




GLUE Benchmark: A Guide to General Language Understanding Evaluation
GLUE Benchmark: A Guide to General Language Understanding Evaluation
DL; DR
The GLUE (General Language Understanding Evaluation) Benchmark is a collection of nine natural language processing (NLP) tasks designed to evaluate the performance of models on a wide range of language understanding challenges. These tasks include textual entailment, sentiment analysis, sentence similarity, and more. It serves as a standard benchmark for comparing NLP models' abilities to understand and process text. GLUE provides a unified framework with standardized evaluation metrics, making it a key resource for advancing and assessing general-purpose language models.
 GLUE Benchmark for LLMs.png
GLUE Benchmark for LLMs.png
Introduction
What does it truly mean for a machine to understand human language? Imagine asking an AI assistant to summarize a complex article, detect sarcasm in a tweet, or answer nuanced questions. How do we measure its success? This challenge is at the heart of evaluating natural language processing (NLP) models.
The GLUE benchmark is a gold standard for assessing a model's ability to handle diverse and essential natural language tasks, such as speech recognition, question/answering, text summarization, etc. It evaluates how well AI models perform and identify areas where they struggle. GLUE helps build stronger, more versatile NLP models by grouping key language tasks into a single set, driving progress in language technology.
This guide will help you understand the GLUE benchmark and its role in evaluating NLP models.
What is the GLUE Benchmark?
The General Language Understanding Evaluation (GLUE) benchmark is an extensive corpus of resources to assess the performance of NLP models across various natural language understanding (NLU) tasks. It systematically evaluates models on various linguistic tasks, including sentiment analysis, textual entailment, and paraphrase generation.
The main aim of GLUE is to encourage the development of powerful models capable of handling diverse language queries. GLUE also provides a systematic framework for researchers to benchmark their NLP models against well-accepted established standards and identify their strengths and weaknesses.
GLUE consists of nine different tasks that cover a diverse set of styles, data quantities, and complexities, including:
Single-Sentence Tasks: These tasks include sentiment analysis and linguistic acceptability. For example, the Corpus of Linguistic Acceptability (CoLA) tests sentence grammatical acceptability, while Stanford Sentiment Treebank (SST-2) focuses on determining the sentiment of movie reviews.
Similarity and Paraphrase Tasks: These tasks involve evaluating how similar two sentences are or whether they are paraphrases. Notable datasets include the Microsoft Research Paraphrase Corpus (MRPC) and the Semantic Textual Similarity Benchmark (STS-B).
Inference Tasks: These tasks determine whether one sentence logically follows from another. For example, the Multi-Genre Natural Language Inference (MNLI) dataset evaluates whether a hypothesis follows from a premise across different domains.
GLUE benchmark tests many linguistic dimensions, such as syntax, semantics, and logical inference. By integrating tasks with varying difficulties and data scales, GLUE challenges models to acquire a general understanding of the languages instead of specializing in just one task or domain.
Key Features of GLUE
Task Diversity: GLUE includes tasks that require models to understand sentence acceptability, sentiment, paraphrasing, and textual entailment, providing a well-rounded assessment of NLU capabilities.
Standardized Benchmarking: GLUE is a reference point, making it easier for researchers to compare different models.
Multi-Task Focus: It encourages models that share linguistic knowledge across different tasks, fostering the development of versatile NLP systems.
Diagnostic Suite: GLUE also includes a diagnostic test set, allowing researchers to understand their models' strengths and weaknesses in handling various tasks, such as logical reasoning and commonsense understanding.
How Does the GLUE Benchmark Work?
The operation of the GLUE benchmark is based on testing NLP models on various tasks, each of which targets specific aspects of language comprehension. Such tasks entail single-sentence classification, sentence-pair classification, and regression tasks involving text relations. GLUE defines standardized tasks and metrics to evaluate how effectively a model generalizes across languages and tasks.
The GLUE metrics discussed below are essential indicators for evaluating how well a model meets the desired performance criteria.
Metrics Used in GLUE
GLUE uses a variety of metrics to evaluate model performance, depending on the task:
Accuracy: Used in tasks like MNLI, QNLI, and others requiring a classification decision.
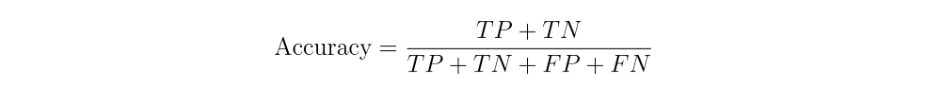 1.png
1.png
Accuracy is the proportion of all predictions (both positives and negatives) that the model classifies correctly. It provides a straightforward measure of overall performance.
F1 Score: Used in tasks with imbalanced classes, such as MRPC, to provide a balanced assessment of precision and recall. The F1 Score is the harmonic mean of precision and recall, ensuring that false positives and negatives are accounted for when evaluating the model.
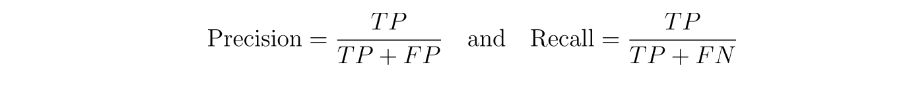 2.png
2.png
 3.png
3.png
F1 score is the harmonic mean of precision and recall, offering a single measure that balances both metrics. Precision is the fraction that truly is positive out of all the predicted instances. Recall is the fraction the model correctly identifies out of all the positive instances.
Correlation Coefficients: For regression tasks like STS-B, metrics like Pearson and Spearman correlation measure the similarity between predicted and actual scores.
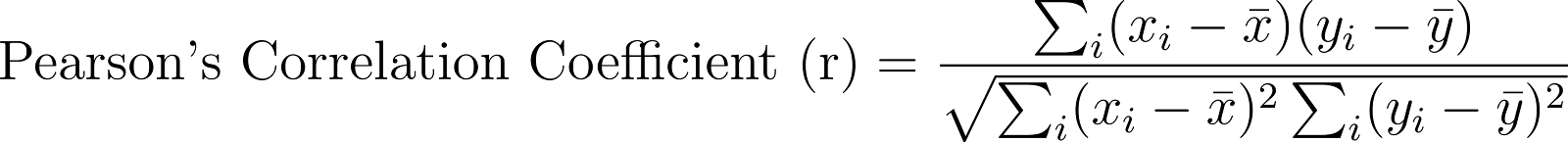 4.png
4.png
Correlation coefficients measure how closely the model’s predictions match the true values continuously. It indicates how well the model captures the underlying relationships.
Matthews Correlation Coefficient: Specifically used for CoLA, this metric evaluates the quality of binary classifications, particularly for imbalanced datasets. The Matthews Correlation Coefficient provides a comprehensive evaluation by considering true and false positives and negatives, making it suitable for evaluating models on datasets with uneven class distributions.
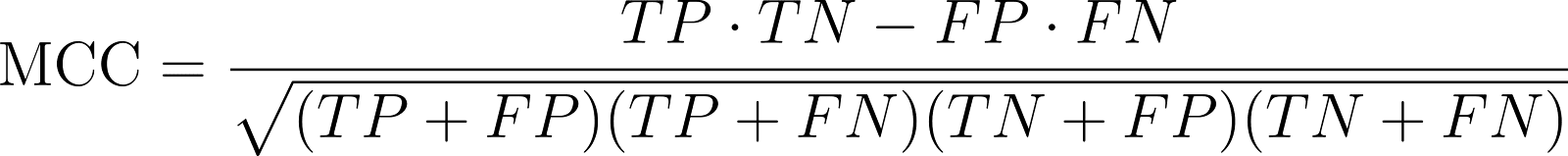 5.png
5.png
MCC provides a balanced evaluation of binary classification performance, accounting for true and false positives and negatives, making it useful especially for imbalanced datasets.
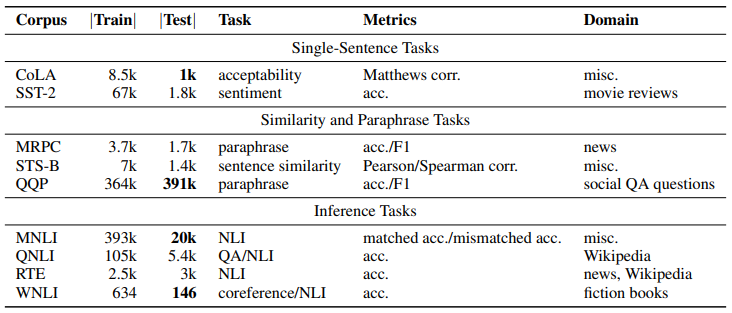 Summary of GLUE benchmark datasets, tasks, metrics, and domains..png
Summary of GLUE benchmark datasets, tasks, metrics, and domains..png
Summary of GLUE benchmark datasets, tasks, metrics, and domains.
This table categorizes GLUE datasets into single-sentence, similarity/paraphrase, and inference tasks, showing the number of examples, task types, metrics, and domains. It highlights the diversity of tasks for evaluating natural language understanding models.
Detailed Overview of GLUE Tasks
The GLUE benchmark consists of nine tasks, each a single-sentence or sentence-pair classification task. Below, each of the nine tasks is explained briefly.
1. CoLA (Corpus of Linguistic Acceptability)
CoLA tests whether a given sentence is grammatically acceptable. This task evaluates the model's ability to understand syntactic correctness.
| Input | Output | Metric |
|---|---|---|
| A single sentence | Acceptable or Not Acceptable | Matthews Correlation Coefficient |
Example:
Input: "She running quickly."
Output: Not Acceptable
2. SST-2 (Stanford Sentiment Treebank)
SST-2 focuses on sentiment analysis of movie reviews, determining whether the sentiment is positive or negative.
| Input | Output | Metric |
|---|---|---|
| A single sentence | Positive or Negative | Accuracy |
Example:
Input: "The movie was breathtaking and captivating."
Output: Positive
3. MRPC (Microsoft Research Paraphrase Corpus)
MRPC involves pairs of sentences, where the model determines if they are semantically equivalent.
| Input | Output | Metric |
|---|---|---|
| Sentence pair | Paraphrase or Not Paraphrase | F1 Score |
Example:
Input: "The car is fast." and "The vehicle moves quickly."
Output: Paraphrase
4. MNLI (Multi-Genre Natural Language Inference)
Given a premise and a hypothesis, this task determines if the hypothesis is true, false, or undetermined based on the premise. MNLI includes both matched (in-domain) and mismatched (cross-domain) sections.
| Input | Output | Metric |
|---|---|---|
| Premise and Hypothesis | Entailment, Contradiction, or Neutral | Accuracy |
Example:
Input: Premise: "The cat is sleeping on the mat." Hypothesis: "The mat is occupied."
Output: Entailment
5. STS-B (Semantic Textual Similarity Benchmark)
STS-B evaluates how similar two sentences are, using scores ranging from 0 to 5, where higher scores indicate greater similarity.
| Input | Output | Metric |
|---|---|---|
| Sentence pair | Similarity score (0-5) | Pearson and Spearman Correlations |
Example:
Input: "A boy is playing in the park." and "A child is playing outside."
Output: 4.5 (High Similarity)
6. QNLI (Question Natural Language Inference)
QNLI is a modified Stanford Question Answering Dataset (SQuAD) version. The task involves determining if a given sentence contains the correct answer to a question.
| Input | Output | Metric |
|---|---|---|
| Question and Sentence | Answerable or Not Answerable | Accuracy |
Example:
Input: Question: "Where do penguins live?" Sentence: "Penguins live in Antarctica."
Output: Answerable
7. RTE (Recognizing Textual Entailment)
RTE combines data from several textual entailment challenges to determine whether a given hypothesis can be logically inferred from a text.
| Input | Output | Metric |
|---|---|---|
| Premise and Hypothesis | Entailment or Not Entailment | Accuracy |
Example:
Input: Premise: "She has a pet cat." Hypothesis: "She owns an animal."
Output: Entailment
8. WNLI (Winograd Schema NLI)
WNLI is a reading comprehension task requiring the model to determine the antecedent of an ambiguous pronoun.
| Input | Output | Metric |
|---|---|---|
| Sentence with Ambiguous Pronoun | Correct Antecedent | Accuracy |
Example:
Input: "The trophy didn't fit in the suitcase because it was too large." (What does "it" refer to?)
Output: Trophy
9. QQP (Quora Question Pairs)
QQP involves determining if two questions asked on Quora have the same intent.
| Input | Output | Metric |
|---|---|---|
| Question pair | Duplicate or Not Duplicate | F1 Score |
Example:
Input: "How do I learn Python?" and "What is the best way to learn Python programming?"
Output: Duplicate
Example Implementation
An example of how you can load GLUE tasks using popular frameworks is shown below:
from datasets import load_dataset
dataset = load_dataset("glue", "mrpc")
print(dataset["train"][0])
This snippet uses the HuggingFace Datasets library to load the MRPC dataset from GLUE, making it easy for developers to start experimenting with these tasks. HuggingFace has made it straightforward for practitioners to quickly access and utilize GLUE datasets for model training, evaluation, and fine-tuning.

The output of the example implementation
Comparison: GLUE vs. SQuAD
The GLUE benchmark provides a more comprehensive approach to evaluating NLP models compared to older benchmarks like SQuAD. The comparison below showcases the differences and demonstrates how GLUE improves upon previous limitations and offers a better understanding of a model's general capabilities.
Diversity and Scope
SQuAD: It focused narrowly on question-answering tasks, providing valuable insights into a model’s ability to retrieve and comprehend information but failing to assess broader language capabilities.
GLUE: It includes a variety of tasks to test models on different language understanding skills, like sentiment analysis, paraphrasing, and linguistic acceptability. This variety shows GLUE’s strength in evaluating models for real-world, multi-task uses.
Promoting Transfer Learning
SQuAD: SQuAD only focuses on question-answering tasks, it doesn’t encourage models to learn skills that can be applied to other tasks, limiting their ability to transfer knowledge effectively.
GLUE: It supports transfer learning by offering diverse tasks with limited training data, allowing models to share knowledge between tasks. This approach works well with pre-trained models like BERT and GPT, which perform strongly in multiple tasks.
Encouraging Robust Model Development
SQuAD: Models optimized for SQuAD often overfit to specific patterns of the QA dataset, limiting their performance on unseen tasks or datasets.
GLUE: Includes a variety of tasks and datasets, helping models develop broader language skills and perform better in real-world situations.
Real-World Applicability
SQuAD: Excels in evaluating QA systems but lacks the breadth to assess a model’s performance in practical, multi-functional use cases.
GLUE: Designed to test models for general-purpose language understanding, making it more suitable for real-world applications where a single model must handle various tasks, such as chatbots, sentiment analyzers, and summarizers.
| Feature | GLUE | SQuAD |
|---|---|---|
| Task Diversity | Multiple tasks, including sentiment, entailment, paraphrasing | Focused on question-answering only |
| Number of Tasks | Nine | One |
| Evaluation Metrics | Accuracy, F1, Correlation, MCC | Exact Match, F1 Score |
| Scope | General-purpose NLU | Information retrieval and QA |
| Applications | Wide range of NLP tasks | QA systems |
| Generalization Focus | Promotes multi-task learning | Focused on QA-specific capabilities |
Comparison: GLUE vs. SuperGLUE
SuperGLUE, short for Super General Language Understanding Evaluation, is a benchmark created to test how well NLP models handle a wide range of complex language understanding tasks. It’s essentially an upgraded version of GLUE, designed to raise the bar. While GLUE focuses on simpler tasks, SuperGLUE includes more sophisticated challenges that demand deeper reasoning, commonsense knowledge, and understanding of context.
SuperGLUE improves upon GLUE by introducing significantly more challenging tasks reflective of real-world language understanding.
| Features | GLUE | SuperGLUE |
|---|---|---|
| Task Complexity | Basic linguistic tasks (e.g., sentiment analysis) | Complex tasks requiring reasoning and commonsense |
| Dataset Saturation | Performance nearing the human level | Ample headroom for model improvements |
| Reasoning Requirement | Minimal reasoning required | High-level reasoning and inference are necessary |
| Task Diversity | Mainly sentence classification and similarity tasks | Includes QA, coreference, and reading comprehension |
| Real-World Application | Limited real-world reflection | Tasks designed to emulate real-world language challenges |
Benefits and Challenges of GLUE
The GLUE benchmark has significantly impacted NLP research and development, offering both opportunities and hurdles for model evaluation.
Benefits
Standardized Evaluation: GLUE provides a common framework for evaluating NLP models, making it easier to benchmark new models against each other. For example, researchers can compare their models' performance on specific tasks, like SST-2, to see how they stack up against competitors.
Promotes Generalization: By including a wide range of tasks, GLUE encourages models to generalize well across different NLU scenarios rather than specializing in just one task. It is crucial for building models that work well in real-world applications where diverse language tasks are required.
Task Diversity: The wide variety of tasks included in GLUE ensures that models are evaluated for different linguistic capabilities, from sentiment analysis to textual entailment. For instance, evaluating both paraphrase detection and entailment tasks helps assess a model's understanding of sentence relationships.
Advancing Research: GLUE has played an important role in driving advances in transfer learning and multi-task training in NLP. By setting a standard for model evaluation, GLUE has prompted the development of more capable and generalized language models like BERT and GPT.
Ease of Use: The availability of preprocessed datasets and tools, such as Hugging Face Datasets, makes it easy for researchers to use GLUE for their experiments. Its access lowers the barrier to entry for evaluating new models.
Performance Benchmarking: The GLUE leaderboard provides a public platform for comparing the state-of-the-art models in NLP. This transparency motivates researchers to push the limits of model performance and encourages collaboration within the community.
Challenges
Task Biases: Some tasks within GLUE have inherent biases, leading models to learn unintended patterns instead of genuinely understanding the language. For instance, models might exploit dataset-specific quirks rather than understanding the underlying semantic relationships.
Data Imbalance: Several tasks in GLUE have imbalanced datasets, which can skew the model's learning process and performance. For example, if one class is overrepresented in the dataset, the model may become biased towards that class, leading to misleading accuracy scores.
Real-World Applicability: The focus on achieving high benchmark scores may not always translate into real-world performance. A model that performs well on GLUE may still struggle with real-world data that contains more variability and noise.
Model Saturation: As top models saturate the benchmark, GLUE becomes less useful for distinguishing between the best-performing models. For instance, many recent models have achieved near-perfect scores on certain GLUE tasks, making it difficult to use the benchmark to identify meaningful improvements.
Compute Intensity: Running models on all GLUE tasks can be computationally expensive, making it challenging for smaller research groups with limited resources. It creates a barrier to participation and innovation for those without access to high-performance computing infrastructure.
Overfitting to Benchmarks: GLUE is a widely used standard for evaluating NLP models, there’s a risk that models are designed specifically to perform well on GLUE tasks rather than truly improving their overall language understanding. This means the models might excel in the benchmark but struggle when applied to new, unseen data, limiting their usefulness in real-world applications.
Use Cases and Tools for GLUE
GLUE is a central measure for evaluating NLP models across many use cases, from sentiment analysis to paraphrasing and linguistic inference. Various GLUE datasets and tools, such as Hugging Face and TensorFlow, are used to fine-tune and test models' performance in natural language understanding.
Use Cases
Benchmark for Multi-Task Learning: GLUE’s design encourages models to perform well across many different tasks, like sentiment analysis and linguistic acceptability, all at once. For example, a model trained with GLUE might handle both analyzing customer reviews and correcting grammar, showing its versatility.
Evaluation for Fine-Grained Language Understanding: GLUE includes tasks that test detailed language skills, such as detecting subtle meaning differences in similar sentences (e.g., “He finished the report” vs. “He completed the report”). This makes it valuable for ensuring models truly understand the nuances of language.
Educational and Research Purposes: GLUE is widely used in academia to teach and experiment with NLU models. Students and researchers can leverage GLUE datasets to practice building, fine-tuning, and evaluating NLP models, making it an invaluable educational tool.
Real-World NLP System Evaluation: Companies use GLUE to evaluate the robustness of NLP systems for deployment in real-world scenarios. For example, a chatbot provider may use GLUE to ensure that their system can handle a variety of linguistic inputs and maintain accuracy across different conversation topics.
Domain-Specific Model Tuning: GLUE can be used as a base for fine-tuning models for specific industries or applications. For example, a company in the finance sector might use GLUE tasks as a preliminary benchmark before fine-tuning a model specifically on financial documents to ensure its adaptability.
Semantic Search Applications: GLUE tasks can be related to use cases such as building semantic search systems, where understanding textual entailment and similarity is crucial. These models can then be used in tools like Milvus to quickly find the most meaningful matches for a search query instead of just matching keywords. This results in more accurate and helpful search results.
Tools
Hugging Face Datasets: Provides easy access to GLUE tasks for training and evaluation. The Hugging Face library has extensive documentation and support for integrating GLUE datasets into various NLP workflows, simplifying experimentation.
TensorFlow Datasets: Includes GLUE datasets, allowing seamless integration with TensorFlow-based workflows. TensorFlow users can leverage these datasets to train and evaluate their models efficiently, ensuring compatibility with the GLUE benchmark.
FAQs
- What is the GLUE benchmark?
GLUE is a set of nine tasks designed to test NLP models on challenges like sentiment analysis, paraphrasing, and textual entailment. It ensures that models can effectively handle different language problems.
- Why is GLUE important?
GLUE provides a standard way to compare NLP models, drives improvements in language understanding, and motivates the creation of better, more versatile models.
- How can I use GLUE datasets?
You can load GLUE tasks easily using platforms like Hugging Face or TensorFlow. For example, Hugging Face allows you to import a GLUE task with a simple Python command.
- How does GLUE help in NLP research?
GLUE evaluates models on multiple tasks, helping researchers test their ability to generalize and learn across different language problems.
- How is the GLUE score calculated?
The GLUE score combines a model’s performance across all GLUE tasks into a single number, representing its overall language understanding ability. For example, if a model performs well on tasks like SST-2 (sentiment analysis) and MRPC (paraphrase detection), the GLUE score summarizes this success.
Related Resources
- DL; DR
- Introduction
- What is the GLUE Benchmark?
- How Does the GLUE Benchmark Work?
- Comparison: GLUE vs. SQuAD
- Comparison: GLUE vs. SuperGLUE
- Benefits and Challenges of GLUE
- Use Cases and Tools for GLUE
- Related Resources
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for Free