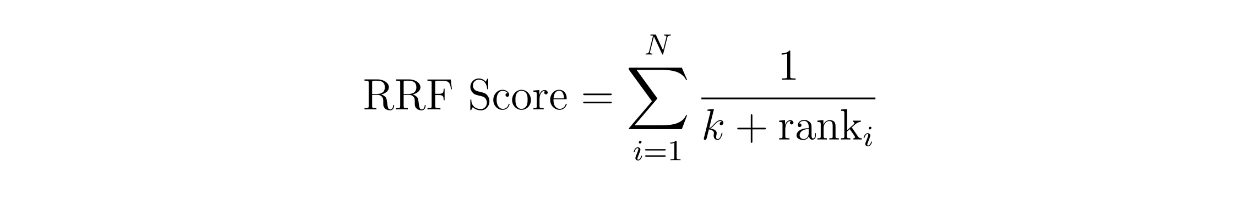 function rrf score.png
function rrf score.png
dove N è il numero di metodi, che dovrebbe essere due poiché stiamo implementando una ricerca ibrida tra un embedding rado e un embedding denso. La variabile "rank" è il rango di un contesto nel metodo i e k è una costante.
Utilizzando l'equazione RRF di cui sopra, possiamo calcolare il punteggio RRF per ogni contesto. Il contesto con il punteggio RRF più alto sarà selezionato come il contesto più rilevante per una query.
Una volta individuato il contesto pertinente, la query originale e il contesto più pertinente vengono combinati in una richiesta coerente. Questa richiesta viene poi inviata a un LLM per generare la risposta finale. Per l'LLM, Inkeep utilizza i modelli di OpenAI e Anthropic.
La demo dell'assistente AI Milvus
In questa sezione, forniremo una breve introduzione su come utilizzare l'assistente AI costruito da Inkeep e Zilliz. Se volete seguirci, potete consultare le pagine di documentazione di Zilliz o Milvus. Per questa dimostrazione, utilizzeremo l'assistente AI nella pagina di documentazione di Milvus.
Quando si apre la pagina di documentazione di Milvus, si vedrà il pulsante "Ask AI" in basso a destra dello schermo. Fare clic su questo pulsante per accedere all'assistente AI.
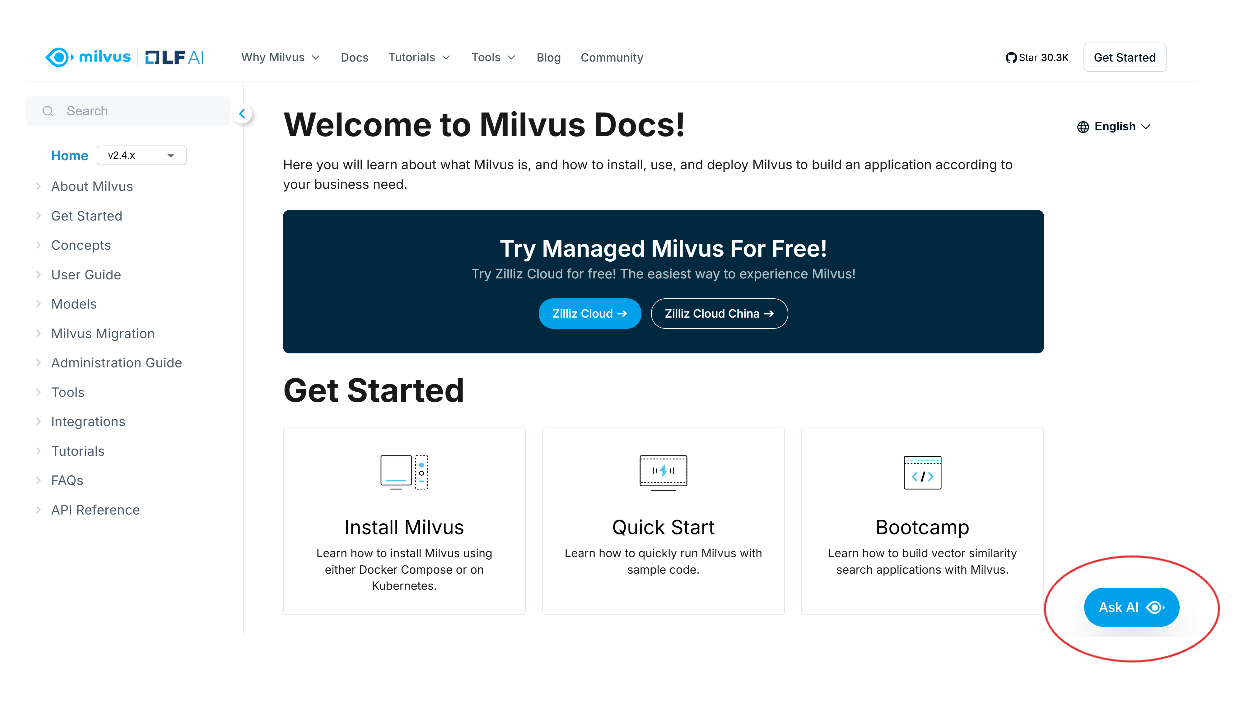 screenshot 1.png
screenshot 1.png
Successivamente, apparirà una schermata a comparsa che vi chiederà di chiedere qualsiasi cosa vogliate trovare nella documentazione di Milvus. È anche possibile eseguire una ricerca di base facendo clic sull'opzione "Cerca" in alto a destra della schermata a comparsa.
Supponiamo di voler sapere come trasformare i nostri dati in embeddings vettoriali usando BGE-M3 con il Milvus Python SDK. Possiamo semplicemente digitare la nostra domanda e l'assistente AI ci fornirà una risposta.
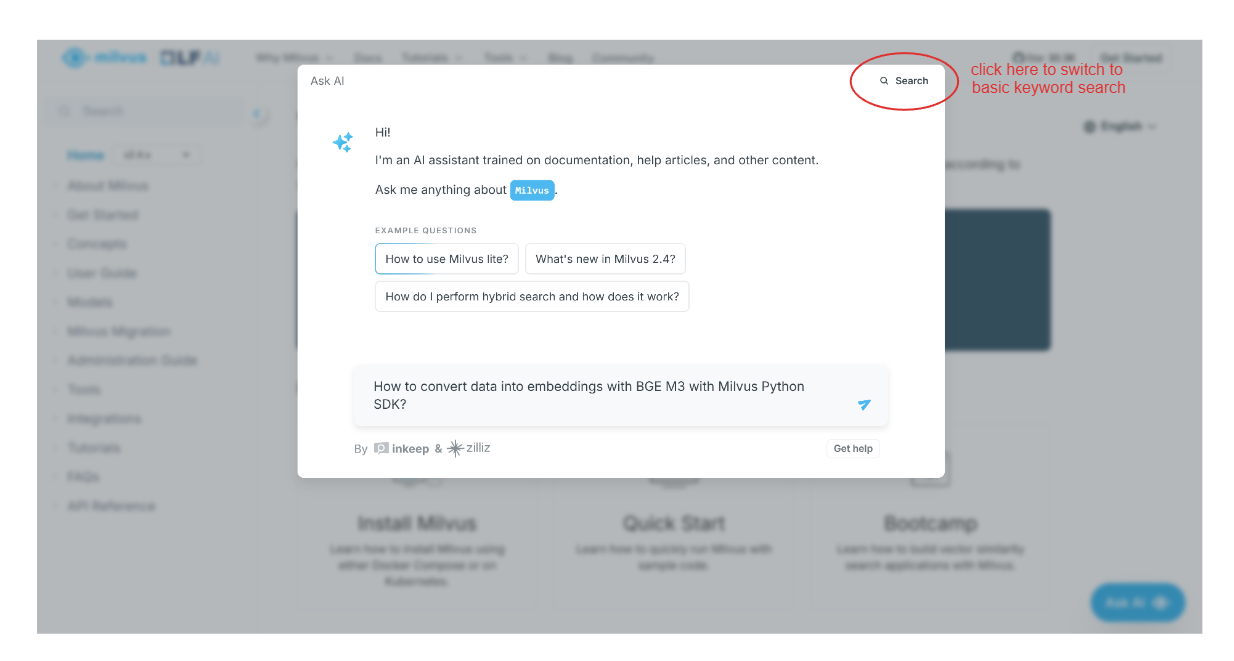 screenshot 2.png
screenshot 2.png
Oltre a fornire una risposta, l'assistente AI ci fornirà anche citazioni o pagine pertinenti dove trovare ulteriori informazioni relative alla risposta generata.
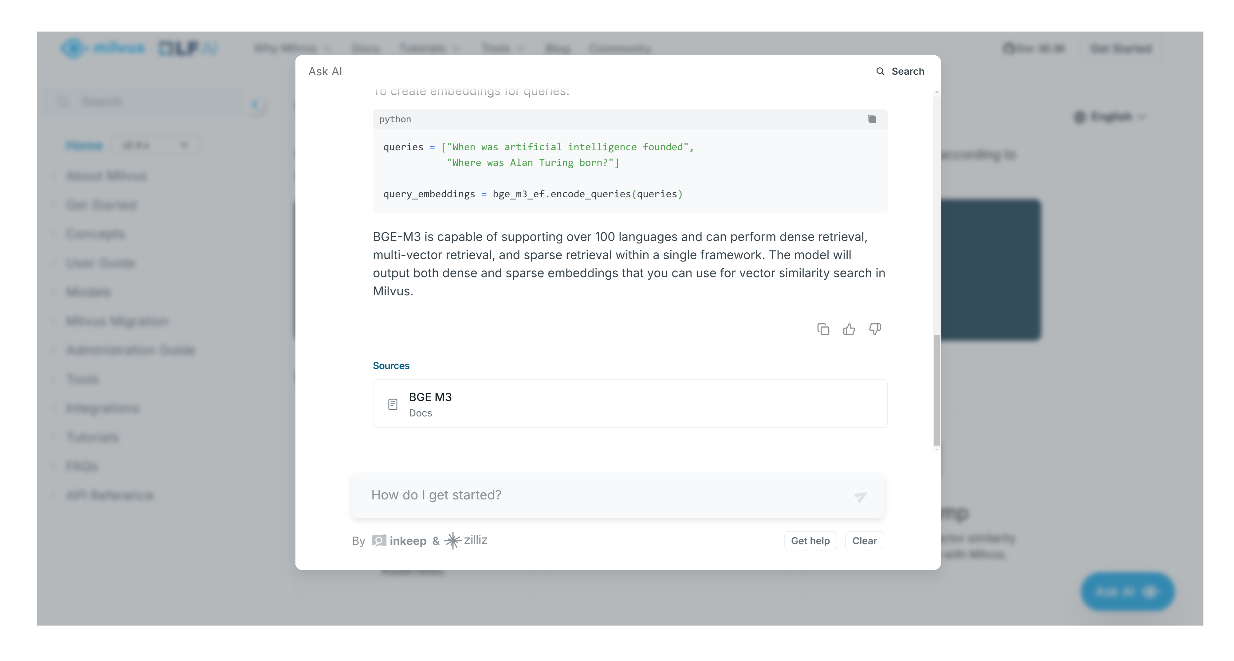 screenshot 3.png
screenshot 3.png
Conclusione
L'integrazione di un assistente AI nella documentazione tecnica, realizzata da Inkeep e Zilliz, dimostra come le soluzioni AI avanzate possano migliorare la produttività degli sviluppatori e l'esperienza degli utenti. Il RAG è il componente fondamentale di questo assistente AI, poiché questo metodo aiuta l'LLM a fornire risposte più accurate e contestualizzate a domande complesse e ricche di sfumature.
Il RAG consiste in quattro fasi fondamentali: ingestione, indicizzazione, recupero e generazione. I database vettoriali come Milvus sono un componente chiave della pipeline RAG, in quanto eseguono le fasi di indicizzazione e recupero. I metodi utilizzati in ciascuna fase devono essere attentamente considerati in base al caso d'uso specifico. In questo articolo abbiamo visto un esempio di come Inkeep e Zilliz abbiano implementato varie strategie in ogni fase della RAG per costruire un sofisticato assistente AI.
Per saperne di più su come Milvus e Inkeep hanno costruito questo assistente AI, guardate il replay dell'intervento di Robert su YouTube.
Ulteriori letture
Continua a leggere

Zilliz Cloud Update: Tiered Storage, Business Critical Plan, Cross-Region Backup, and Pricing Changes
This release offers a rebuilt tiered storage with lower costs, a new Business Critical plan for enhanced security, and pricing updates, among other features.

Zilliz Cloud Launches in AWS Australia, Expanding Global Reach to Australia and Neighboring Markets
We're thrilled to announce that Zilliz Cloud is now available in the AWS Sydney, Australia region (ap-southeast-2).

Milvus WebUI: A Visual Management Tool for Your Vector Database
Explore Milvus WebUI to monitor, manage, and optimize your vector database with real-time insights, performance tracking, and system health monitoring.